
【強化學(xué)習(xí)】通俗易懂談強化學(xué)習(xí)之Q-Learning算法實戰(zhàn)
知乎 |?https://www.zhihu.com/people/xu-xiu-jian-33
前言:上篇介紹了什么是強化學(xué)習(xí),應(yīng)大家需求,本篇實戰(zhàn)講解強化學(xué)習(xí),所有的實戰(zhàn)代碼可以自行下載運行。
本篇使用強化學(xué)習(xí)領(lǐng)域經(jīng)典的Project-Pacman項目進行實操,Python2.7環(huán)境,使用Q-Learning算法進行訓(xùn)練學(xué)習(xí),將講解強化學(xué)習(xí)實操過程中的各處細(xì)節(jié)。如何設(shè)置Reward函數(shù),如何更新各(State,Action)下的Q-Value值等。有基礎(chǔ)的讀者可以直接看Part4實戰(zhàn)部分。文章略長,細(xì)節(jié)講解很多,適合新手入門強化學(xué)習(xí)。
01 強化學(xué)習(xí)
關(guān)于強化學(xué)習(xí)的基礎(chǔ)介紹,可以閱讀我上一篇帖子,本篇不再介紹。如果完全是零基礎(chǔ)的讀者,建議先閱讀上一篇文章。里面介紹了強化學(xué)習(xí)的五大基本組成部分、訓(xùn)練過程、各大常見算法以及實際工業(yè)界應(yīng)用等。
02 Pacman Project講解
Pacman-吃豆人游戲,本身是上世紀(jì)80年代日本南夢宮游戲公司推出的一款街機游戲,在當(dāng)時風(fēng)靡大街小巷。后來加州大學(xué)伯克利分校,這所只有諾貝爾獎獲得者才配在學(xué)校里面擁有固定車位的頂級公立大學(xué),將Pacman游戲引進到強化學(xué)習(xí)的課程中,作為實操項目。慢慢地成為該領(lǐng)域的經(jīng)典Project。
項目鏈接:http://ai.berkeley.edu/project_overview.html,這個項目因為時間比較久,所以整體是Python2.7的源碼,沒有最新的Python3源碼。
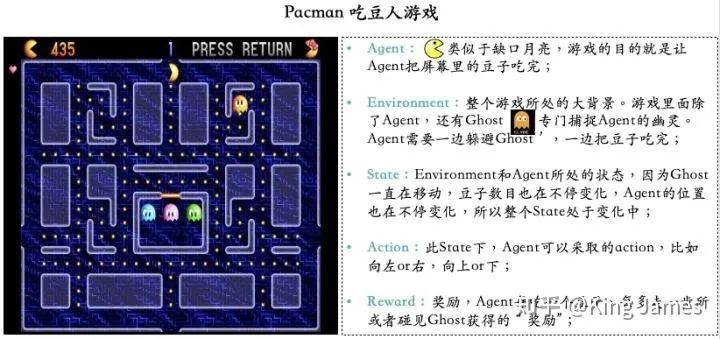
Pacman游戲目標(biāo)很簡單,就是Agent要把屏幕里面所有的豆子全部吃完,同時又不能被幽靈碰到,被幽靈碰到則游戲結(jié)束,幽靈也是在不停移動的。Agent每走一步、每吃一個豆子或者被幽靈碰到,屏幕左上方這分?jǐn)?shù)都會發(fā)生變化,圖例中當(dāng)前分?jǐn)?shù)是435分。
本次項目,我們基于Q-Learning算法,讓Pacman先自行探索訓(xùn)練2000次。探索訓(xùn)練結(jié)束后,重新讓Pacman運行10次,測試這10次中Pacman成功吃完所有屏幕中所有豆子的次數(shù),10次中至少成功8次才算有效。
03 Q-Learning介紹
Q-Learning是Value-Based的強化學(xué)習(xí)算法,所以算法里面有一個非常重要的Value就是Q-Value,也是Q-Learning叫法的由來。這里重新把強化學(xué)習(xí)的五個基本部分介紹一下。
Agent(智能體): 強化學(xué)習(xí)訓(xùn)練的主體就是Agent:智能體。Pacman中就是這個張開大嘴的黃色扇形移動體。 Environment(環(huán)境): 整個游戲的大背景就是環(huán)境;Pacman中Agent、Ghost、豆子以及里面各個隔離板塊組成了整個環(huán)境。 State(狀態(tài)): 當(dāng)前 Environment和Agent所處的狀態(tài),因為Ghost一直在移動,豆子數(shù)目也在不停變化,Agent的位置也在不停變化,所以整個State處于變化中;State包含了Agent和Environment的狀態(tài)。 Action(行動): 基于當(dāng)前的State,Agent可以采取哪些action,比如向左or右,向上or下;Action是和State強掛鉤的,比如上圖中很多位置都是有隔板的,很明顯Agent在此State下是不能往左或者往右的,只能上下; Reward(獎勵): Agent在當(dāng)前State下,采取了某個特定的action后,會獲得環(huán)境的一定反饋就是Reward。這里面用Reward進行統(tǒng)稱,雖然Reward翻譯成中文是“獎勵”的意思,但其實強化學(xué)習(xí)中Reward只是代表環(huán)境給予的“反饋”,可能是獎勵也可能是懲罰。比如Pacman游戲中,Agent碰見了Ghost那環(huán)境給予的就是懲罰。
本次項目我們使用Q-Learning,所以在五個基本部分之外多了一個Q-Value。
Q-Value(State, Action): Q-value是由State和Action組合在一起決定的,這里的Value不是Reward,Reward是Value組成的一部分,具體如何生成Q-value下面會單獨介紹。實際的項目中我們會存儲一張表,我們叫它Q表。key是(state, action), value就是對應(yīng)的Q-value。每當(dāng)agent進入到某個state下時,我們就會來這張表進行查詢,選擇當(dāng)前State下對應(yīng)Value最大的Action,執(zhí)行這個action進入到下一個state,然后繼續(xù)查表選擇action,這樣循環(huán)。Q-Value的價值就在于指導(dǎo)Agent在不同state下選擇哪個action。
重點來了!!!如何知道整個訓(xùn)練過程中,Agent會遇到哪些State,每個State下面可以采取哪些Action。最最重要的是,如何將每個(State, Action)對應(yīng)的Q-value從訓(xùn)練中學(xué)習(xí)出來?
3.1 Bellman 方程
首先我們介紹一下貝爾曼方程,它是我們接下來介紹如何更新學(xué)習(xí)出Q-Value值的前提。貝爾曼方程是由美國一位叫做理查德-貝爾曼科學(xué)家發(fā)現(xiàn)并提出的。它的核心思想是:當(dāng)我們在特定時間點和狀態(tài)下去考慮下一步的決策,我們不僅僅要關(guān)注當(dāng)前決策立即產(chǎn)生的Reward,同時也要考慮當(dāng)前的決策衍生產(chǎn)生未來持續(xù)性的Reward。簡單地說就是既要考慮當(dāng)前收益最大化,還需要去關(guān)注未來持續(xù)的收益。
3.2 貝爾曼方程的Q-Value版
介紹完貝爾曼方程的思想后,在Q-learning算法中如何去更新Q-Value?

如上圖的表達(dá)式,我們更新Q(s,a)時不僅關(guān)注當(dāng)前收益也關(guān)注未來收益,當(dāng)前收益就是狀態(tài)變更環(huán)境立即反饋的reward,未來收益就是狀態(tài)變更后新狀態(tài)對應(yīng)可以采取的action中最大的Value,同時乘以折扣率γ。對機器學(xué)習(xí)不夠了解的,可能比較難以理解為什么要加一個學(xué)習(xí)率和折扣率,意義是什么?簡單來說學(xué)習(xí)率和折扣率的設(shè)置是希望學(xué)習(xí)更新過程緩慢一些,不希望某一步的學(xué)習(xí)跨度過大,從而對整個的學(xué)習(xí)結(jié)果造成比較大的偏差。因為Q(s,a)會更新迭代很多次,不能因為某一次的學(xué)習(xí)對最終的Q-value產(chǎn)生非常大的影響。
下圖是簡版的Q-Learning算法闡述:

04 Q-Learning實戰(zhàn)
介紹完Q-Learning算法正式進入Python實戰(zhàn),下面是實戰(zhàn)用的代碼壓縮包。(有需要的伙伴可公眾號后臺回復(fù)日期「20211212」下載)
4.1 預(yù)熱
首先我們先感受一下Pacman這個游戲,通過人工指揮和隨機運動,觀察一下整個實驗的效果。
手動指揮: 首先進入該文件的工作路徑,cd /Users/賬戶名/Desktop/pacman,執(zhí)行命令:python pacman.py ;就會看到下圖,通過電腦鍵盤的上下左右鍵,就可以指揮Pacman行動了。
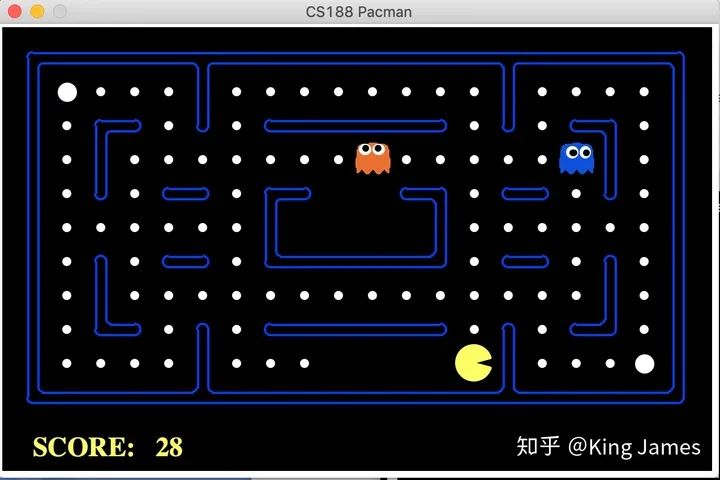
我們讓 Pacman采取隨機策略玩一遍游戲。
4.2 Q-Learning算法訓(xùn)練
現(xiàn)在我們使用Q-Learning算法來訓(xùn)練Pacman,本次Project編寫的代碼都在mlLearningAgents.py文件中,我們在該文件里面編寫代碼。
(1)整體思路
因為本次Pacman Project項目中我們重點在于應(yīng)用Q-learning算法去進行訓(xùn)練,指導(dǎo)Agent行動。所以項目中有很多其他現(xiàn)成的接口我們都是直接用的。比如
State:game.py文件已經(jīng)將如何獲取Agent當(dāng)前的State定義成了Class,直接引用即可; Action:game.py文件已經(jīng)將Agent在當(dāng)前State可以采取的Action定義成了Class,直接引用即可;(感興趣的同學(xué)可以自己打開文件查看代碼,核心就是建立一個坐標(biāo)系,然后確定擋板、Ghost、豆子、Agent的位置,然后進行判斷和數(shù)學(xué)表達(dá)。) 參數(shù)設(shè)置:學(xué)習(xí)率alpha我們設(shè)置為0.2,折扣率gamma設(shè)置為0.8,最終訓(xùn)練完我們讓Pacman運行numTraining=10次查看效果,同時這里面有一個探索率epsilon = 0.05。這就是上一篇介紹的EE問題,我們不能光讓Agent去執(zhí)行Q-value最大的action,同時我們也需要讓Pacman有一定的探索。

(2) Q-value表
因為最開始我們無從得知Pacman會經(jīng)歷哪些狀態(tài)State,以及采取哪些Action,所以我們最開始設(shè)置一個Q-value的空表,將訓(xùn)練中Pacman經(jīng)歷過的狀態(tài)State,以及執(zhí)行的Action,及最終學(xué)習(xí)產(chǎn)出的Q-value都保存在此張表里。

(3) 選擇Best Move
定義一個Class,在State確認(rèn)的情況下,首先找到最大的Q-value是多少。
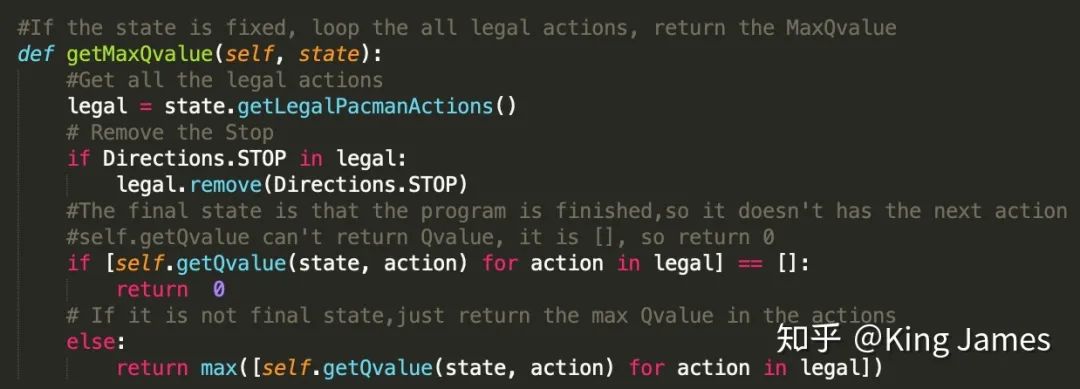
然后找到該Q-value對應(yīng)的Action:
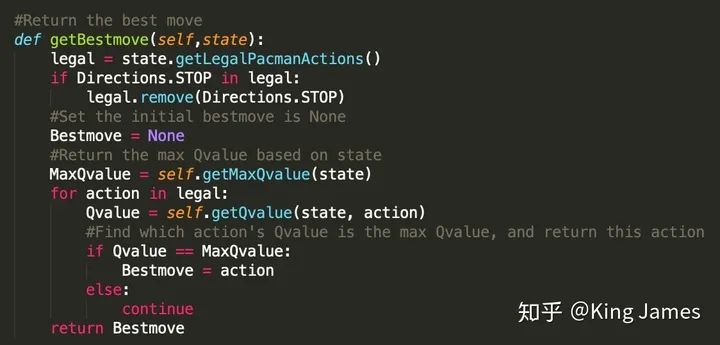
(GetLegalPAcmanActions即為獲取當(dāng)前state下,Agent可以執(zhí)行的所有合理的action的類,文件里現(xiàn)成的類)
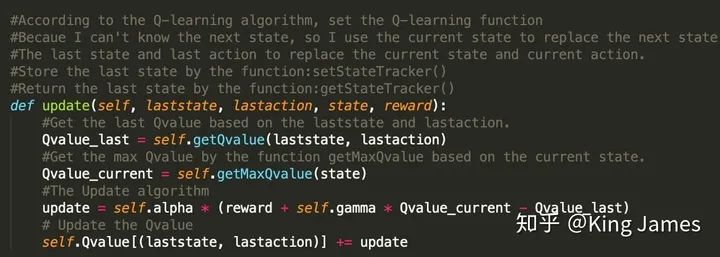
(4) Update Q-value
以下為更新Q-value的表達(dá)式,這里面有一個非常細(xì)節(jié)的地方。Pacman最開始運動的第一步的時候,我們是無法知曉下一步的State是什么的,源文件提供的類只能獲取當(dāng)前的State。但當(dāng)Pacman從當(dāng)前State倒推,我們是知道上一個State是什么的,因為Pacman剛剛經(jīng)歷過,只要我們將上一個State記錄下來即可。所以整個的更新表達(dá)式邏輯變?yōu)榱擞卯?dāng)前的State去更新上一步的(State,Action)對應(yīng)的Q-value。該思路是解決本問題的關(guān)鍵。
(5) 讓Agent運動起來
最后就是指導(dǎo)Pacman行動了,這里面存在大量的狀態(tài)和動作的記錄,我們需要將每一步經(jīng)歷的State和采取的Action都保存進對應(yīng)的Table中。同時這里面還有一個細(xì)節(jié),就是Reward的設(shè)置,一直沒有提到從一個State變?yōu)榱硪粋€State如何設(shè)置Reward。Pacman項目中,我們可以取巧的使用項目中現(xiàn)有的Pacman每行動一步Score發(fā)生的變化作為Reward,兩個狀態(tài)變化時Score的差值我們認(rèn)為就是Reward,這一步為我們節(jié)省了大量設(shè)置Reward的功夫。如果想自己設(shè)置Reward邏輯就是Pacman采取的行動離豆子越近Reward越多,離Ghost越近Reward越少的
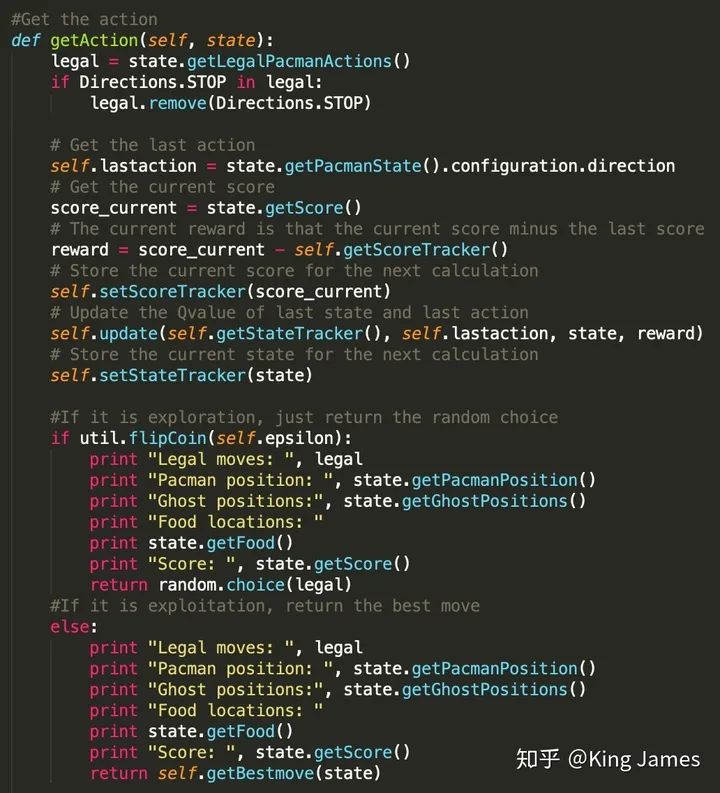
訓(xùn)練時Pacman行動的策略一部分是探索時的Random choice,一部分是利用時的Best Move。探索比例前面參數(shù)設(shè)置已經(jīng)提到0.05。以上Print的部分,是訓(xùn)練時我們打印每一步的訓(xùn)練結(jié)果。
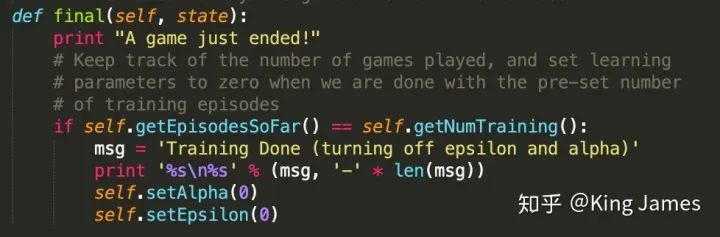
最后訓(xùn)練完以后,我們打印一條message,進行一下標(biāo)記
正式訓(xùn)練我們還是在之前的工作路徑下執(zhí)行如下命令:
python pacman.py -p QLearnAgent -x 2000 -n 2010 -l smallGrid
這里面QLearnAgent就是調(diào)用我們此次算法的類,2000次是訓(xùn)練次數(shù),2010-2000=10,10即為我們測試的次數(shù)。smallGrid是我們此次測試和訓(xùn)練僅使用Pacman的小界面,不使用大的界面進行訓(xùn)練,因為大界面State太多,訓(xùn)練時間過長,為了更快完成實驗看到效果我們在小的游戲界面上進行實驗。
下圖是訓(xùn)練時打印的message;
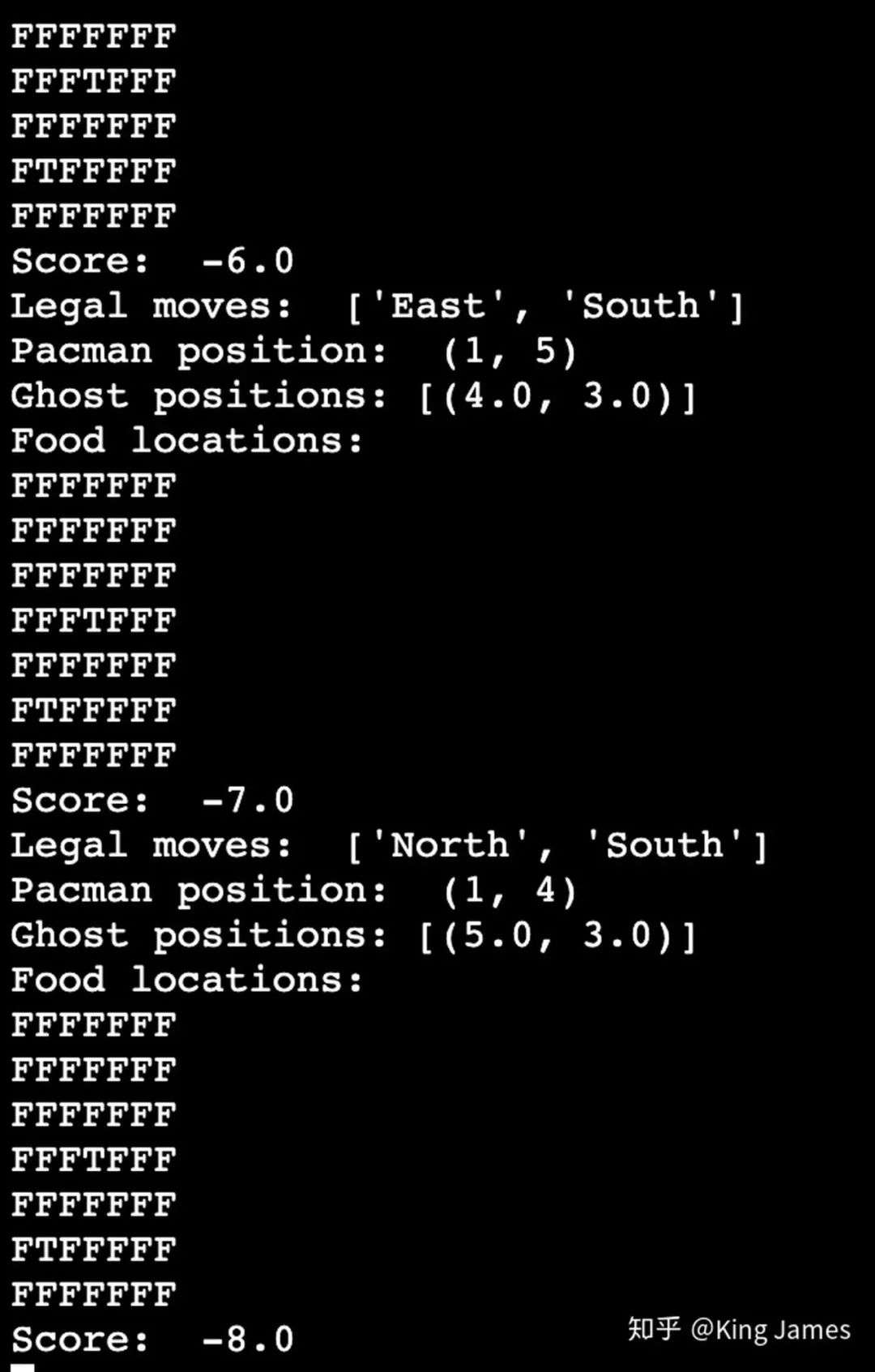
下圖就是最終測試時Pacman的運行小界面smallgrid

最后這條就是統(tǒng)計的10次中,Pacman贏的次數(shù),我們可以看到有8次win,所以圓滿地完成了我們的實驗。

2000次訓(xùn)練對于SmallGrid界面是差不多的,大家也可以將SmallGrid改為MediumGrid,但是要大幅提升訓(xùn)練次數(shù),不然學(xué)習(xí)效果不明顯。大家自己跑起來吧~

King James
倫敦國王學(xué)院 數(shù)據(jù)科學(xué)碩士
知乎同名
往期精彩回顧