
文本生成圖像的技術(shù)演變
目前多模態(tài)任務(wù)成為行業(yè)熱點(diǎn),本文梳理了較為優(yōu)秀的多模態(tài)文本圖像模型:DALL·E、CLIP、GLIDE、DALL·E 2 (unCLIP)的模型框架、優(yōu)缺點(diǎn),及其迭代關(guān)系。


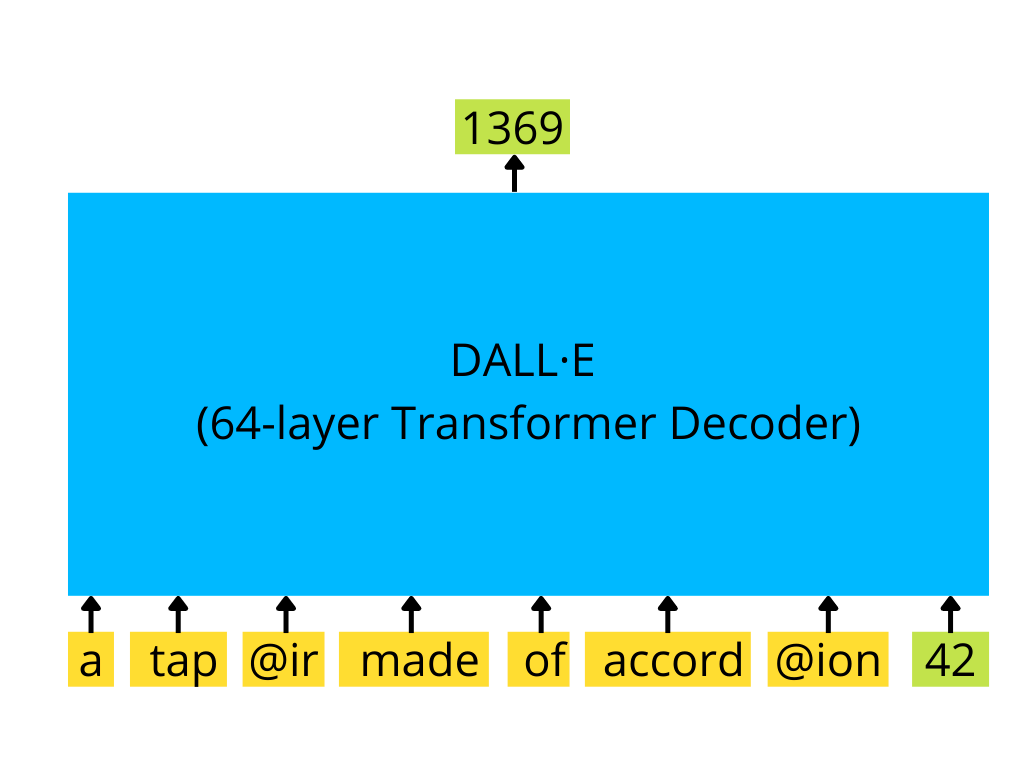

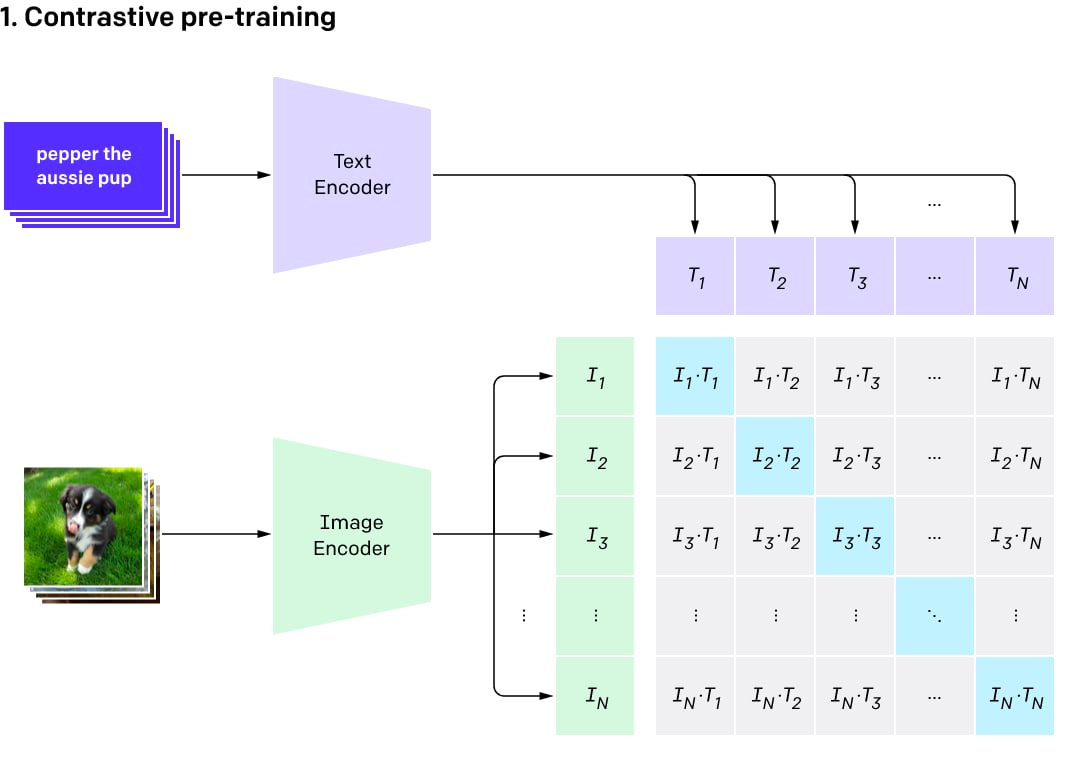
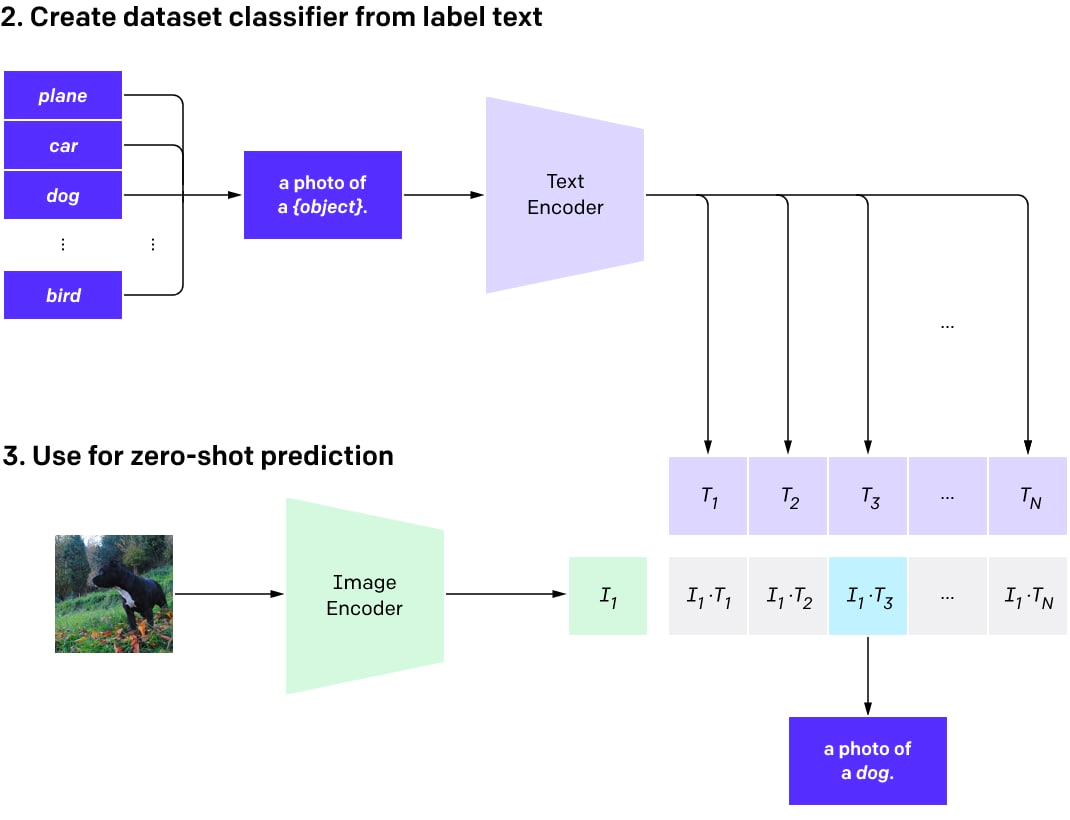



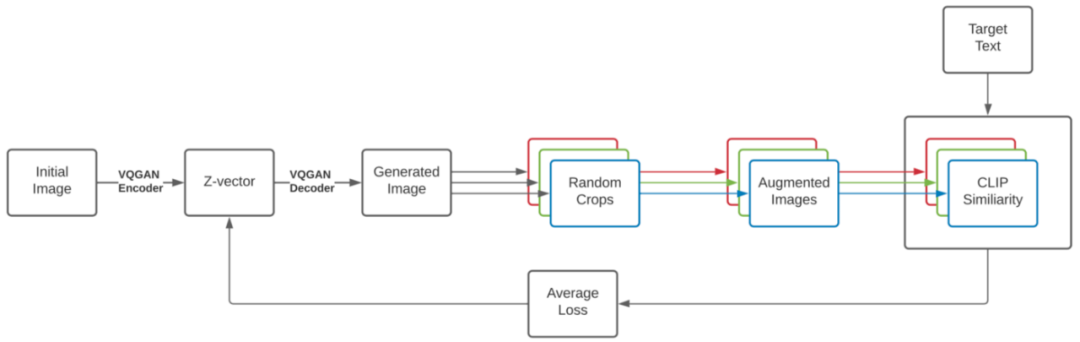



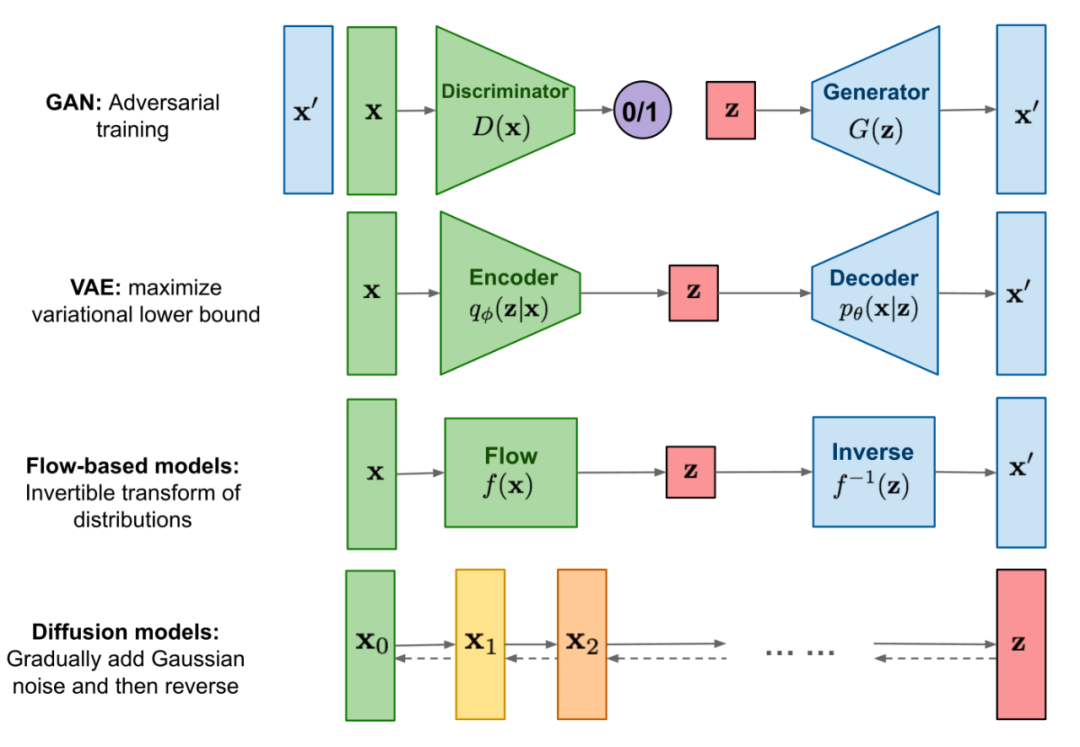







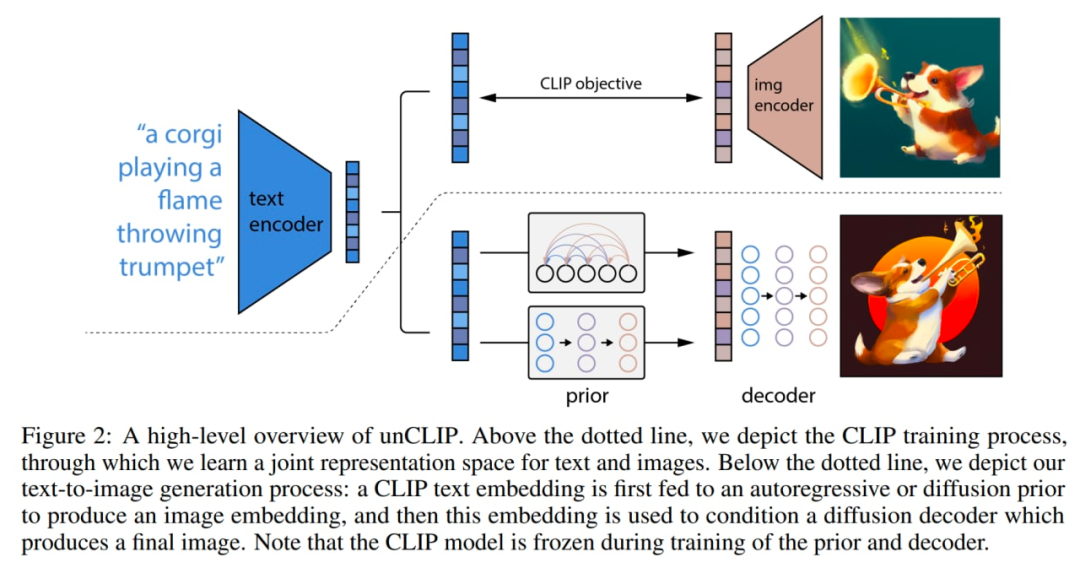
編碼的文本
CLIP 文本嵌入
擴(kuò)散時間步長的嵌入
噪聲 CLIP 圖像嵌入
最終的嵌入,其來自 Transformer 的輸出用于預(yù)測無噪聲 CLIP 圖像嵌入。
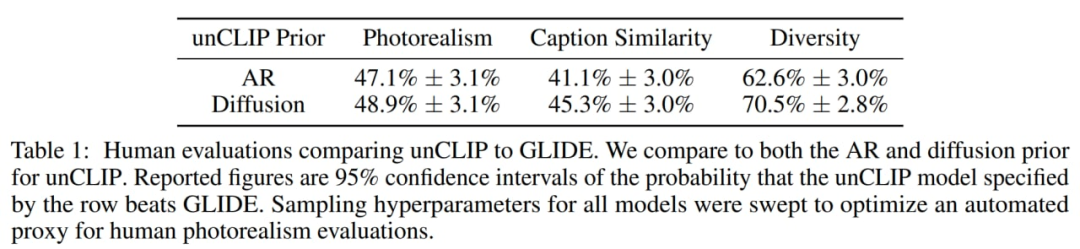




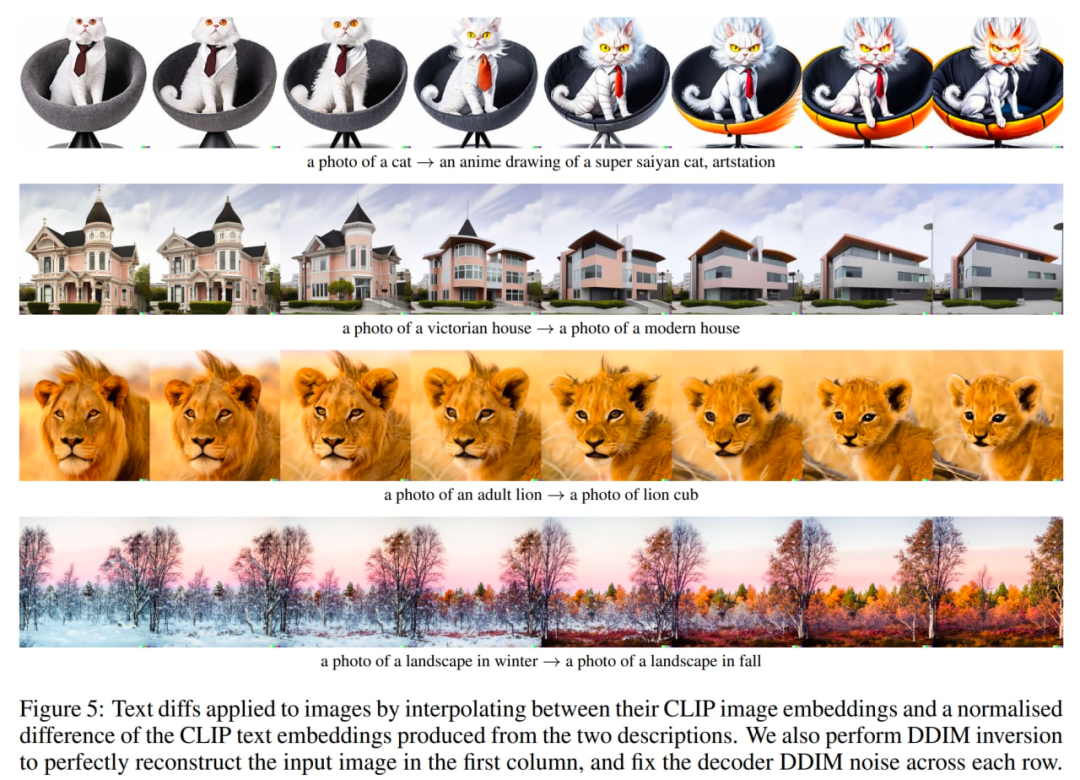




猜您喜歡:
 ?戳我,查看GAN的系列專輯~!
?戳我,查看GAN的系列專輯~!附下載 |?《可解釋的機(jī)器學(xué)習(xí)》中文版
附下載 |《TensorFlow 2.0 深度學(xué)習(xí)算法實戰(zhàn)》
附下載 |《計算機(jī)視覺中的數(shù)學(xué)方法》分享
《基于深度神經(jīng)網(wǎng)絡(luò)的少樣本學(xué)習(xí)綜述》
評論
圖片
表情