
【深度學(xué)習(xí)】常見優(yōu)化器的PyTorch實(shí)現(xiàn)
這里主要講不同常見優(yōu)化器代碼的實(shí)現(xiàn),以及在一個(gè)小數(shù)據(jù)集上做一個(gè)簡單的比較。
備注:pytorch需要升級到最新版本
其中,SGD和SGDM,還有Adam是pytorch自帶的優(yōu)化器,而RAdam是最近提出的一個(gè)說是Adam更強(qiáng)的優(yōu)化器,但是一般情況下真正的大佬還在用SGDM來做優(yōu)化器。
導(dǎo)入必要庫:
import torchimport torch.nn as nnimport torch.nn.functional as Fimport torch.optim as optimimport matplotlib.pyplot as pltimport torch.utils.data as Datafrom torch.optim.optimizer import Optimizerimport?math
主程序部分:
LR = 0.01BATCH_SIZE = 32EPOCH = 12# fake datasetx = torch.unsqueeze(torch.linspace(-1, 1, 300), dim=1)y = x.pow(2) + 0.1 * torch.normal(torch.zeros(*x.size()))torch_dataset = Data.TensorDataset(x, y)loader = Data.DataLoader(dataset=torch_dataset,batch_size=BATCH_SIZE,shuffle=True,num_workers=2)class Net(nn.Module):def __init__(self):self).__init__()= nn.Linear(1, 20)= nn.Linear(20, 1)def forward(self, x):x = F.relu(self.hidden(x))x = self.prediction(x)return xdef main():net_SGD = Net()net_Momentum = Net()net_Adam = Net()net_RAdam = Net()nets = [net_SGD, net_Momentum, net_Adam, net_RAdam]opt_SGD = optim.SGD(net_SGD.parameters(), lr=LR)opt_Momentum = optim.SGD(net_Momentum.parameters(), lr=LR, momentum=0.9)opt_Adam = optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.9, 0.99))opt_RAdam = RAdam(net_RAdam.parameters(),lr=LR,weight_decay=0)optimizers = [opt_SGD, opt_Momentum, opt_Adam, opt_RAdam]loss_func = nn.MSELoss()losses_his = [[], [], [], []]# trainingfor epoch in range(EPOCH)::', epoch)for step, (batch_x, batch_y) in enumerate(loader):b_x = batch_xb_y = batch_yfor net, opt, l_his in zip(nets, optimizers, losses_his):out = net(b_x)loss = loss_func(out, b_y)opt.zero_grad()loss.backward()opt.step()l_his.append(loss.item())labels = ['SGD', 'Momentum', 'Adam','RAdam']for i, l_his in enumerate(losses_his):label=labels[i])='best')plt.xlabel('Steps')plt.ylabel('Loss')0.2))plt.show()if __name__ == '__main__':main()
下圖是優(yōu)化器的對比:
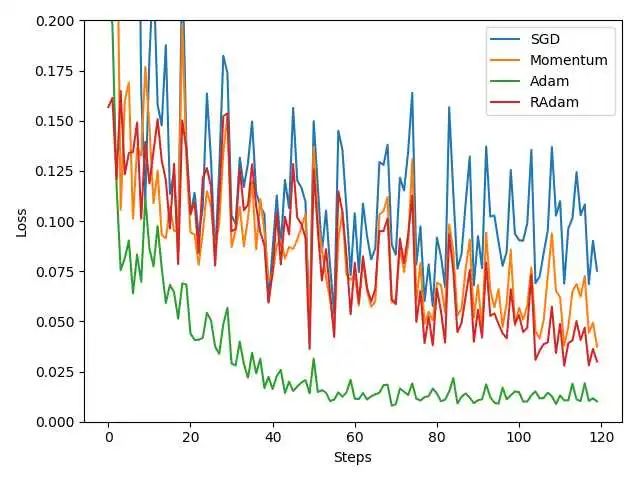
可以看出來,Adam的效果可以說是非常好的。然后SGDM其次,SGDM是大佬們經(jīng)常會使用的,所以在這里雖然看起來SGDM效果不如Adam,但是依然推薦在項(xiàng)目中,嘗試一下SGDM的效果。
往期精彩回顧
獲取一折本站知識星球優(yōu)惠券,復(fù)制鏈接直接打開:
https://t.zsxq.com/yFQV7am
本站qq群1003271085。
加入微信群請掃碼進(jìn)群:
評論
圖片
表情