
深度學(xué)習(xí)調(diào)參tricks總結(jié)!
尋找合適的學(xué)習(xí)率(learning rate)
學(xué)習(xí)率是一個(gè)非常非常重要的超參數(shù),這個(gè)參數(shù)呢,面對不同規(guī)模、不同batch-size、不同優(yōu)化方式、不同數(shù)據(jù)集,其最合適的值都是不確定的,我們無法光憑經(jīng)驗(yàn)來準(zhǔn)確地確定lr的值,我們唯一可以做的,就是在訓(xùn)練中不斷尋找最合適當(dāng)前狀態(tài)的學(xué)習(xí)率。
比如下圖利用fastai中的lr_find()函數(shù)尋找合適的學(xué)習(xí)率,根據(jù)下方的學(xué)習(xí)率-損失曲線得到此時(shí)合適的學(xué)習(xí)率為1e-2。
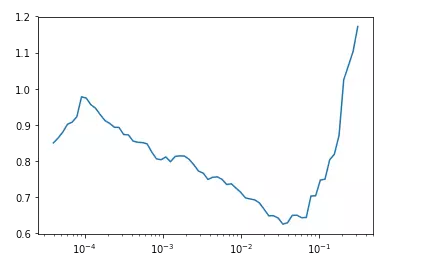
推薦一篇fastai首席設(shè)計(jì)師「Sylvain Gugger」的一篇博客:How Do You Find A Good Learning Rate[1]
以及相關(guān)的論文Cyclical Learning Rates for Training Neural Networks[2]。
learning-rate與batch-size的關(guān)系
一般來說,越大的batch-size使用越大的學(xué)習(xí)率。
原理很簡單,越大的batch-size意味著我們學(xué)習(xí)的時(shí)候,收斂方向的confidence越大,我們前進(jìn)的方向更加堅(jiān)定,而小的batch-size則顯得比較雜亂,毫無規(guī)律性,因?yàn)橄啾扰未蟮臅r(shí)候,批次小的情況下無法照顧到更多的情況,所以需要小的學(xué)習(xí)率來保證不至于出錯(cuò)。
可以看下圖損失Loss與學(xué)習(xí)率Lr的關(guān)系:

在顯存足夠的條件下,最好采用較大的batch-size進(jìn)行訓(xùn)練,找到合適的學(xué)習(xí)率后,可以加快收斂速度。
另外,較大的batch-size可以避免batch normalization出現(xiàn)的一些小問題,參考如下Pytorch庫Issue[3]
權(quán)重初始化
權(quán)重初始化相比于其他的trick來說在平常使用并不是很頻繁。
因?yàn)榇蟛糠秩耸褂玫哪P投际穷A(yù)訓(xùn)練模型,使用的權(quán)重都是在大型數(shù)據(jù)集上訓(xùn)練好的模型,當(dāng)然不需要自己去初始化權(quán)重了。只有沒有預(yù)訓(xùn)練模型的領(lǐng)域會自己初始化權(quán)重,或者在模型中去初始化神經(jīng)網(wǎng)絡(luò)最后那幾個(gè)全連接層的權(quán)重。
常用的權(quán)重初始化算法是「kaiming_normal」或者「xavier_normal」。
相關(guān)論文:
Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification[4] Understanding the difficulty of training deep feedforward neural networks[5] Xavier初始化論文[6] He初始化論文[7]
不初始化可能會減慢收斂速度,影響收斂效果。
以下 為網(wǎng)絡(luò)的輸入大小, 為網(wǎng)絡(luò)的輸出大小, 為 或
uniform均勻分布初始化:
Xavier初始法,適用于普通激活函數(shù)(tanh, sigmoid):
He初始化,適用于ReLU:
normal高斯分布初始化, 其中stdev為高斯分布的標(biāo)準(zhǔn)差,均值設(shè)為0:
Xavier初始法,適用于普通激活函數(shù) (tanh,sigmoid):
He初始化,適用于ReLU:
svd初始化:對RNN有比較好的效果。參考論文:https://arxiv.org/abs/1312.6120[8]
dropout
dropout是指在深度學(xué)習(xí)網(wǎng)絡(luò)的訓(xùn)練過程中,對于神經(jīng)網(wǎng)絡(luò)單元,按照一定的概率將其暫時(shí)從網(wǎng)絡(luò)中丟棄。注意是「暫時(shí)」,對于隨機(jī)梯度下降來說,由于是隨機(jī)丟棄,故而每一個(gè)mini-batch都在訓(xùn)練不同的網(wǎng)絡(luò)。
Dropout類似于bagging ensemble減少variance。也就是投通過投票來減少可變性。通常我們在全連接層部分使用dropout,在卷積層則不使用。但「dropout」并不適合所有的情況,不要無腦上Dropout。
Dropout一般適合于全連接層部分,而卷積層由于其參數(shù)并不是很多,所以不需要dropout,加上的話對模型的泛化能力并沒有太大的影響。
我們一般在網(wǎng)絡(luò)的最開始和結(jié)束的時(shí)候使用全連接層,而hidden layers則是網(wǎng)絡(luò)中的卷積層。所以一般情況,在全連接層部分,采用較大概率的dropout而在卷積層采用低概率或者不采用dropout。
數(shù)據(jù)集處理
主要有「數(shù)據(jù)篩選」 以及 「數(shù)據(jù)增強(qiáng)」
fastai中的圖像增強(qiáng)技術(shù)為什么相對比較好[9]
難例挖掘 hard-negative-mining
分析模型難以預(yù)測正確的樣本,給出針對性方法。
多模型融合
Ensemble是論文刷結(jié)果的終極核武器,深度學(xué)習(xí)中一般有以下幾種方式
同樣的參數(shù),不同的初始化方式 不同的參數(shù),通過cross-validation,選取最好的幾組 同樣的參數(shù),模型訓(xùn)練的不同階段,即不同迭代次數(shù)的模型。 不同的模型,進(jìn)行線性融合. 例如RNN和傳統(tǒng)模型.
提高模型性能和魯棒性大法:probs融合 和 投票法。
假設(shè)這里有model 1, model 2, model 3,可以這樣融合:
1. model1 probs + model2 probs + model3 probs ==> final label
2. model1 label , model2 label , model3 label ==> voting ==> final label
3. model1_1 probs + ... + model1_n probs ==> mode1 label, model2 label與model3獲取的label方式與1相同? ==> voting ==> final label
第三個(gè)方式的啟發(fā)來源于,如果一個(gè)model的隨機(jī)種子沒有固定,多次預(yù)測得到的結(jié)果可能不同。
以上方式的效果要根據(jù)label個(gè)數(shù),數(shù)據(jù)集規(guī)模等特征具體問題具體分析,表現(xiàn)可能不同,方式無非是probs融合和投票法的單獨(dú)使用or結(jié)合。
差分學(xué)習(xí)率與遷移學(xué)習(xí)
首先說下遷移學(xué)習(xí),遷移學(xué)習(xí)是一種很常見的深度學(xué)習(xí)技巧,我們利用很多預(yù)訓(xùn)練的經(jīng)典模型直接去訓(xùn)練我們自己的任務(wù)。雖然說領(lǐng)域不同,但是在學(xué)習(xí)權(quán)重的廣度方面,兩個(gè)任務(wù)之間還是有聯(lián)系的。
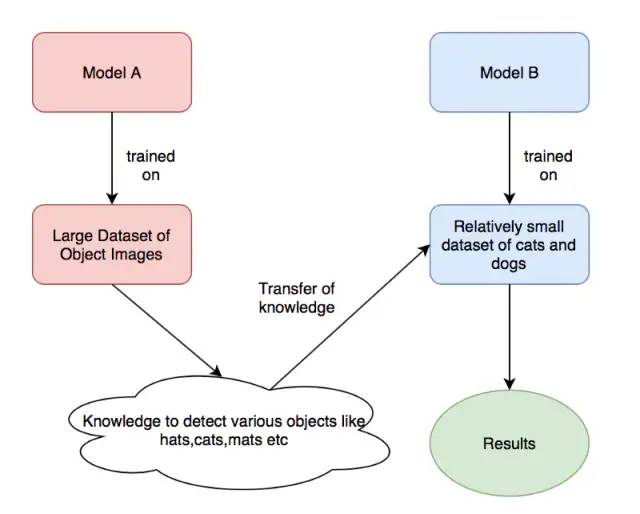
由上圖,我們拿來「model A」訓(xùn)練好的模型權(quán)重去訓(xùn)練我們自己的模型權(quán)重(「Model B」),其中,modelA可能是ImageNet的預(yù)訓(xùn)練權(quán)重,而ModelB則是我們自己想要用來識別貓和狗的預(yù)訓(xùn)練權(quán)重。
那么差分學(xué)習(xí)率和遷移學(xué)習(xí)有什么關(guān)系呢?我們直接拿來其他任務(wù)的訓(xùn)練權(quán)重,在進(jìn)行optimize的時(shí)候,如何選擇適當(dāng)?shù)膶W(xué)習(xí)率是一個(gè)很重要的問題。
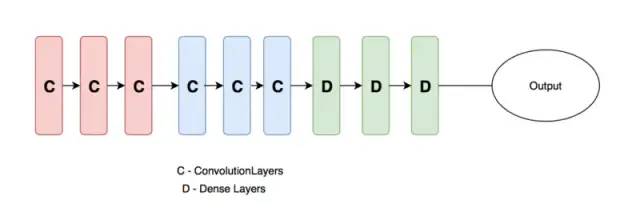
一般地,我們設(shè)計(jì)的神經(jīng)網(wǎng)絡(luò)(如下圖)一般分為三個(gè)部分,輸入層,隱含層和輸出層,隨著層數(shù)的增加,神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)到的特征越抽象。因此,下圖中的卷積層和全連接層的學(xué)習(xí)率也應(yīng)該設(shè)置的不一樣,一般來說,卷積層設(shè)置的學(xué)習(xí)率應(yīng)該更低一些,而全連接層的學(xué)習(xí)率可以適當(dāng)提高。
這就是差分學(xué)習(xí)率的意思,在不同的層設(shè)置不同的學(xué)習(xí)率,可以提高神經(jīng)網(wǎng)絡(luò)的訓(xùn)練效果,具體的介紹可以查看下方的連接。
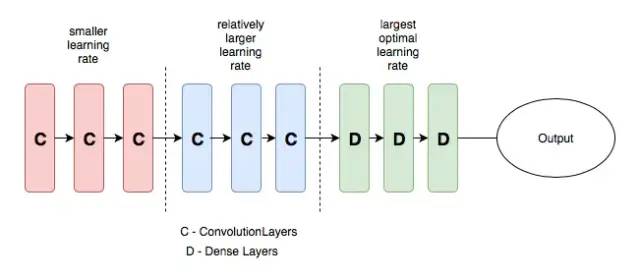
上面的示例圖來自:towardsdatascience.com/transfer-le…[10]
余弦退火(cosine annealing)和熱重啟的隨機(jī)梯度下降
「余弦」就是類似于余弦函數(shù)的曲線,「退火」就是下降,「余弦退火」就是學(xué)習(xí)率類似余弦函數(shù)慢慢下降。
「熱重啟」就是在學(xué)習(xí)的過程中,「學(xué)習(xí)率」慢慢下降然后突然再「回彈」(重啟)然后繼續(xù)慢慢下降。
兩個(gè)結(jié)合起來就是下方的學(xué)習(xí)率變化圖: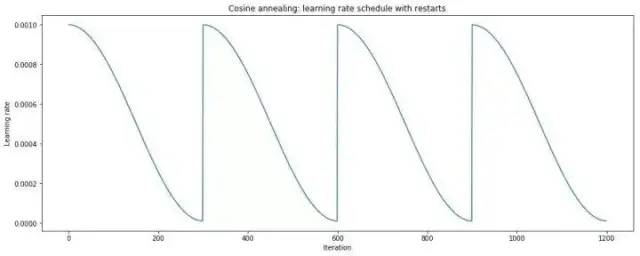
更多詳細(xì)的介紹可以查看知乎機(jī)器學(xué)習(xí)算法如何調(diào)參?這里有一份神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)速率設(shè)置指南[11]
以及相關(guān)論文SGDR: Stochastic Gradient Descent with Warm Restarts[12]
嘗試過擬合一個(gè)小數(shù)據(jù)集
這是一個(gè)經(jīng)典的小trick了,但是很多人并不這樣做,可以嘗試一下。
關(guān)閉正則化/隨機(jī)失活/數(shù)據(jù)擴(kuò)充,使用訓(xùn)練集的一小部分,讓神經(jīng)網(wǎng)絡(luò)訓(xùn)練幾個(gè)周期。確保可以實(shí)現(xiàn)零損失,如果沒有,那么很可能什么地方出錯(cuò)了。
多尺度訓(xùn)練
多尺度訓(xùn)練是一種「直接有效」的方法,通過輸入不同尺度的圖像數(shù)據(jù)集,因?yàn)樯窠?jīng)網(wǎng)絡(luò)卷積池化的特殊性,這樣可以讓神經(jīng)網(wǎng)絡(luò)充分地學(xué)習(xí)不同分辨率下圖像的特征,可以提高機(jī)器學(xué)習(xí)的性能。
也可以用來處理過擬合效應(yīng),在圖像數(shù)據(jù)集不是特別充足的情況下,可以先訓(xùn)練小尺寸圖像,然后增大尺寸并再次訓(xùn)練相同模型,這樣的思想在Yolo-v2的論文中也提到過:

需要注意的是:多尺度訓(xùn)練并不是適合所有的深度學(xué)習(xí)應(yīng)用,多尺度訓(xùn)練可以算是特殊的數(shù)據(jù)增強(qiáng)方法,在圖像大小這一塊做了調(diào)整。如果有可能最好利用可視化代碼將多尺度后的圖像近距離觀察一下,「看看多尺度會對圖像的整體信息有沒有影響」,如果對圖像信息有影響的話,這樣直接訓(xùn)練的話會誤導(dǎo)算法導(dǎo)致得不到應(yīng)有的結(jié)果。
Cross Validation 交叉驗(yàn)證
在李航的統(tǒng)計(jì)學(xué)方法中說到,交叉驗(yàn)證往往是對實(shí)際應(yīng)用中「數(shù)據(jù)不充足」而采用的,基本目的就是重復(fù)使用數(shù)據(jù)。在平常中我們將所有的數(shù)據(jù)分為訓(xùn)練集和驗(yàn)證集就已經(jīng)是簡單的交叉驗(yàn)證了,可以稱為1折交叉驗(yàn)證。「注意,交叉驗(yàn)證和測試集沒關(guān)系,測試集是用來衡量我們的算法標(biāo)準(zhǔn)的,不參與到交叉驗(yàn)證中來。」
交叉驗(yàn)證只針對訓(xùn)練集和驗(yàn)證集。
交叉驗(yàn)證是Kaggle比賽中特別推崇的一種技巧,我們經(jīng)常使用的是5-折(5-fold)交叉驗(yàn)證,將訓(xùn)練集分成5份,隨機(jī)挑一份做驗(yàn)證集其余為訓(xùn)練集,循環(huán)5次,這種比較常見計(jì)算量也不是很大。還有一種叫做leave-one-out cross validation留一交叉驗(yàn)證,這種交叉驗(yàn)證就是n-折交叉,n表示數(shù)據(jù)集的容量,這種方法只適合數(shù)據(jù)量比較小的情況,計(jì)算量非常大的情況很少用到這種方法。
吳恩達(dá)有一節(jié)課The nuts and bolts of building applications using deep learning[13]中也提到了。
優(yōu)化算法
按理說不同的優(yōu)化算法適合于不同的任務(wù),不過我們大多數(shù)采用的優(yōu)化算法還是是adam和SGD+monmentum。
Adam 可以解決一堆奇奇怪怪的問題(有時(shí) loss 降不下去,換 Adam 瞬間就好了),也可以帶來一堆奇奇怪怪的問題(比如單詞詞頻差異很大,當(dāng)前 batch 沒有的單詞的詞向量也被更新;再比如Adam和L2正則結(jié)合產(chǎn)生的復(fù)雜效果)。用的時(shí)候要膽大心細(xì),萬一遇到問題找各種魔改 Adam(比如 MaskedAdam[14], AdamW 啥的)搶救。
但看一些博客說adam的相比SGD,收斂快,但泛化能力差,更優(yōu)結(jié)果似乎需要精調(diào)SGD。
adam,adadelta等, 在小數(shù)據(jù)上,我這里實(shí)驗(yàn)的效果不如sgd, sgd收斂速度會慢一些,但是最終收斂后的結(jié)果,一般都比較好。
如果使用sgd的話,可以選擇從1.0或者0.1的學(xué)習(xí)率開始,隔一段時(shí)間,在驗(yàn)證集上檢查一下,如果cost沒有下降,就對學(xué)習(xí)率減半. 我看過很多論文都這么搞,我自己實(shí)驗(yàn)的結(jié)果也很好. 當(dāng)然,也可以先用ada系列先跑,最后快收斂的時(shí)候,更換成sgd繼續(xù)訓(xùn)練.同樣也會有提升.據(jù)說adadelta一般在分類問題上效果比較好,adam在生成問題上效果比較好。
adam收斂雖快但是得到的解往往沒有sgd+momentum得到的解更好,如果不考慮時(shí)間成本的話還是用sgd吧。
adam是不需要特別調(diào)lr,sgd要多花點(diǎn)時(shí)間調(diào)lr和initial weights。
數(shù)據(jù)預(yù)處理方式
zero-center ,這個(gè)挺常用的.
PCA whitening,這個(gè)用的比較少.
訓(xùn)練技巧
要做梯度歸一化,即算出來的梯度除以minibatch size clip c(梯度裁剪): 限制最大梯度,其實(shí)是value = sqrt(w1^2+w2^2….),如果value超過了閾值,就算一個(gè)衰減系系數(shù),讓value的值等于閾值: 5,10,15 dropout對小數(shù)據(jù)防止過擬合有很好的效果,值一般設(shè)為0.5 小數(shù)據(jù)上dropout+sgd在我的大部分實(shí)驗(yàn)中,效果提升都非常明顯.因此可能的話,建議一定要嘗試一下。 dropout的位置比較有講究, 對于RNN,建議放到輸入->RNN與RNN->輸出的位置.關(guān)于RNN如何用dropout,可以參考這篇論文:http://arxiv.org/abs/1409.2329[15] 除了gate之類的地方,需要把輸出限制成0-1之外,盡量不要用sigmoid,可以用tanh或者relu之類的激活函數(shù). sigmoid函數(shù)在-4到4的區(qū)間里,才有較大的梯度。之外的區(qū)間,梯度接近0,很容易造成梯度消失問題。 輸入0均值,sigmoid函數(shù)的輸出不是0均值的。 rnn的dim和embdding size,一般從128上下開始調(diào)整. batch size,一般從128左右開始調(diào)整. batch size合適最重要,并不是越大越好. word2vec初始化,在小數(shù)據(jù)上,不僅可以有效提高收斂速度,也可以可以提高結(jié)果. 盡量對數(shù)據(jù)做shuffle LSTM 的forget gate的bias,用1.0或者更大的值做初始化,可以取得更好的結(jié)果,來自這篇論文:http://jmlr.org/proceedings/papers/v37/jozefowicz15.pdf[16], 我這里實(shí)驗(yàn)設(shè)成1.0,可以提高收斂速度.實(shí)際使用中,不同的任務(wù),可能需要嘗試不同的值. Batch Normalization據(jù)說可以提升效果,參考論文:Accelerating Deep Network Training by Reducing Internal Covariate Shift 如果你的模型包含全連接層(MLP),并且輸入和輸出大小一樣,可以考慮將MLP替換成Highway Network,我嘗試對結(jié)果有一點(diǎn)提升,建議作為最后提升模型的手段,原理很簡單,就是給輸出加了一個(gè)gate來控制信息的流動,詳細(xì)介紹請參考論文: http://arxiv.org/abs/1505.00387[17] 來自@張馨宇的技巧:一輪加正則,一輪不加正則,反復(fù)進(jìn)行。 在數(shù)據(jù)集很大的情況下,一上來就跑全量數(shù)據(jù)。建議先用 1/100、1/10 的數(shù)據(jù)跑一跑,對模型性能和訓(xùn)練時(shí)間有個(gè)底,外推一下全量數(shù)據(jù)到底需要跑多久。在沒有足夠的信心前不做大規(guī)模實(shí)驗(yàn)。 subword 總是會很穩(wěn)定地漲點(diǎn),只管用就對了。 GPU 上報(bào)錯(cuò)時(shí)盡量放在 CPU 上重跑,錯(cuò)誤信息更友好。例如 GPU 報(bào) "ERROR:tensorflow:Model diverged with loss = NaN" 其實(shí)很有可能是輸入 ID 超出了 softmax 詞表的范圍。 在確定初始學(xué)習(xí)率的時(shí)候,從一個(gè)很小的值(例如 1e-7)開始,然后每一步指數(shù)增大學(xué)習(xí)率(例如擴(kuò)大1.05 倍)進(jìn)行訓(xùn)練。訓(xùn)練幾百步應(yīng)該能觀察到損失函數(shù)隨訓(xùn)練步數(shù)呈對勾形,選擇損失下降最快那一段的學(xué)習(xí)率即可。 補(bǔ)充一個(gè)rnn trick,仍然是不考慮時(shí)間成本的情況下,batch size=1是一個(gè)很不錯(cuò)的regularizer, 起碼在某些task上,這也有可能是很多人無法復(fù)現(xiàn)alex graves實(shí)驗(yàn)結(jié)果的原因之一,因?yàn)樗偸前裝atch size設(shè)成1。 注意實(shí)驗(yàn)的可復(fù)現(xiàn)性和一致性,注意養(yǎng)成良好的實(shí)驗(yàn)記錄習(xí)慣 ==> 不然如何分析出實(shí)驗(yàn)結(jié)論。 超參上,learning rate 最重要,推薦了解 cosine learning rate 和 cyclic learning rate,其次是 batchsize 和 weight decay。當(dāng)你的模型還不錯(cuò)的時(shí)候,可以試著做數(shù)據(jù)增廣和改損失函數(shù)錦上添花了。
參考:
關(guān)于訓(xùn)練神經(jīng)網(wǎng)路的諸多技巧Tricks\(完全總結(jié)版\)[18] 你有哪些deep learning(rnn、cnn)調(diào)參的經(jīng)驗(yàn)?[19] Bag of Tricks for Image Classification with Convolutional Neural Networks[20],trick 合集 1。 Must Know Tips/Tricks in Deep Neural Networks[21],trick 合集 2。 33條神經(jīng)網(wǎng)絡(luò)訓(xùn)練秘技[22],trick 合集 3。 26秒單GPU訓(xùn)練CIFAR10[23],工程實(shí)踐。 Batch Normalization[24],雖然玄學(xué),但是養(yǎng)活了很多煉丹師。 Searching for Activation Functions[25],swish 激活函數(shù)。
本文參考資料
How Do You Find A Good Learning Rate: https://sgugger.github.io/how-do-you-find-a-good-learning-rate.html
[2]Cyclical Learning Rates for Training Neural Networks: https://arxiv.org/abs/1506.01186
[3]Pytorch庫Issue: https://github.com/pytorch/pytorch/issues/4534
[4]Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification: https://www.cv-foundation.org/openaccess/content_iccv_2015/papers/He_Delving_Deep_into_ICCV_2015_paper.pdf
[5]Understanding the difficulty of training deep feedforward neural networks: http://proceedings.mlr.press/v9/glorot10a.html
[6]Xavier初始化論文: http://proceedings.mlr.press/v9/glorot10a/glorot10a.pdf
[7]He初始化論文: https://arxiv.org/abs/1502.01852
[8]https://arxiv.org/abs/1312.6120: https://link.zhihu.com/?target=https%3A//arxiv.org/abs/1312.6120
[9]fastai中的圖像增強(qiáng)技術(shù)為什么相對比較好: https://oldpan.me/archives/fastai-1-0-quick-study
[10]towardsdatascience.com/transfer-le…: https://towardsdatascience.com/transfer-learning-using-differential-learning-rates-638455797f00
[11]機(jī)器學(xué)習(xí)算法如何調(diào)參?這里有一份神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)速率設(shè)置指南: https://zhuanlan.zhihu.com/p/34236769
[12]SGDR: Stochastic Gradient Descent with Warm Restarts: https://arxiv.org/abs/1608.03983
[13]The nuts and bolts of building applications using deep learning: https://www.youtube.com/watch?v=F1ka6a13S9I
[14]MaskedAdam: https://www.zhihu.com/question/265357659/answer/580469438
[15]http://arxiv.org/abs/1409.2329: https://link.zhihu.com/?target=http%3A//arxiv.org/abs/1409.2329
[16]http://jmlr.org/proceedings/papers/v37/jozefowicz15.pdf: https://link.zhihu.com/?target=http%3A//jmlr.org/proceedings/papers/v37/jozefowicz15.pdf
[17]http://arxiv.org/abs/1505.00387: https://link.zhihu.com/?target=http%3A//arxiv.org/abs/1505.00387
[18]關(guān)于訓(xùn)練神經(jīng)網(wǎng)路的諸多技巧Tricks(完全總結(jié)版): https://juejin.im/post/5be5b0d7e51d4543b365da51
[19]你有哪些deep learning(rnn、cnn)調(diào)參的經(jīng)驗(yàn)?: https://www.zhihu.com/question/41631631
[20]Bag of Tricks for Image Classification with Convolutional Neural Networks: https://link.zhihu.com/?target=https%3A//arxiv.org/abs/1812.01187
[21]Must Know Tips/Tricks in Deep Neural Networks: https://link.zhihu.com/?target=http%3A//lamda.nju.edu.cn/weixs/project/CNNTricks/CNNTricks.html
[22]33條神經(jīng)網(wǎng)絡(luò)訓(xùn)練秘技: https://zhuanlan.zhihu.com/p/63841572
[23]26秒單GPU訓(xùn)練CIFAR10: https://zhuanlan.zhihu.com/p/79020733
[24]Batch Normalization: https://link.zhihu.com/?target=https%3A//arxiv.org/abs/1502.03167%3Fcontext%3Dcs
[25]Searching for Activation Functions: https://link.zhihu.com/?target=https%3A//arxiv.org/abs/1710.05941