
MySQL為什么選擇B+樹存儲索引
作者:大春777
鏈接:https://www.jianshu.com/p/99aabf9611a3
為什么加索引?
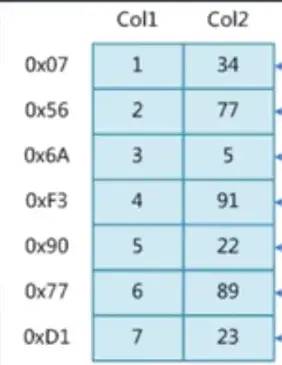
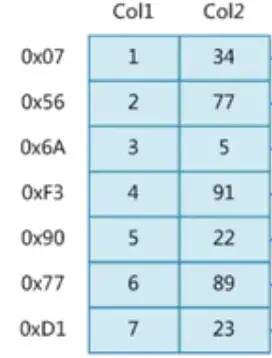
如果上面的表,我們執(zhí)行SQL語句
select * from table where Col2=89;
這樣就會造成全表掃描,從第一行讀取到倒數(shù)第二行,然后拿到這個89這個對應的值的位置,這樣就做了6次才找到對應的值,但是加上索引就不一樣了,接下來介紹索引是什么?
MySQL的索引是什么:
索引是幫助MySQL高效獲取數(shù)據(jù)的排好序的數(shù)據(jù)結構
索引的數(shù)據(jù)結構包括:
二叉樹
紅黑樹
Hash表
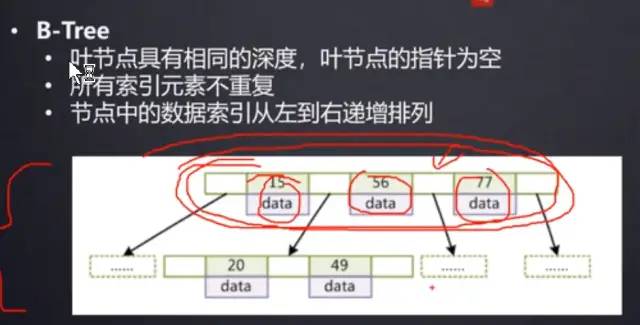
B-Tree
索引存儲方式
索引存儲是按照KV方式進行存儲的,key是這個索引元素,比如34,77等,value是這個索引在磁盤上面的文件地址,索引也是落地到磁盤上面的,因為數(shù)據(jù)時落在磁盤上面的,然后根據(jù)這個key對應的value去磁盤上面找到對應的值,然后輸出.
數(shù)據(jù)使用索引的存儲方式
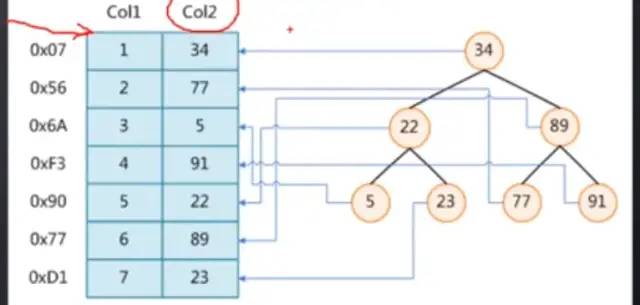
這樣是不是就很快了
但是二叉樹這個數(shù)據(jù)結構在某些情況下并沒有什么效果,比如這個col1這一列
,他是1-6的連續(xù)數(shù)據(jù)
他的二叉樹結構就是如下
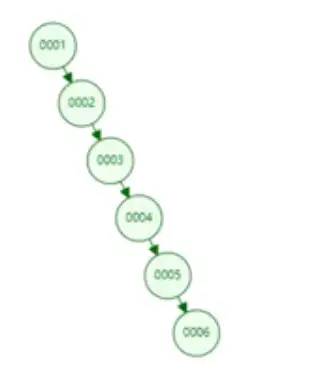
雖然還是二叉樹,但是這個和沒有索引效果是一樣的
所以MySQL最終選的不是二叉樹
然后第一種二叉樹排除了.
然后對比一下紅黑樹
jdk1.8之后hashmap之前就是數(shù)組加鏈表存儲的,假如鏈表非常長的時候,在hashmap里面查找元素性能也不是很好的快速查找所以在jdk1.8之后,在hashmap的底層鏈表被優(yōu)化成紅黑樹,查找性能優(yōu)化很高
紅黑樹的索引要是將1-7變成如下
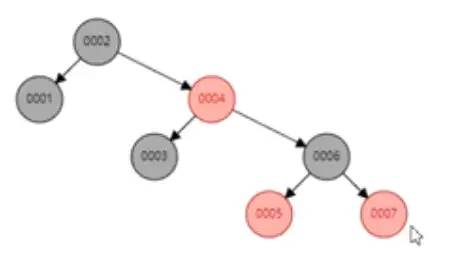
紅黑樹也是二叉樹,也叫做自平衡二叉樹,二叉平衡樹
但是MySQL最后之所以沒有選擇紅黑樹,因為紅黑樹在某些場景下并不能滿足需求,因為用紅黑樹存儲索引在某些情況下有如下問題:
1,層級太多,因為我們只有7個數(shù)據(jù),層數(shù)即高度就這么多,如果要是很多的數(shù)據(jù),那樣不就更多了,假如樹的高度是20,我們查找的元素在葉子結點,最快最快也要經(jīng)過20次查找,也就要經(jīng)過20次磁盤io查找
MySQL是將這個數(shù)據(jù)結構存儲在磁盤上面的,假如你先存儲了10個數(shù)據(jù),然后過了幾天又存儲了10個數(shù)據(jù),中間間隔了很多天,因為數(shù)據(jù)都是要寫到磁道上面,這段時間間隔可能寫了很多其他數(shù)據(jù),可能都跨磁道了,這樣查詢起來更慢了,因為他也是都磁盤上面找的.
樹的高度越低,查找速度越快,最好對這個樹的高度做一下優(yōu)化,即使上千萬數(shù)據(jù),也讓這個樹的高度小于4,這個是可能的,
因為我們比如插入一條數(shù)據(jù),他是先在磁盤上面開辟一個空間,然后再將數(shù)據(jù)存儲上去,我們就可以一次開辟多個空間,這一行存儲多個節(jié)點,然后這個多個節(jié)點又能分出很多只
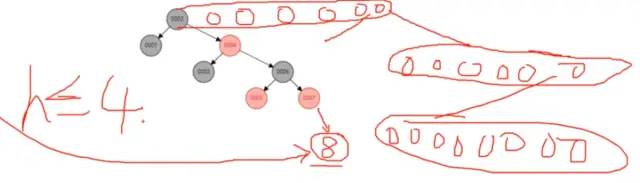
上圖就得到了一個B樹的結構,
所以就引出了B樹,B樹就是B-樹,兩個是一個東西
B樹解釋:
他就是上面二叉樹的變種,只不過每一個節(jié)點存儲了多了key和value,而不是之前的一個
MySQL底層實際上用的是B樹的變種,叫B+樹
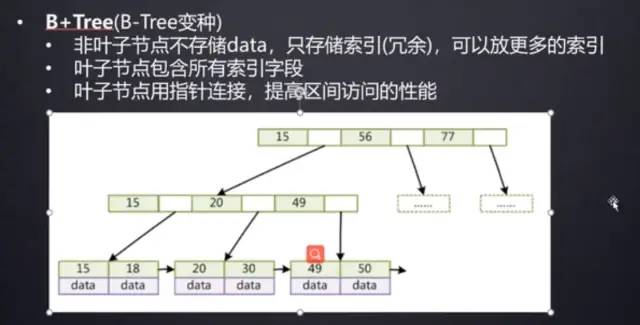
B+樹解釋
B+樹他的葉子節(jié)點才會存儲這個data,這個data對應的是這個數(shù)值在磁盤上面存儲的位置,即我們最上面說的那個value
B+樹每一個節(jié)點從左往右是依次遞增的,而且15,18是在15-20之間,葉子結點之間用指針鏈接.
子節(jié)點大于等于他左邊的父節(jié)點,小于右邊的父節(jié)點
所有葉子結點也是從左往右依次遞增,MySQL維護時候也是方便維護的
B+樹也叫多路(叉)二叉樹,底層也是二叉樹
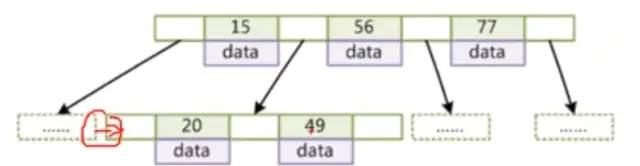
MySQL在B+樹下如何查詢:
查找30為例:
1,首先將最上面的這個如15.56.77加載到內(nèi)存,這是一次磁盤的IO操作,然后在內(nèi)存查找
2,然后發(fā)現(xiàn)30是位于15.56之間,然后去他們兩個之間的那個空白節(jié)點把下面第二行的地址拿到,然后將這個對應的第二行加載到內(nèi)存,又是一次磁盤IO操作
3,然后發(fā)現(xiàn)這個30位于20和49之間,然后讀這個第二行的20和49之間的地址,將對應的第三行讀取到內(nèi)存,第三次磁盤IO.
疑問:為什么不把所有數(shù)據(jù)都放在第一行呢?
答:假如數(shù)據(jù)量很大,幾千萬行數(shù)據(jù),一次把幾千萬行數(shù)據(jù)直接加載到內(nèi)存,那樣內(nèi)存大概率感觸幾百兆.而且一次磁盤IO撐死幾M,可能就幾十K,幾百兆的一次磁盤IO完成不了,磁盤IO幾百兆也需要幾秒鐘或者幾十秒.
所以這個每一行每一點存儲多少K的數(shù)據(jù),MySQL給我們提供了一個默認的,16K,這個一次磁盤IO讀取16K數(shù)據(jù)還是很簡單的,這個值是MYSQL研發(fā)人員在多次測試的成果下給設置的默認值,單位是B
show global status like 'Innodb_page_size'

為什么MYSQL默認設置為16K?
一般索引都是用INT OR BIGINT
以bigint為例,比如這個索引15一般MySQL給他存儲的是8B,然后他和56之間的空白格,這個是下一排的地址.是一個指針,索引和指針成對出現(xiàn),這個一般是存儲6B,MySQL給的值,所以一行16k*1024/(8+6)=1170個
葉子節(jié)點是沒有這個空白區(qū)域,因為空白區(qū)域存放的是指針,他不需要指向下一位,所以沒有這個指針,他的data占用的比較大,大概是1Kb左右,所以葉子節(jié)點一個是存儲16個元素
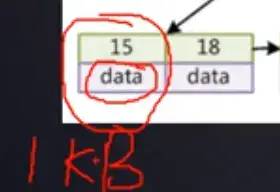
假如一個三層的B+樹放滿了,就是1170117016=兩千兩百萬
所以就可能千萬級別數(shù)據(jù)只需要查詢?nèi)龑?/strong>
hash表存儲方式
MySQL的索引也可以按照hash表存儲方式,
MyISAM和InnoDB存儲引擎:只支持BTREE索引, 也就是說默認使用BTREE,不能夠更換,
但是hash索引某些存儲引擎比如innodb是不支持的,除非經(jīng)過特殊設置
hash表索引在MySQL用的很少
雖然用navicat在innodb和mylsam引擎下,可以選擇hash索引,但是你會發(fā)現(xiàn),點擊保存,自動變成了Btree,如果是memory引擎,他就可以選擇hash索引,memory存儲引擎支持hash索引存儲和btree方式
如果使用hash表存儲的話,就是hash(索引值),把這個hash索引值之后的結果和磁盤地址兩個做一個唯一的映射,這樣看起來好像感覺執(zhí)行比如下面這個SQL好像比B+更快,因為只需要對這個索引做一次hash,然后拿這個這個hash值去磁盤映射的位置找到這個對應的值即可
另外MySQL底層對hash碰撞(如果兩個輸入串的hash函數(shù)的值一樣,則稱這兩個串是一個碰撞)規(guī)避得很好
比如select * from a where Col1=1
但是,假如執(zhí)行的是select * from a where Col2<89 and Col2>34,這個就是B+更快樂,絕大部分場景都是范圍查找吧.所以MySQL默認是B+tree,但是也可以選擇hashTress
用B+樹查找時候,實現(xiàn)范圍查找就非常快了,他的葉子節(jié)點之間用指針連接起來的,而且是雙向的,首尾相連的
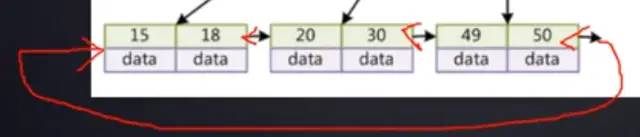
而B樹葉子結點沒有指針的,
假如查找的是10-50之間數(shù)據(jù),找到20之后,又要從根節(jié)點索引元素查找到49,不能像B+樹那樣直接向右取
聯(lián)合索引:

這個就是把之前的一個字段轉換成現(xiàn)在的三個字段而已,這個對比排序方式是首先按照第一個字段對比,都一樣在比較第二個字段,在一樣的話再比較第三個字段 。
PS:如果覺得我的分享不錯,歡迎大家隨手點贊、在看。
(完) 加我"微信"?獲取一份 最新Java面試題資料 請備注:666,不然不通過~
最近好文
最近面試BAT,整理一份面試資料《Java面試BAT通關手冊》,覆蓋了Java核心技術、JVM、Java并發(fā)、SSM、微服務、數(shù)據(jù)庫、數(shù)據(jù)結構等等。 獲取方式:關注公眾號并回復?java?領取,更多內(nèi)容陸續(xù)奉上。 明天見(??ω??)??