
南開&阿里聯(lián)合提出P2T:基于金字塔池化的視覺Transformer!

極市導(dǎo)讀
本文提出了基于金字塔池化的視覺 Transformer,第一次將金字塔池化思想引入到視覺 Transformer 中,并將其應(yīng)用于下游場景理解任務(wù)。 金字塔池化可以自然地解決MHSA序列長度過長的問題,也可以高效地捕捉上下文和結(jié)構(gòu)信息。 >>加入極市CV技術(shù)交流群,走在計(jì)算機(jī)視覺的最前沿

論文鏈接:https://arxiv.org/abs/2106.12011
代碼鏈接:https://github.com/yuhuan-wu/P2T
目前,現(xiàn)有的視覺Transformer中的兩大問題:
1. 傳統(tǒng)的 Multi-Head Self-Attention (MHSA) 需要大量的計(jì)算、空間資源。
2. 最近新提出的視覺 Transformer 在圖像分類中被過度地開發(fā)和調(diào)整,卻忽視了圖像分類(單一場景,與MLP較為相似)和各類下游場景理解任務(wù)(復(fù)雜場景,豐富結(jié)構(gòu)和內(nèi)容信息)的區(qū)別。
為了解決以上兩大問題,研究人員提出了基于金字塔池化的視覺 Transformer,第一次將金字塔池化思想引入到視覺 Transformer 中,從而減少使用傳統(tǒng) MHSA 帶來的過高計(jì)算量和存儲空間(問題1)。此外,研究人員注意到 Pyramid Pooling 因其強(qiáng)大的抽象上下文能力在各類下游視覺任務(wù)上的表現(xiàn)都十分出色,且其空間不變性的自然屬性適合解決結(jié)構(gòu)信息的丟失問題(問題2)。
一、Introduction
過去十年從 AlexNet 開始,卷積神經(jīng)網(wǎng)絡(luò)(CNN)在計(jì)算機(jī)視覺各類任務(wù)上都大放異彩,絕大部分的新 SOTA 都采用了 CNN 作為基礎(chǔ)架構(gòu)。而最近在自然語言處理領(lǐng)域,Transformer技術(shù)逐步替代CNN作為主要技術(shù)。Transformer的主要依賴其自注意力(self-attention)機(jī)制,從而獲取長距離的全局注意力信息。因?yàn)?strong style="color: black;">Transformer 的成功點(diǎn)主要在于其獲取全局信息的能力,而全局信息在計(jì)算機(jī)視覺領(lǐng)域也同樣十分重要,將 Transformer 遷移至視覺領(lǐng)域也能夠克服傳統(tǒng)CNN需要疊加多個(gè)層才能獲取更大感受野的缺陷。
最近,Dosovitskiy 等人[1]第一次將純粹的視覺 Transformer 用于圖像分類中,并取得了與 CNN 相比十分有競爭力的效果。隨后,在極短的時(shí)間內(nèi),大量的研究者試圖去改進(jìn) Dosovitskiy 等人提出的視覺 Transformer 方法,并取得了比CNN更好的效果。
然而,視覺 Transformer 方法仍然有兩點(diǎn)巨大的問題。
1) 一個(gè)問題是自注意力機(jī)制中序列的長度。視覺 Transformer 中序列的長度往往遠(yuǎn)大于自然圖像處理中的序列長度。過長的序列長度會(huì)導(dǎo)致多頭自注意力機(jī)制(MHSA)過大的自注意力計(jì)算量和計(jì)算空間。為了解決這一問題,PVT方法[2]直接將輸入進(jìn) Transformer 的特征圖作下采樣從而避免MHSA帶來的過大計(jì)算量和計(jì)算空間。然而這種做法會(huì)導(dǎo)致它實(shí)際是 token-to-region 的建模,而非 token-to-token 的建模。Swin方法[3]將計(jì)算整個(gè)特征圖的注意力轉(zhuǎn)變?yōu)樵谔卣鲌D的每個(gè)小窗口中計(jì)算。它使用一種 window shift 的策略去逐漸地增大網(wǎng)絡(luò)的感受野,即通過疊加多個(gè)層來增加感受野。這類策略的問題在于它仍然沿用的 CNN 的策略。研究者們用 Transformer 替代 CNN 的初衷在于 Transformer 能夠?qū)μ卣鬟M(jìn)行直接的全局關(guān)系建模。
2) 另一問題是計(jì)算機(jī)視覺與自然語言處理的域間隙(domain gap)。 在計(jì)算機(jī)視覺中,研究人員一般是對圖像進(jìn)行處理,而圖像一般是一種自然的2D結(jié)構(gòu),而在自然語言處理中一般是處理 1D 的句子序列。對于1D的句子序列,研究人員只需要考慮序列的先后順序,利用 Positional Encoding 就可以簡單地解決該問題。然而大部分視覺transformer只是針對 ImageNet 分類進(jìn)行改進(jìn)而不考慮這個(gè)問題。ImageNet 中的圖像僅具有簡單的上下文信息,例如,相同類的某些對象以圖像為中心。一個(gè)簡單的 Position Embedding 就可以處理這種簡單的情況。但顯然對復(fù)雜的真實(shí)情景,特別是對于需要像素級圖像理解的密集預(yù)測任務(wù)來說,這種方式是次優(yōu)的。因此,研究人員認(rèn)為目前 Transformer 網(wǎng)絡(luò)的先前在圖像分類取得結(jié)果不能代表其在下游視覺任務(wù)中的性能。目前也迫切需要一個(gè)下游任務(wù)導(dǎo)向的Transformer 來彌合計(jì)算機(jī)視覺和自然語言處理之間的域間隙。
研究人員注意到金字塔池化 (Pyramid Pooling) 是一種建模深度特征圖長距離特征關(guān)系的有效手段。 具體而言,金字塔池化對給定的特征圖使用具有不同感受野、步長的池化操作。這種技術(shù)已經(jīng)在各類場景理解的視覺任務(wù)應(yīng)用,比如語義分割、物體檢測、視覺顯著性、圖像超分辨率、立體匹配、去雨、去噪等視覺任務(wù)。利用金字塔池化技術(shù)改進(jìn)現(xiàn)有的視覺 Transformer 可以自然地解決視覺 Transformer 中序列過長的問題。而且金字塔池化技術(shù)利用多核池化操作和金字塔的空間不變性可以自然地捕獲多尺度長距離的上下文信息和2D結(jié)構(gòu)。
基于以上觀察,研究人員提出了金字塔池化 Transformer (Pyramid Pooling Transformer, P2T),并將其應(yīng)用于下游場景理解任務(wù)。 金字塔池化可以自然地解決MHSA序列長度過長的問題,也可以高效地捕捉上下文和結(jié)構(gòu)信息。
二、Methodology
 金字塔池化transformer的具體結(jié)構(gòu)
金字塔池化transformer的具體結(jié)構(gòu)
設(shè)MHSA中query, key, value分別為 , 傳統(tǒng)MHSA的計(jì)算方式為
在P2T中,研究人員提出使用:
與傳統(tǒng)MHSA的不一致在于, 是對輸入特征 使用金字塔池化方式生成的,即對 使用多個(gè)不同感受野、步長的池化操作,將中間特征按空間維度拉直拼接為 。研究人員將這種新型的MHSA命名為 Pooling-based MHSA (P-MHSA)。
所以,單個(gè)金字塔池化Transformer的計(jì)算可以用下式來進(jìn)行表示:
研究人員也構(gòu)建了多個(gè)不同深度的金字塔池化Transformer,使得這種Transformer 可以適用于不同的計(jì)算場景。

三、Experiments
為了驗(yàn)證P2T在不同下游任務(wù)的有效性,研究人員在語義分割、目標(biāo)檢測、實(shí)例分割、視覺顯著性等下游任務(wù)與現(xiàn)有的多個(gè)骨干方法進(jìn)行對比。
語義分割(ADE20K val)

語義分割(Cityscapes val)

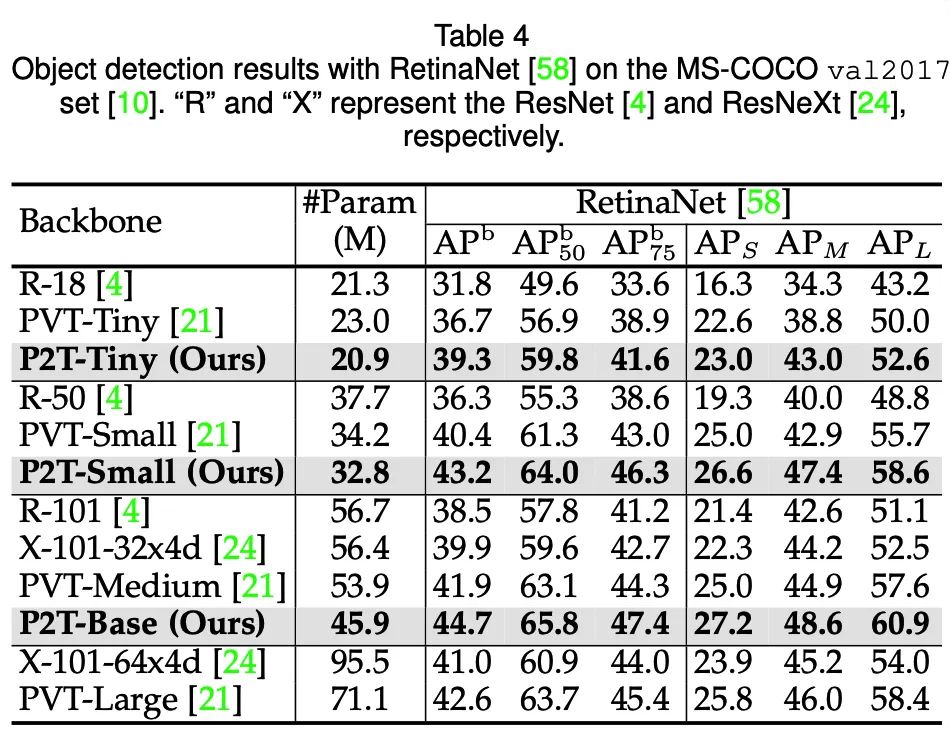
目標(biāo)檢測(MS-COCO 2017val)
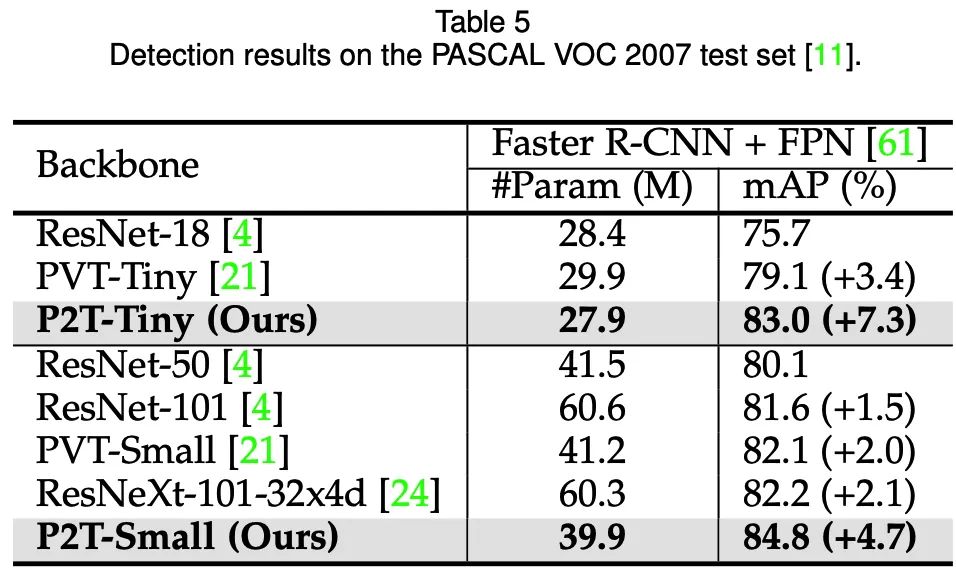
目標(biāo)檢測(Pascal VOC 2007test)
### 實(shí)例分割(MS-COCO 2017val)
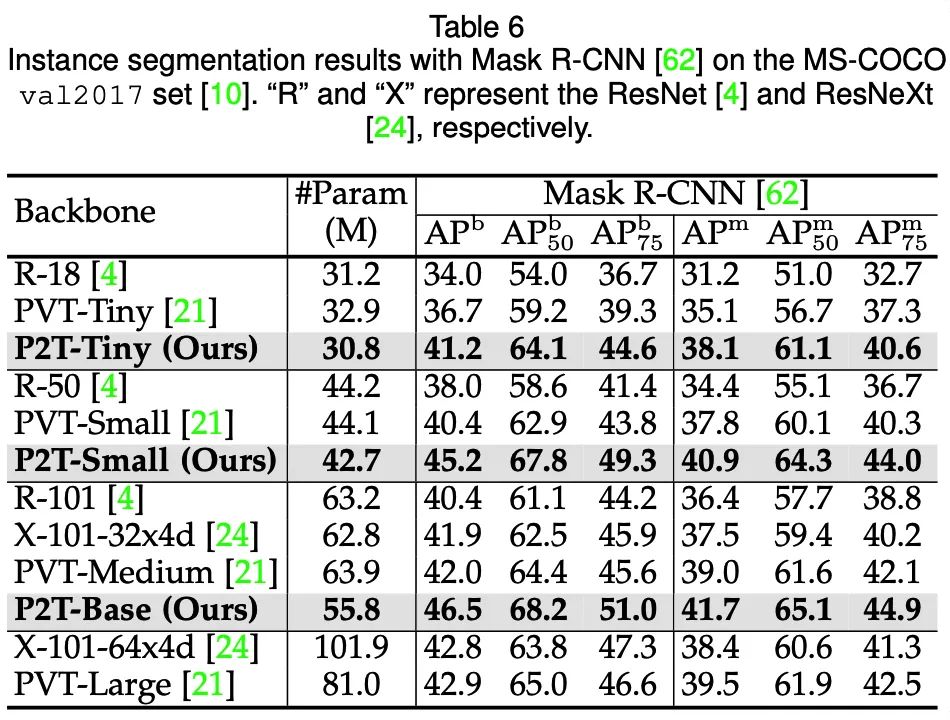
實(shí)例分割(MS-COCO 2017val)
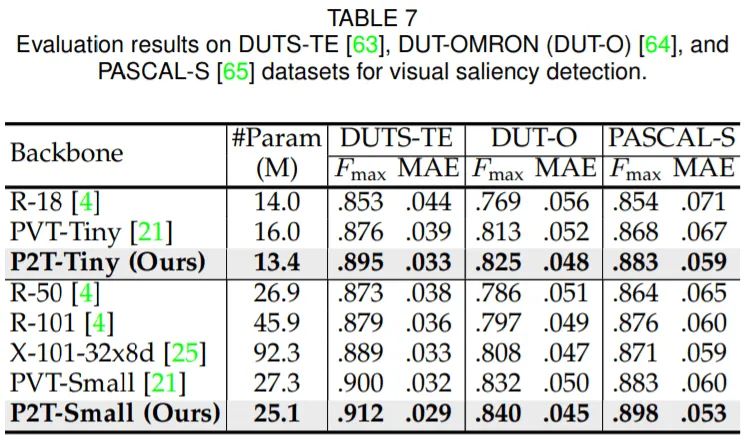
可以發(fā)現(xiàn),在語義分割、目標(biāo)檢測、實(shí)例分割、視覺顯著性等下游場景上,P2T方法均大幅戰(zhàn)勝了CNN及Transformer方法。
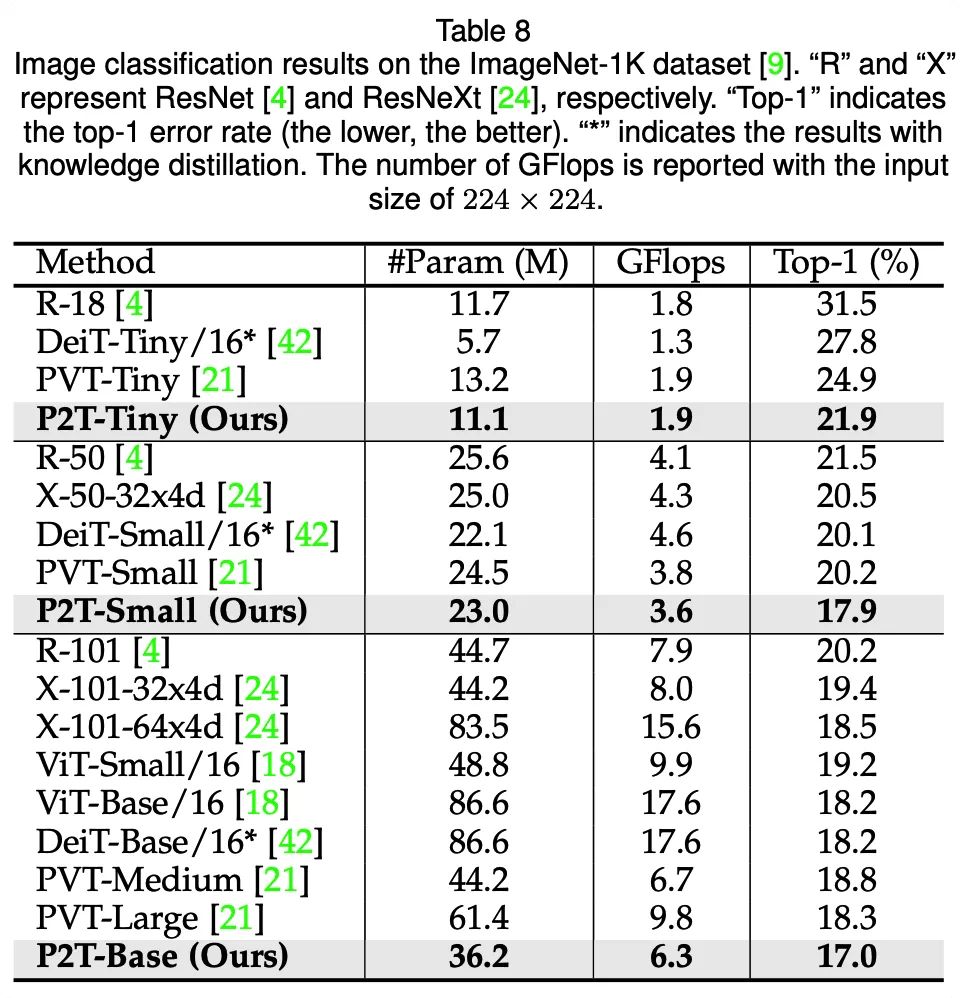
除了在各類下游任務(wù)與其他方法作對比,研究人員也測試了P2T在圖像分類上的性能。雖然P2T并不是專門設(shè)計(jì)于圖像分類任務(wù),但也相對其他CNN、Transformer方法取得了十分有競爭力的性能。
參考文獻(xiàn)
[1] A. Dosovitskiy, et al., “An image is worth 16x16 words: Transformers for image recognition at scale,” arXiv preprint arXiv:2010.11929, 2020.
[2] W. Wang, et. al., “Pyramid Vision Transformer: A versatile backbone for dense prediction without convolutions,” arXiv preprint arXiv:2102.12122, 2021.
[3] Z. Liu, et. al., “Swin Transformer: Hierarchical vision transformer using shifted windows,” arXiv preprint arXiv:2103.14030, 2021.
Illustration by Olha Khomich from Icons8
本文亮點(diǎn)總結(jié)
如果覺得有用,就請分享到朋友圈吧!
公眾號后臺回復(fù)“80”獲取CVPR 2021-Alpha Refine 直播回放及PPT~

# CV技術(shù)社群邀請函 #
備注:姓名-學(xué)校/公司-研究方向-城市(如:小極-北大-目標(biāo)檢測-深圳)
即可申請加入極市目標(biāo)檢測/圖像分割/工業(yè)檢測/人臉/醫(yī)學(xué)影像/3D/SLAM/自動(dòng)駕駛/超分辨率/姿態(tài)估計(jì)/ReID/GAN/圖像增強(qiáng)/OCR/視頻理解等技術(shù)交流群
每月大咖直播分享、真實(shí)項(xiàng)目需求對接、求職內(nèi)推、算法競賽、干貨資訊匯總、與 10000+來自港科大、北大、清華、中科院、CMU、騰訊、百度等名校名企視覺開發(fā)者互動(dòng)交流~
