
中國科學(xué)院、東南大學(xué)等聯(lián)合發(fā)表最新的視覺 Transformer 綜述 | 100+ Transformer 模型
點(diǎn)擊下方“AI算法與圖像處理”,一起進(jìn)步!
重磅干貨,第一時(shí)間送達(dá)
導(dǎo)讀
?中國科學(xué)院、東南大學(xué)等單位聯(lián)合發(fā)表最新的視覺 Transformer 綜述。綜述涵蓋三種基本 CV 任務(wù)的一百多種不同的視覺 Transformer,最新模型截止至今年8月!同時(shí),綜述還包括了大量的實(shí)證分析、性能改進(jìn)分析,并披露了三個(gè)具有廣闊前景的未來研究方向!
Transformer 是一種基于注意力的編碼器-解碼器架構(gòu),它徹底改變了自然語言處理領(lǐng)域。受這一重大成就的啟發(fā),最近,在將類似于 Transformer 的結(jié)構(gòu)應(yīng)用于計(jì)算機(jī)視覺 (CV) 領(lǐng)域上進(jìn)行了一些開創(chuàng)性工作,這已經(jīng)證明了它們?cè)诟鞣N CV 任務(wù)上的有效性。與現(xiàn)在的卷積神經(jīng)網(wǎng)絡(luò) (CNN) 相比,視覺 Transformer (ViT) 依靠有競(jìng)爭(zhēng)力的建模能力,在 ImageNet、COCO 和 ADE20k 等多個(gè)基準(zhǔn)上取得了十分優(yōu)異的性能。在本文中,作者全面回顧了針對(duì)三個(gè)基本 CV 任務(wù)(分類、檢測(cè)和分割)的一百多種不同的視覺 Transformer,其中提出了一種分類法,根據(jù)它們的動(dòng)機(jī)、結(jié)構(gòu)和使用場(chǎng)景來組織這些方法。由于訓(xùn)練設(shè)置和面向任務(wù)的差異,作者還在不同的配置上評(píng)估了這些方法,以方便直觀地進(jìn)行比較,而不僅僅是各種基準(zhǔn)測(cè)試。此外,作者披露了一系列基本但未經(jīng)開發(fā)的方面,這些方面可能使 Transformer 從眾多架構(gòu)中脫穎而出,例如,不充分的高級(jí)語義嵌入以彌合視覺和順序 Transformer 之間的差距。最后,提出了三個(gè)有前景的未來研究方向,以供進(jìn)一步研究。
1. 論文和代碼地址

論文題目:A Survey of Visual Transformers
發(fā)表單位:中國科學(xué)院、東南大學(xué)、聯(lián)想研究院、聯(lián)想
論文地址:arXiv:2111.06091
提交時(shí)間:2021年11月11日
2. 動(dòng)機(jī)
ViT 發(fā)展速度十分迅速!
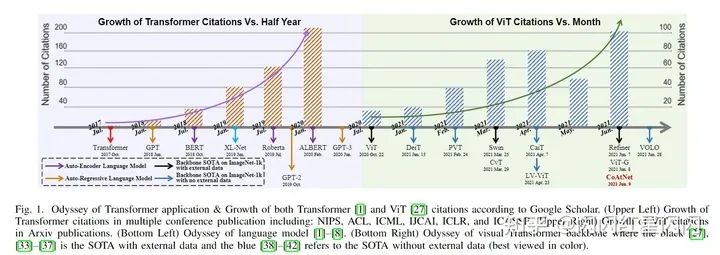
如上圖左邊所示,Transformer 逐漸成為自然語言處理 (NLP) 的主要深度學(xué)習(xí)模型。從上圖右圖所示,在過去的一年中,針對(duì)不同的領(lǐng)域提出了數(shù)百種基于 Transformer 的視覺模型。
這篇綜述和以往綜述有什么區(qū)別?
去年發(fā)表了幾篇關(guān)于 Transformer 的評(píng)論,其中 Tay 等人回顧了 NLP 中 Transformers 的效率,Khan 等人和 Han 等人總結(jié)了早期的視覺 Transformer 和之前的注意力模型,以及一些沒有系統(tǒng)方法的語言模型。最近對(duì) Transformer 的綜述是 Lin 等人介紹的,提供了對(duì) Transformer 各種變體的系統(tǒng)綜述,并粗略地提到了它在視覺上的應(yīng)用。基于這些觀察,本文旨在全面回顧最近的 ViT,并系統(tǒng)地對(duì)這些現(xiàn)有方法進(jìn)行分類:
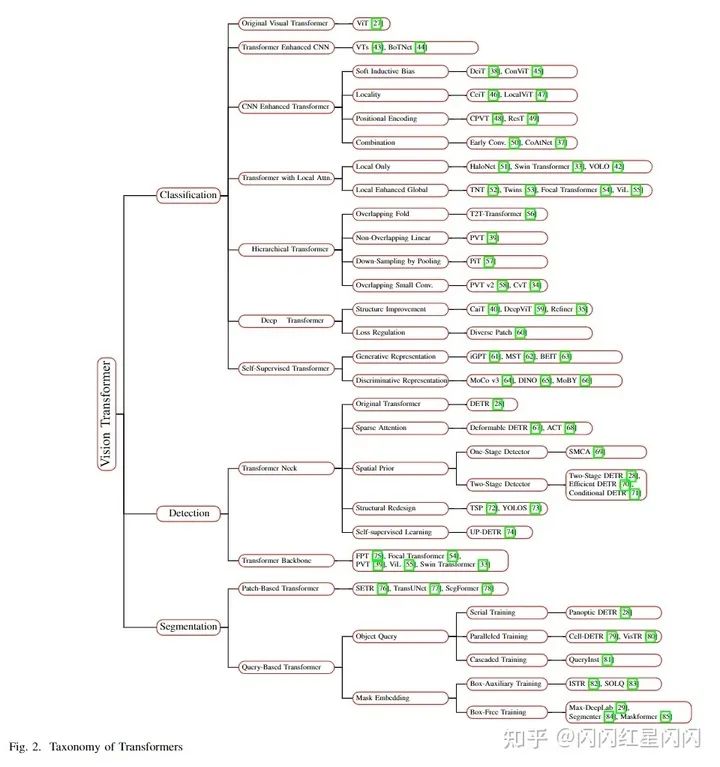
全面性和可讀性。 本文全面綜述了100多種 ViT 的三個(gè)基本任務(wù):分類、檢測(cè)和分割。本文選擇并分析了50多個(gè)代表性模型,如上圖所示,本文不僅從一個(gè)角度對(duì)每個(gè)模型進(jìn)行了詳盡的分析,而且還通過漸進(jìn)、對(duì)比和多視角分析等方式建立了它們之間的內(nèi)在聯(lián)系。 直觀的比較。 由于這些 ViT 在各種任務(wù)中遵循不同的訓(xùn)練方案和超參數(shù)設(shè)置,因此本次調(diào)查通過在不同的數(shù)據(jù)集和限制上將它們分開來呈現(xiàn)多個(gè)橫向比較。更重要的是,本文總結(jié)了為每個(gè)任務(wù)設(shè)計(jì)的一系列有前景的組件,包括:用于主干的具有層次結(jié)構(gòu)的淺層局部卷積,用于頸部檢測(cè)器的具有稀疏注意力的空間先驗(yàn)加速,以及用于分割的通用掩碼預(yù)測(cè)方案。 深入分析。 本文進(jìn)一步在以下方面提供了重要的見解:從序列到視覺任務(wù)的轉(zhuǎn)換過程,Transformer 與其他視覺網(wǎng)絡(luò)之間的對(duì)應(yīng)關(guān)系,以及不同任務(wù)中采用的可學(xué)習(xí)嵌入(即類token、對(duì)象查詢、掩碼嵌入)的相關(guān)性。最后,本文概述了未來的研究方向。例如,編碼器-解碼器的 Transformer 主干可以通過學(xué)習(xí)的嵌入來統(tǒng)一三個(gè)子任務(wù)(分類、檢測(cè)和分割)。
3. 最初的 Transformer
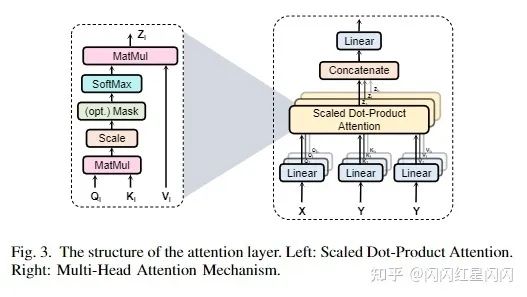
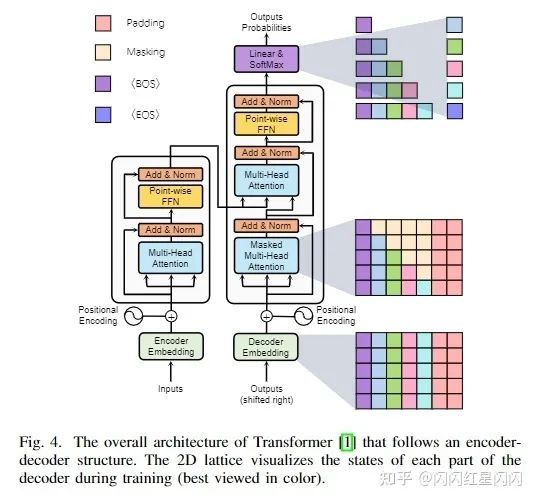
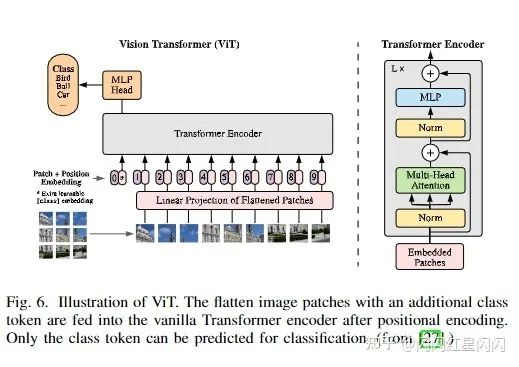
最初的Transformer架構(gòu)如上圖4所示,由以下3個(gè)模塊組成:
多頭注意力機(jī)制(MHSA)
每個(gè)注意力層的細(xì)節(jié)如上圖3所示。
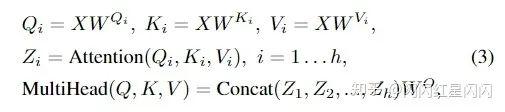
逐位置前饋網(wǎng)絡(luò)(FFN)
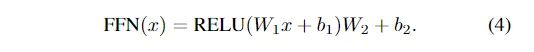
位置編碼
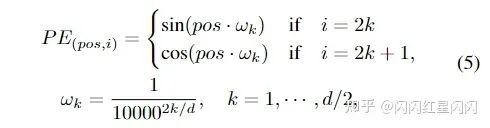
4. 分類中的 Transformer
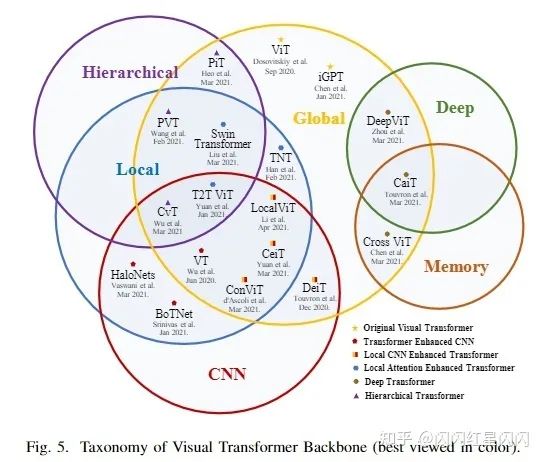
受到在 NLP 中 Transformer 優(yōu)異發(fā)展的啟發(fā),一些研究人員試圖將 Transformer 引入圖像分類。與傳統(tǒng)CNN相比,Vision Transformer(ViT)首次在主流分類基準(zhǔn)上實(shí)現(xiàn)了類似甚至更高的性能。本節(jié)全面回顧了 2021 年 6 月之前發(fā)布的 40 多個(gè) Transformer 主干,并根據(jù)其動(dòng)機(jī)和實(shí)現(xiàn)將它們分為六類,如下圖 5 所示。
基于本文提出的分類,首先介紹了 ViT,用于圖像分類的原始視覺 Transformer。然后討論了 Transformer Enhanced CNN 方法,該方法利用Transformer來增強(qiáng)CNN主干的遠(yuǎn)程依賴性。Transformer 具有很強(qiáng)的全局建模能力,但在早期忽略了局部信息。因此,CNN Enhanced Transformer 方法利用適當(dāng)?shù)木矸e歸納偏置來增強(qiáng) Transformer,而 Local Attention Enhanced Transformer 方法重新設(shè)計(jì)補(bǔ)丁分區(qū)和注意力塊以增強(qiáng) Transformer 的局部性并保持無卷積架構(gòu)。此外,CNN 在性能和計(jì)算效率方面從經(jīng)驗(yàn)上受益于分層和深層結(jié)構(gòu)。受此啟發(fā),提出了 Hierarchical Transformer 和 Deep Transformer 方法。前者用金字塔莖代替固定分辨率的柱狀結(jié)構(gòu),而后者防止注意力圖過于平滑并增加其在深層的多樣性。此外,本文還回顧了當(dāng)前可用的視覺 Transformer 自監(jiān)督方法。最后,作者評(píng)估這些 Transformer 的性能,分析有希望的改進(jìn),并回答一個(gè)常見問題以供進(jìn)一步調(diào)查。
4.1 最初的 ViT
ViT 是 Transformer 在圖像分類中的第一個(gè)骨干。
4.2 Transformer 增強(qiáng)的 CNN
Transformer 有兩個(gè)關(guān)鍵部分:MHSA 和 FFN。最近,Cordonnier 等人已經(jīng)證明卷積層可以通過具有足夠頭數(shù)的 MHSA 來近似。Dong等人已經(jīng)表明,MHSA 可能在沒有跨層連接和 FFN時(shí)對(duì)“token一致性”具有很強(qiáng)的歸納偏置。因此,Transformer 在理論上具有比 CNN 更強(qiáng)大的建模能力。然而,它不可避免地具有沉重的計(jì)算成本,特別是對(duì)于淺層,由自注意力機(jī)制帶來,隨著特征分辨率的二次方增長(zhǎng)。與之前基于注意力的方法類似,一些方法嘗試將 Transformer 插入 CNN 主干或用 Transformer 層替換部分卷積塊。例如 VTs 和 BoTNet。
4.3 CNN 增強(qiáng) Transformer
歸納偏差可以表示為一組關(guān)于數(shù)據(jù)分布或解空間的假設(shè),其在卷積中的表現(xiàn)是局部性和方差平移。局部性側(cè)重于空間上接近的元素,并將它們與遠(yuǎn)端隔離。平移不變性表明在輸入的位置之間重復(fù)使用相同的匹配規(guī)則 [97]。由于局部鄰域內(nèi)的協(xié)方差很大,并且在整個(gè)圖像中趨于逐漸平穩(wěn),這些卷積偏差可以有效地處理圖像數(shù)據(jù)。然而,強(qiáng)大的偏差也限制了 CNN 具有足夠數(shù)據(jù)集的上限。最近的工作試圖利用適當(dāng)?shù)木矸e偏差來增強(qiáng) Transformer 并加速其收斂。 這些應(yīng)用可以概括如下:軟近似(DeiT、ConViT)、直接局部性處理( CeiT、LocalViT)、位置編碼的直接替換(CPVT、ResT)和結(jié)構(gòu)組合(Early Conv. 、CoAtNet)。作者逐一對(duì)這些模型進(jìn)行了簡(jiǎn)要敘述。
4.4 局部注意力增強(qiáng)的 Transformer
ViT 將輸入圖像視為一個(gè)補(bǔ)丁序列。這種粗糙的補(bǔ)丁嵌入過程忽略了語言和圖像之間的差距,這可能會(huì)破壞圖像的局部信息。作為局部提取器,卷積通過相對(duì)固定的濾波器聚合特征。這種模板匹配過程可以有效地處理大多數(shù)小數(shù)據(jù)集,但在處理大型數(shù)據(jù)集時(shí)面臨表示的組合爆炸。與卷積相比,局部注意力機(jī)制可以根據(jù)局部元素之間的關(guān)系動(dòng)態(tài)生成注意力權(quán)重。為了增強(qiáng)局部特征提取能力并保留無卷積結(jié)構(gòu),一些工作(Swin Transformer、 TNT block、Twins、T2T-ViT)嘗試通過局部自注意力機(jī)制來適應(yīng)補(bǔ)丁結(jié)構(gòu)。隨后作者對(duì)一些 ViT 變體進(jìn)行了簡(jiǎn)要闡述,分別是:TNT、Swin Transformer、Twins& ViL和 VOLO。
4.5 分層 Transformer
由于 ViT 在整個(gè)網(wǎng)絡(luò)中以固定分辨率繼承了原始的柱狀結(jié)構(gòu),因此它忽略了細(xì)粒度特征,并帶來了昂貴的計(jì)算成本。繼分層 CNN 之后,最近的工作(CvT、PVT、ViL、T2T-ViT、PiT)將類似的結(jié)構(gòu)應(yīng)用于 Transformer 中。
4.6 深度 Transformer
根據(jù)經(jīng)驗(yàn),增加模型的深度使網(wǎng)絡(luò)能夠?qū)W習(xí)更復(fù)雜的表示。最近的工作將這種深度結(jié)構(gòu)應(yīng)用于 Transformer 并進(jìn)行大量實(shí)驗(yàn),通過分析跨 patch(Diverse Patch)和跨層(Refiner、DeepViT)的相似性以及殘差塊(CaiT)的貢獻(xiàn)來研究其可擴(kuò)展性。在深度 Transformer 中,更深層的特征往往不太具有代表性(注意力崩潰,由 DeepViT 發(fā)現(xiàn)),并且 patch 被映射到難以區(qū)分的潛在表示(補(bǔ)丁過度平滑,由 Diverse Patch 發(fā)現(xiàn))。為了彌補(bǔ)上述限制,這些方法也多方面提出了相應(yīng)的解決方案。本文簡(jiǎn)要介紹了CaiT、DeepViT & Refiner和 Diverse Patch。
4.7 有自監(jiān)督學(xué)習(xí)的 Transformers
自監(jiān)督 Transformers 在 NLP 中取得了成功,但受監(jiān)督的預(yù)訓(xùn)練 Transformers 仍占據(jù) CV 領(lǐng)域的主導(dǎo)地位。最近的工作還試圖在生成性(iGPT、BEiT)和辨別性(MoCo v3、DINO)中為視覺 Transformer 設(shè)計(jì)各種自監(jiān)督學(xué)習(xí)方案。
4.8 討論
1)實(shí)驗(yàn)評(píng)估和對(duì)比分析
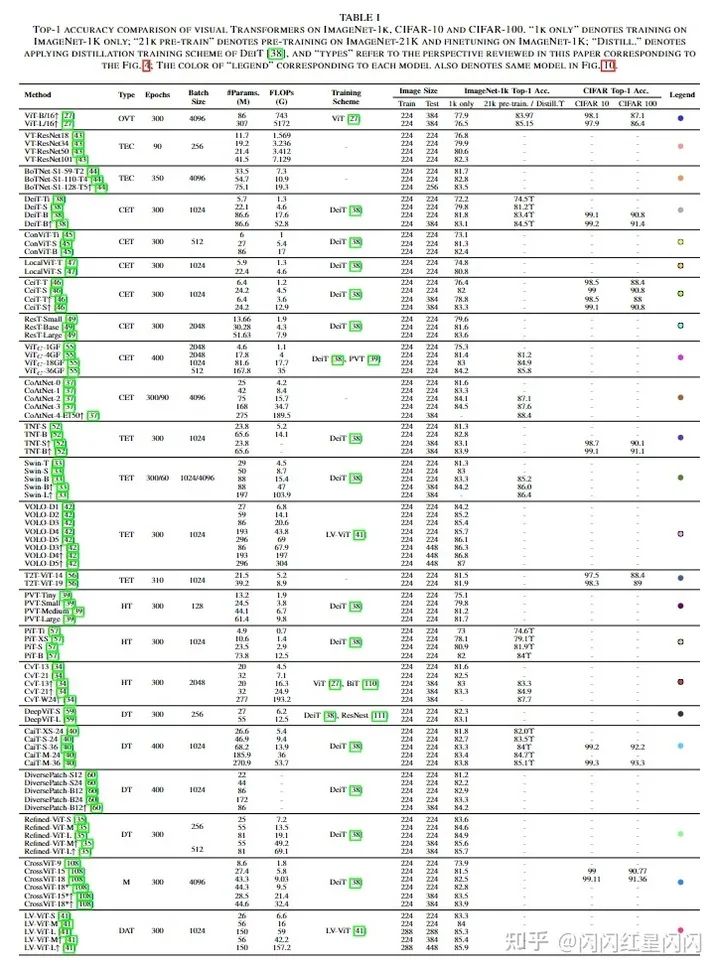
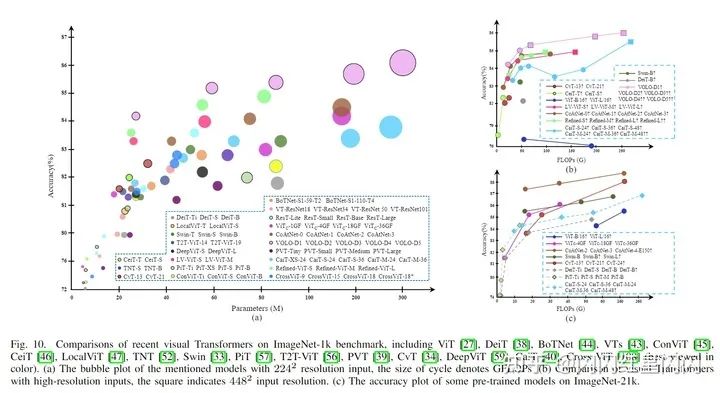
根據(jù)本文的分類法,所綜述的監(jiān)督模型可分為六類。表一總結(jié)了 Transformer 在主流分類基準(zhǔn)上的分類性能,并為每個(gè)型號(hào)指定了專用顏色。為了客觀直觀地評(píng)估它們,以下三幅圖說明了它們?cè)诓煌渲孟略?ImageNet-1k 上的比較(例如,模型大小、FLOPs 和訓(xùn)練方案)。下圖總結(jié)了在 輸入分辨率下,每個(gè)模型的性能。由于 FLOPs 在 Transformer 內(nèi)隨輸入大小呈二次增長(zhǎng),下圖(b)將 FLOPs 作為水平軸,重點(diǎn)關(guān)注其在更高分辨率下的性能。下圖(c)重點(diǎn)介紹帶有外部數(shù)據(jù)集的預(yù)訓(xùn)練模型。根據(jù)這些圖,作者簡(jiǎn)要分析了有利于模型性能、效率和可擴(kuò)展性的幾項(xiàng)改進(jìn),如下所示:
一般來說,大多數(shù)結(jié)構(gòu)改進(jìn)的方法針對(duì)特定模型尺寸、問題或特定輸入分辨率進(jìn)行優(yōu)化,而其它基本訓(xùn)練策略,如 DeiT 和 LV-ViT,更適用于各種模型、任務(wù)和輸入。 局部性對(duì)于 Transformer 來說是不可或缺的,VOLO 和 Swin 分別在分類和密集預(yù)測(cè)任務(wù)中占主導(dǎo)地位。 卷積 patch 化莖(即使用卷積生成patch,如 )和早期卷積階段(CoAtNet)顯著提高了 Transformer 的精度,尤其是在大型模型上,因?yàn)檫@樣的組合可以為淺層的細(xì)粒度局部特征提供相互幫助。 深層 Transformer 潛力巨大,如 Refined-ViT 和 CaiT。然而,由于模型大小與通道維度成二次方增長(zhǎng),因此深度 Transformer 中它們之間的權(quán)衡值得進(jìn)一步研究。 CeiT 和CvT 展示了顯著的優(yōu)勢(shì)在訓(xùn)練小型或中型模型(0?40M)時(shí),這表明這種用于輕量級(jí)模型的混合注意塊值得進(jìn)一步探索。
2)視覺變壓器發(fā)展趨勢(shì)綜述
Transformer 骨干在去年興起。當(dāng)我們的系統(tǒng)學(xué)與這些模型的時(shí)間線相匹配時(shí),可以清楚地追蹤到 Transformer for image classification 的發(fā)展趨勢(shì)(前面的圖 1)。作為一種自注意力機(jī)制,視覺 Transformer 主要根據(jù) NLP 中的 vanilla 結(jié)構(gòu)(ViT 和 iGPT)或 CV 中基于注意力的模型(VTs 和 BoTNet)重新設(shè)計(jì)。
然后,許多方法開始將 CNN 的層次結(jié)構(gòu)或深層結(jié)構(gòu)擴(kuò)展到視覺 Transformer。T2T-ViT、PVT、CvT 和 PiT 的共同動(dòng)機(jī)是將層次結(jié)構(gòu)轉(zhuǎn)移到 Transformer 中,但它們執(zhí)行下采樣的方式不同。CaiT、Diverse Patch、DeepViT 和 Refiner 專注于深度 Transformer 中的問題。此外,一些方法轉(zhuǎn)向內(nèi)部組件以進(jìn)一步增強(qiáng)先前 Transformer 中的圖像處理能力,即位置編碼、MHSA 和 MLP。
下一波 Transformer 是局部范式。他們中的大多數(shù)通過引入局部注意力機(jī)制或卷積將局部性引入 Transformer。如今,最新的監(jiān)督式 Transformer 正在探索結(jié)構(gòu)組合和縮放定律。除了有監(jiān)督的 Transformers,自監(jiān)督學(xué)習(xí)在視覺 Transformers 中占了很大一部分。然而,目前尚不清楚哪些任務(wù)和結(jié)構(gòu)對(duì) CV 中的自監(jiān)督 Transformer 更有利。
3) 淺談替代方案
在視覺 Transformer 的開發(fā)過程中,最常見的問題是 Transformer 是否可以取代卷積。通過回顧過去一年的改善歷史,沒有性能不足的跡象。視覺 Transformer 已經(jīng)從一個(gè)純粹的結(jié)構(gòu)回歸到一個(gè)混合的形式,全局信息逐漸回歸到一個(gè)與局部信息混合的階段。 雖然 Transformer 可以等價(jià)于卷積,甚至比卷積具有更好的建模能力,但這種簡(jiǎn)單有效的卷積運(yùn)算足以處理底層的局部性和低級(jí)語義特征。在未來,兩者結(jié)合的思想將推動(dòng)圖像分類的更多突破。
5. 檢測(cè)中的 Transformer
在本節(jié)中,作者詳細(xì)介紹了用于目標(biāo)檢測(cè)的視覺 Transformer,它可以分為兩類:作為頸部(neck)的 Transformer 和作為主干(backbone)的 Transformer。頸部檢測(cè)器主要是基于 Transformer 結(jié)構(gòu)的一種新表示,稱為目標(biāo)查詢,即一組學(xué)習(xí)的參數(shù)均等地聚合全局特征。這些方法嘗試在提高收斂速度或改進(jìn)性能方面提供最佳融合范式。除了專門為檢測(cè)任務(wù)設(shè)計(jì)的各種頸部外,一部分骨干檢測(cè)器也考慮了特定的策略。最后,本文比較了它們之間的性能,然后分析了 Transformer 檢測(cè)器的一些潛在的改進(jìn)。
5.1 Transformer 頸部
作者首先回顧 DETR,這是最開始的一個(gè) Transformer 檢測(cè)器,它提供了一個(gè)新的表示目標(biāo)查詢,將對(duì)象檢測(cè)制定為一個(gè)集合預(yù)測(cè)問題。由于其對(duì)小物體的準(zhǔn)確性低和收斂速度慢,人們從三個(gè)方面努力改進(jìn)這種 Transformer 檢測(cè)器:稀疏注意力、空間先驗(yàn)和結(jié)構(gòu)重設(shè)計(jì)。此外,本文還回顧了自監(jiān)督的應(yīng)用。
最初的檢測(cè)器:DEtection with TRansformer (DETR)
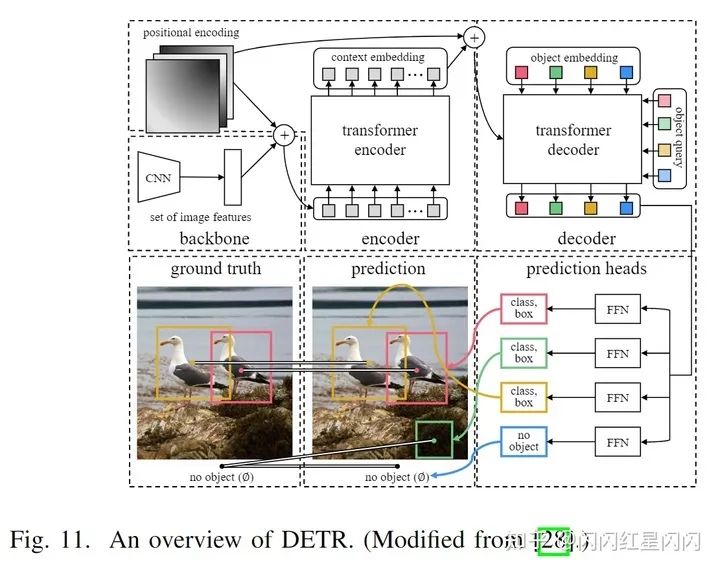
DETR是第一個(gè)端到端的 Transformer 檢測(cè)器,它消除了手工設(shè)計(jì)的表示和非極大值抑制(NMS)后處理,通過引入目標(biāo)查詢和集合預(yù)測(cè)直接檢測(cè)所有對(duì)象。具體地,DETR 使用編碼器-解碼器 Transformer 作為頸部,以及使用 FFN 作為預(yù)測(cè)頭(如上圖所示)。
稀疏注意力的 Transformer
在 DETR 中,解碼器嵌入和全局特征之間的密集交互會(huì)消耗大量計(jì)算資源并減慢 DETR 的收斂速度。因此,一些努力旨在設(shè)計(jì)依賴于數(shù)據(jù)的稀疏注意力來解決這個(gè)問題,例如 Deformable DETR 和 ACT。接著作者描述了在稀疏注意力中的幾個(gè)重要改進(jìn):Deformable DETR、ACT、SMCA、Conditional DETR、Two-Stage Deformable DETR 和 Efficient DETR。
重新設(shè)計(jì)結(jié)構(gòu)的 Transformer
除了聚焦于交叉注意力的改進(jìn)外,一些工作還重新設(shè)計(jì)了僅編碼器的結(jié)構(gòu)來直接避免解碼器的問題。例如,TSP 繼承了集合預(yù)測(cè)的思想,并放棄了解碼器和目標(biāo)查詢。YOLOS 結(jié)合了 DETR 的編碼器-解碼器頸部和 ViT 的僅編碼器主干,來重新設(shè)計(jì)僅編碼器的檢測(cè)器。
自監(jiān)督學(xué)習(xí)的 Transformer 檢測(cè)器
受到自然語言處理中取得成功的預(yù)訓(xùn)練 Transformer 的啟發(fā),Dai 等人提出無監(jiān)督預(yù)訓(xùn)練DETR(UP-DETR)從三個(gè)方面輔助監(jiān)督訓(xùn)練:
從給定圖像中隨機(jī)裁剪的一個(gè) path 分配給所有目標(biāo)查詢。解碼器的目標(biāo)是定位 patch 位置。 為了避免在預(yù)訓(xùn)練中對(duì)定位的過度偏見,提出了一個(gè)輔助重建任務(wù)來保留有判別性的特征。 基于單個(gè)查詢 patch,多查詢定位將多個(gè) patch 分配給不同的目標(biāo)查詢,以模仿多目標(biāo)檢測(cè)任務(wù)并加速收斂。每個(gè) patch 查詢都是通過掩碼注意力和目標(biāo)查詢混洗獨(dú)立預(yù)測(cè)的。
UP-DETR 在小數(shù)據(jù)集上比 DETR 獲得了更高的精度和更快的收斂速度,甚至在訓(xùn)練數(shù)據(jù)充足的情況下性能更好。
5.2 Transformer 骨干
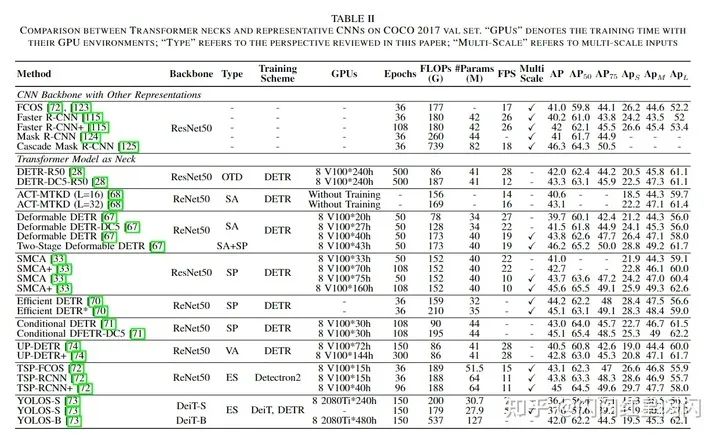
作者在本文中回顧了許多用于圖像分類的基于 Transformer 的主干。這些主干可以很容易地合并到各種框架中(例如,MaskR-CNN、RetinaNet、DETR 等)來執(zhí)行密集預(yù)測(cè)任務(wù)。除了一般的改進(jìn)外,它們中的一部分也有利于改進(jìn)密集預(yù)測(cè)任務(wù)。層次結(jié)構(gòu)將 Transformer 構(gòu)造為一個(gè)從高分辨率到低分辨率的過程來學(xué)習(xí)多尺度特征,如 PVT。局部增強(qiáng)結(jié)構(gòu)將主干構(gòu)建為局部到全局的組合,以有效地提取短程和長(zhǎng)程的視覺依賴性并避免二次計(jì)算開銷,例如 Swin-Transformer、ViL 和 Focal Transformer。下表3在密集預(yù)測(cè)任務(wù)中比較了基于視覺 Transformer 框架的模型。基于 Transformer 的主干比當(dāng)前 CNN 模型的性能高 2-6.8%,這證明了 Transformer 在密集預(yù)測(cè)方面的有效性。
與 FPN 類似,Zhang 等人通過結(jié)合非局部 [14] 和多尺度特征的特性,提出了一種專用于密集預(yù)測(cè)任務(wù)的特征金字塔 Transformer(FPT)[75]。它利用三個(gè)注意力組件來建模跨空間和尺度的交互,包括自注意力、自上而下的交叉注意力和自下而上的跨通道注意力。FPT 作為密集預(yù)測(cè)任務(wù)的通用主干,在許多 SOTA 模型上獲得進(jìn)一步提升。
5.3 討論
本節(jié)在表2和表3中簡(jiǎn)要比較和分析了 Transformer 檢測(cè)器。對(duì)于 Transformer 頸,本文只關(guān)注它們?cè)趩纬叨忍卣鹘Y(jié)構(gòu)中的 FLOPs,而不是多尺度特征,因?yàn)樗鼈儜?yīng)用了不同的層數(shù)。從稀疏注意力(SA)的角度來看,Deformable DETR 減少了 8 GFLOPs 并縮短了 12 倍的訓(xùn)練時(shí)間,而 ACT-DC5 將計(jì)算成本從 187 GFLOPs 降低到 156 GFLOPs,并且性能損失很小。從空間先驗(yàn)(SP)的角度來看,one-stage 檢測(cè)器顯示地將空間先驗(yàn)與目標(biāo)查詢分開,帶來快速收斂和高精度。SMCA 和 Conditional DETR 在 108 個(gè)訓(xùn)練 epoch 時(shí)分別達(dá)到了 42.7% 和 43% 的 mAP。two-stage 檢測(cè)器和 TSP-RCNN 都用 proposals 替換了學(xué)習(xí)到的目標(biāo)查詢。這種本質(zhì)上相同但結(jié)構(gòu)上不同的方法顯著提高了檢測(cè)器的準(zhǔn)確性。從多尺度 (MS) 特征的角度來看,它可以補(bǔ)償 Transformer 在小物體檢測(cè)上的性能。例如,Deformable DETR 和 SMCA 將 DETR 提高了 5.2% 和 3.1% 。僅編碼器的結(jié)構(gòu)減少了 Transformer 層數(shù),但過度增加了 FLOPs,例如具有 537 GFLOPs 的 YOLOS-B。相比之下,編碼器-解碼器的結(jié)構(gòu)是 GFLOPs 和層數(shù)之間的一個(gè)很好的權(quán)衡,但更深的解碼器層可能會(huì)導(dǎo)致長(zhǎng)時(shí)間的訓(xùn)練過程和過度平滑的問題。因此,將 SA 集成到具有 MS 和 SP 的深度解碼器中值得進(jìn)一步研究。
對(duì)于分類,有許多主干的改進(jìn),但很少有工作涉及密集預(yù)測(cè)任務(wù)。基于本文提出的分類法,很容易將現(xiàn)有方法分為兩部分:分層的 Transformer 和局部增強(qiáng)的 Transformer。未來,作者預(yù)計(jì) Transformer 主干將加入深度高分辨率網(wǎng)絡(luò)來解決密集預(yù)測(cè)任務(wù)。
6. 分割中的 Transformer
Transformer 以兩種方式廣泛應(yīng)用于分割:基于 patch 的 Transformer (patch-based Transformer)和基于查詢的 Transformer (query-based Transformer)。后者可以進(jìn)一步分解為帶有目標(biāo)查詢的 Transformer(Transformer with object query) 和帶有掩碼嵌入的Transformer(Transformer with mask embedding)。
6.1 基于 patch 的 Transformer
為了擴(kuò)展感受野,CNN 需要大量的解碼器堆疊來將高級(jí)特征映射到原始空間分辨率。相比之下,依靠全局建模能力,基于 patch 的 Transformer 將輸入圖像視為 patch 序列,并將它們送到一個(gè)柱狀 Transformer 編碼器中。這種分辨率不變策略使 Transformer 能夠僅包含一個(gè)相對(duì)簡(jiǎn)單的解碼器,并為分割任務(wù)獲得理想的性能。此外,一些工作(SETR、TransUNet、Segformer)嘗試研究基于 patch 的 Transformer 與不同分割框架(Mask R-CNN、U-net)之間的最佳組合。
6.2 基于查詢的 Transformer
查詢(Query)是 Transformer 解碼器輸入和輸出處的一個(gè)可學(xué)習(xí)的嵌入。與 patch 嵌入相比,查詢嵌入可以更“公平”地整合每個(gè) patch 的信息。有著集合預(yù)測(cè)損失的基于查詢的 Transformer 能夠刪除其他手工制作的表示和后處理。最近,許多努力試圖將這種表示推廣到可以分為兩類的分割任務(wù)。一類框架是由檢測(cè)任務(wù)監(jiān)督的目標(biāo)查詢所驅(qū)動(dòng)。另一類的查詢僅由分割任務(wù)監(jiān)督,稱為掩碼嵌入。
用目標(biāo)查詢的 Transformer(Transformer with Object Queries)
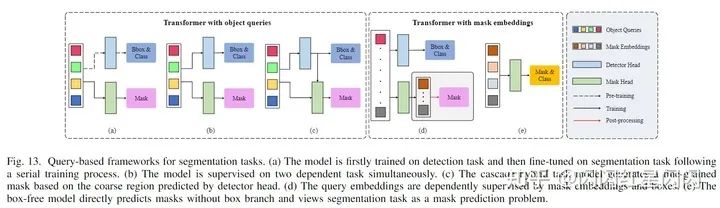
基于目標(biāo)查詢的方法有三種訓(xùn)練方式:
基于 DETR 的預(yù)訓(xùn)練目標(biāo)查詢,一個(gè)帶有查詢的掩碼頭通過分割任務(wù)進(jìn)一步細(xì)化(上圖9(a)所示),如 Panoptic DETR。 代替多階段訓(xùn)練過程,目標(biāo)查詢由一些端到端框架中的檢測(cè)和分割任務(wù)同時(shí)建模(上圖9(b)所示),如 Cell-DETR、VisTR。 用混合級(jí)聯(lián)網(wǎng)絡(luò)構(gòu)建不同任務(wù)分支之間的差距,其中檢測(cè)框的輸出用作掩碼頭的輸入(上圖9(c)所示),如 QueryInst。
用掩碼嵌入的 Transformer(Transformer with Mask Embeddings)
另一類的 Transformer 框架努力使用查詢直接預(yù)測(cè)掩碼,本文將這種基于學(xué)習(xí)掩碼的查詢稱為掩碼嵌入。與目標(biāo)查詢不同,掩碼嵌入僅由分割任務(wù)監(jiān)督。如上圖 9(d)所示,兩個(gè)不相交的查詢集并行用于不同的任務(wù),例如:ISTR 和 SOLQ。對(duì)于語義分割和無框框架,一些研究從基于查詢的 Transformer 中刪除對(duì)象查詢,并直接通過掩碼嵌入來預(yù)測(cè)掩碼(上圖 9(e)),如 Max-DeepLab、Segmenter 和 Maskformer(嚴(yán)格意義上說 Maskformer 結(jié)合了 box-free 和 box-based 方法,使用 box-based 來增強(qiáng) box-free 的效果)。
6.3 討論
作為一項(xiàng)基礎(chǔ)但仍具有挑戰(zhàn)性的任務(wù),分割也從不斷發(fā)展的視覺 Transformers 中受益。本文根據(jù)三種不同的分割子任務(wù)(語義分割、實(shí)例分割和全景分割)總結(jié)了這些 Transformer。
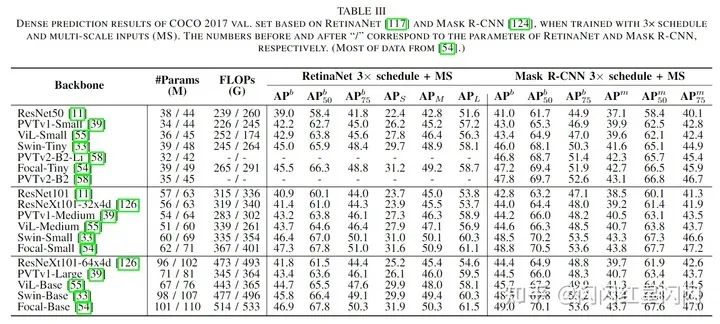
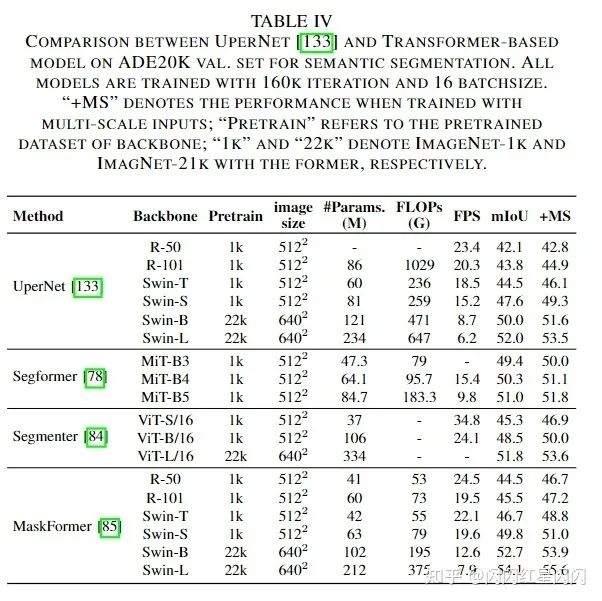
下表 4 側(cè)重于語義分割任務(wù)的 ADE20K 驗(yàn)證集(170 個(gè)類別)。作者發(fā)現(xiàn) Transformer 在有大量類而不是較小類的數(shù)據(jù)集上進(jìn)行訓(xùn)練可以顯示出巨大的性能改進(jìn)。
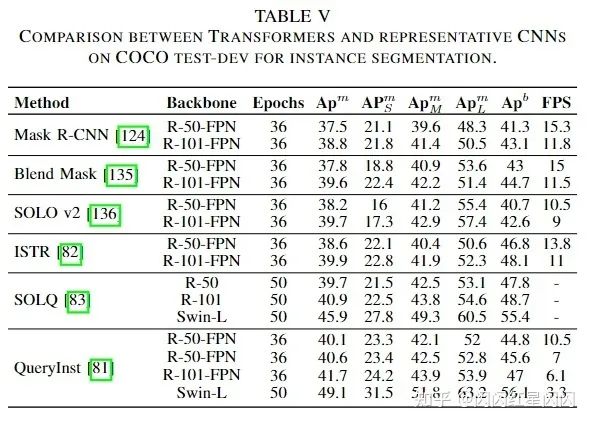
下表 5 側(cè)重于評(píng)估實(shí)例分割任務(wù)的 COCO test-dev 2017 數(shù)據(jù)集。顯然,帶有掩碼嵌入的 Transformer 在分割和檢測(cè)任務(wù)中都超越了以往流行的模型。這些方法顯著提高了 box 的準(zhǔn)確率,但對(duì)分割只有輕微的改進(jìn),從而導(dǎo)致 和 的性能存在巨大差距。基于級(jí)聯(lián)框架,QueryInst 在 Transformer 模型中獲得了 SOTA 性能。因此,Transformer 與混合任務(wù)級(jí)聯(lián)結(jié)構(gòu)的結(jié)合值得進(jìn)一步研究。
下表 6 側(cè)重于評(píng)估全景分割任務(wù)。Max-DeepLab 通常通過掩碼預(yù)測(cè)的方式解決全景分割任務(wù)中的前景和背景,而 Maskformer 成功地將此方式用于語義分割并統(tǒng)一了語義和實(shí)例級(jí)分割任務(wù)。基于它們?cè)谌胺指铑I(lǐng)域的表現(xiàn),可以得出結(jié)論:Transformer 可以將多個(gè)分割任務(wù)統(tǒng)一到一個(gè)具有掩碼預(yù)測(cè)的無框框架中。

7. 討論和總結(jié)
7.1 總結(jié)最近的改進(jìn)
基于之前的比較和討論,作者簡(jiǎn)要總結(jié)了三個(gè)基本任務(wù)(分類、檢測(cè)和分割)的最新改進(jìn)。
對(duì)于分類,深的層次的 Transformer 主干可有效降低計(jì)算復(fù)雜度并避免深層中的特征過度平滑。同時(shí),早期的卷積足以捕獲低級(jí)特征,可以顯著增強(qiáng)魯棒性并降低淺層的計(jì)算復(fù)雜度。 此外,卷積投影和局部注意機(jī)制都可以提高Transformer的局部性。前者也可能是一種替代位置編碼的新方法。 對(duì)于檢測(cè),Transformer 頸部受益于編碼器-解碼器結(jié)構(gòu),其計(jì)算量少于僅編碼器的 Transformer 檢測(cè)器。因此,解碼器是必要的,但由于其收斂速度慢,因此只需要很少的堆疊即可。此外,稀疏注意力有利于降低計(jì)算復(fù)雜度并加速 Transformer 的收斂,而空間先驗(yàn)有利于Transformer的性能,收斂速度稍快。 對(duì)于分割,編碼器-解碼器 Transformer 模型可以通過一系列可學(xué)習(xí)的掩碼嵌入將三個(gè)分割子任務(wù)統(tǒng)一為掩碼預(yù)測(cè)問題。這種無框的方法在多個(gè)基準(zhǔn)測(cè)試中取得了最新的 SOTA (MaskFormer)。此外,基于框的 Transformer 的特定混合任務(wù)的級(jí)聯(lián)模型被證實(shí)可以在實(shí)例分割任務(wù)中獲得更高的性能。
7.2 視覺 Transformer 的討論
盡管有大量的視覺 Transformer 模型和應(yīng)用,但對(duì)視覺 Transformer 的“基本”理解仍然效率低下。因此,本文將重點(diǎn)關(guān)注一些關(guān)鍵問題,以幫助解決讀者的困惑。
7.2.1 Transformer 如何彌合語言和視覺之間的鴻溝
Transformer 最初是為機(jī)器翻譯任務(wù)而設(shè)計(jì)的。在語言模型中,以句子的每個(gè)詞為基本單元,代表高層次、高維的語義信息。這些詞可以嵌入到低維向量空間表示中,因此稱為詞嵌入。在視覺任務(wù)中,圖像的每個(gè)像素都是低級(jí)、低維的語義信息,與嵌入特征不匹配。因此,遷移到視覺任務(wù)的關(guān)鍵是構(gòu)建圖像到矢量的轉(zhuǎn)換并保持圖像的特征。例如,ViT 通過強(qiáng)松弛條件將圖像轉(zhuǎn)換為具有多個(gè)低級(jí)信息的 patch 嵌入,而 Early Conv. 和 CoAtNet 利用卷積來提取高級(jí)信息并減少 patch 中的冗余特征。
7.2.2 Transformer、自注意力與 CNN 的關(guān)系
從卷積的角度來看,如上提到的 4.3 節(jié),其歸納偏置主要表現(xiàn)為局部性、平移不變性、權(quán)重共享、稀疏連接。這種簡(jiǎn)單的卷積核可以有效地執(zhí)行模板匹配,但由于其具有強(qiáng)烈的歸納偏差(因?yàn)楹芸炀涂梢允諗繉W(xué)習(xí)好了),其上限低于 Transformer。
從自注意力機(jī)制的角度來看,如上提到的 4.2 和 4.4 節(jié),當(dāng)給定足夠數(shù)量的頭時(shí),它理論上可以表達(dá)任何卷積層。這種全注意力操作可以交替地結(jié)合局部和全局級(jí)別的注意力,并根據(jù)特征的關(guān)系動(dòng)態(tài)生成注意力權(quán)重。即便如此,它的實(shí)用性也較差,準(zhǔn)確率低于 SOTA CNN,計(jì)算復(fù)雜度更高。
從 Transformer 的角度來看,Dong 等人證明當(dāng)在沒有短連接或 FFNs 的深層訓(xùn)練時(shí),自注意力層會(huì)表現(xiàn)出對(duì)“令牌均勻性(token uniformity)”的強(qiáng)烈歸納偏見。得出的結(jié)論是,Transformer 由兩個(gè)關(guān)鍵組件組成:一個(gè) self-attention 層聚合了 token 的關(guān)系,一個(gè) position-wise FFN 提取了輸入的特征。盡管 Transformer 具有強(qiáng)大的全局建模能力,如 4.3 節(jié)和 7.2.1 節(jié)所述,卷積可以有效處理低級(jí)特征,增強(qiáng) Transformer 的局部性,并通過填充附加位置特征。
7.2.3 不同視覺任務(wù)中的可學(xué)習(xí)到的嵌入
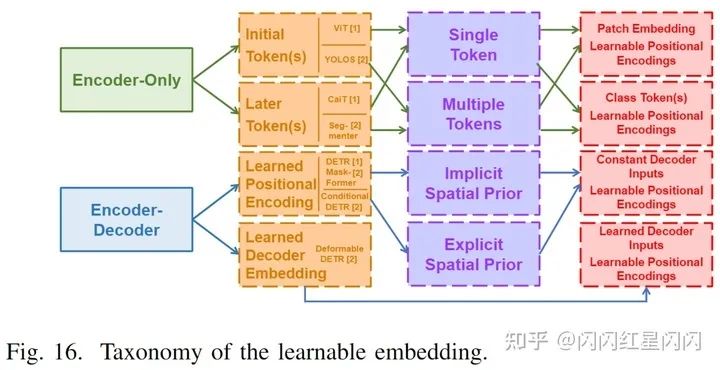
Transformer 模型采用可學(xué)習(xí)的嵌入來執(zhí)行不同的視覺任務(wù)。從監(jiān)督任務(wù)的角度來看,這些嵌入可以分為類標(biāo)記、目標(biāo)查詢和掩碼嵌入。從結(jié)構(gòu)上看,它們之間是有內(nèi)在聯(lián)系的。最近的 Transformer 方法主要采用兩種不同的模式:僅編碼器結(jié)構(gòu)和編碼器-解碼器結(jié)構(gòu)。每個(gè)結(jié)構(gòu)由三個(gè)層次的嵌入組成,如上圖 10 所示。從位置層次,學(xué)習(xí)嵌入在僅編碼器的 Transformer 中的應(yīng)用被分解為初始令牌(initial token)和后期令牌(later token),而學(xué)習(xí)的位置編碼和學(xué)習(xí)的解碼器輸入嵌入被應(yīng)用于編碼器-解碼器結(jié)構(gòu)。從數(shù)量層面來看,僅編碼器的設(shè)計(jì)會(huì)應(yīng)用不同數(shù)量的令牌。例如,ViT 家族和 YOLOS 將不同的數(shù)字標(biāo)記附加到初始層,而 CaiT 和 Segmenter 利用這些標(biāo)記來表示最后幾層的不同特征。在編碼器 - 解碼器結(jié)構(gòu)中,解碼器的學(xué)習(xí)位置編碼(目標(biāo)查詢或掩碼嵌入)在顯式 [28]、[137] 或隱式 [69] 中附加到解碼器的輸入中。與常數(shù)輸入不同,Deformable DETR 采用學(xué)習(xí)嵌入作為輸入并加入到編碼器的輸出。
受多頭注意力設(shè)計(jì)的啟發(fā),多初始的標(biāo)記策略應(yīng)該能進(jìn)一步提高分類性能。然而,DeiT 表明這些額外的令牌會(huì)收斂到相同的結(jié)果,這對(duì) ViT 沒有好處。從另一個(gè)角度來看,YOLOS 提供了一種通過使用多個(gè)初始令牌來統(tǒng)一分類和檢測(cè)的范式,但這種僅編碼器的設(shè)計(jì)會(huì)導(dǎo)致計(jì)算復(fù)雜度過高。根據(jù)CaiT 的觀察,后面的 class token 可以減少 Transformer 的一些 FLOPs 并略微提高性能(從79.9%到80.5%)。Segmenter 還展示了該策略在分割任務(wù)中的效率。
與帶有僅編碼器 Transformer 的多個(gè)后期令牌(later token)相比,編碼器-解碼器結(jié)構(gòu)節(jié)省了更多的計(jì)算。它通過使用一小組目標(biāo)查詢(掩碼嵌入)來標(biāo)準(zhǔn)化檢測(cè)和分割領(lǐng)域中的 Transformer 方法。通過結(jié)合多個(gè)后期令牌和目標(biāo)查詢(掩碼嵌入)的形式,像 Deformable DETR 這樣的結(jié)構(gòu),它們對(duì)目標(biāo)查詢和可學(xué)習(xí)的解碼器嵌入(相當(dāng)于多個(gè)后期令牌)作為輸入,可以將基于不同任務(wù)的可學(xué)習(xí)嵌入統(tǒng)一到 Transformer 編碼器-解碼器中。
7.3 未來的研究方向
Visual Transformer 方法取得了巨大的進(jìn)步,并顯示出在多個(gè)基準(zhǔn)上接近或超過 SOTA CNN 方法的有希望的結(jié)果。然而,該技術(shù)太不成熟,無法顛覆卷積在 CV 領(lǐng)域的主導(dǎo)地位。基于 7.2 中的分析,作者指出了視覺 Transformer 的一些有前途的未來方向,以進(jìn)一步進(jìn)行整體串聯(lián)。
1)集合預(yù)測(cè):如上 7.2.3 節(jié)所述,由于損失函數(shù)的梯度相同,額外的類標(biāo)記(token)將一致收斂。具有二分損失函數(shù)的集合預(yù)測(cè)策略已廣泛應(yīng)用于許多密集預(yù)測(cè)任務(wù)中的視覺 Transformer 里。如之前提到的,為分類任務(wù)考慮集合預(yù)測(cè)設(shè)計(jì)是很自然的,例如多類標(biāo)記 Transformer 通過集合預(yù)測(cè)來預(yù)測(cè)混合 patch 圖像,這類似于 LV-ViT 的數(shù)據(jù)增強(qiáng)策略。此外,在集合預(yù)測(cè)策略中的一對(duì)一標(biāo)簽分配導(dǎo)致早期過程中的訓(xùn)練不穩(wěn)定,這可能會(huì)降低最終結(jié)果的準(zhǔn)確性。使用其他標(biāo)簽分配和損失來改進(jìn)集合預(yù)測(cè)可能有助于新的檢測(cè)框架。
2)自監(jiān)督學(xué)習(xí):自監(jiān)督 Transformer 預(yù)訓(xùn)練規(guī)范了NLP領(lǐng)域,并在各種應(yīng)用中取得了巨大成功。作為 CV 中的自監(jiān)督范式,卷積孿生網(wǎng)絡(luò)采用對(duì)比學(xué)習(xí)來執(zhí)行自監(jiān)督預(yù)訓(xùn)練,這與 NLP 中的基于 mask 的自編碼器不同。最近,一些研究嘗試設(shè)計(jì)一種自監(jiān)督的視覺 Transformer,以彌合視覺和語言之間預(yù)訓(xùn)練方法的差距。他們中的大多數(shù)繼承了 NLP 中的掩碼自編碼器或 CV 中的對(duì)比學(xué)習(xí)方案。但是,沒有像 NLP 中的 GPT-3 那樣革命性的用于視覺 Transformer 的特定監(jiān)督方法。如上 7.2.3 節(jié)所述,編碼器-解碼器結(jié)構(gòu)可以通過學(xué)習(xí)的解碼器嵌入和位置編碼來統(tǒng)一視覺任務(wù)。用于自監(jiān)督學(xué)習(xí)的編碼器-解碼器 Transformer 值得我們進(jìn)一步研究。
7.4 總結(jié)
在 ViT 證明了其在 CV 任務(wù)中的有效性后,視覺 Transformer 受到了相當(dāng)多的關(guān)注,并削弱了 CNN 的主導(dǎo)地位。在本文中,本文全面回顧了 100 多個(gè) Transformer 模型,這些 Transformer 模型已先后應(yīng)用于各種視覺任務(wù)中,包括分類、檢測(cè)和分割。對(duì)于每個(gè)任務(wù),提出了一種具體的分類法來組織最近開發(fā)的 Transformer 方法,并在各種流行的基準(zhǔn)上對(duì)它們的性能進(jìn)行了評(píng)估。通過對(duì)這些方法的綜合分析和系統(tǒng)比較,本文總結(jié)了具有顯著改進(jìn)的方法,討論了視覺 Transformer 的三個(gè)基本問題,并進(jìn)一步提出了未來有希望的幾個(gè)潛在研究方向。
交流群
歡迎加入公眾號(hào)讀者群一起和同行交流,目前有美顏、三維視覺、計(jì)算攝影、檢測(cè)、分割、識(shí)別、醫(yī)學(xué)影像、GAN、算法競(jìng)賽等微信群
個(gè)人微信(如果沒有備注不拉群!) 請(qǐng)注明:地區(qū)+學(xué)校/企業(yè)+研究方向+昵稱
下載1:何愷明頂會(huì)分享
在「AI算法與圖像處理」公眾號(hào)后臺(tái)回復(fù):何愷明,即可下載。總共有6份PDF,涉及 ResNet、Mask RCNN等經(jīng)典工作的總結(jié)分析
下載2:終身受益的編程指南:Google編程風(fēng)格指南
在「AI算法與圖像處理」公眾號(hào)后臺(tái)回復(fù):c++,即可下載。歷經(jīng)十年考驗(yàn),最權(quán)威的編程規(guī)范!
下載3 CVPR2021 在「AI算法與圖像處理」公眾號(hào)后臺(tái)回復(fù):CVPR,即可下載1467篇CVPR?2020論文 和 CVPR 2021 最新論文
