點(diǎn)擊左上方藍(lán)字關(guān)注我們

全網(wǎng)搜集目標(biāo)檢測(cè)相關(guān),人工篩選最優(yōu)價(jià)值內(nèi)容
異常檢測(cè)提供了在數(shù)據(jù)中發(fā)現(xiàn)模式、偏差和異常的途徑,這些模式、偏差和異常不限于模型的標(biāo)準(zhǔn)行為。隨著數(shù)據(jù)呈指數(shù)級(jí)增長(zhǎng),分析數(shù)據(jù)并得出形成重要業(yè)務(wù)決策基礎(chǔ)的見(jiàn)解已成為一種普遍趨勢(shì)。我們不僅需要分析數(shù)據(jù),還需要準(zhǔn)確地解釋數(shù)據(jù)。找出異常并確定異常行為可以讓我們找到最佳解決方案。
- 設(shè)置 PyCaret 環(huán)境并嘗試準(zhǔn)備任務(wù)的各種數(shù)據(jù)
介紹
異常檢測(cè)可以應(yīng)用于各種領(lǐng)域。下面列出了其中一些。- 網(wǎng)絡(luò)安全 —?監(jiān)控網(wǎng)絡(luò)流量并確定異常值
- 欺詐檢測(cè)——?可以識(shí)別信用卡欺詐
- IT 部門 —發(fā)現(xiàn)并應(yīng)對(duì)意外風(fēng)險(xiǎn)
許多機(jī)器學(xué)習(xí)算法可用于異常檢測(cè),它在檢測(cè)和分類復(fù)雜數(shù)據(jù)集中的異常值方面起著至關(guān)重要的作用。為什么是 PyCaret?
PyCaret是一個(gè)開(kāi)源、低代碼的 Python 機(jī)器學(xué)習(xí)庫(kù),支持多種功能,例如在幾行代碼中就可以為部署建模的數(shù)據(jù)準(zhǔn)備。- 它是一個(gè)靈活的低代碼庫(kù),可以提高生產(chǎn)力,從而節(jié)省時(shí)間和精力。
- PyCaret 是一個(gè)簡(jiǎn)單易用的機(jī)器學(xué)習(xí)庫(kù),使我們能夠在幾分鐘內(nèi)執(zhí)行 ML 任務(wù)。
- PyCaret 庫(kù)允許自動(dòng)化機(jī)器學(xué)習(xí)步驟,例如數(shù)據(jù)轉(zhuǎn)換、準(zhǔn)備、超參數(shù)調(diào)整和標(biāo)準(zhǔn)模型比較。
學(xué)習(xí)目標(biāo)
PyCaret 安裝
在你的 jupyter notebook 中安裝最新版本的 Pycaret 并開(kāi)始使用!數(shù)據(jù)導(dǎo)入
讓我們從 PyCaret 預(yù)先配置的數(shù)據(jù)集中導(dǎo)入一個(gè)常見(jiàn)的異常檢測(cè)數(shù)據(jù)集,開(kāi)始我們的動(dòng)手項(xiàng)目。導(dǎo)入必要的庫(kù)
首先,導(dǎo)入整個(gè)項(xiàng)目所需的必要庫(kù)。import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
導(dǎo)入數(shù)據(jù)集
from pycaret.datasets import get_data
all_datasets = get_data(‘index’)
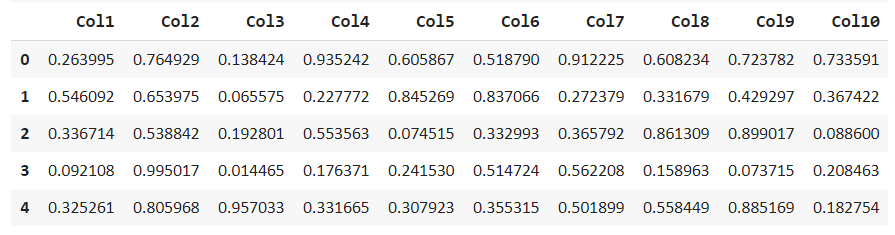
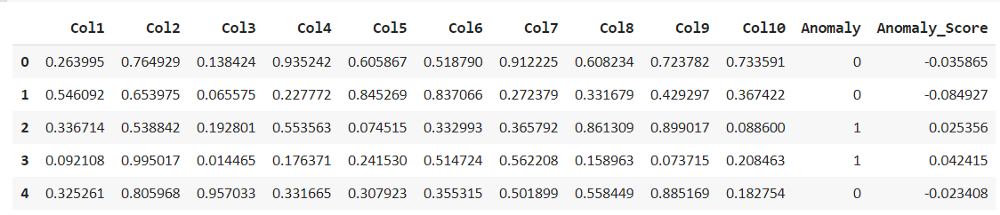
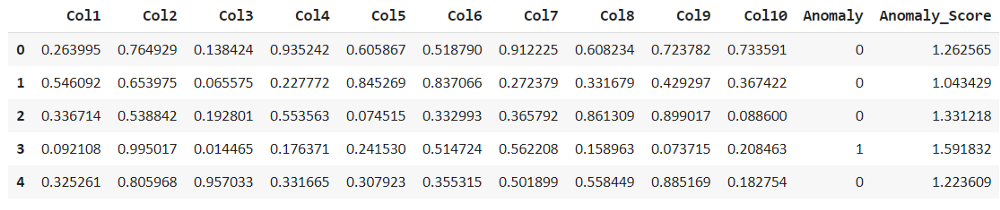
現(xiàn)在我們可以看到所有列出的具有默認(rèn)機(jī)器學(xué)習(xí)任務(wù)的數(shù)據(jù)集。我們只需要訪問(wèn)通過(guò)get_data()函數(shù)可以獲得的異常數(shù)據(jù)。df = get_data(‘a(chǎn)nomaly’)
df.head()
探索和描述此數(shù)據(jù)集以查找缺失值并獲得統(tǒng)計(jì)分布。我們可以注意到數(shù)據(jù)集沒(méi)有任何缺失值。探索性異常檢測(cè)分析
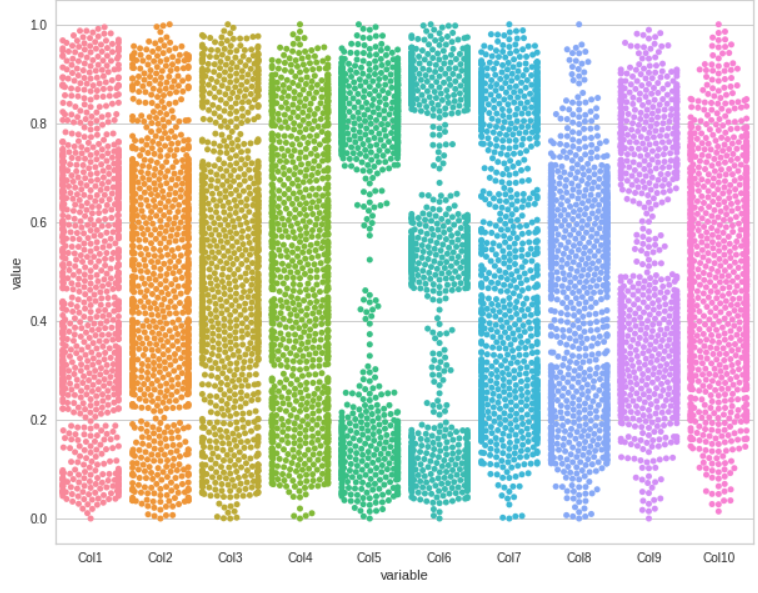
現(xiàn)在我們可以使用各種可視化方法來(lái)解釋數(shù)據(jù)集中的異常值和異常。Swarm 圖
使用melt()函數(shù)獲取數(shù)據(jù)集的Swarm圖。plt.rcParams["figure.figsize"] = (10,8)
sns.swarmplot(x="variable", y="value", data=pd.melt(df))
plt.show()
箱形圖
通過(guò)箱形圖可視化數(shù)據(jù)集,這讓我們清楚地了解大部分?jǐn)?shù)據(jù)所在的位置。sns.boxplot(x="variable", y="value", data=pd.melt(df))
plt.show()
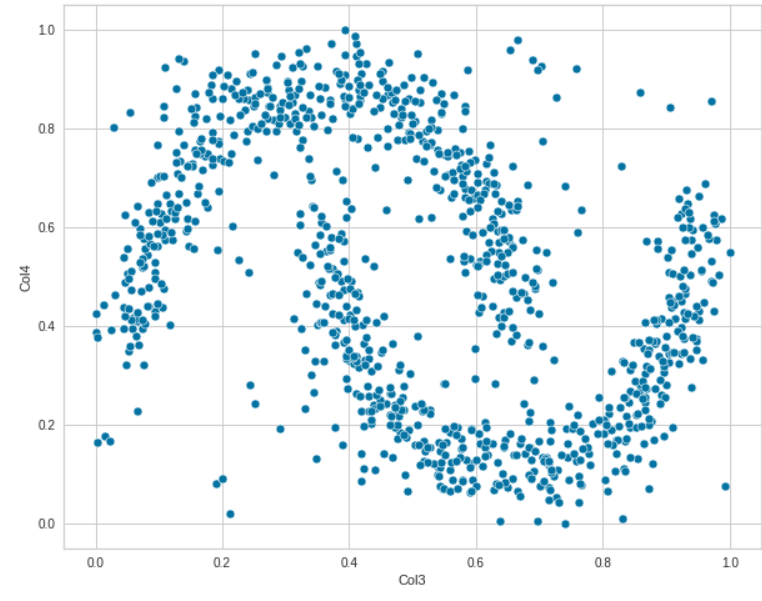
散點(diǎn)圖
我們可以通過(guò)散點(diǎn)圖確定兩個(gè)特征之間的線性關(guān)系。此處明確定義了Col1和Col2之間的關(guān)系。sns.scatterplot(data=df, x="Col1", y='Col2')
我們也可以嘗試不同的特征。探索各種特征如何相互關(guān)聯(lián)。sns.scatterplot(data=df, x="Col3", y='Col4')
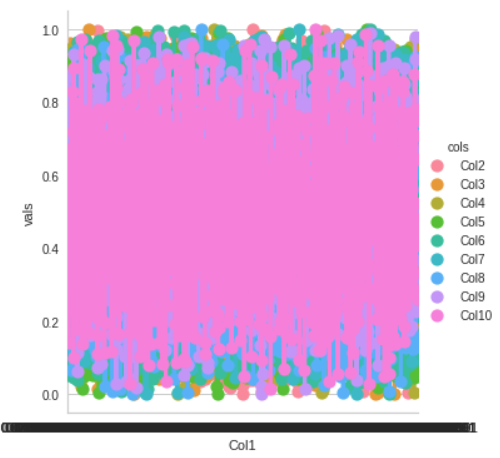
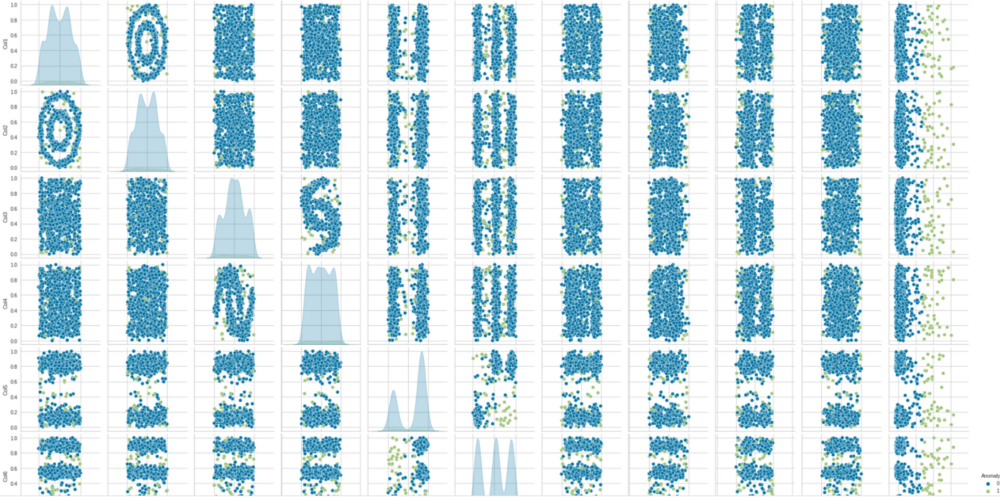
這些圖表明數(shù)據(jù)之間沒(méi)有線性關(guān)系。現(xiàn)在讓我們使用 Seaborn 成對(duì)分析所有特征之間的關(guān)系。該成對(duì)圖確定了不同列之間的關(guān)系以及它們?nèi)绾闻c直方圖一起以多種方式區(qū)分值。通過(guò)這種方式,我們可以為我們的模型解釋多個(gè)維度的邊界。df1 = df.melt(‘Col1’, var_name=’cols’, value_name=’vals’)
g = sns.factorplot(x=”Col1", y=”vals”, hue=’cols’, data=df1)
異常檢測(cè)
為異常檢測(cè)設(shè)置 PyCaret 環(huán)境。為此,我們可以使用 Pycaret 的異常檢測(cè)模塊,這是一個(gè)無(wú)監(jiān)督的機(jī)器學(xué)習(xí)模塊,用于識(shí)別數(shù)據(jù)中可能導(dǎo)致異常情況的異常值。from pycaret.anomaly import *
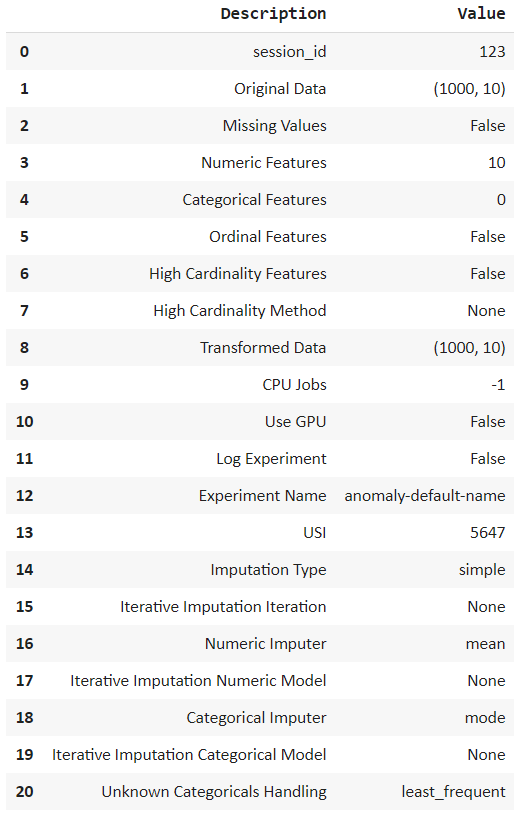
setup = setup(df, session_id = 123)
指定會(huì)話 id,這會(huì)導(dǎo)致執(zhí)行后進(jìn)行處理。它會(huì)自動(dòng)解釋多種類型的變量,并允許我們通過(guò)按ENTER進(jìn)行確認(rèn)。觀察我們的數(shù)據(jù)集由 10 個(gè)特征組成,每個(gè)特征 1000 行。我們可以執(zhí)行各種插補(bǔ)——數(shù)字和分類或歸一化數(shù)據(jù)。但是我們不需要在我們的數(shù)據(jù)集中進(jìn)行這樣的轉(zhuǎn)換,所以讓我們繼續(xù)!用幾行代碼執(zhí)行所有這些計(jì)算顯示了PyCaret庫(kù)的美妙之處。模型創(chuàng)建
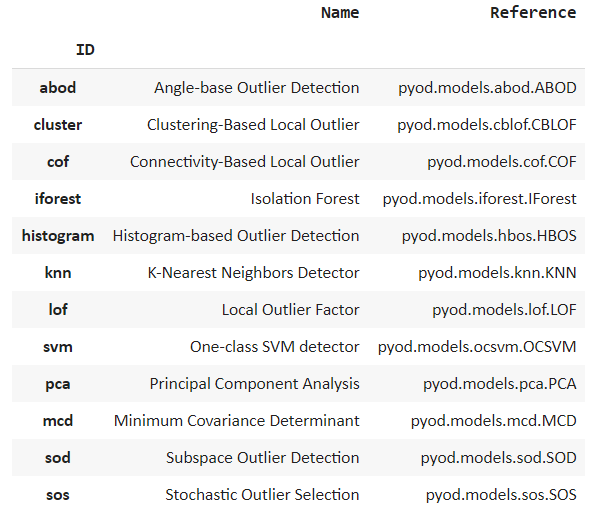
從模型庫(kù)中選擇最佳模型并創(chuàng)建用于異常檢測(cè)的模型。我們可以使用**model()**函數(shù)顯示模型列表。我們可以看到列出了許多流行的算法,例如隔離森林和 k 最近鄰。隔離森林
使用create_model()函數(shù)創(chuàng)建隔離森林模型。隔離森林算法通過(guò)隨機(jī)選擇一個(gè)特征,然后隨機(jī)選擇最大值和最小值之間的分割值來(lái)區(qū)分觀察。iforest = create_model('iforest')
print(iforest)
因此,異常分?jǐn)?shù)被確定為分離給定觀察所需的條件數(shù)量。局部異常因子
它是一種無(wú)監(jiān)督異常檢測(cè)方法的算法,計(jì)算數(shù)據(jù)點(diǎn)相對(duì)于其鄰居的局部密度偏差。lof = create_model('lof')
print(lof)
K最近鄰
KNN 是一種非參數(shù)惰性學(xué)習(xí)算法,用于根據(jù)相似性和各種距離度量對(duì)數(shù)據(jù)進(jìn)行分類。它提供了一種簡(jiǎn)單而可靠的方法來(lái)檢測(cè)異常。knn = create_model('knn')
print(knn)neighbours
比較模型中的異常
繼續(xù)我們的任務(wù),我們現(xiàn)在可以觀察模型確定的異常情況。傳統(tǒng)上,我們必須手動(dòng)設(shè)置不同的參數(shù)。但是通過(guò)使用 PyCaret,我們可以通過(guò)分配的模型函數(shù)來(lái)分配結(jié)果。我們將從隔離森林模型開(kāi)始。iforest_results = assign_model(iforest)
iforest_results.head()
assign_model()函數(shù)返回一個(gè)檢測(cè)異常的數(shù)據(jù)幀,異常值的存在標(biāo)記為 1,非異常值標(biāo)記為 0,以及異常分?jǐn)?shù)。同樣,我們也可以分配其他模型。所以可以進(jìn)行比較。lof_results = assign_model(lof)
lof_results.head()
比較上述模型我們可以看到,隔離森林已經(jīng)將第二行視為異常,但局部異常因子并未將其視為異常。但不同算法的異常得分不同。對(duì)于 k 個(gè)最近鄰,預(yù)測(cè)分?jǐn)?shù)與隔離森林的預(yù)測(cè)分?jǐn)?shù)非常相似。knn_results = assign_model(knn)
knn_results.head()
按每個(gè)模型過(guò)濾異常,這表明 iforest 模型將 1000 行中的 50 行視為異常。iforest_anomaly=iforest_results[iforest_results['Anomaly']==1]
iforest_anomaly.shape
同樣,檢查L(zhǎng)OF和KNN,我們可以看到它們都考慮了50個(gè)異常。必須使用不同的計(jì)算方法來(lái)查找異常值。lof_anomaly=lof_results[lof_results['Anomaly']==1]
lof_anomaly.shape
knn_anomaly=knn_results[knn_results['Anomaly']==1]
knn_anomaly.shape
根據(jù)以上結(jié)果,我們可以得出結(jié)論,1000 個(gè)異常中最有可能有 50 個(gè)。驗(yàn)證的一種方法是分析它們中的哪一個(gè)更適合于對(duì)模型標(biāo)記為離群值的數(shù)據(jù)進(jìn)行分析,并比較它們對(duì)測(cè)試數(shù)據(jù)的影響,或者進(jìn)行分析,看看它們是否位于決策邊界內(nèi)。解釋和可視化
可視化是以創(chuàng)造性和獨(dú)立的方式解釋手頭信息的最便捷方式。讓我們首先從 PyCaret 庫(kù)外部創(chuàng)建視覺(jué)效果,這將突出 PyCaret 庫(kù)的好處,并使我們能夠了解plot_model函數(shù)如何更具交互性。from yellowbrick.features import Manifold
dfr = iforest_results['Anomaly']
viz = Manifold(manifold="tsne")
viz.fit_transform(df, dfr)
viz.show()
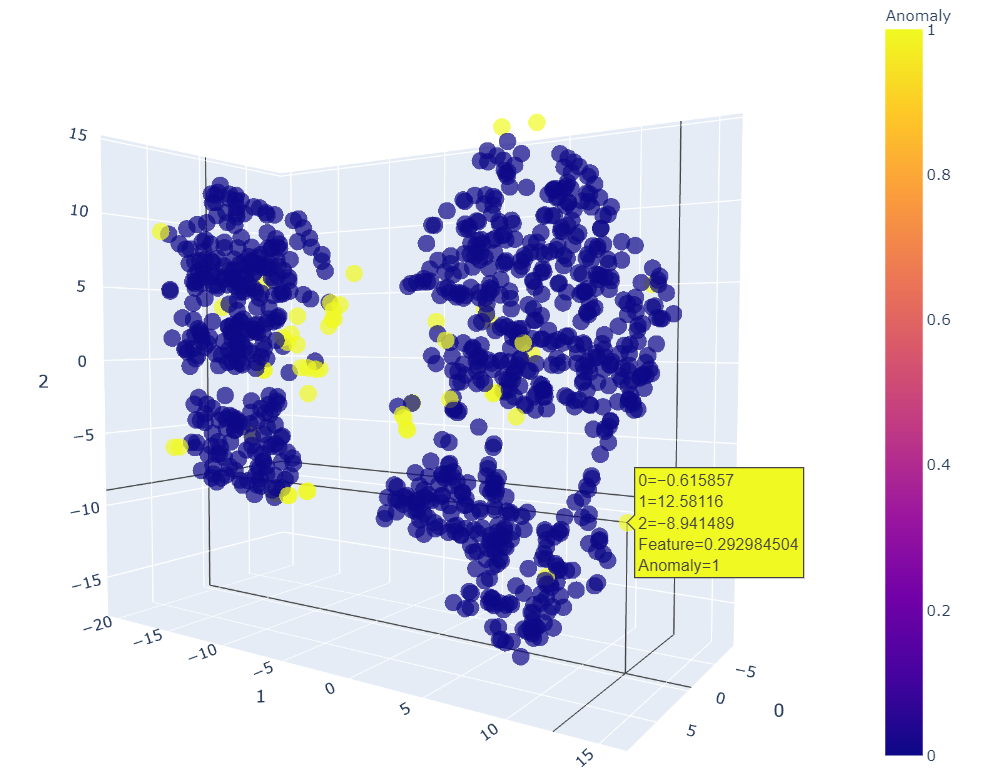
我們可以看到,隔離森林在多個(gè)維度上確定的大多數(shù)異常通常來(lái)自不同的集群。現(xiàn)在在PyCaret 中為 KNN使用plot_model() 函數(shù),它將為異常值創(chuàng)建一個(gè) 3D 圖,在其中我們可以看到為什么某些特征被視為異常。我們可以在任何維度上移動(dòng)它以查看和指出異常。這個(gè) 3D 繪圖有助于我們更好地查看它。KNN 圖顯示大多數(shù)異常值是那些不屬于任何集群的異常值。所以這很好!很明顯,數(shù)據(jù)集被分成了四個(gè)不同的集群,所以這些組之外的任何東西都肯定是異常的。異常并不總是壞兆頭!有時(shí)它們?cè)诮忉尳Y(jié)果或數(shù)據(jù)分析方面非常有用。這些可用于解決不同的數(shù)據(jù)科學(xué)用例。
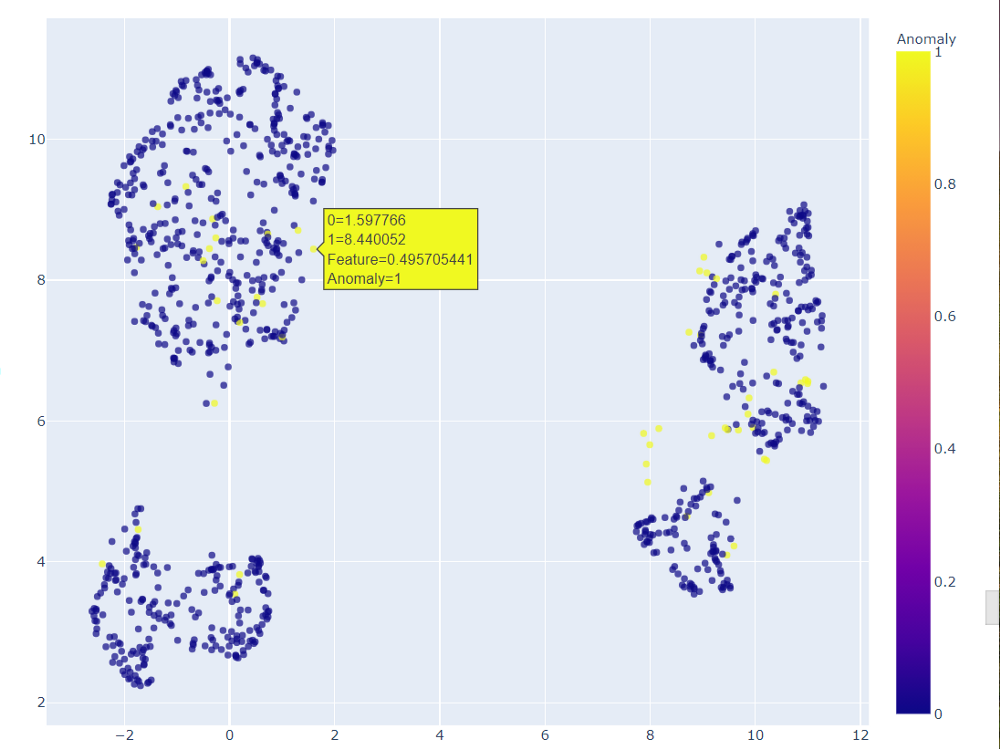
接下來(lái)是第三種模式。線性離群因子,我們可以用一個(gè)不同的圖來(lái)實(shí)驗(yàn),創(chuàng)造一個(gè)2D圖。我們可以放大這個(gè)二維圖來(lái)查看哪些點(diǎn)被認(rèn)為是異常值。可以再次為配對(duì)圖創(chuàng)建另一個(gè)視覺(jué)效果,現(xiàn)在使用異常來(lái)查看哪些點(diǎn)將被視為異常。sns.pairplot(lof_results, hue = "Anomaly")
最后,我們可以保存模型。可以保存任何合適的模型。這里我們保存了 iforest 模型。save_model(iforest,'IForest_Model')
模型與示例數(shù)據(jù)和日志一起成功保存。尾注
這標(biāo)志著我們關(guān)于異常檢測(cè)的動(dòng)手項(xiàng)目的結(jié)束。我們已經(jīng)討論了 PyCaret 庫(kù)的用例和實(shí)現(xiàn),以及它如何用于異常檢測(cè)。PyCaret 是一個(gè)快速可靠的機(jī)器學(xué)習(xí)庫(kù),通常被數(shù)據(jù)科學(xué)家用來(lái)解決復(fù)雜的業(yè)務(wù)問(wèn)題。在創(chuàng)建可部署模型的同時(shí),可以擴(kuò)展該項(xiàng)目進(jìn)行進(jìn)一步的實(shí)驗(yàn)和探索。雙一流大學(xué)研究生團(tuán)隊(duì)創(chuàng)建,專注于目標(biāo)檢測(cè)與深度學(xué)習(xí),希望可以將分享變成一種習(xí)慣!整理不易,點(diǎn)贊三連↓