
【論文解讀】DeepFM論文總結(jié)
本次要總結(jié)分享的是 推薦/CTR 領(lǐng)域內(nèi)著名的deepfm[1] 論文,參考的代碼tensorflow-DeepFM[2],該論文方法較為簡(jiǎn)單,實(shí)現(xiàn)起來也比較容易,該方法在工業(yè)界十分常用。
「建議在非深色主題下閱讀本文,pc端閱讀點(diǎn)擊文末左下角“原文鏈接”,體驗(yàn)更佳」
@
論文動(dòng)機(jī)及創(chuàng)新點(diǎn)
模型結(jié)構(gòu)
輸入數(shù)據(jù)
FM 部分
Deep 部分
代碼分析
數(shù)據(jù)預(yù)處理
定義 DeepFM 模型超參數(shù)
構(gòu)圖
總結(jié)
論文動(dòng)機(jī)及創(chuàng)新點(diǎn)
在 deepfm 提出之前,現(xiàn)有的模型很難很好的提取低階和高階的交互特征,或者需要足夠豐富的人工特征工程才能進(jìn)行。 一些特性交互很容易理解,可以由專家(對(duì)業(yè)務(wù)邏輯很了解的人)設(shè)計(jì)。然而,大多數(shù)其他的特征交互都隱藏在數(shù)據(jù)中,難以識(shí)別先驗(yàn)信息(例如,經(jīng)典的關(guān)聯(lián)規(guī)則“尿布和啤酒”是從數(shù)據(jù)中挖掘出來的,而不是由專家發(fā)現(xiàn)),這只能通過機(jī)器學(xué)習(xí)自動(dòng)獲取。即使對(duì)于易于理解的交互特征,專家似乎也不太可能對(duì)它們進(jìn)行窮盡式的建模,尤其是當(dāng)特征數(shù)量很大的時(shí)候。
?所以對(duì)于許多數(shù)據(jù)挖掘類比賽,特征工程的工作量幾乎占到工作量的 95%以上,大部分甚至一些優(yōu)秀選手,首先一股腦的把所能想到的特征都使用上,然后根據(jù)效果做些適當(dāng)特征選擇。當(dāng)選取的特征效果的確很好時(shí),把構(gòu)建這些特征的思路包裝成某一個(gè)聽起來很高逼格的”方法論“。
?
很容易想到,有沒有什么辦法,能讓模型能端到端的進(jìn)行特征學(xué)習(xí)呢?從而避免繁雜的人工特征工程過程。deepfm 論文里就是基于這一動(dòng)機(jī),將 fm 模型和 DNN 模型聯(lián)合起來進(jìn)行訓(xùn)練,其中 fm 模型可能捕捉到一些低階的交互特征,而 DNN 模型捕捉一些高階模型。該聯(lián)合模型可以進(jìn)行端到端的訓(xùn)練學(xué)習(xí)。 Deepfm 模型中的 Deep 部分和 fm 部分共享 embedding,極大減少了需要學(xué)習(xí)的參數(shù),使其訓(xùn)練過程很有效率。 和以往的 CTR 模型相比,Deepfm 模型效果最好。
模型結(jié)構(gòu)
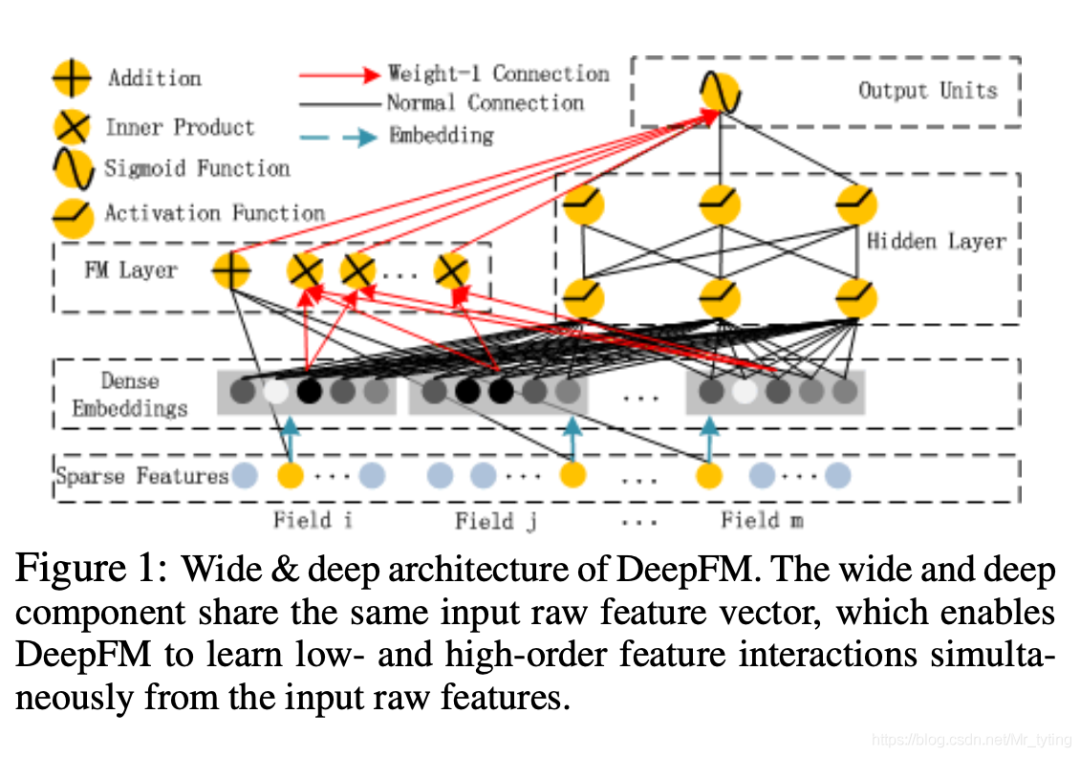
上圖為 DeepFM 的網(wǎng)絡(luò)結(jié)構(gòu)圖,由左邊的 FM 模型和右邊的 DNN 模型組成,兩個(gè)子模型共享下方的輸入 embedding。
輸入數(shù)據(jù)
假定有 個(gè)樣本,每個(gè)樣本由 組成,其中
由 個(gè)特征組成,其中包含了 「類別」型特征 和 「數(shù)值」型特征組成,每個(gè)特征可理解為一個(gè) 。
?其中 類別 型特征可用 one-hot 編碼表示,數(shù)值型特征用其本身數(shù)值或者離散化在 one-hot 表示
?
這里定義 表示特征個(gè)數(shù); 表示 (數(shù)值特征個(gè)數(shù)+類別特征「取值」個(gè)數(shù)); 表示
?類別特征 one-hot 后向量長(zhǎng)度即為取值個(gè)數(shù)
?
FM 部分
這里定義兩個(gè)參數(shù)矩陣
feature_bias:shape 為 的一階參數(shù)矩陣 feature_embeddings:shape 為 的二階參數(shù)矩陣 <> 表示內(nèi)積 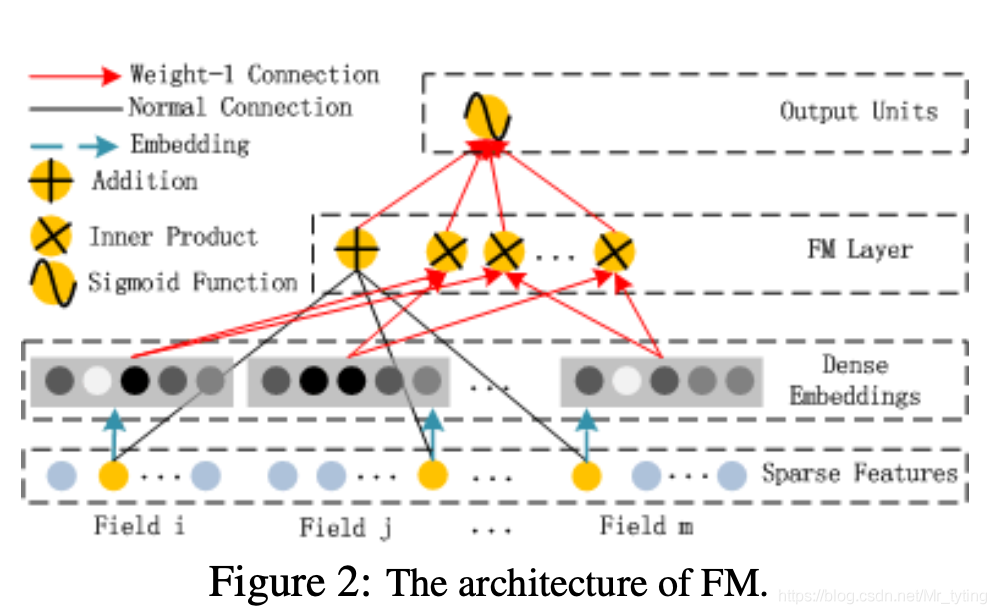 不得不說:這篇論文里面的網(wǎng)絡(luò)圖都畫的好丑
不得不說:這篇論文里面的網(wǎng)絡(luò)圖都畫的好丑
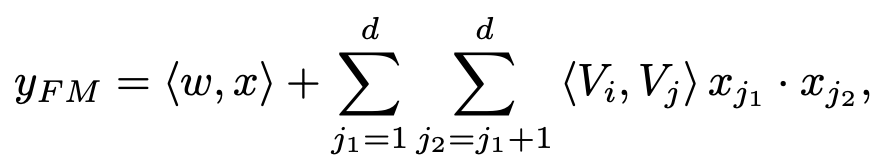
上式中 第一項(xiàng)
d 表示 ,第二項(xiàng)是在不同 field 之間做二階交叉特征計(jì)算。
對(duì)于一階特征中的參數(shù) 表示從 feature_bias 參數(shù)矩陣中 lookup 得到一個(gè)參數(shù),樣本中每個(gè)特征都能得到一個(gè)對(duì)應(yīng)向量(長(zhǎng)度為 1)。
二階特征中, 分別表示 的隱向量,可以從 feature_embeddings 參數(shù)矩陣中 lookup 得到(長(zhǎng)度為 k)。
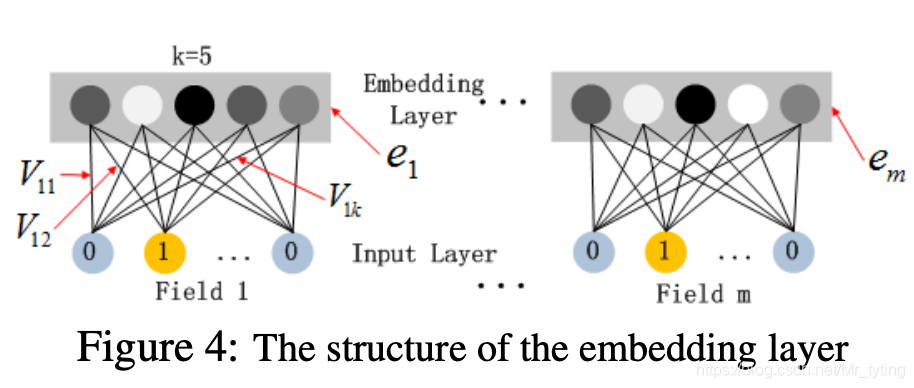
在這里插入圖片描述
?這里可以理解將數(shù)值特征也embedding成向量,一個(gè)數(shù)值特征只對(duì)應(yīng)一個(gè)embedding向量,而一個(gè)類別特征的不同取值則對(duì)應(yīng)不同向量,但向量長(zhǎng)度均為k,對(duì)應(yīng)論文里說:即使不同的field長(zhǎng)度不一樣(one-hot向量長(zhǎng)度不一樣),但是都能embedding成度相同的向量。
?
二階交叉特征推導(dǎo):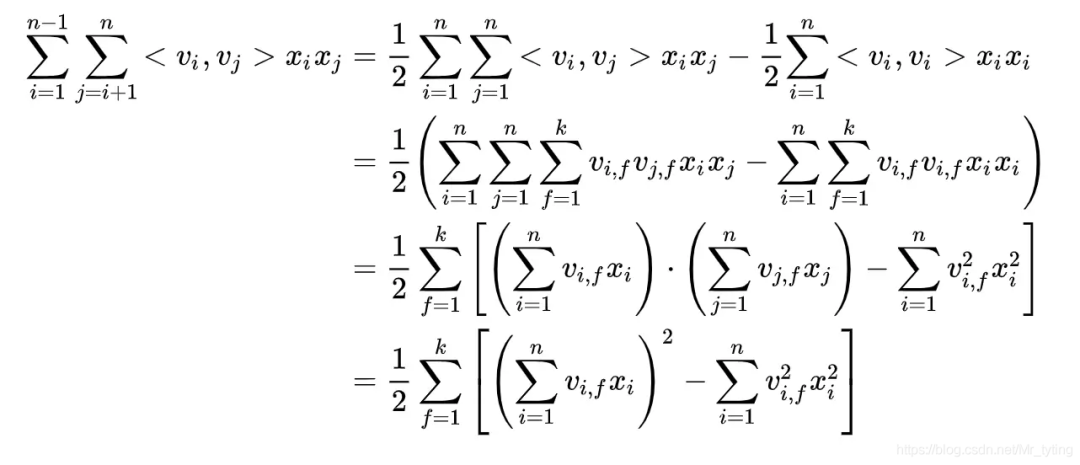
上式中, 表示 , 表示隱向量從 feature*embeddings (shape 為[feature_size,k]) 參數(shù)矩陣中 lookup 得到的參數(shù),那么對(duì)于第 個(gè) ,其得到的 shape 為 ,因此 表示 第 個(gè)分量,對(duì)于類別型特征, 非 0 即 1。
由上面分析可知,每個(gè)輸入特征都有對(duì)應(yīng)的 參數(shù)向量對(duì)應(yīng)。
Deep 部分
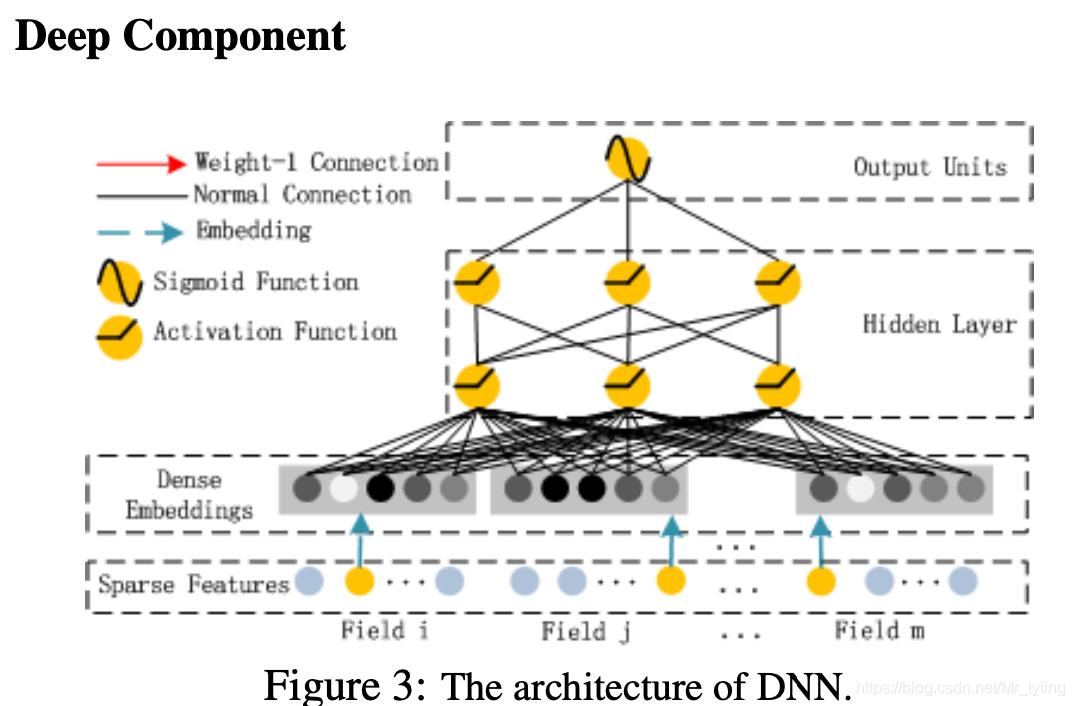 這部分更容易理解了,就是個(gè) DNN 網(wǎng)絡(luò),模型輸入為上圖中的 Dense_Embeddings:
這部分更容易理解了,就是個(gè) DNN 網(wǎng)絡(luò),模型輸入為上圖中的 Dense_Embeddings:
注意:FM 與 Deep 部分共享輸入的 embedding feature,也就是他們共同影響 Dense_Embeddings。
代碼分析
這部分參考的是 tensorflow-DeepFM[3]
數(shù)據(jù)預(yù)處理
該部分對(duì)數(shù)據(jù)集中特征進(jìn)行了編號(hào),一個(gè)連續(xù)特征用一個(gè)編號(hào),類別特征不同取值用不同編號(hào)
def?gen_feat_dict(self):
?????if?self.dfTrain?is?None:
?????????dfTrain?=?pd.read_csv(self.trainfile)
?????else:
?????????dfTrain?=?self.dfTrain
?????if?self.dfTest?is?None:
?????????dfTest?=?pd.read_csv(self.testfile)
?????else:
?????????dfTest?=?self.dfTest
?????df?=?pd.concat([dfTrain,?dfTest])
?????self.feat_dict?=?{}
?????tc?=?0
?????for?col?in?df.columns:
?????????if?col?in?self.ignore_cols:
?????????????continue
?????????if?col?in?self.numeric_cols:
?????????????#?map?to?a?single?index
?????????????self.feat_dict[col]?=?tc
?????????????tc?+=?1
?????????else:
?????????????us?=?df[col].unique()
?????????????self.feat_dict[col]?=?dict(zip(us,?range(tc,?len(us)+tc)))
?????????????tc?+=?len(us)
?????self.feat_dim?=?tc
由上述代碼可以看出 feat_dim 就是我們前面定義的 feature_size
?def?parse(self,?infile=None,?df=None,?has_label=False):
?????assert?not?((infile?is?None)?and?(df?is?None)),?"infile?or?df?at?least?one?is?set"
?????assert?not?((infile?is?not?None)?and?(df?is?not?None)),?"only?one?can?be?set"
?????if?infile?is?None:
?????????dfi?=?df.copy()
?????else:
?????????dfi?=?pd.read_csv(infile)
?????if?has_label:
?????????y?=?dfi["target"].values.tolist()
?????????dfi.drop(["id",?"target"],?axis=1,?inplace=True)
?????else:
?????????ids?=?dfi["id"].values.tolist()
?????????dfi.drop(["id"],?axis=1,?inplace=True)
?????#?dfi?for?feature?index
?????#?dfv?for?feature?value?which?can?be?either?binary?(1/0)?or?float?(e.g.,?10.24)
?????dfv?=?dfi.copy()
?????for?col?in?dfi.columns:
?????????if?col?in?self.feat_dict.ignore_cols:
?????????????dfi.drop(col,?axis=1,?inplace=True)
?????????????dfv.drop(col,?axis=1,?inplace=True)
?????????????continue
?????????if?col?in?self.feat_dict.numeric_cols:
?????????????dfi[col]?=?self.feat_dict.feat_dict[col]
?????????else:
?????????????dfi[col]?=?dfi[col].map(self.feat_dict.feat_dict[col])
?????????????dfv[col]?=?1.
?????#?list?of?list?of?feature?indices?of?each?sample?in?the?dataset
?????Xi?=?dfi.values.tolist()
?????#?list?of?list?of?feature?values?of?each?sample?in?the?dataset
?????Xv?=?dfv.values.tolist()
?????if?has_label:
?????????return?Xi,?Xv,?y
?????else:
?????????return?Xi,?Xv,?ids
由上面代碼可以看出:dfi 表示特征的編號(hào),對(duì)于一個(gè)類別特征,不同取值其編號(hào)不同;dfv 表示該特征值,對(duì)于數(shù)值型特征就是該值本身,類別特征全是 1(表示取到了該編號(hào)的類別值)。
定義 DeepFM 模型超參數(shù)
class?DeepFM(BaseEstimator,?TransformerMixin):
????def?__init__(self,?feature_size,?field_size,
?????????????????embedding_size=8,?dropout_fm=[1.0,?1.0],
?????????????????deep_layers=[32,?32],?dropout_deep=[0.5,?0.5,?0.5],
?????????????????deep_layers_activation=tf.nn.relu,
?????????????????epoch=10,?batch_size=256,
?????????????????learning_rate=0.001,?optimizer_type="adam",
?????????????????batch_norm=0,?batch_norm_decay=0.995,
?????????????????verbose=False,?random_seed=2016,
?????????????????use_fm=True,?use_deep=True,
?????????????????loss_type="logloss",?eval_metric=roc_auc_score,
?????????????????l2_reg=0.0,?greater_is_better=True):
????????assert?(use_fm?or?use_deep)
????????assert?loss_type?in?["logloss",?"mse"],?\
????????????"loss_type?can?be?either?'logloss'?for?classification?task?or?'mse'?for?regression?task"
????????self.feature_size?=?feature_size????????#?M=數(shù)值型特征個(gè)數(shù)+類別型特征取值個(gè)數(shù),就是feat_dim
????????self.field_size?=?field_size????????????#?F=特征個(gè)數(shù)
????????self.embedding_size?=?embedding_size????#?K=embedding_size
????????self.dropout_fm?=?dropout_fm
????????self.deep_layers?=?deep_layers
????????self.dropout_deep?=?dropout_deep
????????self.deep_layers_activation?=?deep_layers_activation
????????self.use_fm?=?use_fm
????????self.use_deep?=?use_deep
????????self.l2_reg?=?l2_reg
????????self.epoch?=?epoch
????????self.batch_size?=?batch_size
????????self.learning_rate?=?learning_rate
????????self.optimizer_type?=?optimizer_type
????????self.batch_norm?=?batch_norm
????????self.batch_norm_decay?=?batch_norm_decay
????????self.verbose?=?verbose
????????self.random_seed?=?random_seed
????????self.loss_type?=?loss_type
????????self.eval_metric?=?eval_metric
????????self.greater_is_better?=?greater_is_better
????????self.train_result,?self.valid_result?=?[],?[]
????????self._init_graph()
構(gòu)圖
feature_bias:shape 為 的一階參數(shù)矩陣 feature_embeddings:shape 為 的二階參數(shù)矩陣
def?_init_graph(self):
????self.graph?=?tf.Graph()
????with?self.graph.as_default():
????????tf.set_random_seed(self.random_seed)
????????self.feat_index?=?tf.placeholder(tf.int32,?shape=[None,?None],
?????????????????????????????????????????????name="feat_index")??#?None?*?F
????????self.feat_value?=?tf.placeholder(tf.float32,?shape=[None,?None],
?????????????????????????????????????????????name="feat_value")??#?None?*?F
????????self.label?=?tf.placeholder(tf.float32,?shape=[None,?1],?name="label")??#?None?*?1
????????self.dropout_keep_fm?=?tf.placeholder(tf.float32,?shape=[None],?name="dropout_keep_fm")
????????self.dropout_keep_deep?=?tf.placeholder(tf.float32,?shape=[None],?name="dropout_keep_deep")
????????self.train_phase?=?tf.placeholder(tf.bool,?name="train_phase")
????????self.weights?=?self._initialize_weights()
????????#?model
????????self.embeddings?=?tf.nn.embedding_lookup(self.weights["feature_embeddings"],
?????????????????????????????????????????????????????????self.feat_index)??#?None?*?F?*?K
????????feat_value?=?tf.reshape(self.feat_value,?shape=[-1,?self.field_size,?1])
????????self.embeddings?=?tf.multiply(self.embeddings,?feat_value)?##?供下面的FM和Deep部分使用
????????#?----------?first?order?term?----------
????????self.y_first_order?=?tf.nn.embedding_lookup(self.weights["feature_bias"],?self.feat_index)?#?None?*?F?*?1
????????self.y_first_order?=?tf.reduce_sum(tf.multiply(self.y_first_order,?feat_value),?2)??#?None?*?F
????????self.y_first_order?=?tf.nn.dropout(self.y_first_order,?self.dropout_keep_fm[0])?#?None?*?F
????????#?----------?second?order?term?---------------
????????#?sum_square?part
????????self.summed_features_emb?=?tf.reduce_sum(self.embeddings,?1)??#?None?*?K
????????self.summed_features_emb_square?=?tf.square(self.summed_features_emb)??#?None?*?K
????????#?square_sum?part
????????self.squared_features_emb?=?tf.square(self.embeddings)
????????self.squared_sum_features_emb?=?tf.reduce_sum(self.squared_features_emb,?1)??#?None?*?K
????????#?second?order
????????self.y_second_order?=?0.5?*?tf.subtract(self.summed_features_emb_square,?self.squared_sum_features_emb)??#?None?*?K
????????self.y_second_order?=?tf.nn.dropout(self.y_second_order,?self.dropout_keep_fm[1])??#?None?*?K
????????#?----------?Deep?component?----------
????????self.y_deep?=?tf.reshape(self.embeddings,?shape=[-1,?self.field_size?*?self.embedding_size])?#?None?*?(F*K)
????????self.y_deep?=?tf.nn.dropout(self.y_deep,?self.dropout_keep_deep[0])
????????for?i?in?range(0,?len(self.deep_layers)):
????????????self.y_deep?=?tf.add(tf.matmul(self.y_deep,?self.weights["layer_%d"?%i]),?self.weights["bias_%d"%i])?#?None?*?layer[i]?*?1
????????????if?self.batch_norm:
????????????????self.y_deep?=?self.batch_norm_layer(self.y_deep,?train_phase=self.train_phase,?scope_bn="bn_%d"?%i)?#?None?*?layer[i]?*?1
????????????self.y_deep?=?self.deep_layers_activation(self.y_deep)
????????????self.y_deep?=?tf.nn.dropout(self.y_deep,?self.dropout_keep_deep[1+i])?#?dropout?at?each?Deep?layer
????????#?----------?DeepFM?----------
????????if?self.use_fm?and?self.use_deep:
????????????concat_input?=?tf.concat([self.y_first_order,?self.y_second_order,?self.y_deep],?axis=1)
????????elif?self.use_fm:
????????????concat_input?=?tf.concat([self.y_first_order,?self.y_second_order],?axis=1)
????????elif?self.use_deep:
????????????concat_input?=?self.y_deep
????????self.out?=?tf.add(tf.matmul(concat_input,?self.weights["concat_projection"]),?self.weights["concat_bias"])
這里需要注意:本實(shí)現(xiàn)代碼中,「也對(duì)連續(xù)特征也直接做了 embedding」,用的時(shí)候也可以把連續(xù)特征改為 deep 側(cè)的直接輸入,另外針對(duì)多值離散特征這里也沒有處理。
總結(jié)
該方法將 FM(捕捉低級(jí)特征)和 Deep(捕捉高級(jí)特征)進(jìn)行端到端的聯(lián)合訓(xùn)練,并且共享輸入 embedding,這是現(xiàn)在非常常見的做法。 論文講到該方法可以一定程度避免人工特征工程,從模型看的確做到了無(wú)腦交叉,模型自動(dòng)學(xué)習(xí)各種交叉的權(quán)重。
Reference
deepfm: https://arxiv.org/abs/1703.04247
[2]tensorflow-DeepFM: https://github.com/ChenglongChen/tensorflow-DeepFM
[3]tensorflow-DeepFM: https://github.com/ChenglongChen/tensorflow-DeepFM
往期精彩回顧
獲取本站知識(shí)星球優(yōu)惠券,復(fù)制鏈接直接打開:
https://t.zsxq.com/qFiUFMV
本站qq群704220115。
加入微信群請(qǐng)掃碼: