
【NLP】文本分類算法-基于字符級(jí)的無(wú)詞嵌入雙向循環(huán)神經(jīng)網(wǎng)絡(luò)(雙向 GRU)
大家好,我是小伍哥,文本數(shù)據(jù)的處理,對(duì)于一個(gè)風(fēng)控策略或者算法,我覺(jué)得是必須要掌握的技能,有人說(shuō),我的風(fēng)控并不涉及到文本?我覺(jué)得這片面了,在非內(nèi)容風(fēng)控領(lǐng)域,文本知識(shí)也是非常有用的。
用戶昵稱、地址啥的,這種絕大部分風(fēng)控場(chǎng)景都能遇到;關(guān)系網(wǎng)絡(luò)的節(jié)點(diǎn)向量化,基本也是文本處理的思路;行為序列,也能用文本的知識(shí)去處理,能捕捉非常有趣模式。
在這里開(kāi)個(gè)系:20大風(fēng)控文本分類算法,去年就已經(jīng)寫(xiě)的差不多了,現(xiàn)在整理好慢慢更新,本系列主要介紹了風(fēng)控場(chǎng)景下文本分類的基本方法,對(duì)抗文本變異,包括傳統(tǒng)的詞袋模型、循環(huán)神經(jīng)網(wǎng)絡(luò),也有常用于計(jì)算機(jī)視覺(jué)任務(wù)的卷積神經(jīng)網(wǎng)絡(luò),以及 RNN + CNN,試驗(yàn)完一遍,基本能搞定大部分的文本分類以及文本變異對(duì)抗問(wèn)題。
今天是第 4 講,主要關(guān)注語(yǔ)句的序列關(guān)系,使用雙向GRU對(duì)文本進(jìn)行分類,邏輯回歸寫(xiě)了3期了,估計(jì)大家看厭煩了, 今天跳躍下,直接跳到雙向RNN,后面在寫(xiě)單向的RNN,有應(yīng)用需求的,可以直接應(yīng)用雙向的,效果比較好,學(xué)習(xí)的,還是需要從簡(jiǎn)單RNN,LSTM再到GRU。
一、原理介紹
RNN 可能看起來(lái)很可怕,盡管它們因?yàn)閺?fù)雜而難以理解,但非常有趣。RNN 模型封裝了一個(gè)非常漂亮的設(shè)計(jì),以克服傳統(tǒng)神經(jīng)網(wǎng)絡(luò)在處理序列數(shù)據(jù)(文本、時(shí)間序列、視頻、DNA 序列等)時(shí)的短板。
RNN 是一系列神經(jīng)網(wǎng)絡(luò)的模塊,它們彼此連接像鎖鏈一樣,每一個(gè)都將消息向后傳遞,強(qiáng)烈推薦大家從 Colah 的博客中深入了解它的內(nèi)部機(jī)制,下面的圖就來(lái)源于此。
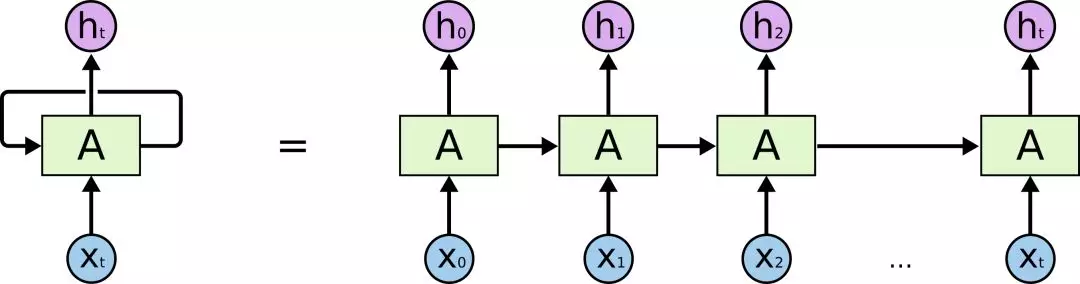
我們要處理的序列類型是文本數(shù)據(jù)。對(duì)意義而言,單詞順序很重要。RNN 考慮到了這一點(diǎn),它可以捕捉長(zhǎng)期依賴關(guān)系。
二、數(shù)據(jù)集和預(yù)處理
本文用一個(gè)風(fēng)險(xiǎn)彈幕數(shù)據(jù)集做實(shí)驗(yàn),該數(shù)據(jù)集包含19670條明細(xì)數(shù)據(jù),每一行都用 1(垃圾文本)和 0(正常文本)進(jìn)行了標(biāo)記。
數(shù)據(jù)集地址:https://github.com/LebronGG/textcnn/blob/master/data/cnews/train.txt,自己需要簡(jiǎn)單處理下,負(fù)向-1,正向-0即可。也可以后臺(tái)回復(fù)【彈幕】獲取
目標(biāo):針對(duì)直播間中存在的大量涉黃涉暴彈幕,進(jìn)行垃圾分類,將彈幕中不合法的內(nèi)容進(jìn)行識(shí)別并屏蔽。
正常彈幕示例
新人主播,各位老板多多關(guān)注??? 0
50077你賣我 0
看看五雷咒的威力 0
垃圾彈幕示例
網(wǎng)站++沜買的私聊我 1
安 KMD555 買-P-微 1
摳逼加薇2928046748摳逼加薇2928046748摳逼。 1

數(shù)據(jù)讀取和查看
import osimport pandas as pdpath = '/Users/wuzhengxiang/Documents/DataSets/TextCnn'os.chdir(path)data = pd.read_csv('text_all.csv')#對(duì)數(shù)據(jù)進(jìn)行隨機(jī)打亂data = data.sample(frac=1, random_state=42)print(data.shape)(19670, 2)#查看0-1的比例,可以看出來(lái),數(shù)據(jù)集基本上平衡data['label'].value_counts()1 98820 9788#查看前10行的數(shù)據(jù)data.head(10)text label17036 鄭 29526 Q 77544 15426 葩葩葩l 014173 網(wǎng)站盤(pán)需要買的私聊我. 114582 買家秀和賣家秀?01730 1776看v 01444 我又沒(méi)送你謝我干啥? 010439 7645 55562筘 02448 伽韋 sx111505 珂視頻箹 Ku 110423 影薇 w2753636 111782 胸還沒(méi)有寒磊的 大? 還奶子疼!0
三、模型構(gòu)建
from keras.preprocessing.text import Tokenizerfrom keras.preprocessing.text import text_to_word_sequencefrom keras.preprocessing.sequence import pad_sequencesfrom keras.models import Modelfrom keras.models import Sequentialfrom keras.layers import Input, Dense, Embedding, Conv1D, Conv2D, MaxPooling1D, MaxPool2Dfrom keras.layers import Reshape, Flatten, Dropout, Concatenatefrom keras.layers import SpatialDropout1D, concatenatefrom keras.layers import GRU, Bidirectional, GlobalAveragePooling1D, GlobalMaxPooling1Dfrom keras.callbacks import Callbackfrom keras.optimizers import Adamfrom keras.callbacks import ModelCheckpoint, EarlyStoppingfrom keras.models import load_modelfrom keras.utils.vis_utils import plot_model#進(jìn)行分字處理import osimport pandas as pdpath = '/Users/wuzhengxiang/Documents/DataSets/TextCnn'os.chdir(path)text_all = pd.read_csv('text_all.csv')data = text_alldata['text'] = text_all['text'].apply(lambda x: ' '.join(x))data.head()x_train, x_test, y_train, y_test=\train_test_split(data['text'],data['label'],test_size=0.2,random_state=42)print(x_train.shape, x_test.shape, y_train.shape, y_test.shape)x_train[45]'\ufeff + C 名 看 P , 是 威 哦 ? ?'MAX_NB_WORDS = 80000tokenizer=Tokenizer(num_words=MAX_NB_WORDS)tokenizer.fit_on_texts(x_train)tokenizer.texts_to_sequences([x_train[38]])train_sequences = tokenizer.texts_to_sequences(x_train)test_sequences = tokenizer.texts_to_sequences(x_test)MAX_LENGTH = 35padded_train_sequences = pad_sequences(train_sequences, maxlen=MAX_LENGTH)padded_test_sequences = pad_sequences(test_sequences, maxlen=MAX_LENGTH)padded_train_sequencesarray([[ 0, 0, 0, ..., 2, 8, 2],[ 0, 0, 0, ..., 387, 443, 16],[ 0, 0, 0, ..., 64, 59, 11],...,[ 0, 0, 0, ..., 27, 27, 27],[ 0, 0, 0, ..., 3, 9, 71],[ 0, 0, 0, ..., 1, 16, 16]], dtype=int32)padded_train_sequences.shape(15736, 35)import numpy as npdef get_simple_rnn_model():embedding_dim = 300embedding_matrix = np.random.random((MAX_NB_WORDS, embedding_dim))inp = Input(shape=(MAX_LENGTH, ))x = Embedding(input_dim = MAX_NB_WORDS,output_dim = embedding_dim,input_length = MAX_LENGTH,weights=[embedding_matrix], trainable=True)(inp)x = SpatialDropout1D(0.3)(x)x = Bidirectional(GRU(100, return_sequences=True))(x)avg_pool = GlobalAveragePooling1D()(x)max_pool = GlobalMaxPooling1D()(x)conc = concatenate([avg_pool, max_pool])outp = Dense(1, activation="sigmoid")(conc)model = Model(inputs=inp, outputs=outp)model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])return modelrnn_simple_model = get_simple_rnn_model()plot_model(rnn_simple_model,#to_file='C:\\Users\\伍正祥\\Desktop\\NLP任務(wù)實(shí)驗(yàn)\\rnn_simple_model.png',show_shapes=True,show_layer_names=True)filepath="weights-improvement-{epoch:02d}-{val_acc:.4f}.hdf5"checkpoint = ModelCheckpoint(filepath,monitor='val_acc',verbose=1,save_best_only=True,mode='max')batch_size = 256epochs = 2history = rnn_simple_model.fit(x = padded_train_sequences,y = y_train,validation_data = (padded_test_sequences, y_test),batch_size = 256,#callbacks=[checkpoint],epochs = 5,verbose=1)#best_rnn_simple_model = load_model('weights-improvement-01-0.8262.hdf5')y_pred_rnn_simple = rnn_simple_model.predict(padded_test_sequences,verbose=1, batch_size=2048)y_pred_rnn_simple = pd.DataFrame(y_pred_rnn_simple, columns=['prediction'])y_pred_rnn_simple['prediction'] = y_pred_rnn_simple['prediction'].map(lambda p: 1 if p >= 0.5 else 0)#y_pred_rnn_simple.to_csv('./predictions/y_pred_rnn_simple.csv', index=False)#y_pred_rnn_simple = pd.read_csv('./predictions/y_pred_rnn_simple.csv')print(accuracy_score(y_test, y_pred_rnn_simple))0.9669547534316217df = pd.DataFrame({'text':x_test,'label':y_test,'pred':y_pred_rnn_simple})df[df['label']!=df['pred']]
相比于第二個(gè)模型(拼音+ngram+邏輯回歸)的0.95602,這個(gè)一下子就干到了0.9669,可以看到深度學(xué)習(xí)還是非常勇猛的,在序列領(lǐng)域,RNN有著不可取代的地位。后續(xù)我們繼續(xù)考慮變異情況,再考慮用深度學(xué)習(xí)來(lái)試驗(yàn),看看能做到多少的準(zhǔn)確率。
四、模型解釋
1)模型打印
plot_model 可以打印模型的框架,我們的框架如下,可以看到,使用了一個(gè)雙項(xiàng)的GRU,然后進(jìn)行了兩種不同的池化方式進(jìn)行池化在拼接起來(lái)。
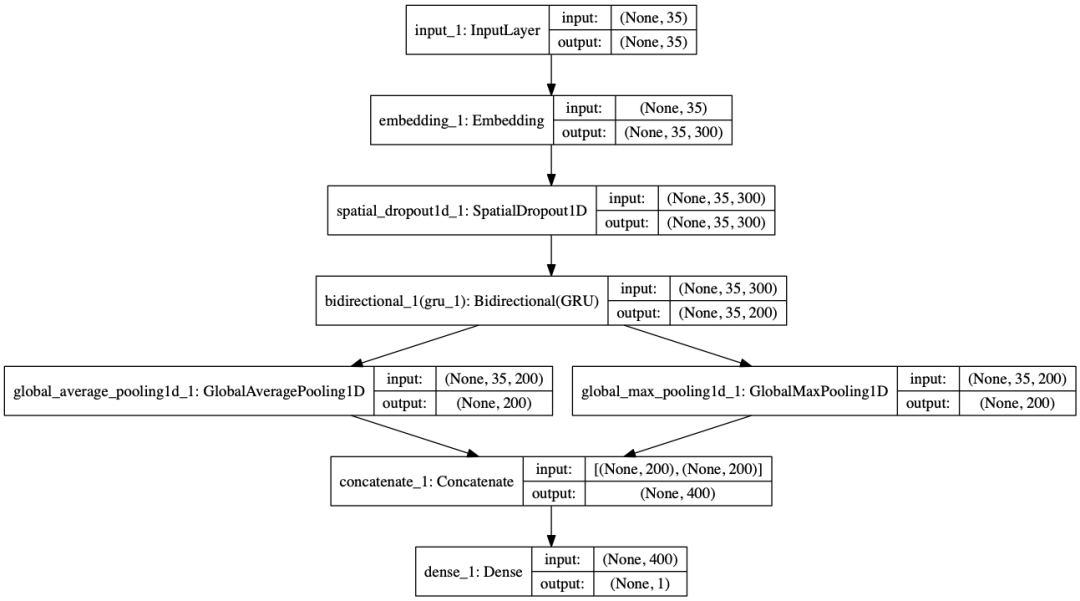
2)模型訓(xùn)練過(guò)程
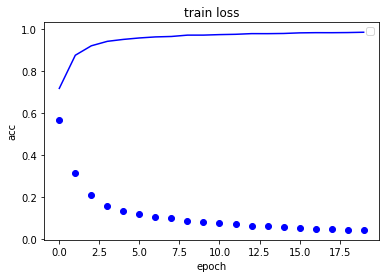
我們可以看看訓(xùn)練過(guò)程的損失下降和準(zhǔn)確率上升,通過(guò)曲線,可以優(yōu)化我們的訓(xùn)練過(guò)程。
import matplotlib.pyplot as plt
# 畫(huà)出損失函數(shù)曲線
plt.plot(history.history['loss'], 'bo',)
plt.plot(history.history['accuracy'], 'b',)
plt.title('train loss')
plt.ylabel('acc')
plt.xlabel('epoch')
plt.legend()
# 畫(huà)出損失函數(shù)曲線
plt.plot(history.history['val_loss'], 'bo',)
plt.plot(history.history['val_accuracy'], 'b',)
plt.title('val loss')
plt.ylabel('acc')
plt.xlabel('epoch')
plt.legend()
可以看到整個(gè)下降曲線還是很平滑的,如果我們輪數(shù)增加,準(zhǔn)確率還有上升的可能性,大家可以測(cè)試下,有點(diǎn)非機(jī)器,一訓(xùn)練就開(kāi)始發(fā)熱了,
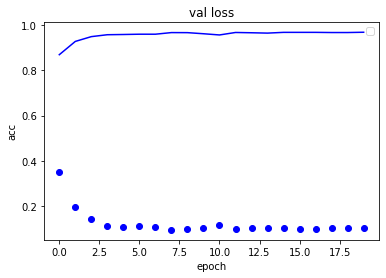
先寫(xiě)到這里了,大家可以看到,深度學(xué)習(xí),對(duì)于解決語(yǔ)言問(wèn)題,還是很有優(yōu)勢(shì)的,就這么簡(jiǎn)簡(jiǎn)單單的一段代碼,準(zhǔn)確率有了非常大的提升,后面的文章,我們繼續(xù)深入研究各種風(fēng)控識(shí)別算法。
··· END ···
往期精彩回顧
適合初學(xué)者入門(mén)人工智能的路線及資料下載 (圖文+視頻)機(jī)器學(xué)習(xí)入門(mén)系列下載 機(jī)器學(xué)習(xí)及深度學(xué)習(xí)筆記等資料打印 《統(tǒng)計(jì)學(xué)習(xí)方法》的代碼復(fù)現(xiàn)專輯 機(jī)器學(xué)習(xí)交流qq群955171419,加入微信群請(qǐng)掃碼