
文本分類的14種算法

向AI轉(zhuǎn)型的程序員都關(guān)注了這個號???
機器學習AI算法工程?? 公眾號:datayx
之前介紹了14種文本分類中的常用算法,包括8種傳統(tǒng)算法:k臨近、決策樹、多層感知器、樸素貝葉斯(包括伯努利貝葉斯、高斯貝葉斯和多項式貝葉斯)、邏輯回歸和支持向量機;4種集成學習算法:隨機森林、AdaBoost、lightGBM和xgBoost;2種深度學習算法:前饋神經(jīng)網(wǎng)絡(luò)和LSTM。
各篇鏈接如下:
測試環(huán)境搭建與數(shù)據(jù)預(yù)處理:
https://blog.csdn.net/qq_43012160/article/details/94993382
決策樹、樸素貝葉斯(伯努利貝葉斯、高斯貝葉斯和多項式貝葉斯):
https://blog.csdn.net/qq_43012160/article/details/95366183
k臨近、邏輯回歸、SVM支持向量機:https://blog.csdn.net/qq_43012160/article/details/95506126
隨機森林、AdaBoost、多層感知器:
https://blog.csdn.net/qq_43012160/article/details/95762591
lightGBM、xgBoost:
https://blog.csdn.net/qq_43012160/article/details/96016265
前饋神經(jīng)網(wǎng)絡(luò)、LSTM(包括pycharm深度學習環(huán)境搭建):
https://blog.csdn.net/qq_43012160/article/details/96101078
性能評估
先放代碼和數(shù)據(jù)集:
關(guān)注微信公眾號 datayx ?然后回復(fù)??文本分類? 即可獲取。
所有14種算法我都跑了一遍,其中4種算法要么把我電腦跑死機了,要么時間長的令人發(fā)指,就沒跑完。整理了跑出來的10種算法的正確率和耗時如下:
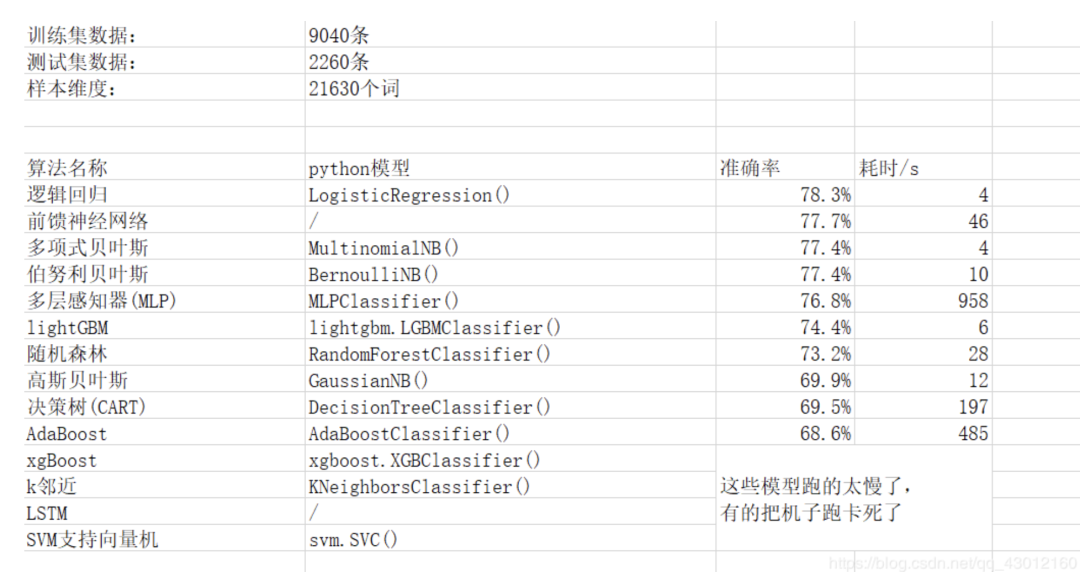
下面這篇博文有一個區(qū)別度更大、更完整的排名:
https://www.kesci.com/home/project/5cbbe1668c90d7002c810f79

這種簡單的文本分類練習,不同算法的性能分層還是比較明顯的。
知識總結(jié)
1.機器學習、集成學習和深度學習:
1)機器學習泛指所有的使機器通過建立和調(diào)整模型從而實現(xiàn)特定功能的算法。2)深度學習是運用了多層的人工神經(jīng)網(wǎng)絡(luò)(ANN)的機器學習方法。3)集成學習是指通過將多個弱分類器的分類結(jié)果進行整合,獲得比單個弱分類器更好效果的機器學習方法。
集成學習和深度學習屬于機器學習。
2.集成學習的bagging和boosting思想:
bagging中的各個弱分類器取值是相互獨立的、無關(guān)的,常使用有放回抽樣實現(xiàn)。
boosting中的弱分類器是在基分類器/前一個分類器的基礎(chǔ)上通過迭代不斷優(yōu)化/調(diào)整出來的。
3.三種樸素貝葉斯:
高斯貝葉斯GaussianNB、多項式貝葉斯MultinomialNB和伯努利貝葉斯BernoulliNB。
分別對應(yīng)數(shù)據(jù)滿足高斯分布(正態(tài)分布)、多項式分布和伯努利分布的訓練集數(shù)據(jù)。
1)伯努利貝葉斯即特征的取值只有取和不取兩類(0和1),對應(yīng)樸素貝葉斯公式中,
p(yi)=標簽為yi的文本數(shù)(句子數(shù))/文本總數(shù)(句子總數(shù))
p(xj|yi)=(標簽為yi的文本中出現(xiàn)了單詞xj的文本數(shù)+1)/(標簽為yi的文本數(shù)+2)。
2)多項式貝葉斯其實就是伯努利貝葉斯的特征取值由簡單的0-1擴展為多個值的情況,
p(yi)=標簽為yi的文本中的單詞總數(shù)/訓練集中的單詞總數(shù)
p(xj|yi)=(標簽為yi的文本中單詞xj的出現(xiàn)次數(shù)+1)/(標簽為yi的文本中的單詞總數(shù)+詞袋單詞種數(shù))。
3)高斯貝葉斯常被用來處理連續(xù)數(shù)據(jù)(如身高)。
4.AdaBoost、lightGBM(GBDT)和xgBoost
AdaBoosting是Boosting框架+任意基學習器算法+指數(shù)損失函數(shù)。
GBDT是Boosting框架+CART回歸樹模型+任意損失函數(shù)。
AdaBoosting利用前一輪迭代弱學習器的誤差率來更新訓練集的權(quán)重,而GBDT采用梯度下降法:丟掉大梯度的數(shù)據(jù)而收納梯度較小的數(shù)據(jù)加入目標決策樹以使樹回歸(貼近真實值)。
xgBoost的損失函數(shù)還考慮了樹不能太復(fù)雜且要分配均衡:一棵樹太復(fù)雜,鶴立雞群,就容易產(chǎn)生弱分類器間的過擬合;一棵樹內(nèi)部的節(jié)點間不均衡,就容易導致大節(jié)點代表的分類特征/分裂閾值的權(quán)重過大,就會產(chǎn)生樹內(nèi)部節(jié)點之間的過擬合。
值得注意的是AdaBoosting的誤差率、權(quán)重和GBDT的梯度都是在弱分類器之間的關(guān)系上的,是在分類器迭代時起作用的,而不是用在單個弱分類器的節(jié)點分裂層面上的,但其實是有影響的。
這里就要說到損失函數(shù)、決策樹節(jié)點分裂閾值和弱分類器迭代、生成之間的關(guān)系了。節(jié)點分裂閾值和分類特征的選定是根據(jù)損失函數(shù)來確定的——假設(shè)損失函數(shù)為L(w),w為目標決策樹的葉節(jié)點分裂閾值向量,我們使損失函數(shù)最小,求得此時的min(w)作為目標決策樹的節(jié)點分裂閾值。
在這個過程中我們雖然做的是對于單一決策樹的節(jié)點分裂特征/閾值選定,但如果一棵樹的節(jié)點分裂特征/閾值全都確定了,這棵樹也就確定了。所以我們就可以通過使損失函數(shù)L(w)取最小值的方式,確定w,同時優(yōu)化決策樹的節(jié)點分裂(通過w)和不同弱分類器間的迭代優(yōu)化(通過使L(w)最小)。即通過w確定目標決策樹,通過w的取值帶動L(w)取最小,進而實現(xiàn)弱分類器的迭代優(yōu)化。
閱讀過本文的人還看了以下文章:
基于40萬表格數(shù)據(jù)集TableBank,用MaskRCNN做表格檢測
《深度學習入門:基于Python的理論與實現(xiàn)》高清中文PDF+源碼
python就業(yè)班學習視頻,從入門到實戰(zhàn)項目
2019最新《PyTorch自然語言處理》英、中文版PDF+源碼
《21個項目玩轉(zhuǎn)深度學習:基于TensorFlow的實踐詳解》完整版PDF+附書代碼
PyTorch深度學習快速實戰(zhàn)入門《pytorch-handbook》
【下載】豆瓣評分8.1,《機器學習實戰(zhàn):基于Scikit-Learn和TensorFlow》
《Python數(shù)據(jù)分析與挖掘?qū)崙?zhàn)》PDF+完整源碼
汽車行業(yè)完整知識圖譜項目實戰(zhàn)視頻(全23課)
李沐大神開源《動手學深度學習》,加州伯克利深度學習(2019春)教材
筆記、代碼清晰易懂!李航《統(tǒng)計學習方法》最新資源全套!
《神經(jīng)網(wǎng)絡(luò)與深度學習》最新2018版中英PDF+源碼
重要開源!CNN-RNN-CTC 實現(xiàn)手寫漢字識別
【Keras】完整實現(xiàn)‘交通標志’分類、‘票據(jù)’分類兩個項目,讓你掌握深度學習圖像分類
VGG16遷移學習,實現(xiàn)醫(yī)學圖像識別分類工程項目
特征工程(二) :文本數(shù)據(jù)的展開、過濾和分塊
如何利用全新的決策樹集成級聯(lián)結(jié)構(gòu)gcForest做特征工程并打分?
Machine Learning Yearning 中文翻譯稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
python+flask搭建CNN在線識別手寫中文網(wǎng)站
中科院Kaggle全球文本匹配競賽華人第1名團隊-深度學習與特征工程
不斷更新資源
深度學習、機器學習、數(shù)據(jù)分析、python
?搜索公眾號添加:?datayx??
機大數(shù)據(jù)技術(shù)與機器學習工程
?搜索公眾號添加:?datanlp
長按圖片,識別二維碼