
C++實現(xiàn)yolov5的OpenVINO部署
[GiantPandaCV導語] 本文介紹了一種使用c++實現(xiàn)的,使用OpenVINO部署yolov5的方法。此方法在2020年9月結(jié)束的極市開發(fā)者榜單中取得后廚老鼠識別賽題第四名。2020年12月,注意到y(tǒng)olov5有了許多變化,對部署流程重新進行了測試,并進行了整理。希望能給需要的朋友一些參考,節(jié)省一些踩坑的時間。
模型訓練
1. 首先獲取yolov5工程
git?clone?https://github.com/ultralytics/yolov5.git
本文編輯的時間是2020年12月3日,官方最新的releases是v3.1,在v3.0的版本中,官網(wǎng)有如下的聲明
August 13, 2020**: v3.0 release( https://github.com/ultralytics/yolov5/releases/tag/v3.0): nn.Hardswish() activations, data autodownload, native AMP.
yolov5訓練獲得的原始的模型以.pt文件方式存儲,要轉(zhuǎn)換為OpenVINO的.xml和.bin的模型存儲方式,需要經(jīng)歷兩次轉(zhuǎn)換.
兩次轉(zhuǎn)換所用到的工具無法同時支持nn.Hardswish()函數(shù)的轉(zhuǎn)換,v3.0版本時需要切換到v2.0版本替換掉nn.Hardswish()函數(shù)才能夠完成兩次模型轉(zhuǎn)換,當時要完成模型轉(zhuǎn)換非常的麻煩.
在v3.1版本的yolov5中用于進行pt模型轉(zhuǎn)onnx模型的程序?qū)n.Hardswish()進行了兼容,模型轉(zhuǎn)換過程大為化簡.
2. 訓練準備
yolov5官方的指南: https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data
描述信息準備
在yolov5的文件夾下/yolov5/models/目錄下可以找到以下文件
yolov5s.yaml
yolov5m.yaml
yolov5l.yaml
這三個文件分別對應s(小尺寸模型),m(中尺寸模型)和l(大尺寸模型)的結(jié)構(gòu)描述信息
其中為了實現(xiàn)自己的訓練常常需要更改以下兩個參數(shù)
nc
需要識別的類別數(shù)量,yolov5原始的默認類別數(shù)量為80
anchors
通過kmeans等算法根據(jù)自己的數(shù)據(jù)集得出合適的錨框. 這里需要注意:yolov5內(nèi)部實現(xiàn)了錨框的自動計算訓練過程默認使用自適應錨框計算.
經(jīng)過實際測試,自己通過kmeans算法得到的錨框在特定數(shù)據(jù)集上能取得更好的性能
在3.執(zhí)行訓練中將提到禁止自動錨框計算的方法.
數(shù)據(jù)準備
參考官方指南的
Create Labels Organize Directories
部分的數(shù)據(jù)要求
注意標注格式是class x_center y_center width height,其中x_center y_center width height均是根據(jù)圖像尺寸歸一化的0到1之間的數(shù)值.
3. 執(zhí)行訓練
python?~/src_repo/yolov5/train.py?--batch?16?--epochs?10?--data?~/src_repo/rat.yaml?--cfg?~/src_repo/yolov5/models/yolov5s.yaml?--weights?""
其中
--data 參數(shù)后面需要填充的是訓練數(shù)據(jù)的說明文件.其中需要說明訓練集,測試集,種類數(shù)目和種類名稱等信息,具體格式可以參考yolov5/data/coco.yaml. --cfg 為在訓練準備階段完成的模型結(jié)構(gòu)描述文件. --weights 后面跟預訓練模型的路徑,如果是""則重新訓練一個模型.推薦使用預訓練模型繼續(xù)訓練,不使用該參數(shù)則默認使用預訓練模型. --noautoanchor 該參數(shù)可選,使用該參數(shù)則禁止自適應anchor計算,使用--cfg文件中提供的原始錨框.
模型轉(zhuǎn)換
經(jīng)過訓練,模型的原始存儲格式為.pt格式,為了實現(xiàn)OpenVINO部署,需要首先轉(zhuǎn)換為.onnx的存儲格式,之后再轉(zhuǎn)化為OpenVINO需要的.xml和.bin的存儲格式.
1. pt格式轉(zhuǎn)onnx格式
這一步的轉(zhuǎn)換主要由yolov5/models/export.py腳本實現(xiàn).
可以參考yolov5提供的簡單教程:https://github.com/ultralytics/yolov5/issues/251
使用該教程中的方法可以獲取onnx模型,但直接按照官方方式獲取的onnx模型其中存在OpenVINO模型轉(zhuǎn)換中不支持的運算,因此,使用該腳本之前需要進行一些更改:
opset_version
在/yolov5/models/export.py中
torch.onnx.export(model,?img,?f,?verbose=False,?opset_version=12,?input_names=['images'],
??????????????????????????output_names=['classes',?'boxes']?if?y?is?None?else?['output'])
opset_version=12,將導致后面的OpenVINO模型裝換時遇到未支持的運算 因此設(shè)置為opset_version=10.
Detect layer export
model.model[-1].export?=?True??
設(shè)置為True則Detect層(包含nms,錨框計算等)不會輸出到模型中.
設(shè)置為False包含Detect層的模型無法通過onnx到OpenVINO格式模型的轉(zhuǎn)換.
需要執(zhí)行如下指令:
python?./models/export.py?--weight?.pt文件路徑?--img?640?--batch?1
需要注意的是在填入的.pt文件路徑不存在時,該程序會自動下載官方預訓練的模型作為轉(zhuǎn)換的原始模型,轉(zhuǎn)換完成則獲得onnx格式的模型.
轉(zhuǎn)換完成后可以使用Netron:https://github.com/lutzroeder/netron.git 進行可視化.對于陌生的模型,該可視化工具對模型結(jié)構(gòu)的認識有很大的幫助.
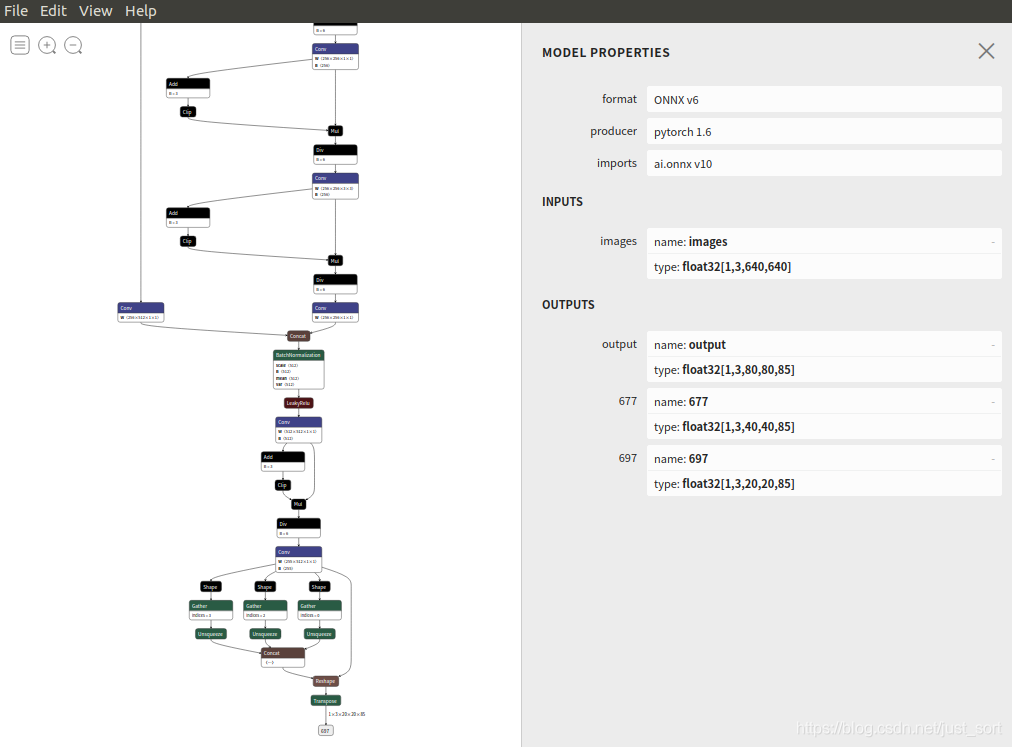
2. onnx格式轉(zhuǎn)換OpenVINO的xml和bin格式
OpenVINO是一個功能豐富的跨平臺邊緣加速工具箱,本文用到了其中的模型優(yōu)化工具和推理引擎兩部分內(nèi)容.
OpenVINO的安裝配置可以參考https://docs.openvinotoolkit.org/2019_R2/_docs_install_guides_installing_openvino_linux.html ,本文的所有實現(xiàn)基于2020.4版本,為確保可用,建議下載2020.4版本的OpenVINO.
安裝完成后在~/.bashrc文件中添加如下內(nèi)容,用于在終端啟動時配置環(huán)境變量.
source?/opt/intel/openvino/bin/setupvars.sh
source?/opt/intel/openvino/opencv/setupvars.sh
安裝完成后運行如下腳本實現(xiàn)onnx模型到xml bin模型的轉(zhuǎn)換.
python?/opt/intel/openvino/deployment_tools/model_optimizer/mo_onnx.py?--input_model?.onnx文件路徑??--output_dir?期望模型輸出的路徑
運行成功之后會獲得.xml和.bin文件,xml和bin是OpenVINO中的模型存儲方式,后續(xù)將基于bin和xml文件進行部署.該模型轉(zhuǎn)換工具還有定點化等模型優(yōu)化功能,有興趣可以自己試試.
使用OpenVINO進行推理部署
OpenVINO除了模型優(yōu)化工具外,還提供了一套運行時推理引擎.
想使用OpenVINO的模型進行推理部署,有兩種方式,第一種方式是使用OpenVINO原生的sdk,另外一種方式是使用支持OpenVINO的opencv(比如OpenVINO自帶的opencv)進行部署,本文對原生sdk的部署方式進行介紹.
OpenVINO提供了相對豐富的例程,本文中實現(xiàn)的yolov5的部署參考了/opt/intel/openvino/deployment_tools/inference_engine/demos/object_detection_demo_yolov3_async文件夾中yolov3的實現(xiàn)方式.
1. 推理引擎的初始化
首先需要進行推理引擎的初始化,此部分代碼封裝在detector.cpp的init函數(shù).
主要流程如下:
Core?ie;
//讀入xml文件,該函數(shù)會在xml文件的目錄下自動讀取相應的bin文件,無需手動指定
auto?cnnNetwork?=?ie.ReadNetwork(_xml_path);?
//從模型中獲取輸入數(shù)據(jù)的格式信息
InputsDataMap?inputInfo(cnnNetwork.getInputsInfo());
InputInfo::Ptr&?input?=?inputInfo.begin()->second;
_input_name?=?inputInfo.begin()->first;
input->setPrecision(Precision::FP32);
input->getInputData()->setLayout(Layout::NCHW);
ICNNNetwork::InputShapes?inputShapes?=?cnnNetwork.getInputShapes();
SizeVector&?inSizeVector?=?inputShapes.begin()->second;
cnnNetwork.reshape(inputShapes);
//從模型中獲取推斷結(jié)果的格式
_outputinfo?=?OutputsDataMap(cnnNetwork.getOutputsInfo());
for?(auto?&output?:?_outputinfo)?{
????output.second->setPrecision(Precision::FP32);
}
//獲取可執(zhí)行網(wǎng)絡(luò),這里的CPU指的是推斷運行的器件,可選的還有"GPU",這里的GPU指的是intel芯片內(nèi)部的核顯
//配置好核顯所需的GPU運行環(huán)境,使用GPU模式進行的推理速度上有很大提升,這里先拿CPU部署后面會提到GPU環(huán)境的配置方式
_network?=??ie.LoadNetwork(cnnNetwork,?"CPU");
2. 數(shù)據(jù)準備
為了適配網(wǎng)絡(luò)的輸入數(shù)據(jù)格式要求,需要對原始的opencv讀取的Mat數(shù)據(jù)進行預處理.
resize
最簡單的方式是將輸入圖像直接resize到640*640尺寸,此種方式會造成部分物體失真變形,識別準確率會受到部分影響,簡單起見,在demo代碼里使用了該方式.
在競賽代碼中,為了追求正確率,圖像縮放的時候需要按圖像原始比例將圖像的長或?qū)捒s放到640.假設(shè)長被放大到640,寬按照長的變換比例無法達到640,則在圖像的兩邊填充黑邊確保輸入圖像總尺寸為640*640.競賽代碼中使用了該種縮放方式,需要注意的是如果使用該種縮放方式,在獲取結(jié)果時需要將結(jié)果轉(zhuǎn)換為在原始圖像中的坐標.
顏色通道轉(zhuǎn)換
鑒于opencv和pytorch的顏色通道差異,opencv是BGR通道,pytorch是RGB,在輸入網(wǎng)絡(luò)之前,需要進行通道轉(zhuǎn)換.
推斷請求和blob填充
InferRequest::Ptr?infer_request?=?_network.CreateInferRequestPtr();
Blob::Ptr?frameBlob?=?infer_request->GetBlob(_input_name);
InferenceEngine::LockedMemory<void>?blobMapped?=?InferenceEngine::as(frameBlob)->wmap();
float*?blob_data?=?blobMapped.as<float*>();
//nchw
for(size_t?row?=0;row<640;row++){
????for(size_t?col=0;col<640;col++){
????????for(size_t?ch?=0;ch<3;ch++){
????????????//將圖像轉(zhuǎn)換為浮點型填入模型
????????????blob_data[img_size*ch?+?row*640?+?col]?=?float(inframe.at(row,col)[ch])/255.0f;
????????}
????}
}
3. 推斷執(zhí)行與解析
推斷執(zhí)行
infer_request->Infer();
獲取推斷結(jié)果
從Netron的可視化結(jié)果可知
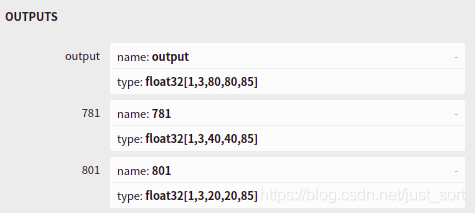
網(wǎng)絡(luò)只包含到輸出三個檢測頭的部分,三個檢測頭分別對應80,40,和20的柵格尺寸,因此需要對三種尺寸的檢測頭輸出結(jié)果依次解析,具體的解析過程在parse_yolov5函數(shù)中進行了實現(xiàn):
//獲取各層結(jié)果
vector?origin_rect;?????????????????????//保存原始的框信息
vector<float>?origin_rect_cof;????????????//保存框?qū)闹眯哦刃畔?/span>
int?s[3]?=?{80,40,20};
int?i=0;
for?(auto?&output?:?_outputinfo)?{
????auto?output_name?=?output.first;
????Blob::Ptr?blob?=?infer_request->GetBlob(output_name);
????parse_yolov5(blob,s[i],_cof_threshold,origin_rect,origin_rect_cof);
????++i;
}
對檢測頭的內(nèi)容進行解析
這部分主要是使用c++將yolov5代碼中的detect層內(nèi)容重新實現(xiàn)一下,主要代碼實現(xiàn)如下:
//注意此處的閾值是框和物體prob乘積的閾值
bool?Detector::parse_yolov5(const?Blob::Ptr?&blob,int?net_grid,float?cof_threshold,
????vector&?o_rect,vector<float>&?o_rect_cof) {
????vector<int>?anchors?=?get_anchors(net_grid);
????LockedMemory<const?void>?blobMapped?=?as(blob)->rmap();
????const?float?*output_blob?=?blobMapped.as<float?*>();
????//80個類是85,一個類是6,n個類是n+5
????//int?item_size?=?6;
????int?item_size?=?85;
????size_t?anchor_n?=?3;
????for(int?n=0;n????????for(int?i=0;i????????????for(int?j=0;j????????????{
????????????????double?box_prob?=?output_blob[n*net_grid*net_grid*item_size?+?i*net_grid*item_size?+?j?*item_size+?4];
????????????????box_prob?=?sigmoid(box_prob);
????????????????//框置信度不滿足則整體置信度不滿足
????????????????if(box_prob?????????????????????continue;
????????????????
????????????????//注意此處輸出為中心點坐標,需要轉(zhuǎn)化為角點坐標
????????????????double?x?=?output_blob[n*net_grid*net_grid*item_size?+?i*net_grid*item_size?+?j*item_size?+?0];
????????????????double?y?=?output_blob[n*net_grid*net_grid*item_size?+?i*net_grid*item_size?+?j*item_size?+?1];
????????????????double?w?=?output_blob[n*net_grid*net_grid*item_size?+?i*net_grid*item_size?+?j*item_size?+?2];
????????????????double?h?=?output_blob[n*net_grid*net_grid*item_size?+?i*net_grid*item_size?+?j?*item_size+?3];
???????????????
????????????????double?max_prob?=?0;
????????????????int?idx=0;
????????????????for(int?t=5;t<85;++t){
????????????????????double?tp=?output_blob[n*net_grid*net_grid*item_size?+?i*net_grid*item_size?+?j?*item_size+?t];
????????????????????tp?=?sigmoid(tp);
????????????????????if(tp?>?max_prob){
????????????????????????max_prob?=?tp;
????????????????????????idx?=?t;
????????????????????}
????????????????}
????????????????float?cof?=?box_prob?*?max_prob;????????????????
????????????????//對于邊框置信度小于閾值的邊框,不關(guān)心其他數(shù)值,不進行計算減少計算量
????????????????if(cof?????????????????????continue;
????????????????x?=?(sigmoid(x)*2?-?0.5?+?j)*640.0f/net_grid;
????????????????y?=?(sigmoid(y)*2?-?0.5?+?i)*640.0f/net_grid;
????????????????w?=?pow(sigmoid(w)*2,2)?*?anchors[n*2];
????????????????h?=?pow(sigmoid(h)*2,2)?*?anchors[n*2?+?1];
????????????????double?r_x?=?x?-?w/2;
????????????????double?r_y?=?y?-?h/2;
????????????????Rect?rect?=?Rect(round(r_x),round(r_y),round(w),round(h));
????????????????o_rect.push_back(rect);
????????????????o_rect_cof.push_back(cof);
????????????}
????if(o_rect.size()?==?0)?return?false;
????else?return?true;
}
這一部分最艱難的是搞清楚輸出數(shù)據(jù)的排列方式,一開始我也試了很多次,最后才得到了正確的輸出.
需要注意的一點是,按照輸出排列方式讀取的數(shù)值不是最終我們需要的結(jié)果,需要進行一些計算來進行轉(zhuǎn)換,
轉(zhuǎn)換的依據(jù)可以參考yolov5/models/yolo.py中forward函數(shù)的實現(xiàn).
注意這里有一個參數(shù)cof_threshold,其計算方式是框置信度乘以物品置信度,如果識別效果不佳,則需要對該數(shù)值進行調(diào)整.
NMS獲取最終結(jié)果
經(jīng)過以上步驟,原始的框信息存儲在origin_rect變量中,還需要通過NMS去除同一個物體多余的框.
OpenVNIO自帶的opencv提供了NMS的一種實現(xiàn),因而直接進行調(diào)用.
?vector<int>?final_id;
????dnn::NMSBoxes(origin_rect,origin_rect_cof,_cof_threshold,_nms_area_threshold,final_id);
????//根據(jù)final_id獲取最終結(jié)果
????for(int?i=0;i????????Rect?resize_rect=?origin_rect[final_id[i]];
????????detected_objects.push_back(Object{
????????????origin_rect_cof[final_id[i]],
????????????"",resize_rect
????????});
????}
其中origin_rect為原始矩形,origin_rect_cof為矩形對應的置信度,_cof_threshold為置信度(框置信度乘以物品置信度)閾值,_nms_area_threshold是重疊百分比多少則算為一個物體的閾值,final_id為目標矩形在origin_rect中的下標.
4. 性能測試
計時實現(xiàn)如下:
auto?start?=?chrono::high_resolution_clock::now();
auto?end?=?chrono::high_resolution_clock::now();
std::chrono::duration<double>?diff?=?end?-?start;
cout<<"use?"<"?s"?<endl;
原始的未經(jīng)優(yōu)化的CPU運行的yolov5,推理時間在240ms左右,測試平臺為intel corei7 6700hq.
檢測結(jié)果如下:

推理加速
使用核顯GPU進行計算
將
_network?=??ie.LoadNetwork(cnnNetwork,?"CPU");
改為
_network?=??ie.LoadNetwork(cnnNetwork,?"GPU");
如果OpenVINO環(huán)境配置設(shè)置無誤程序應該可以直接運行.
檢測環(huán)境是否配置無誤的方法是運行:
/opt/intel/openvino/deployment_tools/demo中的./demo_security_barrier_camera.sh
若成功運行則cpu環(huán)境正常.
./demo_security_barrier_camera.sh -d GPU 運行正常則gpu環(huán)境運行正常.
使用openmp進行并行化
在推理之外的數(shù)據(jù)預處理和解析中存在大量循環(huán),這些循環(huán)都可以利用openmp進行并行優(yōu)化.
模型優(yōu)化如定點化為int8類型
在模型轉(zhuǎn)換時通過設(shè)置參數(shù)可以實現(xiàn)模型的定點化.
git項目使用
項目地址:https://github.com/fb029ed/yolov5_cpp_openvino
demo部分完成了yolov5原始模型的部署
使用方法為依次執(zhí)行
cd?./demo
mkdir?build?
cd?build
cmake?..
make?
./detect_test
cvmart_competition部分為開發(fā)者榜單競賽的參賽代碼,不能直接運行僅供參考
歡迎關(guān)注GiantPandaCV, 在這里你將看到獨家的深度學習分享,堅持原創(chuàng),每天分享我們學習到的新鮮知識。( ? ?ω?? )?
有對文章相關(guān)的問題,或者想要加入交流群,歡迎添加BBuf微信:
為了方便讀者獲取資料以及我們公眾號的作者發(fā)布一些Github工程的更新,我們成立了一個QQ群,二維碼如下,感興趣可以加入。