
MySQL 中的臨時表
點擊上方藍(lán)色字體,選擇“標(biāo)星公眾號”
優(yōu)質(zhì)文章,第一時間送達(dá)
? 作者?|? 萌新J
來源 |? urlify.cn/7VvYBz
文章正文:
在使用 explain 解析一個 sql 時,有時我們會發(fā)現(xiàn)在 extra 列上顯示 using temporary ,這表示這條語句用到了臨時表,那么臨時表究竟是什么?它又會對 sql 的性能產(chǎn)生什么影響?又會在哪些場景中出現(xiàn)?本文根據(jù) <
出現(xiàn)場景
其實臨時表在之前的博客就已經(jīng)出現(xiàn)過了,在 MySQL 中的排序?一文中就說到如果 order by 的列上沒有索引,或者說沒有用到索引,那么就需要進(jìn)行額外排序(using filesort),而額外排序優(yōu)先在一塊 sort_buffer 空間中進(jìn)行,如果這塊空間大小小于要加載的字段總長度,那么就會用到臨時文件輔助排序,這個臨時文件就是臨時表。臨時表的作用就是作為中間表優(yōu)化操作,比如 group by 作為分組的中間表, order by rand() (MySQL 中的排序?中的例子)作為中間表幫助運算等。
特點

?
1、建表語法是 create temporary table …。
2、一個臨時表只能被創(chuàng)建它的 session 訪問,對其他線程不可見,在會話結(jié)束后自動刪除。所以,圖中 session A 創(chuàng)建的臨時表 t,對于 session B 就是不可見的。(所以特別適合用于join 優(yōu)化)
3、臨時表可以與普通表同名。
4、session A 內(nèi)有同名的臨時表和普通表的時候,show create 語句,以及增刪改查語句訪問的是臨時表。
5、show tables 命令不顯示臨時表。
種類
臨時表分為磁盤臨時表和內(nèi)存臨時表。磁盤臨時表指的是存儲在磁盤上的臨時表,因為在磁盤上,所以執(zhí)行效率比較低,優(yōu)點結(jié)構(gòu)可以是有序的,實現(xiàn)可以是 InnoDB(默認(rèn)),MyISAM 引擎;內(nèi)存臨時表就是存儲在內(nèi)存中,執(zhí)行效率高,常用的實現(xiàn)引擎是 Memory。
磁盤臨時表和內(nèi)存臨時表的區(qū)別
1、相比于 InnoDB 表,使用內(nèi)存表不需要寫磁盤,往表 temp_t 的寫數(shù)據(jù)的速度更快;
2、索引 b 使用 hash 索引,查找的速度比 B-Tree 索引快;
3、臨時表數(shù)據(jù)只有 2000 行,占用的內(nèi)存有限。
Memory?引擎
與 InnoDB?的區(qū)別
1、InnoDB 表的數(shù)據(jù)總是有序存放的,而內(nèi)存表的數(shù)據(jù)就是按照寫入順序存放的;關(guān)于這點可以通過創(chuàng)建 b+?索引來進(jìn)行排序,優(yōu)化查詢。alter table t1 add index a_btree_index using btree (id);
2、當(dāng)數(shù)據(jù)文件有空洞的時候,InnoDB 表在插入新數(shù)據(jù)的時候,為了保證數(shù)據(jù)有序性,只能在固定的位置寫入新值,而內(nèi)存表找到空位就可以插入新值;
3、數(shù)據(jù)位置發(fā)生變化的時候,InnoDB 表只需要修改主鍵索引,而內(nèi)存表需要修改所有索引;
4、InnoDB 表用主鍵索引查詢時需要走一次索引查找,用普通索引查詢的時候,需要走兩次索引查找。而內(nèi)存表沒有這個區(qū)別,所有索引的“地位”都是相同的。
5、InnoDB 支持變長數(shù)據(jù)類型,不同記錄的長度可能不同;內(nèi)存表不支持 Blob 和 Text 字段,并且即使定義了 varchar(N),實際也當(dāng)作 char(N),也就是固定長度字符串來存儲,因此內(nèi)存表的每行數(shù)據(jù)長度相同。
6、內(nèi)存表支持 hash 索引,并且數(shù)據(jù)存儲在內(nèi)存中,所以執(zhí)行比數(shù)據(jù)存儲在磁盤上的 Innodb 快。
缺點
1、鎖粒度大,只支持表級鎖,并發(fā)度低。


2、數(shù)據(jù)持久性差。因為是內(nèi)存結(jié)構(gòu),所以在重啟后數(shù)據(jù)會丟失 。由此會導(dǎo)致備庫在硬件升級后數(shù)據(jù)就會丟失,并且如果主從庫互為 "主備關(guān)系" ,備庫在關(guān)閉后還會將刪除數(shù)據(jù)記錄進(jìn) binlog,重啟后主機會執(zhí)行備庫發(fā)送過來的 binlog ,導(dǎo)致主庫數(shù)據(jù)也會丟失。
雖然 Memory 引擎看起來缺點很多,但是因為其存儲在內(nèi)存中,并且關(guān)機后會自動清除數(shù)據(jù),所以其是作為臨時表的一個絕佳選擇。
?
常見的應(yīng)用場景
分庫分表查詢
將一個大表 ht,按照字段 f,拆分成 1024 個分表,然后分布到 32 個數(shù)據(jù)庫實例上(水平分表)。一般情況下,這種分庫分表系統(tǒng)都有一個中間層 proxy。不過,也有一些方案會讓客戶端直接連接數(shù)據(jù)庫,也就是沒有 proxy 這一層。假設(shè)分區(qū)鍵是?列 f 。
1、如果只使用分區(qū)鍵作為查詢條件如 select v from ht where f=N,那么直接通過分表規(guī)則找到 N 所在的表,然后去該表上查詢就可以了。
2、如果使用其他字段作為條件且需要排序如 select v from ht where k >= M order by t_modified desc limit 100,那么非但不能確定要查詢的記錄在哪張表上,而且因為默認(rèn)使用的是分區(qū)鍵排序,所以得到的結(jié)果還是無序的,需要額外排序。
1)在 proxy 層完成排序。優(yōu)勢是速度快,缺點是開發(fā)工作量比較大,如果涉及復(fù)雜的操作如 group by,甚至 join 這樣的操作,對中間層的開發(fā)能力要求比較高。并且還容易出現(xiàn)內(nèi)存不夠、CPU 瓶頸的問題。
2)將各個分區(qū)的查詢結(jié)果(未排序)總結(jié)到一張臨時表上進(jìn)行排序。
Ⅰ、在匯總庫上創(chuàng)建一個臨時表 temp_ht,表里包含三個字段 v、k、t_modified;
Ⅱ、在各個分庫上執(zhí)行 select v,k,t_modified from ht_x where k >= M order by t_modified desc limit 100;?
Ⅲ、把分庫執(zhí)行的結(jié)果插入到 temp_ht 表中;
Ⅳ、執(zhí)行 select v from temp_ht order by t_modified desc limit 100;
union?作為中間表
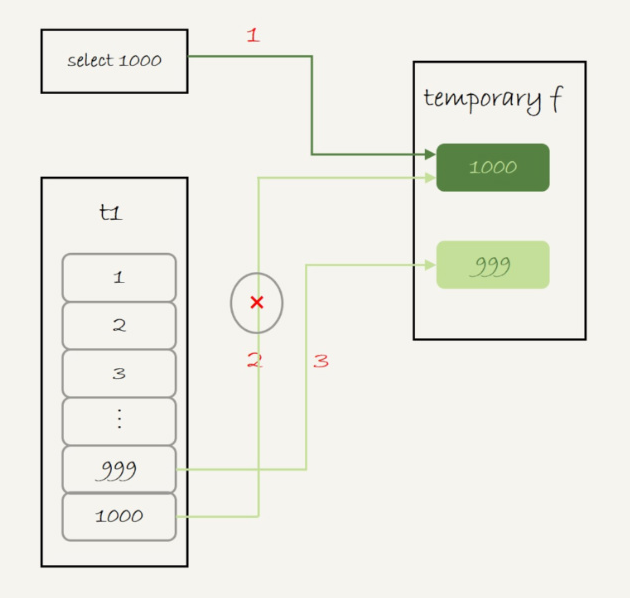
有表t1:create table t1(id int primary key, a int, b int, index(a));?有記錄(1,1,1)?到 (1000,1000,1000) 執(zhí)行?(select 1000 as f) union (select id from t1 order by id desc limit 2);?
解析這條 sql:

可以知道:
1、左邊語句沒有進(jìn)行查表操作 2、右邊語句使用了 id?索引 3、聯(lián)合時使用了臨時表
具體過程:
1、創(chuàng)建一個內(nèi)存臨時表,這個臨時表只有一個整型字段 f,并且 f 是主鍵字段。
2、執(zhí)行第一個子查詢,得到 1000 這個值,并存入臨時表中。
3、執(zhí)行第二個子查詢:
1)拿到第一行 id=1000,試圖插入臨時表中。但由于 1000 這個值已經(jīng)存在于臨時表了,違反了唯一性約束,所以插入失敗,然后繼續(xù)執(zhí)行;
2)取到第二行 id=999,插入臨時表成功。
4、從臨時表中按行取出數(shù)據(jù),返回結(jié)果,并刪除臨時表,結(jié)果中包含兩行數(shù)據(jù)分別是 1000 和 999。
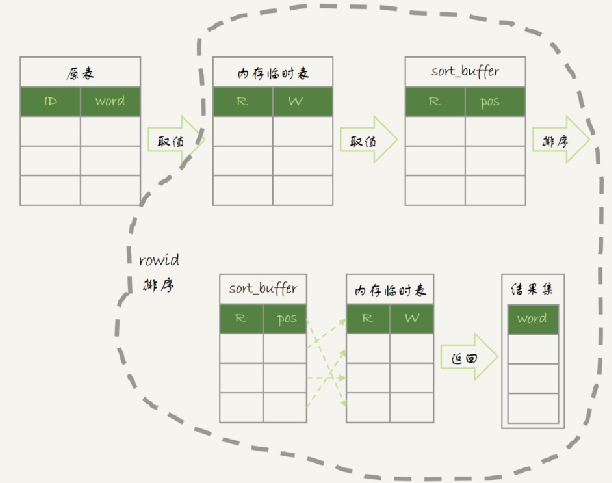
排序返回的字段過大
舉一個在 ?MySQL中的排序?中提到過的例子。
select word from words order by rand() limit 3;? 表數(shù)據(jù)有10000行? SQL是從10000行記錄中隨機獲取3條記錄返回。
這個執(zhí)行過程因為涉及到 rand()?且數(shù)據(jù)量比較大,所以單靠 sort_buffer 排序空間不夠,所以還用到臨時表。
過程:
1、從緩沖池依次讀取記錄,每次讀取后都調(diào)用 rand() 函數(shù)生成一個 0-1 的數(shù)存入內(nèi)存臨時表,W 是 word 值,R 是 rand() 生成的隨機數(shù)。到這掃描了 10000 行。
2、初始化 sort_buffer,從內(nèi)存臨時表中將 rowid(這張表自動生成的) 以及 排序數(shù)據(jù) R 存入 sort_buffer。到這因為要遍歷內(nèi)存臨時表所以又掃描了 10000 行。
3、在 sort_buffer 中根據(jù) R 排好序,然后選擇前三個記錄的 rowid 逐條去內(nèi)存臨時表中查到 word 值返回。到這因為取了三個數(shù)據(jù)去內(nèi)存臨時表去查找所以又掃描了 3 行。總共 20003 行。
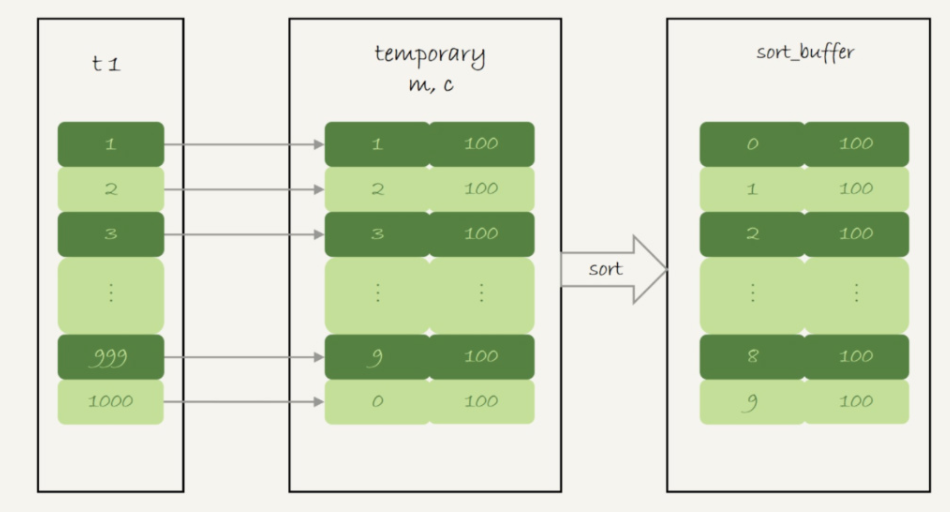
group by?作為中間表
執(zhí)行:select id%10 as m, count(*) as c from t1 group by m;
首先解析 SQL:

可以看到使用了臨時表和額外排序,接下來來解析
執(zhí)行過程:
1、創(chuàng)建內(nèi)存臨時表,表里有兩個字段 m 和 c,主鍵是 m;
2、掃描表 t1 的索引 a,依次取出葉子節(jié)點上的 id 值,計算 id%10 的結(jié)果,記為 x;
1)如果臨時表中沒有主鍵為 x 的行,就插入一個記錄 (x,1);
2)如果表中有主鍵為 x 的行,就將 x 這一行的 c 值加 1;
遍歷完成后,再根據(jù)字段 m 做排序,得到結(jié)果集返回給客戶端。
排序的過程就按照排序規(guī)則進(jìn)行,用到 sort_buffer ,可能用到臨時表。
優(yōu)化 BNL?排序
表結(jié)構(gòu):
CREATE?TABLE?`t2`?(
`id`?int(11)?NOT?NULL,
`a`?int(11)?DEFAULT?NULL,
`b`?int(11)?DEFAULT?NULL,
PRIMARY?KEY?(`id`),
KEY?`a`?(`a`)
)?ENGINE=InnoDB;
t1、t2 結(jié)構(gòu)相等,t2 100萬條數(shù)據(jù),t1 1000行數(shù)據(jù),t1 的數(shù)據(jù)在 t2 上都有對應(yīng),相等。執(zhí)行語句:select * from t1 join t2 on (t1.b=t2.b) where t2.b>=1 and t2.b<=2000;
分析:因為字段b 沒有創(chuàng)建索引,所以排序是屬于 BNL 排序,再加上數(shù)據(jù)量比較大,所以在比較時掃描的總行數(shù)就等于? 100萬*1000,也就是10億次。
具體過程:
1、把表 t1 的所有字段取出來,存入 join_buffer 中。這個表只有 1000 行,join_buffer_size 默認(rèn)值是 256k,可以完全存入。
2、掃描表 t2,取出每一行數(shù)據(jù)跟 join_buffer 中的數(shù)據(jù)進(jìn)行對比,
1)如果不滿足 t1.b=t2.b,則跳過;
2)如果滿足 t1.b=t2.b, 再判斷其他條件,也就是是否滿足 t2.b 處于[1,2000]的條件,如果是,就作為結(jié)果集的一部分返回,否則跳過。
優(yōu)化:
如果篩選字段用的比較多,那么可以為其創(chuàng)建索引,使 BNL 優(yōu)化成 NLJ,但是如果這個字段使用的不多,那么為其創(chuàng)建索引反倒會因為多了不必要的維護成本而降低總體的性能。所以。針對于使用率不高的 BNL 篩選字段的優(yōu)化,可以創(chuàng)建一個臨時表,讓這個臨時表作為一個索引表,來優(yōu)化成 NLJ,同時因為臨時表在會話結(jié)束后會自動刪除,省去了維護成本。
create?temporary?table?temp_t(id?int?primary?key,?a?int,?b?int,?index(b))engine=innodb;
insert?into?temp_t?select?*?from?t2?where?b>=1?and?b<=2000;
select?*?from?t1?join?temp_t?on?(t1.b=temp_t.b);這樣執(zhí)行過程就變成:?
1、執(zhí)行 insert 語句構(gòu)造 temp_t 表并插入數(shù)據(jù)的過程中,對表 t2 做了全表掃描,這里掃描行數(shù)是 100 萬。
2、之后的 join 語句,掃描表 t1,這里的掃描行數(shù)是 1000;join 比較過程中,做了 1000 次帶索引的查詢(因為t1 1000行,作為驅(qū)動表,t2作為被驅(qū)動表)。相比于優(yōu)化前的 join 語句需要做 10 億次條件判斷來說,這個優(yōu)化效果還是很明顯的。
為什么臨時表可以重名

可以看到在 sessionA 在已經(jīng)創(chuàng)建了一個名為 t1 的臨時表,并且 sessionA 未結(jié)束前,sessionB 也創(chuàng)建了一個名為 t1 的臨時表,沒有發(fā)生異常。這是為什么?
首先要知道在 MySQL 啟動后每張表都會加載到內(nèi)存中,所以每張表都分為內(nèi)存表和磁盤表。
1、對于磁盤表:
1)普通表的表結(jié)構(gòu)和數(shù)據(jù)文件都是存儲在庫名文件夾下的,文件名就是表名。
2)結(jié)構(gòu)文件存儲在臨時文件夾下,文件的后綴是 frm,前綴是 "#sql{進(jìn)程 id}_{線程id}_序列號";
? 數(shù)據(jù)文件在 5.6 及之前是存儲在臨時文件夾下的,5.7 開始存放在專門存放臨時文件數(shù)據(jù)的臨時表空間。?
2、對于內(nèi)存表:
1)普通表的命名是 "庫名 +?表名"。
2)臨時表的命名則在 "?庫名 +?表名 "?的基礎(chǔ)上,加入了 " server_id + thread_id "。比如:
? ? ? ?
session A 的臨時表 t1,在備庫的 table_def_key 就是:庫名 +t1+“M 的 serverid”+“session A 的 thread_id”;
session B 的臨時表 t1,在備庫的 table_def_key 就是 :庫名 +t1+“M 的 serverid”+“session B 的 thread_id”。
綜上所述,因為臨時表在磁盤和內(nèi)存中表的命名都取自具體的進(jìn)程id、線程id、所以可以實現(xiàn)不同的會話創(chuàng)建相同的表名。
?
如果 binlog 的格式是 row,那么是不會記錄臨時表的各個操作的,因為臨時表就是作為中間表來輔助各種操作的,所以在 row 格式下直接記錄的是經(jīng)過臨時表得出的具體要操作的數(shù)據(jù)。
總結(jié)
臨時表是一種非常方便的結(jié)構(gòu),因為其會隨著會話結(jié)束而自動刪除,所以在一些查詢效率較低但篩選字段使用很少的場景,就可以通過創(chuàng)建臨時表,然后在臨時表上創(chuàng)建索引來提高查詢效率,同時也避免了索引的后續(xù)維護,而在其他復(fù)雜操作中,臨時表也可以充當(dāng)中間表的作用。所以臨時表廣泛出現(xiàn)在查詢(多表聯(lián)查)、分組、排序(排序返回的字段總長度過大)等場景中。在某些復(fù)雜操作我們可以使用臨時表去優(yōu)化,但是使用臨時表還是會消耗一定的性能,所以如果 explain 一條語句出現(xiàn) using temporary,首要是想辦法去優(yōu)化使其沒有用到臨時表,如果沒有更好的方法優(yōu)化才放棄。
總結(jié):
1、如果語句執(zhí)行過程可以一邊讀數(shù)據(jù),一邊直接得到結(jié)果,是不需要額外內(nèi)存的,否則就需要額外的內(nèi)存,來保存中間結(jié)果;
2、join_buffer 是無序數(shù)組,專門用于多表聯(lián)查未用到索引時輔助查詢的,如果不足以裝下驅(qū)動表就會分多次進(jìn)行;sort_buffer 是有序數(shù)組,在排序時優(yōu)先使用的區(qū)域,如果要排序返回的總字段長度超過設(shè)置的區(qū)域就會用到內(nèi)存臨時表,如果再超過 tmp_table_size ?設(shè)置的值就會轉(zhuǎn)成磁盤臨時表;內(nèi)存臨時表是二維表結(jié)構(gòu),無序;磁盤臨時表默認(rèn)是B+結(jié)構(gòu),可以是數(shù)組,有序。
3、如果執(zhí)行邏輯需要用到二維表特性,就會優(yōu)先考慮使用臨時表。比如我們的例子中,union 需要用到唯一索引約束, group by 還需要用到另外一個字段來存累積計數(shù)。
粉絲福利:Java從入門到入土學(xué)習(xí)路線圖
??????

??長按上方微信二維碼?2 秒
感謝點贊支持下哈?