
什么是 MySQL 的“回表”?

大家好我是躍哥。平時(shí)躍哥就斷斷續(xù)續(xù)和大家分享一些數(shù)據(jù)庫(kù)的知識(shí),有簡(jiǎn)單的,有進(jìn)階的,不知道大家平時(shí)看了沒有呢?今天繼續(xù)和大家分享數(shù)據(jù)庫(kù)的一個(gè)概念--“回表”。
小伙伴們?cè)诿嬖嚨臅r(shí)候,有一個(gè)特別常見的問題,那就是數(shù)據(jù)庫(kù)的回表。什么是回表?為什么需要回表?
今天松哥就來和大家聊一聊這個(gè)話題。
1. 索引結(jié)構(gòu)
要搞明白這個(gè)問題,需要大家首先明白 MySQL 中索引存儲(chǔ)的數(shù)據(jù)結(jié)構(gòu)。這個(gè)其實(shí)很多小伙伴可能也都聽說過,B+Tree 嘛!
B+Tree 是什么?那你得先明白什么是 B-Tree,來看如下一張圖:
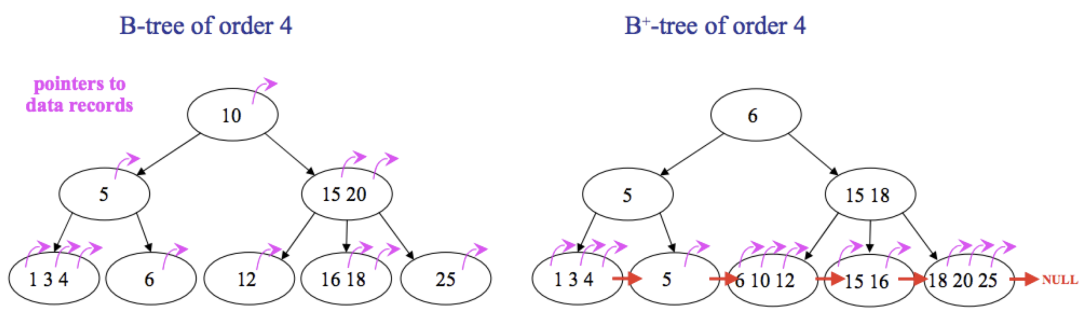
前面是 B-Tree,后面是 B+Tree,兩者的區(qū)別在于:
B-Tree 中,所有節(jié)點(diǎn)都會(huì)帶有指向具體記錄的指針;B+Tree 中只有葉子結(jié)點(diǎn)會(huì)帶有指向具體記錄的指針。 B-Tree 中不同的葉子之間沒有連在一起;B+Tree 中所有的葉子結(jié)點(diǎn)通過指針連接在一起。 B-Tree 中可能在非葉子結(jié)點(diǎn)就拿到了指向具體記錄的指針,搜索效率不穩(wěn)定;B+Tree 中,一定要到葉子結(jié)點(diǎn)中才可以獲取到具體記錄的指針,搜索效率穩(wěn)定。
基于上面兩點(diǎn)分析,我們可以得出如下結(jié)論:
B+Tree 中,由于非葉子結(jié)點(diǎn)不帶有指向具體記錄的指針,所以非葉子結(jié)點(diǎn)中可以存儲(chǔ)更多的索引項(xiàng),這樣就可以有效降低樹的高度,進(jìn)而提高搜索的效率。 B+Tree 中,葉子結(jié)點(diǎn)通過指針連接在一起,這樣如果有范圍掃描的需求,那么實(shí)現(xiàn)起來將非常容易,而對(duì)于 B-Tree,范圍掃描則需要不停的在葉子結(jié)點(diǎn)和非葉子結(jié)點(diǎn)之間移動(dòng)。
對(duì)于第一點(diǎn),一個(gè) B+Tree 可以存多少條數(shù)據(jù)呢?以主鍵索引的 B+Tree 為例(二級(jí)索引存儲(chǔ)數(shù)據(jù)量的計(jì)算原理類似,但是葉子節(jié)點(diǎn)和非葉子節(jié)點(diǎn)上存儲(chǔ)的數(shù)據(jù)格式略有差異),我們可以簡(jiǎn)單算一下。
?計(jì)算機(jī)在存儲(chǔ)數(shù)據(jù)的時(shí)候,最小存儲(chǔ)單元是扇區(qū),一個(gè)扇區(qū)的大小是 512 字節(jié),而文件系統(tǒng)(例如 XFS/EXT4)最小單元是塊,一個(gè)塊的大小是 4KB。InnoDB 引擎存儲(chǔ)數(shù)據(jù)的時(shí)候,是以頁(yè)為單位的,每個(gè)數(shù)據(jù)頁(yè)的大小默認(rèn)是 16KB,即四個(gè)塊。
基于這樣的知識(shí)儲(chǔ)備,我們可以大致算一下一個(gè) B+Tree 能存多少數(shù)據(jù)。
假設(shè)數(shù)據(jù)庫(kù)中一條記錄是 1KB,那么一個(gè)頁(yè)就可以存 16 條數(shù)據(jù)(葉子結(jié)點(diǎn));對(duì)于非葉子結(jié)點(diǎn)存儲(chǔ)的則是主鍵值+指針,在 InnoDB 中,一個(gè)指針的大小是 6 個(gè)字節(jié),假設(shè)我們的主鍵是 bigint ,那么主鍵占 8 個(gè)字節(jié),當(dāng)然還有其他一些頭信息也會(huì)占用字節(jié)我們這里就不考慮了,我們大概算一下,小伙伴們心里有數(shù)即可:
16*1024/(8+6)=1170
即一個(gè)非葉子結(jié)點(diǎn)可以指向 1170 個(gè)頁(yè),那么一個(gè)三層的 B+Tree 可以存儲(chǔ)的數(shù)據(jù)量為:
1170*1170*16=21902400
可以存儲(chǔ) 2100萬(wàn) 條數(shù)據(jù)。
在 InnoDB 存儲(chǔ)引擎中,B+Tree 的高度一般為 2-4 層,這就可以滿足千萬(wàn)級(jí)的數(shù)據(jù)的存儲(chǔ),查找數(shù)據(jù)的時(shí)候,一次頁(yè)的查找代表一次 IO,那我們通過主鍵索引查詢的時(shí)候,其實(shí)最多只需要 2-4 次 IO 操作就可以了。
大家先搞明白這個(gè) B+Tree。
2. 兩類索引
大家知道,MySQL 中的索引有很多中不同的分類方式,可以按照數(shù)據(jù)結(jié)構(gòu)分,可以按照邏輯角度分,也可以按照物理存儲(chǔ)分,其中,按照物理存儲(chǔ)方式,可以分為聚簇索引和非聚簇索引。
我們?nèi)粘Kf的主鍵索引,其實(shí)就是聚簇索引(Clustered Index);主鍵索引之外,其他的都稱之為非主鍵索引,非主鍵索引也被稱為二級(jí)索引(Secondary Index),或者叫作輔助索引。
對(duì)于主鍵索引和非主鍵索引,使用的數(shù)據(jù)結(jié)構(gòu)都是 B+Tree,唯一的區(qū)別在于葉子結(jié)點(diǎn)中存儲(chǔ)的內(nèi)容不同:
主鍵索引的葉子結(jié)點(diǎn)存儲(chǔ)的是一行完整的數(shù)據(jù)。 非主鍵索引的葉子結(jié)點(diǎn)存儲(chǔ)的則是主鍵值。
這就是兩者最大的區(qū)別。
所以,當(dāng)我們需要查詢的時(shí)候:
如果是通過主鍵索引來查詢數(shù)據(jù),例如 select * from user where id=100,那么此時(shí)只需要搜索主鍵索引的 B+Tree 就可以找到數(shù)據(jù)。如果是通過非主鍵索引來查詢數(shù)據(jù),例如 select * from user where username='javaboy',那么此時(shí)需要先搜索 username 這一列索引的 B+Tree,搜索完成后得到主鍵的值,然后再去搜索主鍵索引的 B+Tree,就可以獲取到一行完整的數(shù)據(jù)。
對(duì)于第二種查詢方式而言,一共搜索了兩棵 B+Tree,第一次搜索 B+Tree 拿到主鍵值后再去搜索主鍵索引的 B+Tree,這個(gè)過程就是所謂的回表。
從上面的分析中我們也能看出,通過非主鍵索引查詢要掃描兩棵 B+Tree,而通過主鍵索引查詢只需要掃描一棵 B+Tree,所以如果條件允許,還是建議在查詢中優(yōu)先選擇通過主鍵索引進(jìn)行搜索。
3. 一定會(huì)回表嗎?
那么不用主鍵索引就一定需要回表嗎?
不一定!
如果查詢的列本身就存在于索引中,那么即使使用二級(jí)索引,一樣也是不需要回表的。
舉個(gè)例子,我有如下一張表:
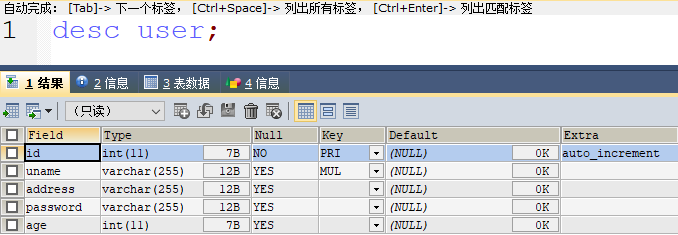
uname 和 address 字段組成了一個(gè)復(fù)合索引,那么此時(shí),雖然這是一個(gè)二級(jí)索引,但是索引樹的葉子節(jié)點(diǎn)中除了保存主鍵值,也保存了 address 的值。
我們來看如下分析:

可以看到,此時(shí)使用到了 uname 索引,但是最后的 Extra 的值為 Using index,這就表示用到了索引覆蓋掃描(覆蓋索引),此時(shí)直接從索引中過濾不需要的記錄并返回命中的結(jié)果,這一步是在 MySQL 服務(wù)器層完成的,并且不需要回表。
4. 擴(kuò)展
基于第一、二小節(jié)的分析,我們?cè)賮磙垡晦蹫槭裁丛跀?shù)據(jù)庫(kù)中建議使用自增主鍵。
自增主鍵往往占用空間比較小,int 占 4 個(gè)字節(jié),bigint 占 8 個(gè)字節(jié)。由于二級(jí)索引的葉子節(jié)點(diǎn)存儲(chǔ)的就是主鍵,所以如果主鍵占用空間小,意味著二級(jí)索引的葉子節(jié)點(diǎn)將來占用的空間小(間接降低 B+Tree 的高度,提高搜索效率)。 自增主鍵插入的時(shí)候比較快,直接插入即可,不會(huì)涉及到葉子節(jié)點(diǎn)分裂等問題(不需要挪動(dòng)其他記錄);而其他非自增主鍵插入的時(shí)候,可能要插入到兩個(gè)已有的數(shù)據(jù)中間,就有可能導(dǎo)致葉子節(jié)點(diǎn)分裂等問題,插入效率低(要挪動(dòng)其他記錄)。
當(dāng)然,這個(gè)是基于技術(shù)層面的討論,如果業(yè)務(wù)上無法使用自增主鍵或者有其他要求導(dǎo)致無法使用自增主鍵,那沒辦法,在滿足新要求的情況下重新選擇一個(gè)最佳實(shí)踐吧。
好啦,今天的主題是回表,現(xiàn)在大家明白什么是回表了吧?

