
Java 代碼實(shí)現(xiàn)——使用 IK 分詞器進(jìn)行詞頻統(tǒng)計(jì)
本文主要介紹如何通過 IK 分詞器進(jìn)行詞頻統(tǒng)計(jì)。
使用分詞器對文章的詞頻進(jìn)行統(tǒng)計(jì),主要目的是實(shí)現(xiàn)如下圖所示的詞云功能,可以找到文章內(nèi)的重點(diǎn)詞匯。
后續(xù)也可以對詞進(jìn)行詞性標(biāo)注,實(shí)體識別以及對實(shí)體的情感分析等功能。

詞頻統(tǒng)計(jì)服務(wù)具體模塊如下:
數(shù)據(jù)輸入:文本信息 數(shù)據(jù)輸出:詞 - 詞頻(TF-IDF等) - 詞性等內(nèi)容 使用的組件:分詞器、語料庫、詞云展示組件等 功能點(diǎn):白名單,黑名單,同義詞等
現(xiàn)存的中文分詞器有 IK、HanLP、jieba 和 NLPIR 等幾種,不同分詞器各有特點(diǎn),本文使用 IK 實(shí)現(xiàn),因?yàn)?ES 一般使用 medcl 等大佬封裝的 IK 分詞器插件作為中文分詞器。
由于 ES 的 IK 分詞器插件深度結(jié)合了 ES,僅對文本分詞使用不到 ES 的內(nèi)容,所以文本采用申艷超大佬版本的 IK。
IK 地址:https://github.com/blueshen/ik-analyzer
1. IK 分詞統(tǒng)計(jì)代碼
IK 的代碼相對比較簡單,東西不多,將 String 拆分為詞并統(tǒng)計(jì)代碼如下:
單純統(tǒng)計(jì)詞頻:
/**
?*?全文本詞頻統(tǒng)計(jì)
?*
?*?@param?content??文本內(nèi)容
?*?@param?useSmart?是否使用?smart
?*?@return?詞,詞頻
?*?@throws?IOException
?*/
private?static?Map?countTermFrequency(String?content,?Boolean?useSmart)?throws?IOException?{
????//?輸出結(jié)果?Map
????Map?frequencies?=?new?HashMap<>();
????if?(StringUtils.isBlank(content))?{
????????return?frequencies;
????}
????DefaultConfig?conf?=?new?DefaultConfig();
????conf.setUseSmart(useSmart);
????//?使用?IKSegmenter?初始化文本信息并加載詞典
????IKSegmenter?ikSegmenter?=?new?IKSegmenter(new?StringReader(content),?conf);
????Lexeme?lexeme;
????while?((lexeme?=?ikSegmenter.next())?!=?null)?{
????????if?(lexeme.getLexemeText().length()?>?1)?{//?過濾單字,也可以過濾其他內(nèi)容,如數(shù)字和單純符號等內(nèi)容
????????????final?String?term?=?lexeme.getLexemeText();
????????????//?Map?累加操作
????????????frequencies.compute(term,?(k,?v)?->?{
????????????????if?(v?==?null)?{
????????????????????v?=?1;
????????????????}?else?{
????????????????????v?+=?1;
????????????????}
????????????????return?v;
????????????});
????????}
????}
????return?frequencies;
}
統(tǒng)計(jì)詞頻和文檔頻率:
/**
?*?文本列表詞頻和詞文檔頻率統(tǒng)計(jì)
?*
?*?@param?docs?????文檔列表
?*?@param?useSmart?是否使用只能分詞
?*?@return?詞頻列表?詞-[詞頻,文檔頻率]
?*?@throws?IOException
?*/
private?static?Map?countTFDF(List?docs,?boolean?useSmart)?throws?IOException?{
????//?輸出結(jié)果?Map
????Map?frequencies?=?new?HashMap<>();
????for?(String?doc?:?docs)?{
????????if?(StringUtils.isBlank(doc))?{
????????????continue;
????????}
????????DefaultConfig?conf?=?new?DefaultConfig();
????????conf.setUseSmart(useSmart);
????????//?使用?IKSegmenter?初始化文本信息并加載詞典
????????IKSegmenter?ikSegmenter?=?new?IKSegmenter(new?StringReader(doc),?conf);
????????Lexeme?lexeme;
????????//?用于文檔頻率統(tǒng)計(jì)的?Set
????????Set?terms?=?new?HashSet<>();
????????while?((lexeme?=?ikSegmenter.next())?!=?null)?{
????????????if?(lexeme.getLexemeText().length()?>?1)?{
????????????????final?String?text?=?lexeme.getLexemeText();
????????????????//?進(jìn)行詞頻統(tǒng)計(jì)
????????????????frequencies.compute(text,?(k,?v)?->?{
????????????????????if?(v?==?null)?{
????????????????????????v?=?new?Integer[]{1,?0};
????????????????????}?else?{
????????????????????????v[0]?+=?1;
????????????????????}
????????????????????return?v;
????????????????});
????????????????terms.add(text);
????????????}
????????}?
????????//?進(jìn)行文檔頻率統(tǒng)計(jì):無需初始化 Map,統(tǒng)計(jì)詞頻后 Map 里面必有該詞記錄
????????for?(String?term?:?terms)?{
????????????frequencies.get(term)[1]?+=?1;
????????}
????}
????return?frequencies;
}
2. 獲取詞云 TopN 個詞
獲取 TopN 個詞用于詞云展示有多種排序方式,可以直接根據(jù)詞頻、文檔頻率或者 TF-IDF 等算法進(jìn)行排序,本文僅根據(jù)詞頻求取 TopN。M 個數(shù)字獲取 TopN 有以下算法:
M 小 N 小:快速選擇算法 M 大 N 小:小頂堆 M 大 N 大:歸并排序
本文采用小頂堆方式實(shí)現(xiàn),對應(yīng)JAVA中的優(yōu)先隊(duì)列數(shù)據(jù)結(jié)構(gòu) PriorityQueue:
/**
?*?按出現(xiàn)次數(shù),從高到低排序取?TopN
?*
?*?@param?data?詞和排序數(shù)字對應(yīng)的?Map
?*?@param?TopN?詞云展示的?TopN
?*?@return?前?N?個詞和排序值
?*/
private?static?List>?order(Map?data,?int?topN)?{
????PriorityQueue>?priorityQueue?=?new?PriorityQueue<>(data.size(),?new?Comparator>()?{
????????@Override
????????public?int?compare(Map.Entry?o1,?Map.Entry?o2)?{
????????????return?o2.getValue().compareTo(o1.getValue());
????????}
????});
????for?(Map.Entry?entry?:?data.entrySet())?{
????????priorityQueue.add(entry);
????}
????//TODO?當(dāng)前100詞頻一致時(概率極低)的處理辦法,if(?list(0).value?==?list(99).value?){xxx}
????List>?list?=?new?ArrayList<>();
????//統(tǒng)計(jì)結(jié)果隊(duì)列size和topN值取較小值列表
????int?size?=?priorityQueue.size()?<=?topN???priorityQueue.size()?:?topN;
????for?(int?i?=?0;?i?????????list.add(priorityQueue.remove());
????}
????return?list;
}
3. IK 代碼淺析
核心主類為IKSegmenter,需要關(guān)注的點(diǎn)有dic包也就是詞典相關(guān)內(nèi)容以及字符處理工具類CharacterUtil的identifyCharType()方法,目錄結(jié)構(gòu)如下:
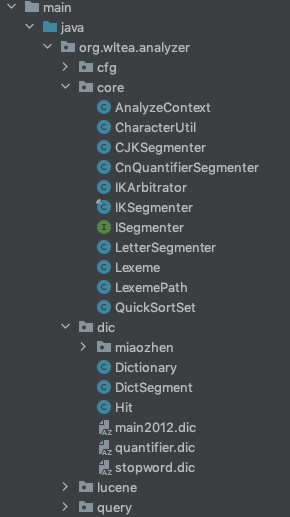
IKSegmenter類結(jié)構(gòu)如下圖,其中 init() 為私有方法,初始化加載詞典采用非懶加載模式,在第一次初始化IKSegmenter實(shí)例時會調(diào)用并加載詞典,代碼位于結(jié)構(gòu)圖下方。
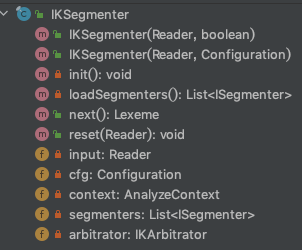
//?IKSegmenter?類構(gòu)造方法
public?IKSegmenter(Reader?input,?Configuration?cfg)?{
????this.input?=?input;
????this.cfg?=?cfg;
????this.init();
}
//?IKSegmenter?類初始化
private?void?init()?{
????//初始化詞典單例
????Dictionary.initial(this.cfg);
????//初始化分詞上下文
????this.context?=?new?AnalyzeContext(this.cfg);
????//加載子分詞器
????this.segmenters?=?this.loadSegmenters();
????//加載歧義裁決器
????this.arbitrator?=?new?IKArbitrator();
}
//?Dictionary?類初始化詞典
public?static?Dictionary?initial(Configuration?cfg)?{
????if?(singleton?==?null)?{
????????synchronized?(Dictionary.class)?{
????????????if?(singleton?==?null)?{
????????????????singleton?=?new?Dictionary(cfg);
????????????????return?singleton;
????????????}
????????}
????}
????return?singleton;
}
詞典私有構(gòu)造方法Dictionary()內(nèi)會加載 IK 自帶的詞典以及擴(kuò)展詞典,我們也可以把自己線上不變的詞典放到這里這樣IKAnalyzer.cfg.xml中就只需要配置經(jīng)常變更詞典即可。
private?Dictionary(Configuration?cfg)?{
????this.cfg?=?cfg;
????this.loadMainDict();//?主詞典以及擴(kuò)展詞典
????this.loadmiaozhenDict();//?自定義詞典加載,仿照其他方法即可
??? this.loadStopWordDict();//?擴(kuò)展停詞詞典
????this.loadQuantifierDict();//?量詞詞典
}
在IKSegmenter類調(diào)用next()方法獲取下一個詞元時,會調(diào)用CharacterUtil類中的identifyCharType()方法識別字符種類,這里我們也可以自定義一些字符種類針對處理新興的網(wǎng)絡(luò)語言,如@、##等內(nèi)容:
static?int?identifyCharType(char?input)?{
????if?(input?>=?'0'?&&?input?<=?'9')?{
????????return?CHAR_ARABIC;
????}?else?if?((input?>=?'a'?&&?input?<=?'z')?||?(input?>=?'A'?&&?input?<=?'Z'))?{
????????return?CHAR_ENGLISH;
????}?else?{
????????Character.UnicodeBlock?ub?=?Character.UnicodeBlock.of(input);
????????//caster?增加#為中文字符
????????if?(ub?==?Character.UnicodeBlock.CJK_UNIFIED_IDEOGRAPHS
????????????????||?ub?==?Character.UnicodeBlock.CJK_COMPATIBILITY_IDEOGRAPHS
????????????????||?ub?==?Character.UnicodeBlock.CJK_UNIFIED_IDEOGRAPHS_EXTENSION_A?||input=='#')?{
????????????//目前已知的中文字符UTF-8集合
????????????return?CHAR_CHINESE;
????????}?else?if?(ub?==?Character.UnicodeBlock.HALFWIDTH_AND_FULLWIDTH_FORMS?//全角數(shù)字字符和日韓字符
????????????????//韓文字符集
????????????????||?ub?==?Character.UnicodeBlock.HANGUL_SYLLABLES
????????????????||?ub?==?Character.UnicodeBlock.HANGUL_JAMO
????????????????||?ub?==?Character.UnicodeBlock.HANGUL_COMPATIBILITY_JAMO
????????????????//日文字符集
????????????????||?ub?==?Character.UnicodeBlock.HIRAGANA?//平假名
????????????????||?ub?==?Character.UnicodeBlock.KATAKANA?//片假名
????????????????||?ub?==?Character.UnicodeBlock.KATAKANA_PHONETIC_EXTENSIONS)?{
????????????return?CHAR_OTHER_CJK;
????????}
????}
????//其他的不做處理的字符
????return?CHAR_USELESS;
}
由于 IK 內(nèi)容不多,建議大家可以從頭捋一遍,包括各個實(shí)現(xiàn)ISegmenter接口的各個自分詞器等內(nèi)容。
4. 進(jìn)行詞云展示
詞云展示可以使用 Kibana 自帶的詞云 Dashboard,或者比較熱門的 WordCloud。自己測試可以使用線上的微詞云快速便捷查看詞云效果:導(dǎo)入兩列的 XLS 文件即可,左側(cè)控制欄也可以對形狀字體等進(jìn)行配置美化。
展示效果如下圖所示:

5. 總結(jié)
本文主要通過 IK 分詞器實(shí)現(xiàn)了詞頻統(tǒng)計(jì)功能,用于詞云的展示,不僅僅適用于 ES,任何數(shù)據(jù)源文檔都可以進(jìn)行詞頻統(tǒng)計(jì)。
但是功能比較基礎(chǔ),感興趣的同學(xué)可以實(shí)現(xiàn)一下詞排序方式變更(tf/idf)、詞性標(biāo)注、實(shí)體識別和情感分析等功能;IK 分詞器較為局限,需要使用 HanLP(自帶詞性標(biāo)注)等更高級的分詞器以及 NLP 相關(guān)知識來輔助,也可以參考百度 AI 的詞法分析模塊。
作者:caster(Elastic 認(rèn)證工程師)
作者博客:https://www.jianshu.com/u/cc7ee7454afc
審核:銘毅天下
說明

上個月,死磕 Elasticsearch 知識星球搞了:“群智涌現(xiàn)”杯輸出倒逼輸入——Elastic干貨輸出活動。
后續(xù)會不定期逐步推出系列文章,目的:以文會友,“輸出倒逼輸入”。
推薦
更短時間更快習(xí)得更多干貨!
已帶領(lǐng)75位球友通過 Elastic 官方認(rèn)證!
