在云原生時(shí)代下,應(yīng)用工作負(fù)載都是以容器的形式部署在宿主機(jī),共享各類物理資源。隨著宿主機(jī)硬件性能的增強(qiáng),單節(jié)點(diǎn)的容器部署密度進(jìn)一步提升,由此帶來的進(jìn)程間 CPU 爭用,跨 NUMA 訪存等問題也更加嚴(yán)重,影響了應(yīng)用性能表現(xiàn)。如何分配和管理宿主機(jī)的 CPU 資源,保障應(yīng)用可以獲得最優(yōu)的服務(wù)質(zhì)量,是衡量容器服務(wù)技術(shù)能力的關(guān)鍵因素。節(jié)點(diǎn)側(cè)容器 CPU 資源管理
Kubernetes 為容器資源管理提供了 request(請求)和 limit(約束)的語義描述,當(dāng)容器指定了 request 時(shí),調(diào)度器會利用該信息決定 Pod 應(yīng)該被分配到哪個(gè)節(jié)點(diǎn)上;當(dāng)容器指定了 limit 時(shí),Kubelet 會確保容器在運(yùn)行時(shí)不會超用。
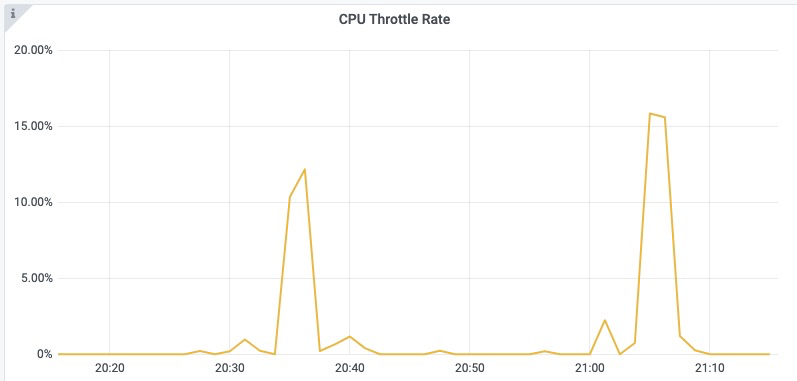
CPU 是一種典型的分時(shí)復(fù)用型資源,內(nèi)核調(diào)度器會將 CPU 分為多個(gè)時(shí)間片,輪流為各進(jìn)程分配一定的運(yùn)行時(shí)間。Kubelet 默認(rèn)的 CPU 管理策略會通過 Linux 內(nèi)核的 CFS 帶寬控制器(CFS Bandwidth Controller)來控制容器 CPU 資源的使用上限。在多核節(jié)點(diǎn)下,進(jìn)程在運(yùn)行過程中經(jīng)常會被遷移到其不同的核心,考慮到有些應(yīng)用的性能對 CPU 上下文切換比較敏感,Kubelet 還提供了 static 策略,允許 Guaranteed 類型 Pod 獨(dú)占 CPU 核心。內(nèi)核 CFS 調(diào)度是通過 cfs_period 和 cfs_quota 兩個(gè)參數(shù)來管理容器 CPU 時(shí)間片消耗的,cfs_period 一般為固定值 100 ms,cfs_quota 對應(yīng)容器的 CPU Limit。例如對于一個(gè) CPU Limit = 2 的容器,其 cfs_quota 會被設(shè)置為 200ms,表示該容器在每 100ms 的時(shí)間周期內(nèi)最多使用 200ms 的 CPU 時(shí)間片,即 2 個(gè) CPU 核心。當(dāng)其 CPU 使用量超出預(yù)設(shè)的 limit 值時(shí),容器中的進(jìn)程會受內(nèi)核調(diào)度約束而被限流。細(xì)心的應(yīng)用管理員往往會在集群 Pod 監(jiān)控中的 CPU Throttle Rate 指標(biāo)觀察到這一特征。讓應(yīng)用管理員常常感到疑惑的是,為什么容器的資源利用率并不高,但卻頻繁出現(xiàn)應(yīng)用性能下降的問題?從 CPU 資源的角度來分析,問題通常來自于以下兩方面:一是內(nèi)核在根據(jù) CPU Limit 限制容器資源消耗時(shí)產(chǎn)生的 CPU Throttle 問題;二是受 CPU 拓?fù)浣Y(jié)構(gòu)的影響,部分應(yīng)用對進(jìn)程在 CPU 間的上下文切換比較敏感,尤其是在發(fā)生跨 NUMA 訪問時(shí)的情況。
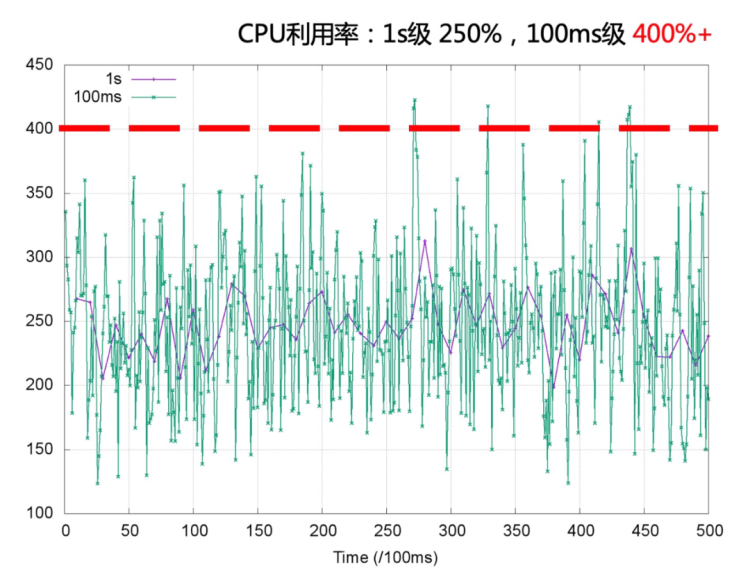
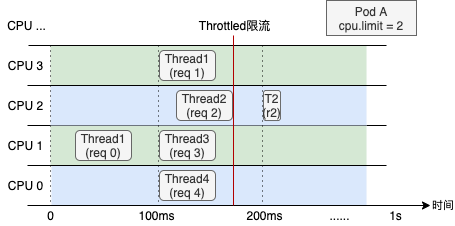
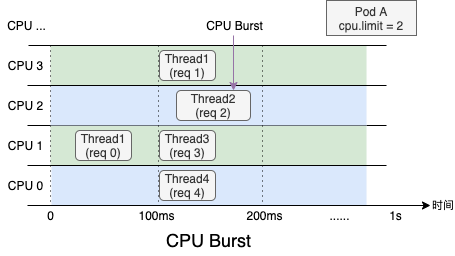
受內(nèi)核調(diào)度控制周期(cfs_period)影響,容器的 CPU 利用率往往具有一定的欺騙性,下圖展示了某容器一段時(shí)間的 CPU 使用情況(單位為0.01核),可以看到在 1s 級別的粒度下(圖中紫色折線),容器的 CPU 用量較為穩(wěn)定,平均在 2.5 核左右。根據(jù)經(jīng)驗(yàn),管理員會將 CPU Limit設(shè)置為 4 核。本以為這已經(jīng)保留了充足的彈性空間,然而若我們將觀察粒度放大到 100ms 級別(圖中綠色折線),容器的 CPU 用量呈現(xiàn)出了嚴(yán)重的毛刺現(xiàn)象,峰值達(dá)到 4 核以上。此時(shí)容器會產(chǎn)生頻繁的 CPU Throttle,進(jìn)而導(dǎo)致應(yīng)用性能下降、RT 抖動(dòng),但我們從常用的 CPU 利用率指標(biāo)中竟然完全無法發(fā)現(xiàn)!毛刺產(chǎn)生的原因通常是由于應(yīng)用突發(fā)性的 CPU 資源需求(如代碼邏輯熱點(diǎn)、流量突增等),下面我們用一個(gè)具體的例子來描述 CPU Throttle 導(dǎo)致應(yīng)用性能下降的過程。圖中展示了一個(gè)CPU Limit = 2 的 Web 服務(wù)類容器,在收到請求后(req)各線程(Thread)的 CPU 資源分配情況。假設(shè)每個(gè)請求的處理時(shí)間均為 60 ms,可以看到,即使容器在最近整體的 CPU 利用率較低,由于在 100 ms~200 ms 區(qū)間內(nèi)連續(xù)處理了4 個(gè)請求,將該內(nèi)核調(diào)度周期內(nèi)的時(shí)間片預(yù)算(200ms)全部消耗,Thread 2 需要等待下一個(gè)周期才能繼續(xù)將 req 2 處理完成,該請求的響應(yīng)時(shí)延(RT)就會變長。這種情況在應(yīng)用負(fù)載上升時(shí)將更容易發(fā)生,導(dǎo)致其 RT 的長尾情況將會變得更為嚴(yán)重。為了避免 CPU Throttle 的問題,我們只能將容器的 CPU Limit 值調(diào)大。然而,若想徹底解決 CPU Throttle,通常需要將 CPU Limit 調(diào)大兩三倍,有時(shí)甚至五到十倍,問題才會得到明顯緩解。而為了降低 CPU Limit 超賣過多的風(fēng)險(xiǎn),還需降低容器的部署密度,進(jìn)而導(dǎo)致整體資源成本上升。?CPU 拓?fù)浣Y(jié)構(gòu)的影響
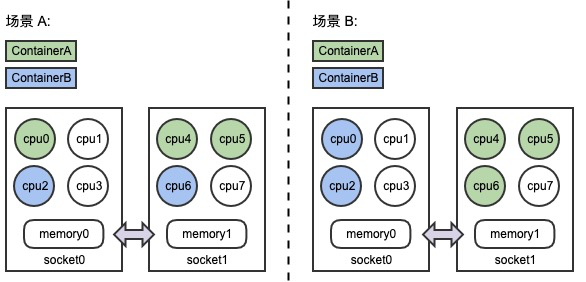
在 NUMA 架構(gòu)下,節(jié)點(diǎn)中的 CPU 和內(nèi)存會被切分成了兩部分甚至更多(例如圖中 Socket0,Socket1),CPU 被允許以不同的速度訪問內(nèi)存的不同部分,當(dāng) CPU 跨 Socket 訪問另一端內(nèi)存時(shí),其訪存時(shí)延相對更高。盲目地在節(jié)點(diǎn)為容器分配物理資源可能會降低延遲敏感應(yīng)用的性能,因此我們需要避免將 CPU 分散綁定到多個(gè) Socket 上,提升內(nèi)存訪問時(shí)的本地性。如下圖所示,同樣是為兩個(gè)容器分配 CPU、內(nèi)存資源,顯然場景B中的分配策略更為合理。Kubelet 提供的 CPU 管理策略 “static policy”、以及拓?fù)涔芾聿呗?“single-numa-node”,會將容器與 CPU 綁定,可以提升應(yīng)用負(fù)載與 CPU Cache,以及 NUMA 之間的親和性,但這是否一定能夠解決所有因 CPU 帶來的性能問題呢,我們可以看下面的例子。
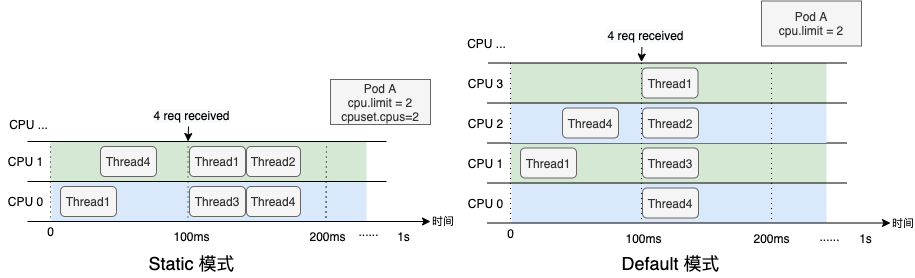
某 CPU Limit = 2 的容器,其應(yīng)用在 100ms 時(shí)間點(diǎn)收到了 4 個(gè)請求需要處理,在 Kubelet 提供的 static 模式下,容器會被固定在 CPU0 和 CPU1 兩個(gè)核心,各線程只能排隊(duì)運(yùn)行,而在 Default 模式下,容器獲得了更多的 CPU 彈性,收到請求后各線程可以立即處理。可以看出,綁核策略并不是“銀彈”,Default 模式也有適合自己的應(yīng)用場景。
事實(shí)上,CPU 綁核解決的是進(jìn)程在不同 Core,特別是不同 NUMA 間上下文切換帶來的性能問題,但解決的同時(shí)也損失了資源彈性。在這種情況下線程會在各 CPU 排隊(duì)運(yùn)行,雖然 CPU Throttle 指標(biāo)可能有所降低,但應(yīng)用自身的性能問題并沒有完全解決。使用 CPU Burst 機(jī)制提升容器性能
往期文章我們介紹了阿里云貢獻(xiàn)的 CPU Burst 內(nèi)核特性,可以有效解決 CPU Throttle 的問題,當(dāng)容器真實(shí) CPU 資源使用小于 cfs_quota 時(shí),內(nèi)核會將多余的 CPU 時(shí)間“存入”到 cfs_burst 中;當(dāng)容器有突發(fā)的 CPU 資源需求,需要使用超出 cfs_quota 的資源時(shí),內(nèi)核的 CFS 帶寬控制器(CFS Bandwidth Controller,簡稱 BWC) 會允許其消費(fèi)其之前存到 cfs_burst 的時(shí)間片。CPU Burst 機(jī)制可以有效解決延遲敏感性應(yīng)用的 RT 長尾問題,提升容器性能表現(xiàn),目前阿里云容器服務(wù) ACK 已經(jīng)完成了對 CPU Burst 機(jī)制的全面支持。對于尚未支持 CPU Burst 策略的內(nèi)核版本,ACK 也會通過類似的原理,監(jiān)測容器 CPU Throttle 狀態(tài),并動(dòng)態(tài)調(diào)節(jié)容器的 CPU Limit,實(shí)現(xiàn)與內(nèi)核 CPU Burst 策略類似的效果。
我們使用 Apache HTTP Server 作為延遲敏感型在線應(yīng)用,通過模擬請求流量,評估 CPU Burst 能力對響應(yīng)時(shí)間(RT)的提升效果。以下數(shù)據(jù)分別展示了 CPU Burst 策略開啟前后的表現(xiàn)情況: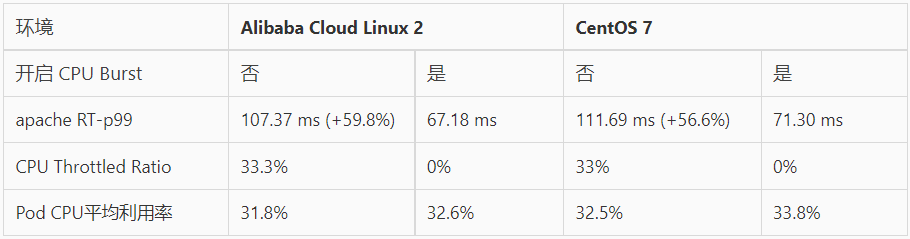
- 在開啟 CPU Burst 能力后,應(yīng)用的 RT 指標(biāo)的 p99 分位值得到了明顯的優(yōu)化。
- 對比 CPU Throttled 及利用率指標(biāo),可以看到開啟 CPU Burst 能力后,CPU Throttled 情況得到了消除,同時(shí) Pod 整體利用率基本保持不變。
雖然 Kubelet 提供了單機(jī)的資源管理策略(static policy,single-numa-node),可以部分解決應(yīng)用性能表現(xiàn)受 CPU 緩存、NUMA 親和性影響的問題,但該策略尚有以下不足之處:- static policy 只支持 QoS 為 Guaranteed?的 Pod,其他 QoS 類型的 Pod 無法使用
- 策略對節(jié)點(diǎn)內(nèi)所有 Pod 全部生效,而我們通過前面的分析知道,CPU 綁核并不是”銀彈“
- 中心調(diào)度并不感知節(jié)點(diǎn)實(shí)際的 CPU 分配情況,無法在集群范圍內(nèi)選擇到最優(yōu)組合
阿里云容器服務(wù) ACK 基于 Scheduling framework 實(shí)現(xiàn)了拓?fù)涓兄{(diào)度以及靈活的綁核策略,針對 CPU 敏感型的工作負(fù)載可以提供更好的性能。ACK 拓?fù)涓兄{(diào)度可以適配所有 QoS 類型,并支持在 Pod 維度按需開啟,同時(shí)可以在全集群范圍內(nèi)選擇節(jié)點(diǎn)和 CPU 拓?fù)涞淖顑?yōu)組合。
通過對 Nginx 服務(wù)進(jìn)行的評測,我們發(fā)現(xiàn)在 Intel(104核)、AMD(256核)的物理機(jī)上,使用 CPU 拓?fù)涓兄{(diào)度能夠?qū)?yīng)用性能提升 22%~43%。
CPU Burst、拓?fù)涓兄{(diào)度是阿里云容器服務(wù) ACK 提升應(yīng)用性能的兩大利器,它們解決了不同場景下的 CPU 資源管理,可以共同使用。
CPU Burst 解決了內(nèi)核 BWC 調(diào)度時(shí)針對 CPU Limit 的限流問題,可以有效提升延時(shí)敏感型任務(wù)的性能表現(xiàn)。但 CPU Burst 本質(zhì)并不是將資源無中生有地變出來,若容器 CPU 利用率已經(jīng)很高(例如大于50%),CPU Burst 能起到的優(yōu)化效果將會受限,此時(shí)應(yīng)該通過 HPA 或 VPA 等手段對應(yīng)用進(jìn)行擴(kuò)容。
拓?fù)涓兄{(diào)度降低了工作負(fù)載 CPU 上下文切換的開銷,特別是在 NUMA 架構(gòu)下,可以提升 CPU 密集型,訪存密集型應(yīng)用的服務(wù)質(zhì)量。不過正如前文中提到的,CPU 綁核并不是“銀彈”,實(shí)際效果取決于應(yīng)用類型。此外,若同一節(jié)點(diǎn)內(nèi)大量 Burstable ?類型 Pod 同時(shí)開啟了拓?fù)涓兄{(diào)度,CPU 綁核可能會產(chǎn)生重疊,在個(gè)別場景下反而會加劇應(yīng)用間的干擾。因此,拓?fù)涓兄{(diào)度更適合針對性的開啟。