
基于強化學(xué)習(xí)的自動化剪枝模型
點擊上方“視學(xué)算法”,選擇加"星標"或“置頂”
重磅干貨,第一時間送達
導(dǎo)讀
GitHub上最新開源的一個基于強化學(xué)習(xí)的自動化剪枝模型,本模型在圖像識別的實驗證明了能夠有效減少計算量,同時還能提高模型的精度。
今天為大家介紹一個GitHub上最新開源的一個基于強化學(xué)習(xí)的自動化剪枝模型,本模型在圖像識別的實驗證明了能夠有效減少計算量,同時還能提高模型的精度。
項目地址:
https://github.com/freefuiiismyname/cv-automatic-pruning-transformer
介紹
目前的強化學(xué)習(xí)工作很多集中在利用外部環(huán)境的反饋訓(xùn)練agent,忽略了模型本身就是一種能夠獲得反饋的環(huán)境。本項目的核心思想是:將模型視為環(huán)境,構(gòu)建附生于模型的 agent ,以輔助模型進一步擬合真實樣本。
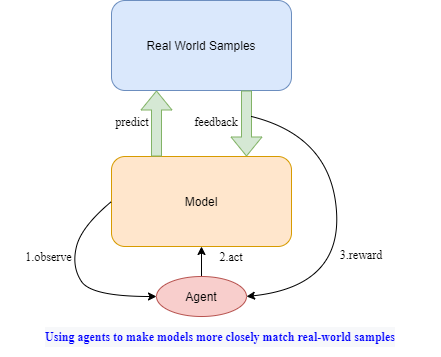
大多數(shù)領(lǐng)域的模型都可以采用這種方式來優(yōu)化,如cv/多模態(tài)等。它至少能夠以三種方式工作:
1.過濾噪音信息,如刪減語音或圖像特征;
2.進一步豐富表征信息,如高效引用外部信息;
3.實現(xiàn)記憶、聯(lián)想、推理等復(fù)雜工作,如構(gòu)建重要信息的記憶池。
這里推出一款早期完成的裁剪機制transformer版本(后面稱為APT),實現(xiàn)了一種更高效的訓(xùn)練模式,能夠優(yōu)化模型指標;此外,可以使用動態(tài)圖丟棄大量的不必要單元,在指標基本不變的情況下,大幅降低計算量。
該項目希望為大家拋磚引玉。

為什么要做自動剪枝
在具體任務(wù)中,往往存在大量毫無價值的信息和過渡性信息,有時不但對任務(wù)無益,還會成為噪聲。比如:表述會存在冗余/無關(guān)片段以及過渡性信息;動物圖像識別中,有時候背景無益于辨別動物主體,即使是動物部分圖像,也僅有小部分是關(guān)鍵的特征。

以transformer為例,在進行self-attention計算時其復(fù)雜度與序列長度平方成正比。長度為10,復(fù)雜度為100;長度為9,復(fù)雜度為81。
利用強化學(xué)習(xí)構(gòu)建agent,能夠精準且自動化地動態(tài)裁剪已喪失意義部分,甚至能將長序列信息壓縮到50-100之內(nèi)(實驗中有從500+的序列長度壓縮到個位數(shù)的示例),以大幅減少計算量。
實驗中,發(fā)現(xiàn)與裁剪agent聯(lián)合訓(xùn)練的模型比普通方法訓(xùn)練的模型效果要更好。
模型介紹及實驗
模型主體
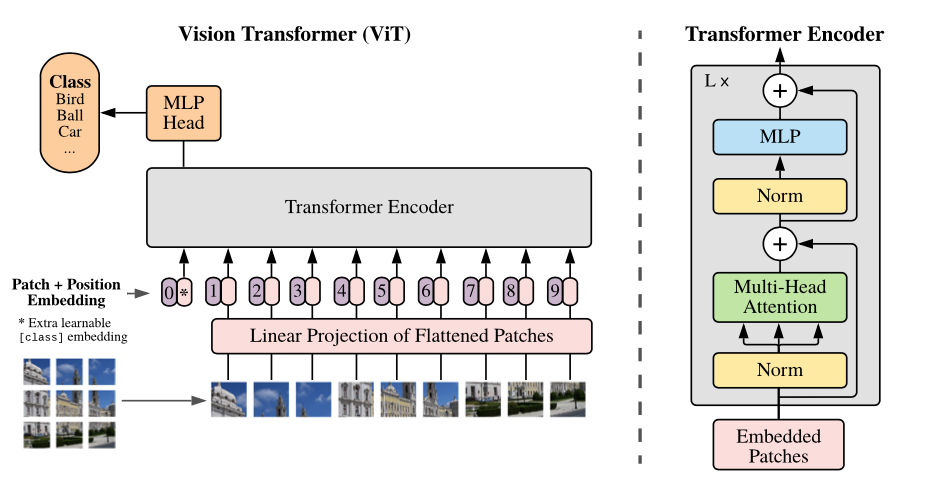
基于transformer的視覺預(yù)訓(xùn)練模型ViT是本項目的模型主體,具體細節(jié)可以查看論文:《An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale》
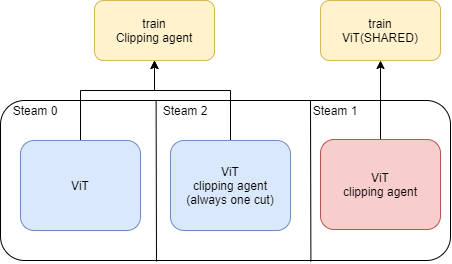
自動化裁剪的智能體
對于強化學(xué)習(xí)agent來說,最關(guān)鍵的問題之一是如何衡量動作帶來的反饋。為了評估單次動作所帶來的影響,使用了以下三步驟:
1、使用一個普通模型(無裁剪模塊)進行預(yù)測;
2、使用一個帶裁剪器的模型(執(zhí)行一次裁剪動作)進行預(yù)測;
3、對比兩次預(yù)測的結(jié)果,若裁剪后損失相對更小,則說明該裁剪動作幫助了模型進一步擬合真實狀況,應(yīng)該得到獎勵;反之,應(yīng)該受到懲罰。
但是在實際預(yù)測過程中,模型是同時裁剪多個單元的,這或?qū)⒁驗槎鄠€裁剪的連鎖反應(yīng)而導(dǎo)致模型失效。訓(xùn)練過程中需要構(gòu)建一個帶裁剪器的模型(可執(zhí)行多次裁剪動作),以減小該問題所帶來的影響。
綜上,本模型使用的是三通道模式進行訓(xùn)練。
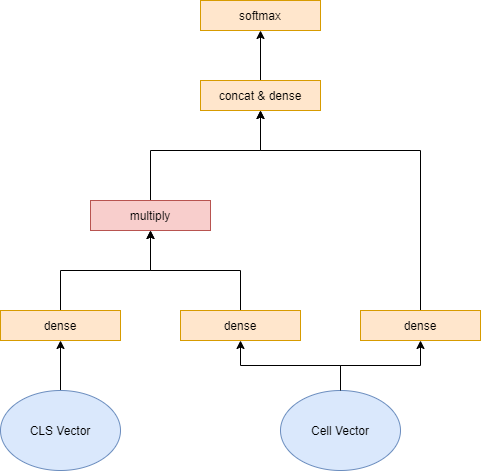
關(guān)于裁剪器的模型結(jié)構(gòu)設(shè)計,本模型中認為如何衡量一個信息單元是否對模型有意義,建立于其自身的信息及它與任務(wù)的相關(guān)性上。
因此以信息單元本身及它與CLS單元的交互作為agent的輸入信息。
實驗
數(shù)據(jù)集 | ViT | APT(pruning) | APT(no pruning) |
CIFAR-100 | 92.3 | 92.6 | 93.03 |
CIFAR-10 | 99.08 | 98.93 | 98.92 |
以上加載的均為ViT-B_16,resolution為224*224。
使用說明
環(huán)境

下載經(jīng)過預(yù)先訓(xùn)練的模型(來自Google官方)
本項目使用的型號:ViT-B_16(您也可以選擇其它型號進行測試)

訓(xùn)練與推理
下載好預(yù)訓(xùn)練模型就可以跑了。

CIFAR-10和CIFAR-100會自動下載和培訓(xùn)。如果使用其他數(shù)據(jù)集,您需要自定義data_utils.py。
在裁剪模式的推理過程中,預(yù)期您將看到如下格式的輸出。

默認的batch size為72、gradient_accumulation_steps為3。當GPU內(nèi)存不足時,您可以通過它們來進行訓(xùn)練。
注:相較于原始的ViT,APT(Automatic pruning transformer)的訓(xùn)練步數(shù)、訓(xùn)練耗時都會上升。原因是使用pruning agent的模型由于總會丟失部分信息,使得收斂速度變慢,同時為了訓(xùn)練pruning agent,也需要多次的觀測、行動、反饋。
致謝
感謝基于pytorch的圖像分類項目(https://github.com/jeonsworld/ViT-pytorch),本項目是在此基礎(chǔ)上做的研發(fā)。
最后再附上一次項目地址,歡迎感興趣的讀者Star?
https://github.com/freefuiiismyname/cv-automatic-pruning-transformer
如果覺得有用,就請分享到朋友圈吧!

點個在看 paper不斷!