
強(qiáng)化學(xué)習(xí)(一)模型基礎(chǔ)
點(diǎn)擊上方“小白學(xué)視覺”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)

?
從今天開始整理強(qiáng)化學(xué)習(xí)領(lǐng)域的知識,主要參考的資料是Sutton的強(qiáng)化學(xué)習(xí)書和UCL強(qiáng)化學(xué)習(xí)的課程。這個(gè)系列大概準(zhǔn)備寫10到20篇,希望寫完后自己的強(qiáng)化學(xué)習(xí)碎片化知識可以得到融會貫通,也希望可以幫到更多的人,畢竟目前系統(tǒng)的講解強(qiáng)化學(xué)習(xí)的中文資料不太多。
第一篇會從強(qiáng)化學(xué)習(xí)的基本概念講起,對應(yīng)Sutton書的第一章和UCL課程的第一講。
章節(jié)目錄
強(qiáng)化學(xué)習(xí)在機(jī)器學(xué)習(xí)中的位置
強(qiáng)化學(xué)習(xí)的建模
強(qiáng)化學(xué)習(xí)的簡單實(shí)例
強(qiáng)化學(xué)習(xí)的學(xué)習(xí)思路和人比較類似,是在實(shí)踐中學(xué)習(xí),比如學(xué)習(xí)走路,如果摔倒了,那么我們大腦后面會給一個(gè)負(fù)面的獎勵(lì)值,說明走的姿勢不好。然后我們從摔倒?fàn)顟B(tài)中爬起來,如果后面正常走了一步,那么大腦會給一個(gè)正面的獎勵(lì)值,我們會知道這是一個(gè)好的走路姿勢。那么這個(gè)過程和之前講的機(jī)器學(xué)習(xí)方法有什么區(qū)別呢?
強(qiáng)化學(xué)習(xí)是和監(jiān)督學(xué)習(xí),非監(jiān)督學(xué)習(xí)并列的第三種機(jī)器學(xué)習(xí)方法,從下圖我們可以看出來。
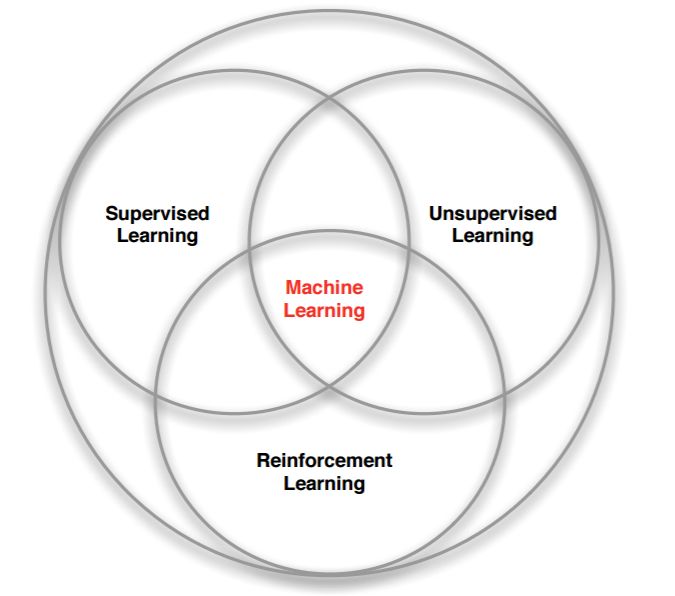
強(qiáng)化學(xué)習(xí)來和監(jiān)督學(xué)習(xí)最大的區(qū)別是它是沒有監(jiān)督學(xué)習(xí)已經(jīng)準(zhǔn)備好的訓(xùn)練數(shù)據(jù)輸出值的。強(qiáng)化學(xué)習(xí)只有獎勵(lì)值,但是這個(gè)獎勵(lì)值和監(jiān)督學(xué)習(xí)的輸出值不一樣,它不是事先給出的,而是延后給出的,比如上面的例子里走路摔倒了才得到大腦的獎勵(lì)值。同時(shí),強(qiáng)化學(xué)習(xí)的每一步與時(shí)間順序前后關(guān)系緊密。而監(jiān)督學(xué)習(xí)的訓(xùn)練數(shù)據(jù)之間一般都是獨(dú)立的,沒有這種前后的依賴關(guān)系。
再來看看強(qiáng)化學(xué)習(xí)和非監(jiān)督學(xué)習(xí)的區(qū)別。也還是在獎勵(lì)值這個(gè)地方。非監(jiān)督學(xué)習(xí)是沒有輸出值也沒有獎勵(lì)值的,它只有數(shù)據(jù)特征。同時(shí)和監(jiān)督學(xué)習(xí)一樣,數(shù)據(jù)之間也都是獨(dú)立的,沒有強(qiáng)化學(xué)習(xí)這樣的前后依賴關(guān)系。
我們現(xiàn)在來看看強(qiáng)化學(xué)習(xí)這樣的問題我們怎么來建模,簡單的來說,是下圖這樣的:
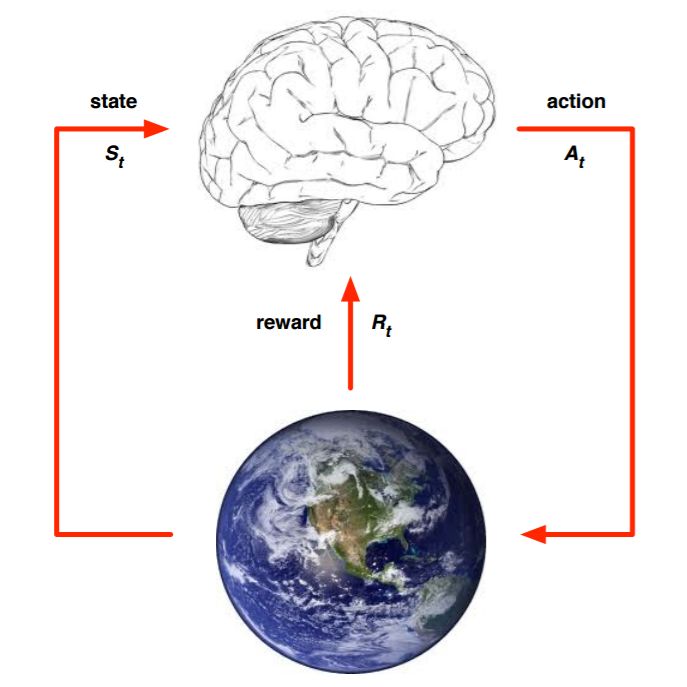
上面的大腦代表我們的算法執(zhí)行個(gè)體,我們可以操作個(gè)體來做決策,即選擇一個(gè)合適的動作(Action)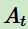 。下面的地球代表我們要研究的環(huán)境,它有自己的狀態(tài)模型,我們選擇了動作后,環(huán)境的狀態(tài)(State)會變,我們會發(fā)現(xiàn)環(huán)境狀態(tài)已經(jīng)變?yōu)?/span>
。下面的地球代表我們要研究的環(huán)境,它有自己的狀態(tài)模型,我們選擇了動作后,環(huán)境的狀態(tài)(State)會變,我們會發(fā)現(xiàn)環(huán)境狀態(tài)已經(jīng)變?yōu)?/span>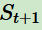 ,同時(shí)我們得到了我們采取動作的延時(shí)獎勵(lì)(Reward)
,同時(shí)我們得到了我們采取動作的延時(shí)獎勵(lì)(Reward)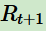 。然后個(gè)體可以繼續(xù)選擇下一個(gè)合適的動作,然后環(huán)境的狀態(tài)又會變,又有新的獎勵(lì)值。。。這就是強(qiáng)化學(xué)習(xí)的思路。
。然后個(gè)體可以繼續(xù)選擇下一個(gè)合適的動作,然后環(huán)境的狀態(tài)又會變,又有新的獎勵(lì)值。。。這就是強(qiáng)化學(xué)習(xí)的思路。
那么我們可以整理下這個(gè)思路里面出現(xiàn)的強(qiáng)化學(xué)習(xí)要素。
第一個(gè)是環(huán)境的狀態(tài),t時(shí)刻環(huán)境的狀態(tài)
是它的環(huán)境狀態(tài)集中某一個(gè)狀態(tài)。
第二個(gè)是個(gè)體的動作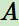 ,t時(shí)刻個(gè)體采取的動作是它的動作集中某一個(gè)動作。
,t時(shí)刻個(gè)體采取的動作是它的動作集中某一個(gè)動作。
第三個(gè)是環(huán)境的獎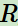 ,t時(shí)刻個(gè)體在狀態(tài)
,t時(shí)刻個(gè)體在狀態(tài)采取的動作
對應(yīng)的獎勵(lì)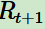 會在t+1時(shí)刻得到。
會在t+1時(shí)刻得到。
下面是稍復(fù)雜一些的模型要素。
第四個(gè)是個(gè)體的策略(policy)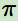 ,它代表個(gè)體采取動作的依據(jù),即個(gè)體會依據(jù)策略來選擇動作。最常見的策略表達(dá)方式是一個(gè)條件概率分布
,它代表個(gè)體采取動作的依據(jù),即個(gè)體會依據(jù)策略來選擇動作。最常見的策略表達(dá)方式是一個(gè)條件概率分布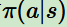 ,即在
,即在時(shí)采取動作
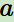 的概率。即
的概率。即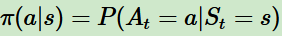 。此時(shí)概率大的動作被個(gè)體選擇的概率較高。
。此時(shí)概率大的動作被個(gè)體選擇的概率較高。
第五個(gè)是個(gè)體在策略和狀時(shí),采取行動后的價(jià)值(value),一般用
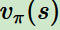 表示。這個(gè)價(jià)值一般是一個(gè)期望函數(shù)。雖然當(dāng)前動作會給一個(gè)延時(shí)獎勵(lì)
表示。這個(gè)價(jià)值一般是一個(gè)期望函數(shù)。雖然當(dāng)前動作會給一個(gè)延時(shí)獎勵(lì)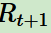 ,但是光看這個(gè)延時(shí)獎勵(lì)是不行的,因?yàn)楫?dāng)前的延時(shí)獎勵(lì)高,不代表到了t+1,t+2,...時(shí)刻的后續(xù)獎勵(lì)也高。比如下象棋,我們可以某個(gè)動作可以吃掉對方的車,這個(gè)延時(shí)獎勵(lì)是很高,但是接著后面我們輸棋了。此時(shí)吃車的動作獎勵(lì)值高但是價(jià)值并不高。因此我們的價(jià)值要綜合考慮當(dāng)前的延時(shí)獎勵(lì)和后續(xù)的延時(shí)獎勵(lì)。價(jià)值函數(shù)一般可以表示為下式,不同的算法會有對應(yīng)的一些價(jià)值函數(shù)變種,但思路相同:
,但是光看這個(gè)延時(shí)獎勵(lì)是不行的,因?yàn)楫?dāng)前的延時(shí)獎勵(lì)高,不代表到了t+1,t+2,...時(shí)刻的后續(xù)獎勵(lì)也高。比如下象棋,我們可以某個(gè)動作可以吃掉對方的車,這個(gè)延時(shí)獎勵(lì)是很高,但是接著后面我們輸棋了。此時(shí)吃車的動作獎勵(lì)值高但是價(jià)值并不高。因此我們的價(jià)值要綜合考慮當(dāng)前的延時(shí)獎勵(lì)和后續(xù)的延時(shí)獎勵(lì)。價(jià)值函數(shù)一般可以表示為下式,不同的算法會有對應(yīng)的一些價(jià)值函數(shù)變種,但思路相同:
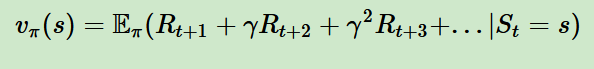
其中是第六個(gè)模型要素,即獎勵(lì)衰減因子,在[0,1]之間。如果為0,則是貪婪法,即價(jià)值只由當(dāng)前延時(shí)獎勵(lì)決定,如果是1,則所有的后續(xù)狀態(tài)獎勵(lì)和當(dāng)前獎勵(lì)一視同仁。大多數(shù)時(shí)候,我們會取一個(gè)0到1之間的數(shù)字,即當(dāng)前延時(shí)獎勵(lì)的權(quán)重比后續(xù)獎勵(lì)的權(quán)重大。
第七個(gè)是環(huán)境的狀態(tài)轉(zhuǎn)化模型,可以理解為一個(gè)概率狀態(tài)機(jī),它可以表示為一個(gè)概率模型,即在狀態(tài)下采取動作
,轉(zhuǎn)到下一個(gè)狀態(tài)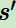 的概率,表示為
的概率,表示為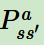 。
。
第八個(gè)是探索率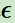 ,這個(gè)比率主要用在強(qiáng)化學(xué)習(xí)訓(xùn)練迭代過程中,由于我們一般會選擇使當(dāng)前輪迭代價(jià)值最大的動作,但是這會導(dǎo)致一些較好的但我們沒有執(zhí)行過的動作被錯(cuò)過。因此我們在訓(xùn)練選擇最優(yōu)動作時(shí),會有一定的概率不選擇使當(dāng)前輪迭代價(jià)值最大的動作,而選擇其他的動作。
,這個(gè)比率主要用在強(qiáng)化學(xué)習(xí)訓(xùn)練迭代過程中,由于我們一般會選擇使當(dāng)前輪迭代價(jià)值最大的動作,但是這會導(dǎo)致一些較好的但我們沒有執(zhí)行過的動作被錯(cuò)過。因此我們在訓(xùn)練選擇最優(yōu)動作時(shí),會有一定的概率不選擇使當(dāng)前輪迭代價(jià)值最大的動作,而選擇其他的動作。
以上8個(gè)就是強(qiáng)化學(xué)習(xí)模型的基本要素了。當(dāng)然,在不同的強(qiáng)化學(xué)習(xí)模型中,會考慮一些其他的模型要素,或者不考慮上述要素的某幾個(gè),但是這8個(gè)是大多數(shù)強(qiáng)化學(xué)習(xí)模型的基本要素。
?
?
這里給出一個(gè)簡單的強(qiáng)化學(xué)習(xí)例子Tic-Tac-Toe。這是一個(gè)簡單的游戲,在一個(gè)3x3的九宮格里,兩個(gè)人輪流下,直到有個(gè)人的棋子滿足三個(gè)一橫一豎或者一斜,贏得比賽游戲結(jié)束,或者九宮格填滿也沒有人贏,則和棋。
這個(gè)例子的完整代碼在我的github(https://github.com/ljpzzz/machinele
arning/blob/master/reinforcement-learning/introduction.py)。例子只有一個(gè)文件,很簡單,代碼首先會用兩個(gè)電腦選手訓(xùn)練模型,然后可以讓人和機(jī)器對戰(zhàn)。當(dāng)然,由于這個(gè)模型很簡單,所以只要你不亂走,最后的結(jié)果都是和棋,當(dāng)然想贏電腦也是不可能的。
我們重點(diǎn)看看這個(gè)例子的模型,理解上面第二節(jié)的部分。如何訓(xùn)練強(qiáng)化學(xué)習(xí)模型可以先不管。代碼部分大家可以自己去看,只有300多行。
首先看第一個(gè)要素環(huán)境的狀態(tài)。這是一個(gè)九宮格,每個(gè)格子有三種狀態(tài),即沒有棋子(取值0),有第一個(gè)選手的棋子(取值1),有第二個(gè)選手的棋子(取值-1)。那么這個(gè)模型的狀態(tài)一共有
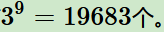
接著我們看個(gè)體的動作,這里只有9個(gè)格子,每次也只能下一步,所以最多只有9個(gè)動作選項(xiàng)。實(shí)際上由于已經(jīng)有棋子的格子是不能再下的,所以動作選項(xiàng)會更少。實(shí)際可以選擇動作的就是那些取值為0的格子。
第三個(gè)是環(huán)境的獎勵(lì),這個(gè)一般是我們自己設(shè)計(jì)。由于我們的目的是贏棋,所以如果某個(gè)動作導(dǎo)致的改變到的狀態(tài)可以使我們贏棋,結(jié)束游戲,那么獎勵(lì)最高,反之則獎勵(lì)最低。其余的雙方下棋動作都有獎勵(lì),但獎勵(lì)較少。特別的,對于先下的棋手,不會導(dǎo)致結(jié)束的動作獎勵(lì)要比后下的棋手少。
# give reward to two playersdef giveReward(self):if self.currentState.winner == self.p1Symbol:self.p1.feedReward(1)self.p2.feedReward(0)elif self.currentState.winner == self.p2Symbol:self.p1.feedReward(0)self.p2.feedReward(1)else:self.p1.feedReward(0.1)self.p2.feedReward(0.5)
第四個(gè)是個(gè)體的策略(policy),這個(gè)一般是學(xué)習(xí)得到的,我們會在每輪以較大的概率選擇當(dāng)前價(jià)值最高的動作,同時(shí)以較小的概率去探索新動作,在這里AI的策略如下面代碼所示。
里面的exploreRate就是我們的第八個(gè)要素探索率。即策略是以1-的概率選擇當(dāng)前最大價(jià)值的動作,以的概率隨機(jī)選擇新動作。
# determine next actiondef takeAction(self):state = self.states[-1]nextStates = []nextPositions = []for i in range(BOARD_ROWS):for j in range(BOARD_COLS):if state.data[i, j] == 0:nextPositions.append([i, j])nextStates.append(state.nextState(i, j, self.symbol).getHash())if np.random.binomial(1, self.exploreRate):np.random.shuffle(nextPositions)# Not sure if truncating is the best way to deal with exploratory step# Maybe it's better to only skip this step rather than forget all the historyself.states = []action = nextPositions[0]action.append(self.symbol)return actionvalues = []for hash, pos in zip(nextStates, nextPositions):values.append((self.estimations[hash], pos))np.random.shuffle(values)values.sort(key=lambda x: x[0], reverse=True)action = values[0][1]action.append(self.symbol)return action
第五個(gè)是價(jià)值函數(shù),代碼里用value表示。價(jià)值函數(shù)的更新代碼里只考慮了當(dāng)前動作的現(xiàn)有價(jià)值和得到的獎勵(lì)兩部分,可以認(rèn)為我們的第六個(gè)模型要素衰減因子為0。具體的代碼部分如下,價(jià)值更新部分的代碼加粗。具體為什么會這樣更新價(jià)值函數(shù)我們以后會講。
# update estimation according to rewarddef feedReward(self, reward):if len(self.states) == 0:returnself.states = [state.getHash() for state in self.states]target = rewardfor latestState in reversed(self.states):value = self.estimations[latestState] + self.stepSize * (target - self.estimations[latestState])self.estimations[latestState] = valuetarget = valueself.states = []
第七個(gè)是環(huán)境的狀態(tài)轉(zhuǎn)化模型, 這里由于每一個(gè)動作后,環(huán)境的下一個(gè)模型狀態(tài)是確定的,也就是九宮格的每個(gè)格子是否有某個(gè)選手的棋子是確定的,因此轉(zhuǎn)化的概率都是1,不存在某個(gè)動作后會以一定的概率到某幾個(gè)新狀態(tài),比較簡單。
從這個(gè)例子,相信大家對于強(qiáng)化學(xué)習(xí)的建模會有一個(gè)初步的認(rèn)識了。
以上就是強(qiáng)化學(xué)習(xí)的模型基礎(chǔ)。
下載1:OpenCV-Contrib擴(kuò)展模塊中文版教程 在「小白學(xué)視覺」公眾號后臺回復(fù):擴(kuò)展模塊中文教程,即可下載全網(wǎng)第一份OpenCV擴(kuò)展模塊教程中文版,涵蓋擴(kuò)展模塊安裝、SFM算法、立體視覺、目標(biāo)跟蹤、生物視覺、超分辨率處理等二十多章內(nèi)容。 下載2:Python視覺實(shí)戰(zhàn)項(xiàng)目52講 在「小白學(xué)視覺」公眾號后臺回復(fù):Python視覺實(shí)戰(zhàn)項(xiàng)目,即可下載包括圖像分割、口罩檢測、車道線檢測、車輛計(jì)數(shù)、添加眼線、車牌識別、字符識別、情緒檢測、文本內(nèi)容提取、面部識別等31個(gè)視覺實(shí)戰(zhàn)項(xiàng)目,助力快速學(xué)校計(jì)算機(jī)視覺。 下載3:OpenCV實(shí)戰(zhàn)項(xiàng)目20講 在「小白學(xué)視覺」公眾號后臺回復(fù):OpenCV實(shí)戰(zhàn)項(xiàng)目20講,即可下載含有20個(gè)基于OpenCV實(shí)現(xiàn)20個(gè)實(shí)戰(zhàn)項(xiàng)目,實(shí)現(xiàn)OpenCV學(xué)習(xí)進(jìn)階。 交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動駕駛、計(jì)算攝影、檢測、分割、識別、醫(yī)學(xué)影像、GAN、算法競賽等微信群(以后會逐漸細(xì)分),請掃描下面微信號加群,備注:”昵稱+學(xué)校/公司+研究方向“,例如:”張三?+?上海交大?+?視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會根據(jù)研究方向邀請進(jìn)入相關(guān)微信群。請勿在群內(nèi)發(fā)送廣告,否則會請出群,謝謝理解~