
在Go中如何正確重試請(qǐng)求?

導(dǎo)語(yǔ) | 我們平時(shí)在開(kāi)發(fā)中肯定避不開(kāi)的一個(gè)問(wèn)題是如何在不可靠的網(wǎng)絡(luò)服務(wù)中實(shí)現(xiàn)可靠的網(wǎng)絡(luò)通信,其中http請(qǐng)求重試是經(jīng)常用的技術(shù)。但是Go標(biāo)準(zhǔn)庫(kù)net/http 實(shí)際上是沒(méi)有重試這個(gè)功能的,所以本篇文章主要講解如何在Go中實(shí)現(xiàn)請(qǐng)求重試。
一、概述
要理解cpo機(jī)制的產(chǎn)生和使用,并不是一件容易的事。說(shuō)實(shí)話(huà),筆者第一次看到這個(gè)機(jī)制。
一般而言,對(duì)于網(wǎng)絡(luò)通信失敗的處理分為以下幾步:
感知錯(cuò)誤。通過(guò)不同的錯(cuò)誤碼來(lái)識(shí)別不同的錯(cuò)誤,在HTTP中status code可以用來(lái)識(shí)別不同類(lèi)型的錯(cuò)誤;
重試決策。這一步主要用來(lái)減少不必要的重試,比如HTTP的4xx的錯(cuò)誤,通常4xx表示的是客戶(hù)端的錯(cuò)誤,這時(shí)候客戶(hù)端不應(yīng)該進(jìn)行重試操作,或者在業(yè)務(wù)中自定義的一些錯(cuò)誤也不應(yīng)該被重試。根據(jù)這些規(guī)則的判斷可以有效的減少不必要的重試次數(shù),提升響應(yīng)速度;
重試策略。重試策略就包含了重試間隔時(shí)間,重試次數(shù)等。如果次數(shù)不夠,可能并不能有效的覆蓋這個(gè)短時(shí)間故障的時(shí)間段,如果重試次數(shù)過(guò)多,或者重試間隔太小,又可能造成大量的資源(CPU、內(nèi)存、線(xiàn)程、網(wǎng)絡(luò))浪費(fèi)。這個(gè)我們后面再說(shuō);
對(duì)沖策略。對(duì)沖是指在不等待響應(yīng)的情況主動(dòng)發(fā)送單次調(diào)用的多個(gè)請(qǐng)求,然后取首個(gè)返回的回包。這個(gè)概念是grpc中的概念,我把它也借用過(guò)來(lái);
熔斷降級(jí)。如果重試之后還是不行,說(shuō)明這個(gè)故障不是短時(shí)間的故障,而是長(zhǎng)時(shí)間的故障。那么可以對(duì)服務(wù)進(jìn)行熔斷降級(jí),后面的請(qǐng)求不再重試,這段時(shí)間做降級(jí)處理,減少?zèng)]必要的請(qǐng)求,等服務(wù)端恢復(fù)了之后再進(jìn)行請(qǐng)求,這方面的實(shí)現(xiàn)很多go-zero、sentinel、hystrix-go,也蠻有意思的;
二、重試策略
重試策略可以分為很多種,一方面要考慮到本次請(qǐng)求時(shí)長(zhǎng)過(guò)長(zhǎng)而影響到的業(yè)務(wù)忍受度,另一方面要考慮到重試會(huì)對(duì)下游服務(wù)產(chǎn)生過(guò)多的請(qǐng)求而帶來(lái)的影響,總之就是一個(gè)trade-off的問(wèn)題。
所以對(duì)于重試算法,一般是在重試之間加一個(gè)gap時(shí)間,感興趣的朋友也可以去看看這篇文章(https://aws.amazon.com/cn/blogs/architecture/exponential-backoff-and-jitter/)。結(jié)合我們自己平時(shí)的實(shí)踐加上這篇文章的算法一般可以總結(jié)出以下幾條規(guī)則:
線(xiàn)性間隔(Linear Backoff):每次重試間隔時(shí)間是固定的進(jìn)行重試,如每1s重試一次;
線(xiàn)性間隔+隨機(jī)時(shí)間(Linear Jitter Backoff):有時(shí)候每次重試間隔時(shí)間一致可能會(huì)導(dǎo)致多個(gè)請(qǐng)求在同一時(shí)間請(qǐng)求,那么我們可以加入一個(gè)隨機(jī)時(shí)間,在線(xiàn)性間隔時(shí)間的基礎(chǔ)上波動(dòng)一個(gè)百分比的時(shí)間;
指數(shù)間隔(Exponential Backoff):每次間隔時(shí)間是2指數(shù)型的遞增,如等3s 9s 27s后重試;
指數(shù)間隔+隨機(jī)時(shí)間(Exponential Jitter Backoff):這個(gè)就和第二個(gè)類(lèi)似了,在指數(shù)遞增的基礎(chǔ)上添加一個(gè)波動(dòng)時(shí)間;
上面有兩種策略都加入了擾動(dòng)(jitter),目的是防止驚群?jiǎn)栴} (Thundering Herd Problem)的發(fā)生。
所謂驚群?jiǎn)栴}當(dāng)許多進(jìn)程都在等待被同一事件喚醒的時(shí)候,當(dāng)事件發(fā)生后最后只有一個(gè)進(jìn)程能獲得處理。其余進(jìn)程又造成阻塞,這會(huì)造成上下文切換的浪費(fèi)。所以加入一個(gè)隨機(jī)時(shí)間來(lái)避免同一時(shí)間同時(shí)請(qǐng)求服務(wù)端還是很有必要的。
使用net/http重試所帶來(lái)的問(wèn)題
重試這個(gè)操作其實(shí)對(duì)于Go來(lái)說(shuō)其實(shí)還不能直接加一個(gè)for循環(huán)根據(jù)次數(shù)來(lái)進(jìn)行,對(duì)于Get請(qǐng)求重試的時(shí)候沒(méi)有請(qǐng)求體,可以直接進(jìn)行重試,但是對(duì)于Post請(qǐng)求來(lái)說(shuō)需要把請(qǐng)求體放到Reader里面,如下:
req, _ := http.NewRequest("POST", "localhost", strings.NewReader("hello"))服務(wù)端收到請(qǐng)求之后就會(huì)從這個(gè)Reader中調(diào)用Read()函數(shù)去讀取數(shù)據(jù),通常情況當(dāng)服務(wù)端去讀取數(shù)據(jù)的時(shí)候,offset會(huì)隨之改變,下一次再讀的時(shí)候會(huì)從offset位置繼續(xù)向后讀取。所以如果直接重試,會(huì)出現(xiàn)讀不到 Reader的情況。
我們可以先弄一個(gè)例子:
func main() {go func() {http.HandleFunc("/", http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {time.Sleep(time.Millisecond * 20)body, _ := ioutil.ReadAll(r.Body)fmt.Printf("received body with length %v containing: %v\n", len(body), string(body))w.WriteHeader(http.StatusOK)}))http.ListenAndServe(":8090", nil)}()fmt.Print("Try with bare strings.Reader\n")retryDo(req)}func retryDo() {originalBody := []byte("abcdefghigklmnopqrst")reader := strings.NewReader(string(originalBody))req, _ := http.NewRequest("POST", "http://localhost:8090/", reader)client := http.Client{Timeout: time.Millisecond * 10,}for {_, err := client.Do(req)if err != nil {fmt.Printf("error sending the first time: %v\n", err)}time.Sleep(1000)}}// output:error sending the first time: Post "http://localhost:8090/": context deadline exceeded (Client.Timeout exceeded while awaiting headers)error sending the first time: Post "http://localhost:8090/": http: ContentLength=20 with Body length 0error sending the first time: Post "http://localhost:8090/": http: ContentLength=20 with Body length 0received body with length 20 containing: abcdefghigklmnopqrsterror sending the first time: Post "http://localhost:8090/": http: ContentLength=20 with Body length 0....
在上面這個(gè)例子中,在客戶(hù)端設(shè)值了10ms的超時(shí)時(shí)間。在服務(wù)端模擬請(qǐng)求處理超時(shí)情況,先sleep 20ms,然后再讀請(qǐng)求數(shù)據(jù),這樣必然會(huì)超時(shí)。
當(dāng)再次請(qǐng)求的時(shí)候,發(fā)現(xiàn)client請(qǐng)求的Body數(shù)據(jù)并不是我們預(yù)期的20個(gè)長(zhǎng)度,而是0,導(dǎo)致了err。因此需要將Body這個(gè)Reader進(jìn)行重置,如下:
func resetBody(request *http.Request, originalBody []byte) {request.Body = io.NopCloser(bytes.NewBuffer(originalBody))request.GetBody = func() (io.ReadCloser, error) {return io.NopCloser(bytes.NewBuffer(originalBody)), nil}}
上面這段代碼中,我們使用io.NopCloser對(duì)請(qǐng)求的Body數(shù)據(jù)進(jìn)行了重置,避免下次請(qǐng)求的時(shí)候出現(xiàn)非預(yù)期的異常。
那么相對(duì)于上面簡(jiǎn)陋的例子,還可以完善一下,加上我們上面說(shuō)的StatusCode重試判斷、重試策略、重試次數(shù)等等,可以寫(xiě)成這樣:
func retryDo(req *http.Request, maxRetries int, timeout time.Duration,backoffStrategy BackoffStrategy) (*http.Response, error) {var (originalBody []byteerr error)if req != nil && req.Body != nil {originalBody, err = copyBody(req.Body)resetBody(req, originalBody)}if err != nil {return nil, err}AttemptLimit := maxRetriesif AttemptLimit <= 0 {AttemptLimit = 1}client := http.Client{Timeout: timeout,}var resp *http.Response//重試次數(shù)for i := 1; i <= AttemptLimit; i++ {resp, err = client.Do(req)if err != nil {fmt.Printf("error sending the first time: %v\n", err)}// 重試 500 以上的錯(cuò)誤碼if err == nil && resp.StatusCode < 500 {return resp, err}// 如果正在重試,那么釋放fdif resp != nil {resp.Body.Close()}// 重置bodyif req.Body != nil {resetBody(req, originalBody)}time.Sleep(backoffStrategy(i) + 1*time.Microsecond)}// 到這里,說(shuō)明重試也沒(méi)用return resp, req.Context().Err()}func copyBody(src io.ReadCloser) ([]byte, error) {b, err := ioutil.ReadAll(src)if err != nil {return nil, ErrReadingRequestBody}src.Close()return b, nil}func resetBody(request *http.Request, originalBody []byte) {request.Body = io.NopCloser(bytes.NewBuffer(originalBody))request.GetBody = func() (io.ReadCloser, error) {return io.NopCloser(bytes.NewBuffer(originalBody)), nil}}
三、對(duì)沖策略
上面講的是重試的概念,那么有時(shí)候我們接口只是偶然會(huì)出問(wèn)題,并且我們的下游服務(wù)并不在乎多請(qǐng)求幾次,那么我們可以借用grpc里面的概念:對(duì)沖策略(Hedged requests)。
對(duì)沖是指在不等待響應(yīng)的情況主動(dòng)發(fā)送單次調(diào)用的多個(gè)請(qǐng)求,然后取首個(gè)返回的回包。對(duì)沖和重試的區(qū)別點(diǎn)主要在:對(duì)沖在超過(guò)指定時(shí)間沒(méi)有響應(yīng)就會(huì)直接發(fā)起請(qǐng)求,而重試則必須要服務(wù)端響應(yīng)后才會(huì)發(fā)起請(qǐng)求。所以對(duì)沖更像是比較激進(jìn)的重試策略。
使用對(duì)沖的時(shí)候需要注意一點(diǎn)是,因?yàn)橄掠畏?wù)可能會(huì)做負(fù)載均衡策略,所以要求請(qǐng)求的下游服務(wù)一般是要求冪等的,能夠在多次并發(fā)請(qǐng)求中是安全的,并且是符合預(yù)期的。
對(duì)沖請(qǐng)求一般是用來(lái)處理“長(zhǎng)尾”請(qǐng)求的,關(guān)于”長(zhǎng)尾“請(qǐng)求的概念可以看這篇文章:https://segmentfault.com/a/1190000039978117
四、并發(fā)模式的處理
因?yàn)閷?duì)沖重試加上了并發(fā)的概念,要用到goroutine來(lái)并發(fā)請(qǐng)求,所以我們可以把數(shù)據(jù)封裝到channel里面來(lái)進(jìn)行消息的異步處理。
并且由于是多個(gè)goroutine處理消息,我們需要在每個(gè)goroutine處理完畢,但是都失敗的情況下返回err,不能直接由于channel等待卡住主流程,這一點(diǎn)十分重要。
但是由于在Go中是無(wú)法獲取每個(gè)goroutine的執(zhí)行結(jié)果的,我們又只關(guān)注正確處理結(jié)果,需要忽略錯(cuò)誤,所以需要配合WaitGroup來(lái)實(shí)現(xiàn)流程控制,示例如下:
func main() {totalSentRequests := &sync.WaitGroup{}allRequestsBackCh := make(chan struct{})multiplexCh := make(chan struct {result stringretry int})go func() {//所有請(qǐng)求完成之后會(huì)close掉allRequestsBackChtotalSentRequests.Wait()close(allRequestsBackCh)}()for i := 1; i <= 10; i++ {totalSentRequests.Add(1)go func() {// 標(biāo)記已經(jīng)執(zhí)行完defer totalSentRequests.Done()// 模擬耗時(shí)操作time.Sleep(500 * time.Microsecond)// 模擬處理成功if random.Intn(500)%2 == 0 {multiplexCh <- struct {result stringretry int}{"finsh success", i}}// 處理失敗不關(guān)心,當(dāng)然,也可以加入一個(gè)錯(cuò)誤的channel中進(jìn)一步處理}()}select {case <-multiplexCh:fmt.Println("finish success")case <-allRequestsBackCh:// 到這里,說(shuō)明全部的 goroutine 都執(zhí)行完畢,但是都請(qǐng)求失敗了fmt.Println("all req finish,but all fail")}}
從上面這段代碼看為了進(jìn)行流程控制,多用了兩個(gè)channel:totalSentRequests、allRequestsBackCh,多用了一個(gè)goroutine異步關(guān)停allRequestsBackCh,才實(shí)現(xiàn)的流程控制,實(shí)在太過(guò)于麻煩,有新的實(shí)現(xiàn)方案的同學(xué)不妨和我探討一下。
除了上面的并發(fā)請(qǐng)求控制的問(wèn)題,對(duì)于對(duì)沖重試來(lái)說(shuō),還需要注意的是,由于請(qǐng)求不是串行的,所以http.Request的上下文會(huì)變,所以每次請(qǐng)求前需要clone一次context,保證每個(gè)不同請(qǐng)求的context是獨(dú)立的。但是每次clone之后Reader的offset位置又變了,所以我們還需要進(jìn)行重新reset:
func main() {req, _ := http.NewRequest("POST", "localhost", strings.NewReader("hello"))req2 := req.Clone(req.Context())contents, _ := io.ReadAll(req.Body)contents2, _ := io.ReadAll(req2.Body)fmt.Printf("First read: %v\n", string(contents))fmt.Printf("Second read: %v\n", string(contents2))}//output:First read: helloSecond read:
所以結(jié)合一下上面的例子,我們可以將對(duì)沖重試的代碼變?yōu)椋?/span>
func retryHedged(req *http.Request, maxRetries int, timeout time.Duration,backoffStrategy BackoffStrategy) (*http.Response, error) {var (originalBody []byteerr error)if req != nil && req.Body != nil {originalBody, err = copyBody(req.Body)}if err != nil {return nil, err}AttemptLimit := maxRetriesif AttemptLimit <= 0 {AttemptLimit = 1}client := http.Client{Timeout: timeout,}// 每次請(qǐng)求copy新的requestcopyRequest := func() (request *http.Request) {request = req.Clone(req.Context())if request.Body != nil {resetBody(request, originalBody)}return}multiplexCh := make(chan struct {resp *http.Responseerr errorretry int})totalSentRequests := &sync.WaitGroup{}allRequestsBackCh := make(chan struct{})go func() {totalSentRequests.Wait()close(allRequestsBackCh)}()var resp *http.Responsefor i := 1; i <= AttemptLimit; i++ {totalSentRequests.Add(1)go func() {// 標(biāo)記已經(jīng)執(zhí)行完defer totalSentRequests.Done()req = copyRequest()resp, err = client.Do(req)if err != nil {fmt.Printf("error sending the first time: %v\n", err)}// 重試 500 以上的錯(cuò)誤碼if err == nil && resp.StatusCode < 500 {multiplexCh <- struct {resp *http.Responseerr errorretry int}{resp: resp, err: err, retry: i}return}// 如果正在重試,那么釋放fdif resp != nil {resp.Body.Close()}// 重置bodyif req.Body != nil {resetBody(req, originalBody)}time.Sleep(backoffStrategy(i) + 1*time.Microsecond)}()}select {case res := <-multiplexCh:return res.resp, res.errcase <-allRequestsBackCh:// 到這里,說(shuō)明全部的 goroutine 都執(zhí)行完畢,但是都請(qǐng)求失敗了return nil, errors.New("all req finish,but all fail")}}
五、熔斷&降級(jí)
因?yàn)樵谖覀兪褂胔ttp調(diào)用的時(shí)候,調(diào)用的外部服務(wù)很多時(shí)候其實(shí)并不可靠,很有可能因?yàn)橥獠康姆?wù)問(wèn)題導(dǎo)致自身服務(wù)接口調(diào)用等待,從而調(diào)用時(shí)間過(guò)長(zhǎng),產(chǎn)生大量的調(diào)用積壓,慢慢耗盡服務(wù)資源,最終導(dǎo)致服務(wù)調(diào)用雪崩的發(fā)生,所以在服務(wù)中使用熔斷降級(jí)是非常有必要的一件事。
其實(shí)熔斷降級(jí)的概念總體上來(lái)說(shuō),實(shí)現(xiàn)都差不多。核心思想就是通過(guò)全局的計(jì)數(shù)器,用來(lái)統(tǒng)計(jì)調(diào)用次數(shù)、成功/失敗次數(shù)。通過(guò)統(tǒng)計(jì)的計(jì)數(shù)器來(lái)判斷熔斷器的開(kāi)關(guān),熔斷器的狀態(tài)由三種狀態(tài)表示:closed、open、half open,下面借用了sentinel的圖來(lái)表示三者的關(guān)系:
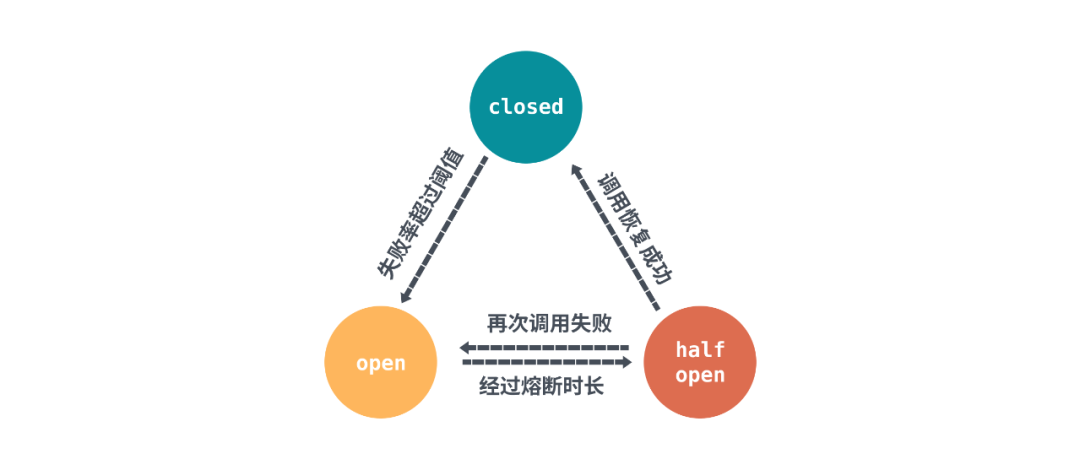
首先初始狀態(tài)是closed,每次調(diào)用都會(huì)經(jīng)過(guò)計(jì)數(shù)器統(tǒng)計(jì)總次數(shù)和成功/失敗次數(shù),然后在達(dá)到一定閾值或條件之后熔斷器會(huì)切換到open狀態(tài),發(fā)起的請(qǐng)求會(huì)被拒絕。
熔斷器規(guī)則中會(huì)配置一個(gè)熔斷超時(shí)重試的時(shí)間,經(jīng)過(guò)熔斷超時(shí)重試時(shí)長(zhǎng)后熔斷器會(huì)將狀態(tài)置為half-open狀態(tài)。這個(gè)狀態(tài)對(duì)于sentinel來(lái)說(shuō)會(huì)發(fā)起定時(shí)探測(cè),對(duì)于go-zero來(lái)說(shuō)會(huì)允許通過(guò)一定比例的請(qǐng)求,不管是主動(dòng)定時(shí)探測(cè),還是被動(dòng)通過(guò)的請(qǐng)求調(diào)用,只要請(qǐng)求的結(jié)果返回正常,那么就需要重置計(jì)數(shù)器恢復(fù)到closed狀態(tài)。
一般而言會(huì)支持兩種熔斷策略:
錯(cuò)誤比率:熔斷時(shí)間窗口內(nèi)的請(qǐng)求數(shù)閾值錯(cuò)誤率大于錯(cuò)誤率閾值,從而觸發(fā)熔斷。
平均RT(響應(yīng)時(shí)間):熔斷時(shí)間窗口內(nèi)的請(qǐng)求數(shù)閾值大于平均 RT 閾值,從而觸發(fā)熔斷。
比如我們使用hystrix-go來(lái)處理我們的服務(wù)接口的熔斷,可以結(jié)合我們上面說(shuō)的重試從而進(jìn)一步保障我們的服務(wù)。
hystrix.ConfigureCommand("my_service", hystrix.CommandConfig{ErrorPercentThreshold: 30,})_ = hystrix.Do("my_service", func() error {req, _ := http.NewRequest("POST", "http://localhost:8090/", strings.NewReader("test"))_, err := retryDo(req, 5, 20*time.Millisecond, ExponentialBackoff)if err != nil {fmt.Println("get error:%v",err)return err}return nil}, func(err error) error {fmt.Printf("handle error:%v\n", err)return nil})
上面這個(gè)例子中就利用hystrix-go設(shè)置了最大錯(cuò)誤百分比等于30,超過(guò)這個(gè)閾值就會(huì)進(jìn)行熔斷。
總結(jié)
這篇文章從接口調(diào)用出發(fā),探究了重試的幾個(gè)要點(diǎn),講解了重試的幾種策略;然后在實(shí)踐環(huán)節(jié)中講解了直接使用net/http重試會(huì)有什么問(wèn)題,對(duì)于對(duì)沖策略使用channel加上waitgroup來(lái)實(shí)現(xiàn)并發(fā)請(qǐng)求控制;最后使用hystrix-go來(lái)對(duì)故障服務(wù)進(jìn)行熔斷,防止請(qǐng)求堆積引起資源耗盡的問(wèn)題。
參考資料:
1.從gRPC的重試策略說(shuō)起
2.Go HTTP如何正確重試
3.熔斷原理與實(shí)現(xiàn)
4.處理過(guò)載
5.Google怎么解決長(zhǎng)尾延遲問(wèn)題
作者簡(jiǎn)介

羅志赟
騰訊后臺(tái)開(kāi)發(fā)工程師
騰訊后臺(tái)開(kāi)發(fā)工程師,深入研究過(guò)Go runtime相關(guān)代碼,喜歡專(zhuān)研技術(shù)細(xì)節(jié),探索技術(shù)中有趣的實(shí)現(xiàn)分享給大家。
推薦閱讀
萬(wàn)卷共知,一書(shū)一頁(yè)總關(guān)情,TVP讀書(shū)會(huì)帶你突圍閱讀迷障!
小白入門(mén)級(jí)!webpack基礎(chǔ)、分包大揭秘
