
你的感知損失可能用錯了,沈春華團(tuán)隊提出隨機權(quán)值廣義感知損失

極市導(dǎo)讀
本文介紹了阿德萊德沈春華老師團(tuán)隊的工作,文章揭示了感知損失最關(guān)鍵的是其網(wǎng)絡(luò)結(jié)構(gòu)而非其預(yù)訓(xùn)練權(quán)重,并證實:基于隨機權(quán)值的CNN可被用于建模輸出的結(jié)構(gòu)化依賴性。 >>本周六,極市CVPR2021線下沙龍即將舉辦,三位CVPR2021論文作者齊聚深圳!【報告三:戴志港-UP-DETR:針對目標(biāo)檢測的無監(jiān)督預(yù)訓(xùn)練transformer】。點擊藍(lán)字即可免費報名,名額有限,先到先得!

本文是阿德萊德沈春華老師團(tuán)隊在“感知損失對于結(jié)構(gòu)化輸出依賴性建模影響”方面的一次有意思的探索之旅。從圖像生成任務(wù)中的感知損失影響出發(fā),揭示了感知損失的成功關(guān)鍵在于網(wǎng)絡(luò)結(jié)構(gòu)而非預(yù)訓(xùn)練權(quán)值;在此基礎(chǔ)上,將其進(jìn)一步擴展到更廣義的稠密預(yù)測任務(wù)(比如語義分割、實例分割等)上,并通過實驗驗證了所提廣義感知損失的有效性;甚至,當(dāng)單階段目標(biāo)檢測器配上Mask翅膀上,該損失還可以進(jìn)一步提升目標(biāo)檢測的性能。原文鏈接:https://arxiv.org/abs/2103.10571
Abstract
感知損失作為一種有效損失已被廣泛應(yīng)用在圖像生成類任務(wù)中,比如圖像超分、風(fēng)格遷移等,感知損失的成功往往被歸因于預(yù)訓(xùn)練模型能夠提取圖像的高級感知特征。在這篇文章中,我們揭示了感知損失最關(guān)鍵的是其網(wǎng)絡(luò)結(jié)構(gòu)而非其預(yù)訓(xùn)練權(quán)重。無需任何學(xué)習(xí),深度網(wǎng)絡(luò)的結(jié)構(gòu)足以捕獲多層CNN所提取的多級統(tǒng)計信息之間的相關(guān)性。該發(fā)現(xiàn)移除了預(yù)訓(xùn)練與特定網(wǎng)絡(luò)架構(gòu)(通常為VGG)假設(shè),因而引發(fā)了更廣泛的應(yīng)用。我們證實:基于隨機權(quán)值的CNN可被用于建模輸出的結(jié)構(gòu)化依賴性。在多個稠密預(yù)測任務(wù)(比如語義分割、深度估計、實例分割)上,相比僅僅采用像素?fù)p失,采用擴展的隨機感知損失可以進(jìn)一步提升模型的性能。我們期望這種簡單的、擴展感知損失可以作為一種廣義結(jié)構(gòu)輸出損失用于結(jié)構(gòu)輸出學(xué)習(xí)任務(wù)中。本文的主要貢獻(xiàn)包含以下幾點:
證實感知損失的成功并非源于預(yù)訓(xùn)練權(quán)值,而是源于CNN結(jié)構(gòu); 將所提廣義感知損失應(yīng)用到多個結(jié)構(gòu)化輸出任務(wù)上可以看到顯著性能提升; 探索了初始化與網(wǎng)絡(luò)結(jié)構(gòu)是如何影響所提感知損失的性能; 所提感知損失可以作為一種廣義結(jié)構(gòu)化輸出損失應(yīng)用到大部分結(jié)構(gòu)化輸出學(xué)習(xí)任務(wù)中。
Introduction
在之前的研究中,感知損失往往采用在ImageNet上預(yù)訓(xùn)練的模型提取圖像的高級感知特征然后再計算損失,稱之為感知損失。基于該假設(shè),感知損失往往采用預(yù)訓(xùn)練VGG16/VGG19計算。
我們發(fā)現(xiàn):不同于前述假設(shè),感知損失的成功并非預(yù)訓(xùn)練模型而是多層CNN結(jié)構(gòu),它足大量輸出的交互統(tǒng)計信息。為驗證該結(jié)論,我們在圖像超分任務(wù)上進(jìn)行了一個簡單的實驗,結(jié)果見下圖。

從上圖可以看到:相比簡單的像素?fù)p失,預(yù)訓(xùn)練VGG與隨機權(quán)重VGG均取得了顯著的視覺效果提升,且兩者視覺效果相當(dāng)。這就意味著:預(yù)訓(xùn)練權(quán)值并非感知損失成功的關(guān)鍵。
Method
前述實驗結(jié)果表明:感知損失成功的關(guān)鍵是網(wǎng)絡(luò)結(jié)構(gòu)而非預(yù)訓(xùn)練權(quán)重。接下來,我們將對感知損失進(jìn)行擴展以適用到更多結(jié)構(gòu)化輸出學(xué)習(xí)任務(wù);然后我們深入分析了權(quán)值初始化的影響并設(shè)計了一種近似方案用于有效初始化。
Generic Perception Loss
如果隨機權(quán)值模型有助于捕獲結(jié)構(gòu)化信息,那么它同樣對于稠密預(yù)測問題有效,由于不需要預(yù)訓(xùn)練權(quán)值,可以輕易的將其作為正則項用于任意任務(wù)并比較不同感知損失網(wǎng)絡(luò)的性能。我們采用常規(guī)VGG網(wǎng)絡(luò)作為出發(fā)點,采用表示最大值池化之間的卷積數(shù)量。
Semantic Segmentation。為將感知損失擴展到語義分割任務(wù)中,我們采用估計的分割圖或者真值作為感知損失網(wǎng)絡(luò)的輸入,可以得到由CNN提取到的嵌入結(jié)構(gòu)化特征,最后采用MSE最小化兩者之間的距離。由于softmax輸出與one-hot真值之間的域差異使得感知損失難以收斂。為解決該問題,我們參考《Structured Knowledge Distillation》采用大的老師網(wǎng)絡(luò)生成軟標(biāo)簽作為學(xué)習(xí)目標(biāo),此時整體損失函數(shù)定義如下:
Depth Estimation。深度估計是一種回歸問題,它用來圖像中每個像素對應(yīng)的目標(biāo)與camera的距離,網(wǎng)絡(luò)將輸出一個深度圖像。由于真值與預(yù)測圖像具有相同的統(tǒng)計分布,因此它們可以直接作為感知損失網(wǎng)絡(luò)的輸入。 Instance Segmentation。實例分割是最具挑戰(zhàn)的CV任務(wù)之一,它需要精確的預(yù)測每個像素對應(yīng)的目標(biāo)和語義信息。它采用了與語義分割類似的方式,將老師網(wǎng)絡(luò)生成的軟標(biāo)簽作為學(xué)習(xí)目標(biāo)并送入感知損失網(wǎng)絡(luò)中。
Devils in the Initialization
隨機權(quán)值網(wǎng)絡(luò)的初始化方式會影響廣義感知損失的性能。由于我們采用結(jié)構(gòu)化預(yù)測作為感知損失的輸入并生成一個嵌入向量,不合理的初始化可能導(dǎo)致不穩(wěn)定的結(jié)果。因此很有必要確保每一層的Lipschitiz接近1,因而確保了隨機網(wǎng)絡(luò)的梯度不會爆炸或者消失。我們對隨機網(wǎng)絡(luò)的梯度尺度進(jìn)行了探索并得出一種魯邦初始化方法。對于稠密預(yù)測任務(wù)來首,我們有預(yù)測結(jié)果與真值/軟標(biāo)簽,隨機權(quán)值感知損失網(wǎng)絡(luò)會將兩者變換到嵌入空間。那么廣義感知損失定義如下:假設(shè)對應(yīng)了卷積核的響應(yīng)激活值,此時有:基于深度卷及網(wǎng)絡(luò),此時有,其中表示ReLU激活函數(shù)。如果我們采用零附近的對稱分布對權(quán)值進(jìn)行初始化,且,此時均具有零均值且對稱分布。此時嵌入層的方差如下:
當(dāng)L無限大時,就會導(dǎo)致爆炸或者消失。因此,我們采用標(biāo)準(zhǔn)差為的零均值高斯分布進(jìn)行初始化。在優(yōu)化開始時,之間的相關(guān)性很小;隨著訓(xùn)練的進(jìn)行,會朝著Y進(jìn)行優(yōu)化,兩者之間的協(xié)方差朝著1進(jìn)行優(yōu)化,兩者之間的嵌入距離則朝著0優(yōu)化。
Experiments
我們先對感知損失的幾個感興趣問題進(jìn)行探索;然后采用一種有效的結(jié)構(gòu)作為感知損失并說明其在稠密預(yù)測任務(wù)上的性能提升。
Discussions
關(guān)于感知損失,有這樣幾個有意思的問題:
Will the trained filters help the perceptual loss in dense prediction problems? How does the depth/receptive filed/multi-scale losses affect the performance? How does the initializaton affect the performance?
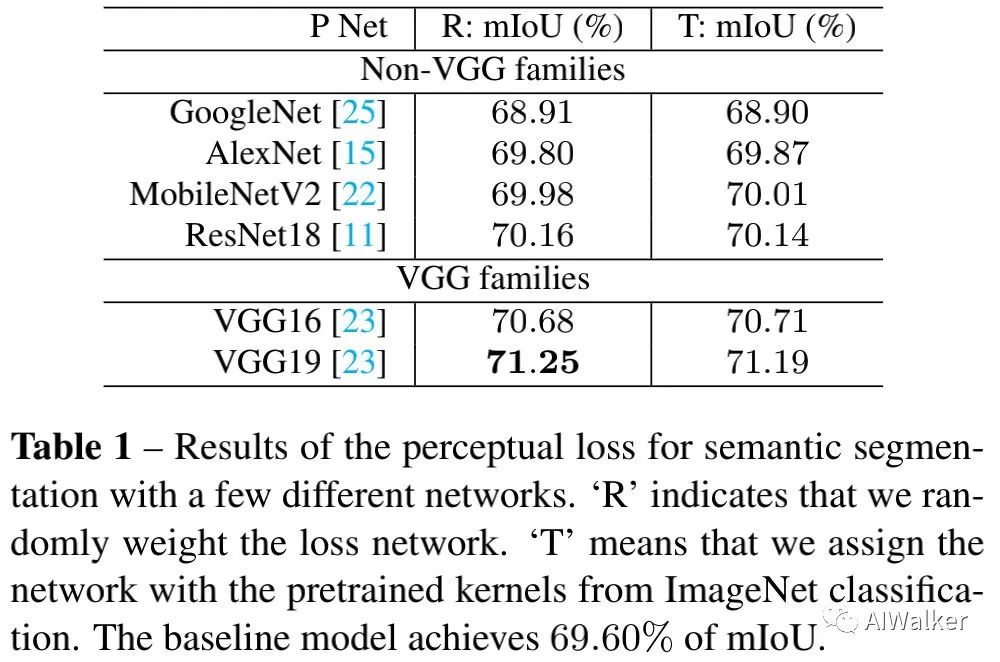
為說明第一個問題,我們基于語義分割任務(wù)做了一個簡單的實驗,結(jié)果見上表。從上表數(shù)據(jù)與對比可以看到:
隨機權(quán)值與預(yù)訓(xùn)練權(quán)值在性能上幾乎沒有差異(差異范圍在0.02%~0.06%之間);但是不同結(jié)構(gòu)之間的差異非常大(從68.9%~71.25%)。這意味著:對于結(jié)構(gòu)化輸出學(xué)習(xí)任務(wù)來說,ImageNet上的預(yù)訓(xùn)練權(quán)值并非感知損失成功的關(guān)鍵,相反,網(wǎng)絡(luò)結(jié)構(gòu)才是其中關(guān)鍵因素。 VGG類架構(gòu)明顯優(yōu)于其他結(jié)構(gòu)。已有研究同樣表明:在風(fēng)格遷移任務(wù)上,VGG結(jié)構(gòu)的效果要優(yōu)化ResNet并解釋了VGG要比ResNet更為魯棒。
為回答第二個問題,我們設(shè)計了一系列實驗,包含不同深度、不同卷積核的VGG網(wǎng)絡(luò)結(jié)構(gòu)。結(jié)果見下表,可以看到:(1)預(yù)訓(xùn)練核不會帶來性能提升,相反網(wǎng)絡(luò)結(jié)構(gòu)影響很大;(2)VGG19為其中最佳感知損失函數(shù);(3)考慮到有效性與高效性,1,1,1,1,1組合會是最佳選擇。
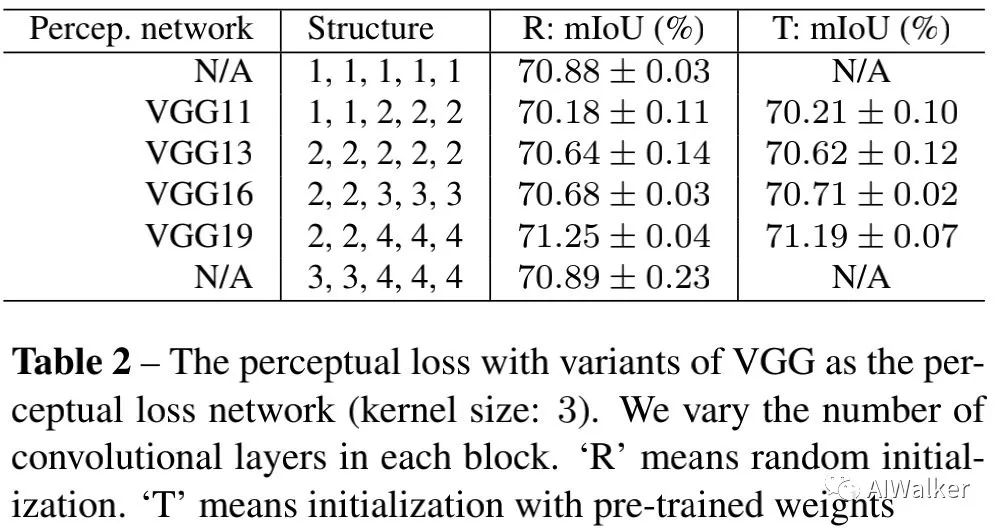
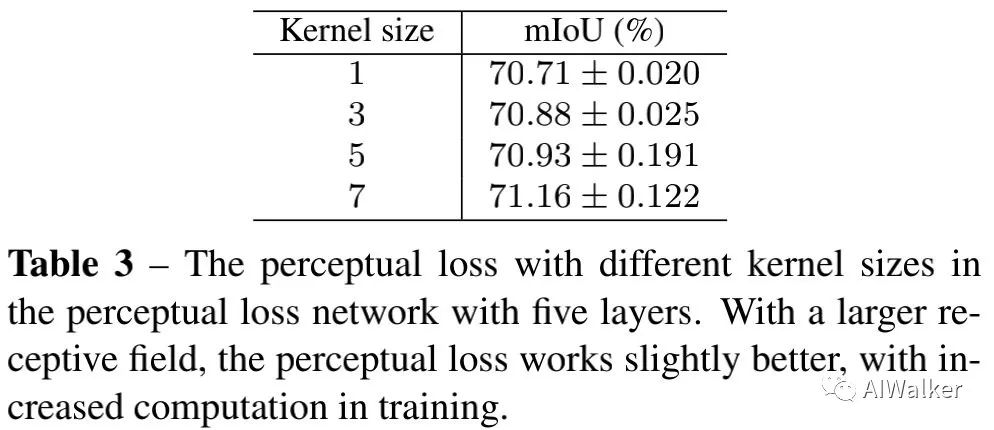
與此同時,我們還給出了感受野的影響性分析,見下表。更大的核尺寸可以帶來稍好的性能(從70.71%提升到71.16%)。
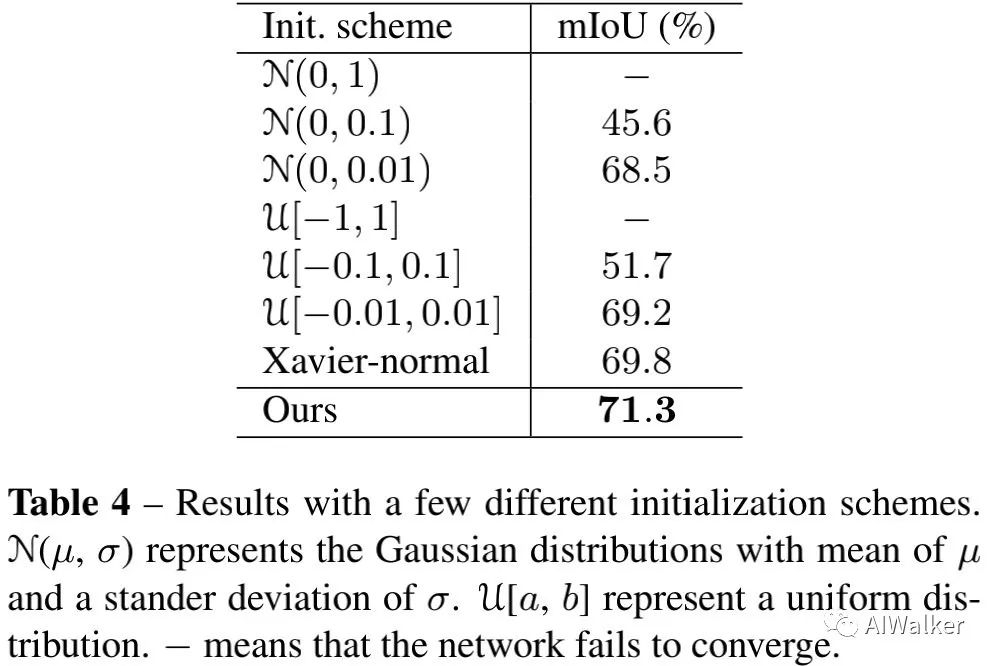
為回答最后一個問題,我們采用不同的初始化方法進(jìn)行了對比分析,結(jié)果見下表。
Application
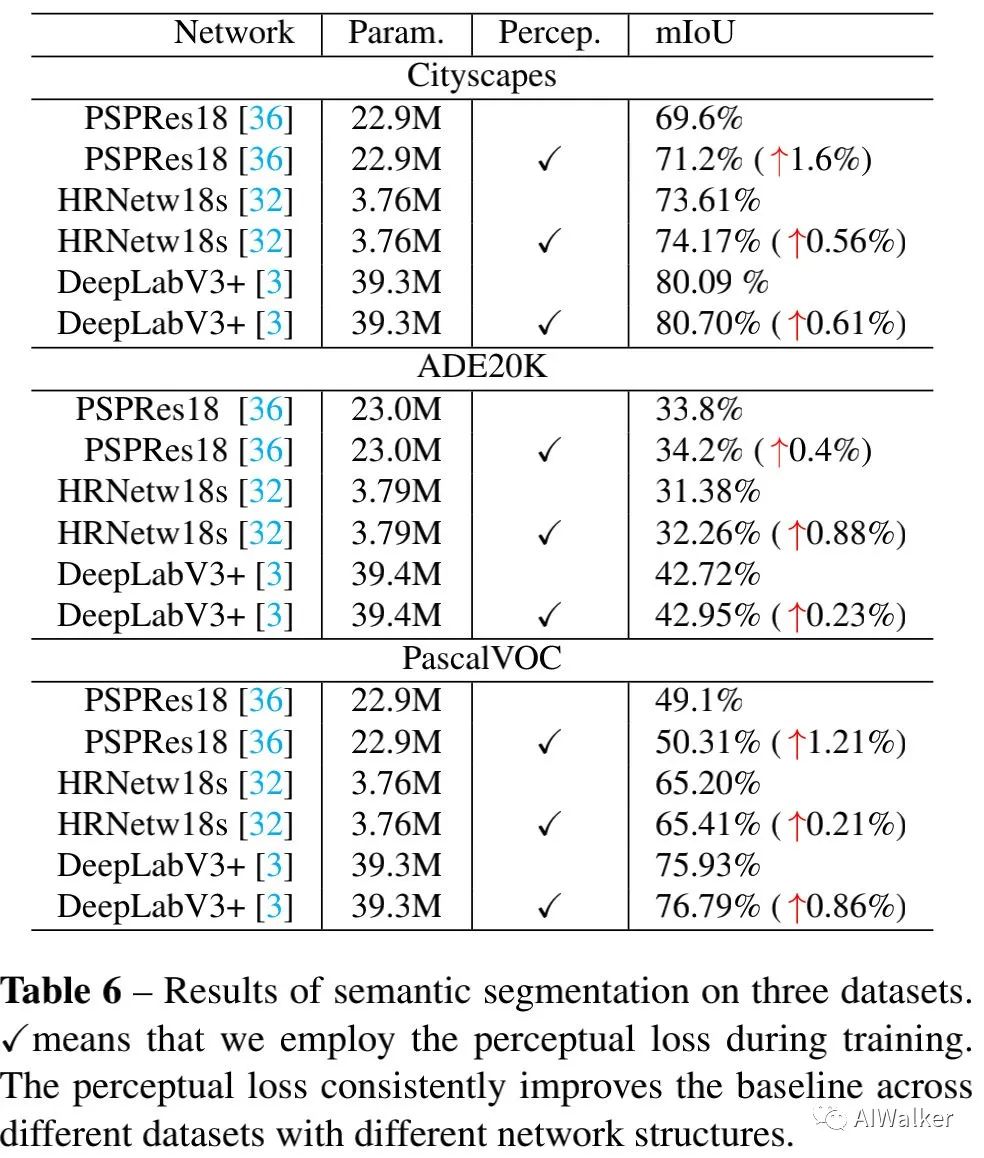
上表給出了不同語義分割數(shù)據(jù)集、不同分割網(wǎng)絡(luò)添加該損失前后的性能對比。看一看到:廣義感知損失可以一致性的提升現(xiàn)有語義分割網(wǎng)絡(luò)的性能(0.21%~1.6%不等)。

上表給出了實例分割任務(wù)上的性能對比。可以看到:廣義感知損失對于兩個任務(wù)咋所有質(zhì)量上均有顯著提升。該實驗進(jìn)一步說明:當(dāng)類似CondInst將Mask分支添加到單階段目標(biāo)檢測方法上時,廣義感知損失甚至可以提升目標(biāo)檢測的性能。
推薦閱讀
2021-03-23
2021-03-23
2021-03-22

# CV技術(shù)社群邀請函 #
備注:姓名-學(xué)校/公司-研究方向-城市(如:小極-北大-目標(biāo)檢測-深圳)
即可申請加入極市目標(biāo)檢測/圖像分割/工業(yè)檢測/人臉/醫(yī)學(xué)影像/3D/SLAM/自動駕駛/超分辨率/姿態(tài)估計/ReID/GAN/圖像增強/OCR/視頻理解等技術(shù)交流群
每月大咖直播分享、真實項目需求對接、求職內(nèi)推、算法競賽、干貨資訊匯總、與 10000+來自港科大、北大、清華、中科院、CMU、騰訊、百度等名校名企視覺開發(fā)者互動交流~
