
消息系統(tǒng)興起二次革命:Kafka不需要ZooKeeper


導讀
“我對該版本感到非常興奮,但我們的業(yè)務特性決定了我們不能停機升級...”
嘉賓介紹
韓欣
騰訊云中間件 - 微服務產(chǎn)品中心技術總監(jiān)
微服務平臺 TSF、消息隊列 CKafka / TDMQ、微服務觀測平臺 TSW 等中間件產(chǎn)品的負責人
有超過十三年的研發(fā)架構經(jīng)驗
王國璋
Confluent - 流數(shù)據(jù)部門首席工程師
Apache Kafka 項目管理委員會成員(PMC)
Kafka Streams 作者
分別于復旦大學計算機系和美國康奈爾大學計算機系取得學士和博士學位
此前曾就職于 LinkedIn 數(shù)據(jù)架構組任高級工程師

3 月 30 日,Kafka 背后的企業(yè) Confluent 發(fā)布博客表示,在即將發(fā)布的 2.8 版本里,用戶可在完全不需要 ZooKeeper 的情況下運行 Kafka,該版本將依賴于 ZooKeeper 的控制器改造成了基于 Kafka Raft 的 Quorm 控制器。
在之前的版本中,如果沒有 ZooKeeper,Kafka 將無法運行。但管理部署兩個不同的系統(tǒng)不僅讓運維復雜度翻倍,還讓 Kafka 變得沉重,進而限制了 Kafka 在輕量環(huán)境下的應用,同時 ZooKeeper 的分區(qū)特性也限制了 Kafka 的承載能力。
從 2019 年起,Confluent 就開始策劃更換掉 ZooKeeper。這是一項相當大的工程,經(jīng)過九個多月的開發(fā),KIP-500 代碼的早期訪問已經(jīng)提交到 trunk 中。
第一次,用戶可以在沒有 ZooKeeper 的情況下運行 Kafka。
這是一次架構上的重大升級,讓一向“重量級”的 Kafka 從此變得簡單了起來。輕量級的單進程部署可以作為 ActiveMQ 或 RabbitMQ 等的替代方案,同時也適合于邊緣場景和使用輕量級硬件的場景。
為什么要拋棄使用了十年的 ZooKeeper
ZooKeeper 是 Hadoop 的一個子項目,一般用來管理較大規(guī)模、結(jié)構復雜的服務器集群,具有自己的配置文件語法、管理工具和部署模式。Kafka 最初由 LinkedIn 開發(fā),隨后于 2011 年初開源,2014 年由主創(chuàng)人員組建企業(yè) Confluent。
Broker 是 Kafka 集群的骨干,負責從生產(chǎn)者(producer)到消費者(consumer)的接收、存儲和發(fā)送消息。在當前架構下,Kafka 進程在啟動的時候需要往 ZooKeeper 集群中注冊一些信息,比如 BrokerId,并組建集群。
ZooKeeper 為 Kafka 提供了可靠的元數(shù)據(jù)存儲,比如 Topic/ 分區(qū)的元數(shù)據(jù)、Broker 數(shù)據(jù)、ACL 信息等等。
同時 ZooKeeper 充當 Kafka 的領導者,以更新集群中的拓撲更改;根據(jù) ZooKeeper 提供的通知,生產(chǎn)者和消費者發(fā)現(xiàn)整個 Kafka 集群中是否存在任何新 Broker 或 Broker 失敗。大多數(shù)的運維操作,比如說擴容、分區(qū)遷移等等,都需要和 ZooKeeper 交互。
也就是說,Kafka 代碼庫中有很大一部分是負責實現(xiàn)在集群中多個 Broker 之間分配分區(qū)(即日志)、分配領導權、處理故障等分布式系統(tǒng)的功能。而早已經(jīng)過業(yè)界廣泛使用和驗證過的 ZooKeeper 是分布式代碼工作的關鍵部分。
假設沒有 ZooKeeper 的話,Kafka 甚至無法啟動進程。騰訊云中間件 - 微服務產(chǎn)品中心技術總監(jiān)韓欣對 InfoQ 說,“在以前的版本中,ZooKeeper 可以說是 Kafka 集群的靈魂。”
但嚴重依賴 ZooKeeper,也給 Kafka 帶來了掣肘。Kafka 一路發(fā)展過來,繞不開的兩個話題就是集群運維的復雜度以及單集群可承載的分區(qū)規(guī)模,韓欣表示,比如騰訊云 Kafka 維護了上萬節(jié)點的 Kafka 集群,主要遇到的問題也還是這兩個。
首先從集群運維的角度來看,Kafka 本身就是一個分布式系統(tǒng)。但它又依賴另一個開源的分布式系統(tǒng),而這個系統(tǒng)又是 Kafka 系統(tǒng)本身的核心。這就要求集群的研發(fā)和維護人員需要同時了解這兩個開源系統(tǒng),需要對其運行原理以及日常的運維(比如參數(shù)配置、擴縮容、監(jiān)控告警等)都有足夠的了解和運營經(jīng)驗。否則在集群出現(xiàn)問題的時候無法恢復,是不可接受的。所以,ZooKeeper 的存在增加了運維的成本。
其次從集群規(guī)模的角度來看,限制 Kafka 集群規(guī)模的一個核心指標就是集群可承載的分區(qū)數(shù)。集群的分區(qū)數(shù)對集群的影響主要有兩點:ZooKeeper 上存儲的元數(shù)據(jù)量和控制器變動效率。
Kafka 集群依賴于一個單一的 Controller 節(jié)點來處理絕大多數(shù)的 ZooKeeper 讀寫和運維操作,并在本地緩存所有 ZooKeeper 上的元數(shù)據(jù)。分區(qū)數(shù)增加,ZooKeeper 上需要存儲的元數(shù)據(jù)就會增加,從而加大 ZooKeeper 的負載,給 ZooKeeper 集群帶來壓力,可能導致 Watch 的延時或丟失。
當 Controller 節(jié)點出現(xiàn)變動時,需要進行 Leader 切換、Controller 節(jié)點重新選舉等行為,分區(qū)數(shù)越多需要進行越多的 ZooKeeper 操作:比如當一個 Kafka 節(jié)點關閉的時候,Controller 需要通過寫 ZooKeeper 將這個節(jié)點的所有 Leader 分區(qū)遷移到其他節(jié)點;新的 Controller 節(jié)點啟動時,首先需要將所有 ZooKeeper 上的元數(shù)據(jù)讀進本地緩存,分區(qū)越多,數(shù)據(jù)量越多,故障恢復耗時也就越長。
Kafka 單集群可承載的分區(qū)數(shù)量對于一些業(yè)務來說,又特別重要。韓欣舉例補充道,“騰訊云 Kafka 主要為公有云用戶以及公司內(nèi)部業(yè)務提供服務。我們遇到了很多需要支持百萬分區(qū)的用戶,比如騰訊云 Serverless、騰訊云的 CLS 日志服務、云上的一些客戶等,他們面臨的場景是一個客戶需要一個 topic 來進行業(yè)務邏輯處理,當用戶量達到百萬千萬量級的情況下,topic 帶來的膨脹是非常恐怖的。在當前架構下,Kafka 單集群無法穩(wěn)定承載百萬分區(qū)穩(wěn)定運行。這也是我對新的 KIP-500 版本感到非常興奮的原因。”
去除 ZooKeeper 后的 Kafka
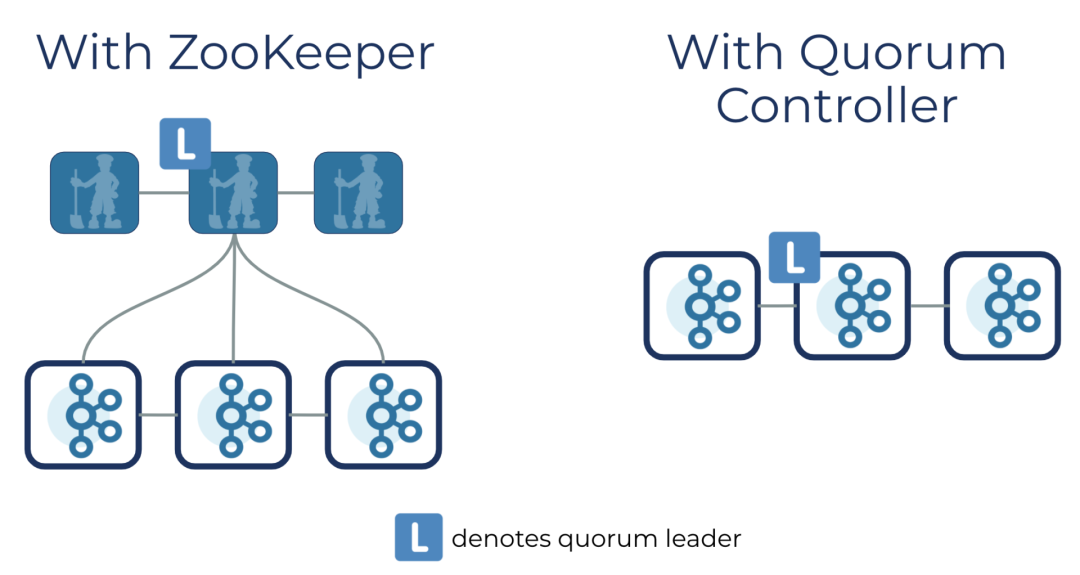
為了改善 Kafka,去年起 Confluent 就開始重寫 ZooKeeper 功能,將這部分代碼集成到了 Kafka 內(nèi)部。他們將新版本稱為“ Kafka on Kafka”,意思是將元數(shù)據(jù)存儲在 Kafka 本身,而不是存儲 ZooKeeper 這樣的外部系統(tǒng)中。Quorum 控制器使用新的 KRaft 協(xié)議來確保元數(shù)據(jù)在仲裁中被精確地復制。這個協(xié)議在很多方面與 ZooKeeper 的 ZAB 協(xié)議和 Raft 相似。這意味著,仲裁控制器在成為活動狀態(tài)之前不需要從 ZooKeeper 加載狀態(tài)。當領導權發(fā)生變化時,新的活動控制器已經(jīng)在內(nèi)存中擁有所有提交的元數(shù)據(jù)記錄。
去除 ZooKeeper 后,Kafka 集群的運維復雜性直接減半。
在架構改進之前,一個最小的分布式 Kafka 集群也需要六個異構的節(jié)點:三個 ZooKeeper 節(jié)點,三個 Kafka 節(jié)點。而一個最簡單的 Quickstart 演示也需要先啟動一個 ZooKeeper 進程,然后再啟動一個 Kafka 進程。在新的 KIP-500 版本中,一個分布式 Kafka 集群只需要三個節(jié)點,而 Quickstart 演示只需要一個 Kafka 進程就可以。
改進后同時提高了集群的延展性(scalability),大大增加了 Kafka 單集群可承載的分區(qū)數(shù)量。
在此之前,元數(shù)據(jù)管理一直是集群范圍限制的主要瓶頸。特別是在集群規(guī)模比較大的時候,如果出現(xiàn) Controller 節(jié)點失敗涉及到的選舉、Leader 分區(qū)遷移,以及將所有 ZooKeeper 的元數(shù)據(jù)讀進本地緩存的操作,所有這些操作都會受限于單個 Controller 的讀寫帶寬。因此一個 Kafka 集群可以管理的分區(qū)總數(shù)也會受限于這單個 Controller 的效率。??Confluent 流數(shù)據(jù)部門首席工程師王國璋解釋道:“在 KIP-500 中,我們用一個 Quorum Controller 來代替和 ZooKeeper 交互的單個 Controller,這個 Quorum 里面的每個 Controller 節(jié)點都會通過 Raft 機制來備份所有元數(shù)據(jù),而其中的 Leader 在寫入新的元數(shù)據(jù)時,也可以借由批量寫入(batch writes)Raft 日志來提高效率。我們的實驗表明,在一個可以管理兩百萬個分區(qū)的集群中,Quorum Controller 的遷移過程可以從幾分鐘縮小至三十秒。”
升級是否需要停機?
減少依賴、擴大單集群承載能力,這肯定是一個很積極的改變方向。雖然目前的版本還未經(jīng)過大流量檢驗,可能存在穩(wěn)定性問題,這也是讓廣大開發(fā)者擔心的一個方面。但從長期意義上來講,KIP-500 對社區(qū)和用戶都是一個很大的福音。
當版本穩(wěn)定之后,最終大家就會涉及到“升級”的工作。但如何升級,卻成了一個新的問題,在很多 Kafka 的使用場景中,是不允許業(yè)務停機的。韓欣拿騰訊云的業(yè)務舉例說,“微信安全業(yè)務的消息管道就使用了騰訊云的 Kafka,假設發(fā)生停機,那么一些自動化的安全業(yè)務就會受到影響,從而嚴重影響客戶體驗。”
“就我們的經(jīng)驗而言,停機升級,在騰訊云上是一個非常敏感的詞。騰訊云 Kafka 至今為止已經(jīng)運營了六七年,服務了內(nèi)外部幾百家大客戶,還未發(fā)生過一次停機升級的情況。如果需要停機才能升級,那么對客戶的業(yè)務肯定會有影響的,影響的范圍取決于客戶業(yè)務的重要性。從云服務的角度來看,任何客戶的業(yè)務的可持續(xù)性都是非常重要的、不可以被影響的。”
對于 Confluent 來講,提供不需要停機的平滑升級方案是一件非常有必要的事情。
據(jù)王國璋介紹,“目前的設計方案是,在 2.8 版本之后的 3.0 版本會是一個特殊的搭橋版本(bridge release),在這個版本中,Quorum Controller 會和老版本的基于 ZooKeeper 的 Controller,而在之后的版本我們才會去掉舊的 Controller 模塊。”
對于用戶而言,這意味著如果想要從 2.8 版本以下升級到 3.0 以后的某一個版本,比如說 3.1,則需要借由 3.0 版本實現(xiàn)兩次“跳躍”,也就是說先在線平滑升級到 3.0,然后再一次在線平滑升級到 3.1。并且在整個過程中,Kafka 服務器端都可以和各種低版本的客戶端進行交互,而不需要強制客戶端的升級。
而像騰訊這樣的企業(yè),也會持續(xù)采用灰度的方式來進行業(yè)務的升級驗證,韓欣說,“一般不會在存量集群上做大規(guī)模升級操作,而是會采用新建集群的方式,讓一些有迫切訴求的業(yè)務先切量進行灰度驗證,在保證線上業(yè)務穩(wěn)定運行的情況下,逐步擴展新集群的規(guī)模,這樣逐步將業(yè)務升級和遷移到新的架構上去。”
消息系統(tǒng)掀起二次革命?
Apache Kafka 出現(xiàn)之后,很快擊敗其它的消息系統(tǒng),成為最主流的應用。從 2011 年啟動,經(jīng)過十年發(fā)展,得到大規(guī)模應用之后,為什么現(xiàn)在又決定用“Raft 協(xié)議”替換 ZooKeeper 呢?對此,王國璋回復 InfoQ 說,Raft 是近年來很火的共識算法,但在 Kafka 設計之初(2011 年),不僅僅是 Raft 方案,就連一個成熟通用的共識機制(consensus)代碼庫也不存在。當時最直接的設計方案就是基于 ZooKeeper 這樣一個高可用的同步服務項目。
在這十年里,Hadoop 生態(tài)中的不少軟件都在被逐漸拋棄。如今,作為 Hadoop 生態(tài)中的一員,ZooKeeper 也開始過時了?韓欣給予了否認意見,“每一種架構或者軟件都有其適合的應用場景,我不認可過時這個詞。”
從技術的角度來看,歷史的車輪在不斷向前滾動,學術界和工業(yè)界的理論基礎一直在不斷進化,技術也要適應不斷革新的業(yè)務不停去演進。不否認有一些軟件會被一些新的軟件所替代,或者說一些新的軟件會更適合某些場景。比如流計算領域,Storm、Spark、Filnk 的演進。但是合適的組件總會出現(xiàn)在合適的地方,這就是架構師和研發(fā)人員的工作和責任。
Kafka 發(fā)展至今,雖然其體系結(jié)構不斷被改進,比如引入自動縮放、多租戶等功能,來滿足用戶發(fā)展的需求,但針對這次大的改進,且還存在需要驗證的現(xiàn)狀,網(wǎng)友在 HackerNews 上提出了一個靈魂發(fā)問:“如果現(xiàn)在還要設計一個新系統(tǒng),那么是什么理由選擇 Kafka 而不是 Pulsar?”
Confluent 的科林·麥凱布(Colin McCabe)回應這個爭議說,起碼去掉 ZooKeeper 對 Pulsar 來說是一個艱巨的挑戰(zhàn)。Kafka 去除 ZooKeeper 依賴是個很大的賣點,意味著 Kafka 只有一個組件 Broker,而 Pulsar 則需要 ZooKeeper、Bookie、Broker(或者 proxy)等多個組件。但也正因為 抽離出一層存儲層(Bookie),使得后起之秀的 Pulsar 在架構上天然具有了“計算存儲分離”的優(yōu)勢。
總的來說,在企業(yè)加速上云的背景下,無論是 Kafka 還是 Pulsar,消息系統(tǒng)必須是要適應云原生的大趨勢的,實現(xiàn)計算和存儲分離的功能也是 Kafka 下一步的策略。據(jù)王國璋介紹:Confluent 在另一個 KIP-405 版本中,實現(xiàn)了一個分層式的存儲模式,利用在云架構下多種存儲介質(zhì)的實際情況,將計算層和存儲層分離,將“冷數(shù)據(jù)”和“熱數(shù)據(jù)”分離,使得 Kafka 的分區(qū)擴容、縮容、遷移等等操作更加高效和低耗,同時也使 Kafka 可以在理論上長時間保留數(shù)據(jù)流。
在發(fā)展趨勢上,云原生的出現(xiàn)對消息系統(tǒng)的影響是比較大的,比如容器化和大規(guī)模云盤,為原本在單集群性能和堆積限制方面存在上限問題的 Kafka,在突破資源瓶頸這里帶來了新的思路。Broker 的容器化,堆積的消息用大規(guī)模的云盤,再加上 KRaft 去掉了 ZooKeeper 給 Kafka 帶來的元數(shù)據(jù)管理方面的限制,是否是給 Kafka 帶來了二次的消息系統(tǒng)革命?容器化的消息系統(tǒng)是否會帶來運營運維方面更多的自動化的能力?Serverless 是否是消息系統(tǒng)的未來趨勢?云和云原生的發(fā)展,給傳統(tǒng)的消息系統(tǒng)安上了新的翅膀,帶來了新的想象空間。
產(chǎn)品
動態(tài)
TSW
增加了對 Skywalking Agent 采集 MongoDB 的兼容性;
優(yōu)化了服務數(shù)的顯示邏輯,對長期無數(shù)據(jù)上報的服務不納入統(tǒng)計;
優(yōu)化了常用環(huán)境的跳轉(zhuǎn)邏輯。在您進入 TSW 后,會為您自動載入上次推出時使用的環(huán)境;
優(yōu)化了依賴拓撲圖的節(jié)點分布邏輯,減少了節(jié)點與關系線的遮擋。
往期
回顧
《速來圍觀,Apache Pulsar Meetup 深圳站來啦!| 現(xiàn)場精美禮品等你來拿》
《TVP 專家談鵝廠中間件:創(chuàng)新前行 遇見未來》

掃描下方二維碼關注本公眾號,
了解更多微服務、消息隊列的相關信息!
解鎖超多鵝廠周邊!
