
【NLP】深度學(xué)習(xí)文本分類|模型&代碼&技巧
文本分類是NLP的必備入門任務(wù),在搜索、推薦、對(duì)話等場景中隨處可見,并有情感分析、新聞分類、標(biāo)簽分類等成熟的研究分支和數(shù)據(jù)集。
本文主要介紹深度學(xué)習(xí)文本分類的常用模型原理、優(yōu)缺點(diǎn)以及技巧,是「NLP入門指南」的其中一章,之后會(huì)不斷完善,歡迎提意見:
https://github.com/leerumor/nlp_tutorial
P.S. 有基礎(chǔ)的同學(xué)可以直接看文末的技巧
Fasttext
論文:https://arxiv.org/abs/1607.01759
代碼:https://github.com/facebookresearch/fastText
Fasttext是Facebook推出的一個(gè)便捷的工具,包含文本分類和詞向量訓(xùn)練兩個(gè)功能。
Fasttext的分類實(shí)現(xiàn)很簡單:把輸入轉(zhuǎn)化為詞向量,取平均,再經(jīng)過線性分類器得到類別。輸入的詞向量可以是預(yù)先訓(xùn)練好的,也可以隨機(jī)初始化,跟著分類任務(wù)一起訓(xùn)練。
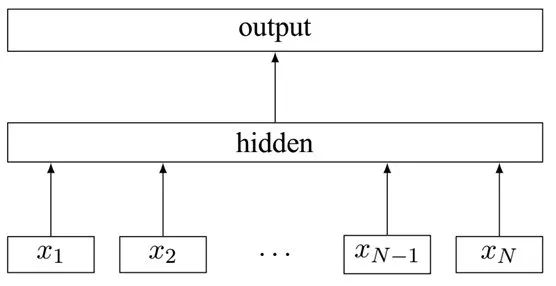
Fasttext直到現(xiàn)在還被不少人使用,主要有以下優(yōu)點(diǎn):
模型本身復(fù)雜度低,但效果不錯(cuò),能快速產(chǎn)生任務(wù)的baseline Facebook使用C++進(jìn)行實(shí)現(xiàn),進(jìn)一步提升了計(jì)算效率 采用了char-level的n-gram作為附加特征,比如paper的trigram是 [pap, ape, per],在將輸入paper轉(zhuǎn)為向量的同時(shí)也會(huì)把trigram轉(zhuǎn)為向量一起參與計(jì)算。這樣一方面解決了長尾詞的OOV (out-of-vocabulary)問題,一方面利用n-gram特征提升了表現(xiàn) 當(dāng)類別過多時(shí),支持采用hierarchical softmax進(jìn)行分類,提升效率
對(duì)于文本長且對(duì)速度要求高的場景,F(xiàn)asttext是baseline首選。同時(shí)用它在無監(jiān)督語料上訓(xùn)練詞向量,進(jìn)行文本表示也不錯(cuò)。不過想繼續(xù)提升效果還需要更復(fù)雜的模型。
TextCNN
論文:https://arxiv.org/abs/1408.5882
代碼:https://github.com/yoonkim/CNN_sentence
TextCNN是Yoon Kim小哥在2014年提出的模型,開創(chuàng)了用CNN編碼n-gram特征的先河。
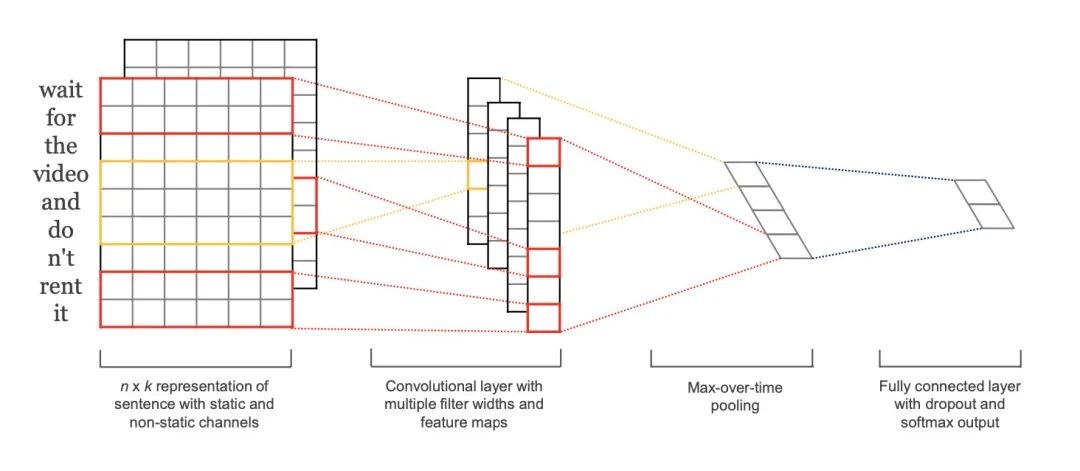
模型結(jié)構(gòu)如圖,圖像中的卷積都是二維的,而TextCNN則使用「一維卷積」,即filter_size * embedding_dim,有一個(gè)維度和embedding相等。這樣就能抽取filter_size個(gè)gram的信息。以1個(gè)樣本為例,整體的前向邏輯是:
對(duì)詞進(jìn)行embedding,得到 [seq_length, embedding_dim]用N個(gè)卷積核,得到N個(gè) seq_length-filter_size+1長度的一維feature map對(duì)feature map進(jìn)行max-pooling(因?yàn)槭菚r(shí)間維度的,也稱max-over-time pooling),得到N個(gè) 1x1的數(shù)值,拼接成一個(gè)N維向量,作為文本的句子表示將N維向量壓縮到類目個(gè)數(shù)的維度,過Softmax
在TextCNN的實(shí)踐中,有很多地方可以優(yōu)化(參考這篇論文[1]):
Filter尺寸:這個(gè)參數(shù)決定了抽取n-gram特征的長度,這個(gè)參數(shù)主要跟數(shù)據(jù)有關(guān),平均長度在50以內(nèi)的話,用10以下就可以了,否則可以長一些。在調(diào)參時(shí)可以先用一個(gè)尺寸grid search,找到一個(gè)最優(yōu)尺寸,然后嘗試最優(yōu)尺寸和附近尺寸的組合 Filter個(gè)數(shù):這個(gè)參數(shù)會(huì)影響最終特征的維度,維度太大的話訓(xùn)練速度就會(huì)變慢。這里在100-600之間調(diào)參即可 CNN的激活函數(shù):可以嘗試Identity、ReLU、tanh 正則化:指對(duì)CNN參數(shù)的正則化,可以使用dropout或L2,但能起的作用很小,可以試下小的dropout率(<0.5),L2限制大一點(diǎn) Pooling方法:根據(jù)情況選擇mean、max、k-max pooling,大部分時(shí)候max表現(xiàn)就很好,因?yàn)榉诸惾蝿?wù)對(duì)細(xì)粒度語義的要求不高,只抓住最大特征就好了 Embedding表:中文可以選擇char或word級(jí)別的輸入,也可以兩種都用,會(huì)提升些效果。如果訓(xùn)練數(shù)據(jù)充足(10w+),也可以從頭訓(xùn)練 蒸餾BERT的logits,利用領(lǐng)域內(nèi)無監(jiān)督數(shù)據(jù) 加深全連接:原論文只使用了一層全連接,而加到3、4層左右效果會(huì)更好[2]
TextCNN是很適合中短文本場景的強(qiáng)baseline,但不太適合長文本,因?yàn)榫矸e核尺寸通常不會(huì)設(shè)很大,無法捕獲長距離特征。同時(shí)max-pooling也存在局限,會(huì)丟掉一些有用特征。另外再仔細(xì)想的話,TextCNN和傳統(tǒng)的n-gram詞袋模型本質(zhì)是一樣的,它的好效果很大部分來自于詞向量的引入[3],因?yàn)榻鉀Q了詞袋模型的稀疏性問題。
DPCNN
論文:https://ai.tencent.com/ailab/media/publications/ACL3-Brady.pdf
代碼:https://github.com/649453932/Chinese-Text-Classification-Pytorch
上面介紹TextCNN有太淺和長距離依賴的問題,那直接多懟幾層CNN是否可以呢?感興趣的同學(xué)可以試試,就會(huì)發(fā)現(xiàn)事情沒想象的那么簡單。直到2017年,騰訊才提出了把TextCNN做到更深的DPCNN模型:
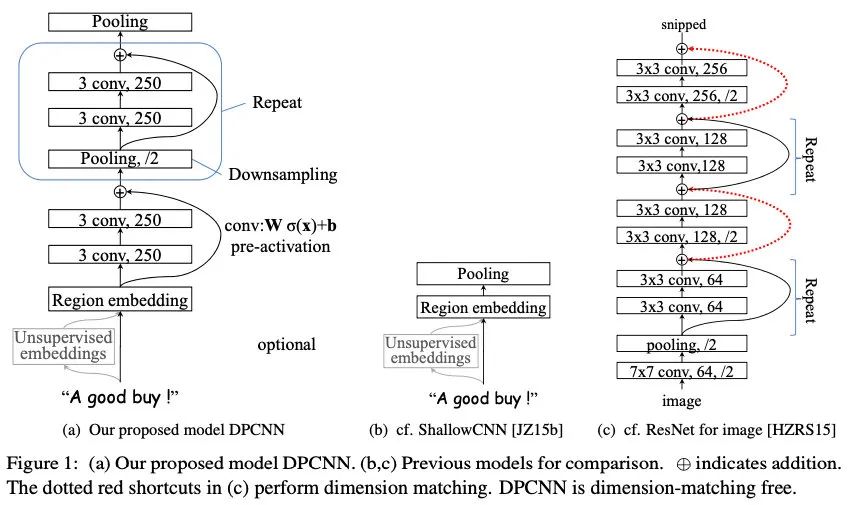
上圖中的ShallowCNN指TextCNN。DPCNN的核心改進(jìn)如下:
在Region embedding時(shí)不采用CNN那樣加權(quán)卷積的做法,而是對(duì)n個(gè)詞進(jìn)行pooling后再加個(gè)1x1的卷積,因?yàn)閷?shí)驗(yàn)下來效果差不多,且作者認(rèn)為前者的表示能力更強(qiáng),容易過擬合 使用1/2池化層,用size=3 stride=2的卷積核,直接讓模型可編碼的sequence長度翻倍(自己在紙上畫一下就get啦) 殘差鏈接,參考ResNet,減緩梯度彌散問題
憑借以上一些精妙的改進(jìn),DPCNN相比TextCNN有1-2個(gè)百分點(diǎn)的提升。
TextRCNN
論文:https://dl.acm.org/doi/10.5555/2886521.2886636
代碼:https://github.com/649453932/Chinese-Text-Classification-Pytorch
除了DPCNN那樣增加感受野的方式,RNN也可以緩解長距離依賴的問題。下面介紹一篇經(jīng)典TextRCNN。
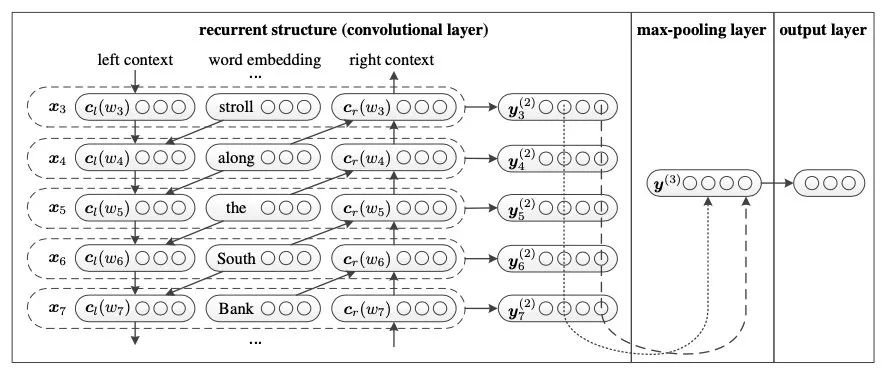
模型的前向過程是:
得到單詞 i 的表示 通過RNN得到左右雙向的表示 和 將表示拼接得到 ,再經(jīng)過變換得到 對(duì)多個(gè) 進(jìn)行 max-pooling,得到句子表示 ,在做最終的分類
這里的convolutional是指max-pooling。通過加入RNN,比純CNN提升了1-2個(gè)百分點(diǎn)。
TextBiLSTM+Attention
論文:https://www.aclweb.org/anthology/P16-2034.pdf
代碼:https://github.com/649453932/Chinese-Text-Classification-Pytorch
從前面介紹的幾種方法,可以自然地得到文本分類的框架,就是先基于上下文對(duì)token編碼,然后pooling出句子表示再分類。在最終池化時(shí),max-pooling通常表現(xiàn)更好,因?yàn)槲谋痉诸惤?jīng)常是主題上的分類,從句子中一兩個(gè)主要的詞就可以得到結(jié)論,其他大多是噪聲,對(duì)分類沒有意義。而到更細(xì)粒度的分析時(shí),max-pooling可能又把有用的特征去掉了,這時(shí)便可以用attention進(jìn)行句子表示的融合:
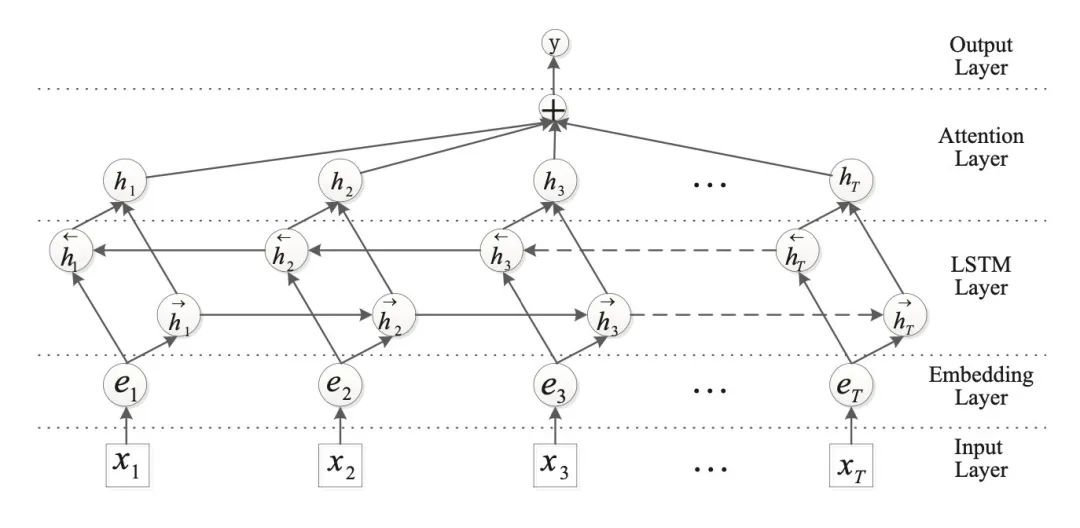
BiLSTM就不解釋了,要注意的是,計(jì)算attention score時(shí)會(huì)先進(jìn)行變換:
其中 是context vector,隨機(jī)初始化并隨著訓(xùn)練更新。最后得到句子表示 ,再進(jìn)行分類。
這個(gè)加attention的套路用到CNN編碼器之后代替pooling也是可以的,從實(shí)驗(yàn)結(jié)果來看attention的加入可以提高2個(gè)點(diǎn)。如果是情感分析這種由句子整體決定分類結(jié)果的任務(wù)首選RNN。
HAN
論文:https://www.aclweb.org/anthology/N16-1174.pdf
代碼:https://github.com/richliao/textClassifier
上文都是句子級(jí)別的分類,雖然用到長文本、篇章級(jí)也是可以的,但速度精度都會(huì)下降,于是有研究者提出了層次注意力分類框架,即Hierarchical Attention。先對(duì)每個(gè)句子用 BiGRU+Att 編碼得到句向量,再對(duì)句向量用 BiGRU+Att 得到doc級(jí)別的表示進(jìn)行分類:
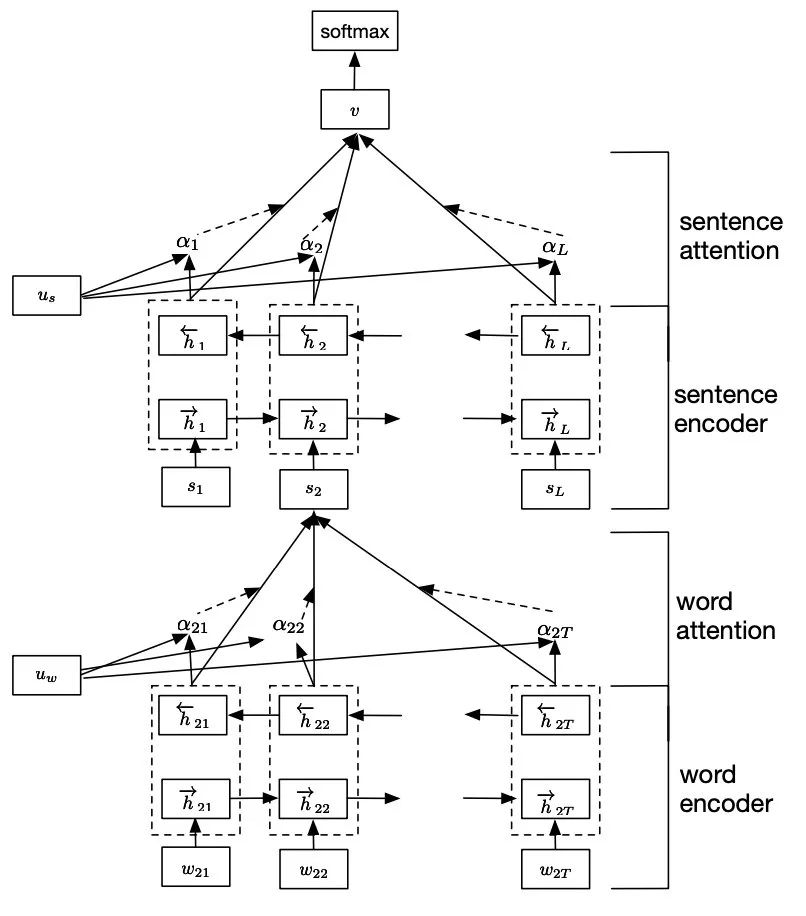
方法很符合直覺,不過實(shí)驗(yàn)結(jié)果來看比起avg、max池化只高了不到1個(gè)點(diǎn)(狗頭,真要是很大的doc分類,好好清洗下,fasttext其實(shí)也能頂?shù)模ㄎ婺槨?/p>
BERT
BERT的原理代碼就不用放了叭~
BERT分類的優(yōu)化可以嘗試:
多試試不同的預(yù)訓(xùn)練模型,比如RoBERT、WWM、ALBERT 除了 [CLS] 外還可以用 avg、max 池化做句表示,甚至可以把不同層組合起來 在領(lǐng)域數(shù)據(jù)上增量預(yù)訓(xùn)練 集成蒸餾,訓(xùn)多個(gè)大模型集成起來后蒸餾到一個(gè)上 先用多任務(wù)訓(xùn),再遷移到自己的任務(wù)
其他模型
除了上述常用模型之外,還有Capsule Network[4]、TextGCN[5]等紅極一時(shí)的模型,因?yàn)樯婕暗谋尘爸R(shí)較多,本文就暫不介紹了(嘻嘻)。
雖然實(shí)際的落地應(yīng)用中比較少見,但在機(jī)器學(xué)習(xí)比賽中還是可以用的。Capsule Network被證明在多標(biāo)簽遷移的任務(wù)上性能遠(yuǎn)超CNN和LSTM[6],但這方面的研究在18年以后就很少了。TextGCN則可以學(xué)到更多的global信息,用在半監(jiān)督場景中,但碰到較長的需要序列信息的文本表現(xiàn)就會(huì)差些[7]。
技巧
模型說得差不多了,下面介紹一些自己的數(shù)據(jù)處理血淚經(jīng)驗(yàn),如有不同意見歡迎討論~
數(shù)據(jù)集構(gòu)建
首先是標(biāo)簽體系的構(gòu)建,拿到任務(wù)時(shí)自己先試標(biāo)一兩百條,看有多少是難確定(思考1s以上)的,如果占比太多,那這個(gè)任務(wù)的定義就有問題。可能是標(biāo)簽體系不清晰,或者是要分的類目太難了,這時(shí)候就要找項(xiàng)目owner去反饋而不是繼續(xù)往下做。
其次是訓(xùn)練評(píng)估集的構(gòu)建,可以構(gòu)建兩個(gè)評(píng)估集,一個(gè)是貼合真實(shí)數(shù)據(jù)分布的線上評(píng)估集,反映線上效果,另一個(gè)是用規(guī)則去重后均勻采樣的隨機(jī)評(píng)估集,反映模型的真實(shí)能力。訓(xùn)練集則盡可能和評(píng)估集分布一致,有時(shí)候我們會(huì)去相近的領(lǐng)域拿現(xiàn)成的有標(biāo)注訓(xùn)練數(shù)據(jù),這時(shí)就要注意調(diào)整分布,比如句子長度、標(biāo)點(diǎn)、干凈程度等,盡可能做到自己分不出這個(gè)句子是本任務(wù)的還是從別人那里借來的。
最后是數(shù)據(jù)清洗:
去掉文本強(qiáng)pattern:比如做新聞主題分類,一些爬下來的數(shù)據(jù)中帶有的XX報(bào)道、XX編輯高頻字段就沒有用,可以對(duì)語料的片段或詞進(jìn)行統(tǒng)計(jì),把很高頻的無用元素去掉。還有一些會(huì)明顯影響模型的判斷,比如之前我在判斷句子是否為無意義的閑聊時(shí),發(fā)現(xiàn)加個(gè)句號(hào)就會(huì)讓樣本由正轉(zhuǎn)負(fù),因?yàn)橛?xùn)練預(yù)料中的閑聊很少帶句號(hào)(跟大家的打字習(xí)慣有關(guān)),于是去掉這個(gè)pattern就好了不少 糾正標(biāo)注錯(cuò)誤:這個(gè)我真的屢試不爽,生生把自己從一個(gè)算法變成了標(biāo)注人員。簡單的說就是把訓(xùn)練集和評(píng)估集拼起來,用該數(shù)據(jù)集訓(xùn)練模型兩三個(gè)epoch(防止過擬合),再去預(yù)測這個(gè)數(shù)據(jù)集,把模型判錯(cuò)的拿出來按 abs(label-prob) 排序,少的話就自己看,多的話就反饋給標(biāo)注人員,把數(shù)據(jù)質(zhì)量搞上去了提升好幾個(gè)點(diǎn)都是可能的
長文本
任務(wù)簡單的話(比如新聞分類),直接用fasttext就可以達(dá)到不錯(cuò)的效果。
想要用BERT的話,最簡單的方法是粗暴截?cái)啵热缰蝗【涫?句尾、句首+tfidf篩幾個(gè)詞出來;或者每句都預(yù)測,最后對(duì)結(jié)果綜合。
另外還有一些魔改的模型可以嘗試,比如XLNet、Reformer、Longformer。
如果是離線任務(wù)且來得及的話還是建議跑全部,讓我們相信模型的編碼能力。
少樣本
自從用了BERT之后,很少受到數(shù)據(jù)不均衡或者過少的困擾,先無腦訓(xùn)一版。
如果樣本在幾百條,可以先把分類問題轉(zhuǎn)化成匹配問題,或者用這種思想再去標(biāo)一些高置信度的數(shù)據(jù),或者用自監(jiān)督、半監(jiān)督的方法。
魯棒性
在實(shí)際的應(yīng)用中,魯棒性是個(gè)很重要的問題,否則在面對(duì)badcase時(shí)會(huì)很尷尬,怎么明明那樣就分對(duì)了,加一個(gè)字就錯(cuò)了呢?
這里可以直接使用一些粗暴的數(shù)據(jù)增強(qiáng),加停用詞加標(biāo)點(diǎn)、刪詞、同義詞替換等,如果效果下降就把增強(qiáng)后的訓(xùn)練數(shù)據(jù)洗一下。
當(dāng)然也可以用對(duì)抗學(xué)習(xí)、對(duì)比學(xué)習(xí)這樣的高階技巧來提升,一般可以提1個(gè)點(diǎn)左右,但不一定能避免上面那種尷尬的情況。
總結(jié)
文本分類是工業(yè)界最常用的任務(wù),同時(shí)也是大多數(shù)NLPer入門做的第一個(gè)任務(wù),我當(dāng)年就是啥都不會(huì),從訓(xùn)練到部署地實(shí)踐了文本分類后就順暢了。上文給出了不少模型,但實(shí)際任務(wù)中常用的也就那幾個(gè),下面是快速選型的建議:
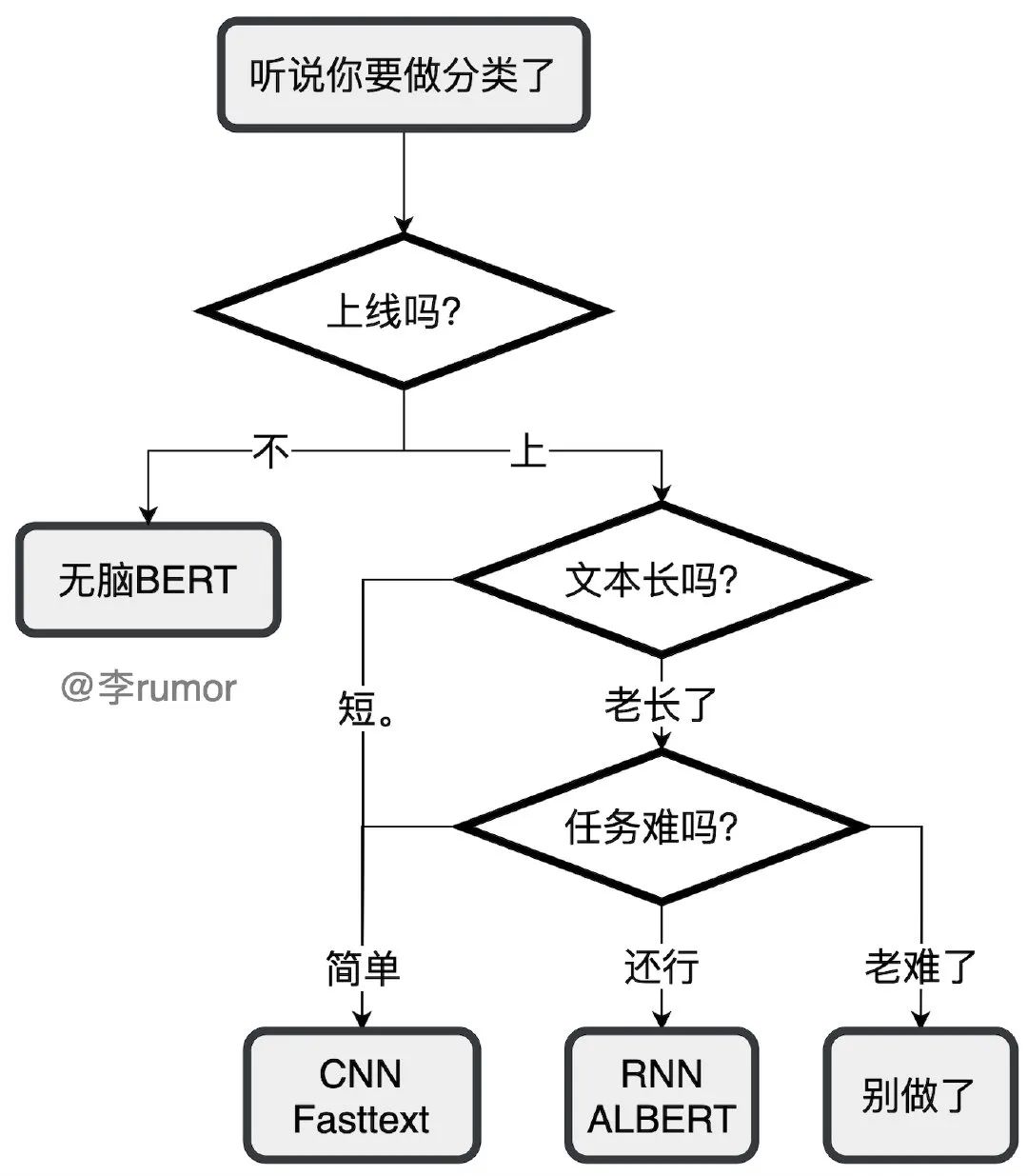
實(shí)際上,落地時(shí)主要還是和數(shù)據(jù)的博弈。數(shù)據(jù)決定模型的上限,大多數(shù)人工標(biāo)注的準(zhǔn)確率達(dá)到95%以上就很好了,而文本分類通常會(huì)對(duì)準(zhǔn)確率的要求更高一些,與其苦苦調(diào)參想fancy的結(jié)構(gòu),不如好好看看badcase,做一些數(shù)據(jù)增強(qiáng)提升模型魯棒性更實(shí)用。
最后,歡迎大家來NLP卷王群一起學(xué)習(xí)~
參考資料
A Sensitivity Analysis of (and Practitioners' Guide to) Convolutional Neural Networks for Sentence Classification: https://arxiv.org/pdf/1510.03820.pdf
[2]卷積層和分類層,哪個(gè)更重要?: https://www.zhihu.com/question/270245936
[3]從經(jīng)典文本分類模型TextCNN到深度模型DPCNN: https://zhuanlan.zhihu.com/p/35457093
[4]揭開迷霧,來一頓美味的Capsule盛宴: https://kexue.fm/archives/4819
[5]Graph Convolutional Networks for Text Classification: https://arxiv.org/abs/1809.05679
[6]膠囊網(wǎng)絡(luò)(Capsule Network)在文本分類中的探索: https://zhuanlan.zhihu.com/p/35409788
[7]怎么看待最近比較火的 GNN?: https://www.zhihu.com/question/307086081/answer/717456124
往期精彩回顧
本站知識(shí)星球“黃博的機(jī)器學(xué)習(xí)圈子”(92416895)
本站qq群704220115。
加入微信群請掃碼: