
Spring Kafka 之 @KafkaListener 單條或批量處理消息

消息監(jiān)聽容器
1、KafkaMessageListenerContainer
由spring提供用于監(jiān)聽以及拉取消息,并將這些消息按指定格式轉(zhuǎn)換后交給由@KafkaListener注解的方法處理,相當(dāng)于一個(gè)消費(fèi)者;
看看其整體代碼結(jié)構(gòu):
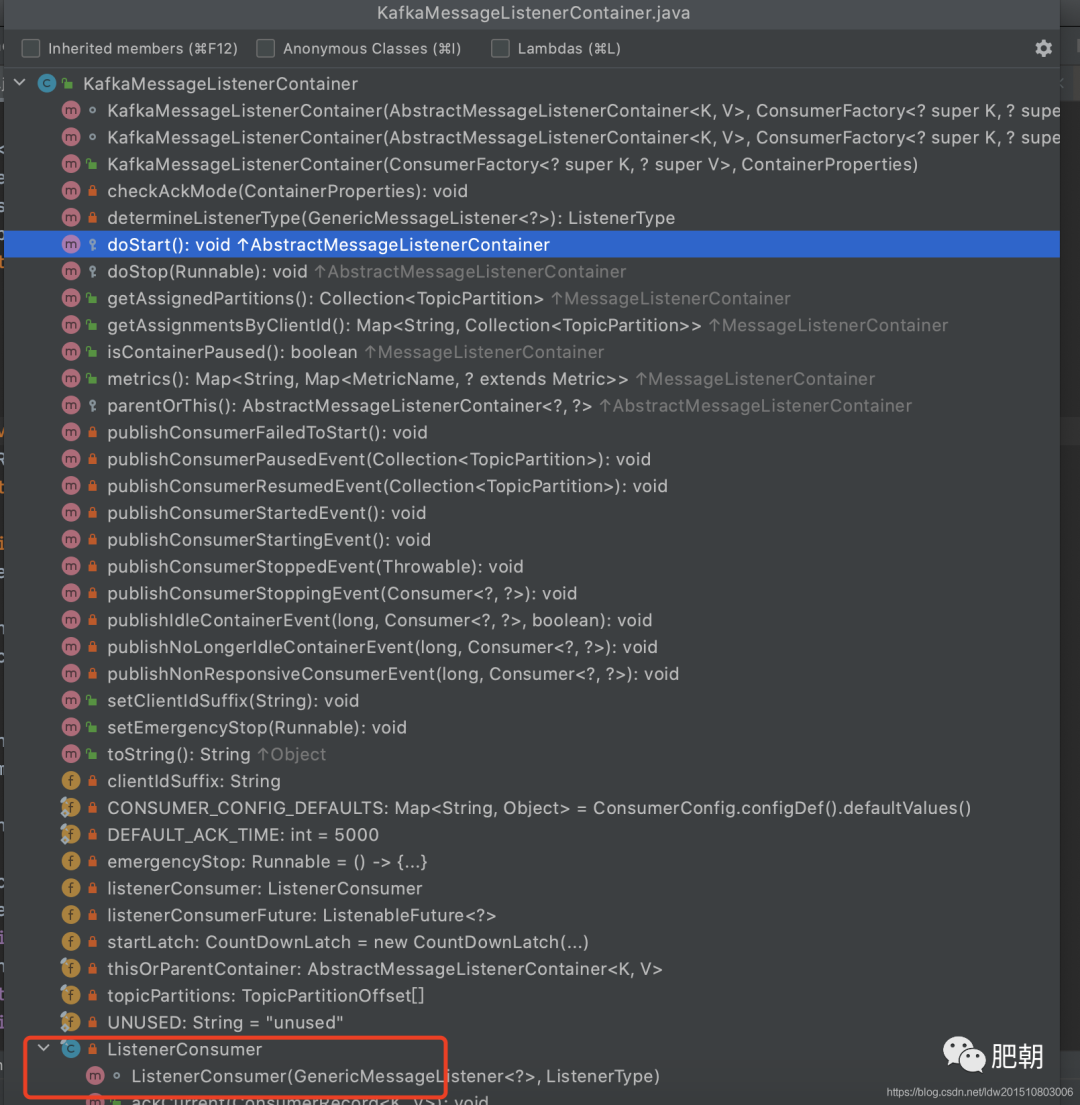
可以發(fā)現(xiàn)其入口方法為doStart(), 往上追溯到實(shí)現(xiàn)了SmartLifecycle接口,很明顯,由spring管理其start和stop操作;
ListenerConsumer, 內(nèi)部真正拉取消息消費(fèi)的是這個(gè)結(jié)構(gòu),其 實(shí)現(xiàn)了Runable接口,簡言之,它就是一個(gè)后臺(tái)線程輪訓(xùn)拉取并處理消息
在doStart方法中會(huì)創(chuàng)建ListenerConsumer并交給線程池處理
以上步驟就開啟了消息監(jiān)聽過程
KafkaMessageListenerContainer#doStart
protected void doStart() {
if (isRunning()) {
return;
}
if (this.clientIdSuffix == null) { // stand-alone container
checkTopics();
}
ContainerProperties containerProperties = getContainerProperties();
checkAckMode(containerProperties);
......
// 創(chuàng)建ListenerConsumer消費(fèi)者并放入到線程池中執(zhí)行
this.listenerConsumer = new ListenerConsumer(listener, listenerType);
setRunning(true);
this.startLatch = new CountDownLatch(1);
this.listenerConsumerFuture = containerProperties
.getConsumerTaskExecutor()
.submitListenable(this.listenerConsumer);
......
}
KafkaMessageListenerContainer.ListenerConsumer#run
public void run() { // NOSONAR complexity
.......
Throwable exitThrowable = null;
while (isRunning()) {
try {
// 拉去消息并處理消息
pollAndInvoke();
}
catch (@SuppressWarnings(UNUSED) WakeupException e) {
......
}
......
}
wrapUp(exitThrowable);
}
2、ConcurrentMessageListenerContainer
并發(fā)消息監(jiān)聽,相當(dāng)于創(chuàng)建消費(fèi)者;其底層邏輯仍然是通過KafkaMessageListenerContainer實(shí)現(xiàn)處理;從實(shí)現(xiàn)上看就是在KafkaMessageListenerContainer上做了層包裝,有多少的concurrency就創(chuàng)建多個(gè)KafkaMessageListenerContainer,也就是concurrency個(gè)消費(fèi)者
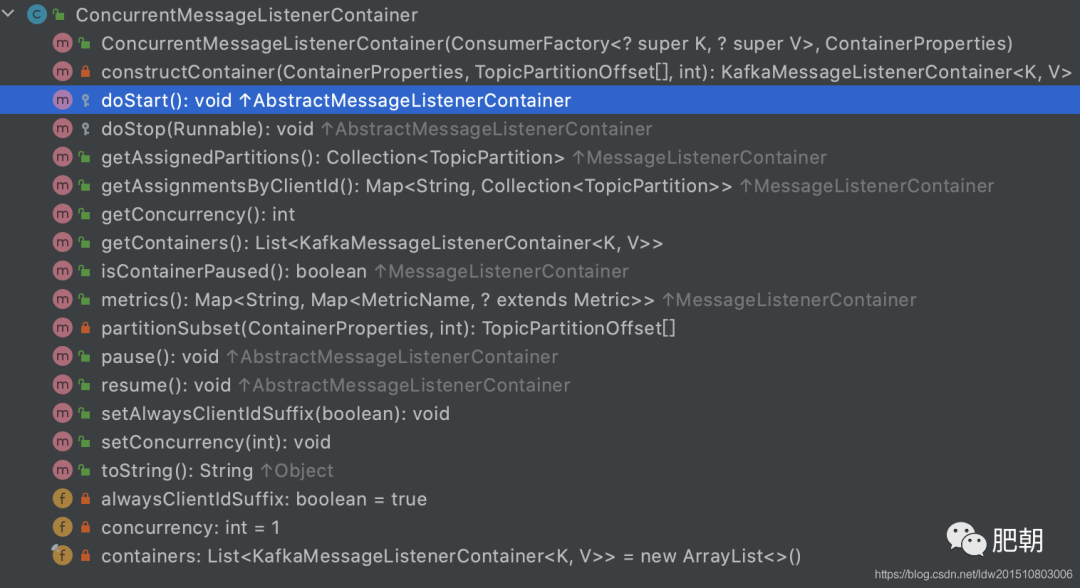
ConcurrentMessageListenerContainer#doStart
protected void doStart() {
if (!isRunning()) {
checkTopics();
......
setRunning(true);
for (int i = 0; i < this.concurrency; i++) {
KafkaMessageListenerContainer<K, V> container =
constructContainer(containerProperties, topicPartitions, i);
String beanName = getBeanName();
container.setBeanName((beanName != null ? beanName : "consumer") + "-" + i);
......
if (isPaused()) {
container.pause();
}
// 這里調(diào)用KafkaMessageListenerContainer啟動(dòng)相關(guān)監(jiān)聽方法
container.start();
this.containers.add(container);
}
}
}
@KafkaListener底層監(jiān)聽原理
上面已經(jīng)介紹了
KafkaMessageListenerContainer的作用是拉取并處理消息,但還缺少關(guān)鍵的一步,即 如何將我們的業(yè)務(wù)邏輯與KafkaMessageListenerContainer的處理邏輯聯(lián)系起來?
那么這個(gè)橋梁就是@KafkaListener注解
KafkaListenerAnnotationBeanPostProcessor, 從后綴BeanPostProcessor就可以知道這是Spring IOC初始化bean相關(guān)的操作,當(dāng)然這里也是;此類會(huì)掃描帶@KafkaListener注解的類或者方法,通過 KafkaListenerContainerFactory工廠創(chuàng)建對(duì)應(yīng)的KafkaMessageListenerContainer,并調(diào)用start方法啟動(dòng)監(jiān)聽,也就是這樣打通了這條路…
Spring Boot 自動(dòng)加載kafka相關(guān)配置
1、KafkaAutoConfiguration
自動(dòng)生成kafka相關(guān)配置,比如當(dāng)缺少這些bean的時(shí)候KafkaTemplate、ProducerListener、ConsumerFactory、ProducerFactory等,默認(rèn)創(chuàng)建bean實(shí)例
2、KafkaAnnotationDrivenConfiguration
主要是針對(duì)于spring-kafka提供的注解背后的相關(guān)操作,比如 @KafkaListener;
在開啟了@EnableKafka注解后,spring會(huì)掃描到此配置并創(chuàng)建缺少的bean實(shí)例,比如當(dāng)配置的工廠beanName不是kafkaListenerContainerFactory的時(shí)候,就會(huì)默認(rèn)創(chuàng)建一個(gè)beanName為kafkaListenerContainerFactory的實(shí)例,這也是為什么在springboot中不用定義consumer的相關(guān)配置也可以通過@KafkaListener正常的處理消息
生產(chǎn)配置
1、單條消息處理
@Configuration
@EnableKafka
public class KafkaConfig {
@Bean
KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<Integer, String>>
kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<Integer, String> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
factory.setConcurrency(3);
factory.getContainerProperties().setPollTimeout(3000);
return factory;
}
@Bean
public ConsumerFactory<Integer, String> consumerFactory() {
return new DefaultKafkaConsumerFactory<>(consumerConfigs());
}
@Bean
public Map<String, Object> consumerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, embeddedKafka.getBrokersAsString());
...
return props;
}
}
@KafkaListener(id = "myListener", topics = "myTopic",
autoStartup = "${listen.auto.start:true}", concurrency = "${listen.concurrency:3}")
public void listen(String data) {
...
}
2、批量處理
@Configuration
@EnableKafka
public class KafkaConfig {
@Bean
public KafkaListenerContainerFactory<?, ?> batchFactory() {
ConcurrentKafkaListenerContainerFactory<Integer, String> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
factory.setBatchListener(true); // <<<<<<<<<<<<<<<<<<<<<<<<<
return factory;
}
@Bean
public ConsumerFactory<Integer, String> consumerFactory() {
return new DefaultKafkaConsumerFactory<>(consumerConfigs());
}
@Bean
public Map<String, Object> consumerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, embeddedKafka.getBrokersAsString());
...
return props;
}
}
@KafkaListener(id = "list", topics = "myTopic", containerFactory = "batchFactory")
public void listen(List<String> list) {
...
}
3、同一個(gè)消費(fèi)組支持單條和批量處理
場(chǎng)景:
生產(chǎn)上最初都采用單條消費(fèi)模式,隨著量的積累,部分topic常常出現(xiàn)消息積壓,最開始通過新增消費(fèi)者實(shí)例和分區(qū)來提升消費(fèi)端的能力;一段時(shí)間后又開始出現(xiàn)消息積壓,由此便從代碼層面通過批量消費(fèi)來提升消費(fèi)能力。
只對(duì)部分topic做批量消費(fèi)處理
簡單的說就是需要配置批量消費(fèi)和單條記錄消費(fèi)(從單條消費(fèi)逐步向批量消費(fèi)演進(jìn))
假設(shè)最開始就是配置的單條消息處理的相關(guān)配置,原配置基本不變
然后新配置 批量消息監(jiān)聽KafkaListenerContainerFactory
@Configuration
@EnableKafka
public class KafkaConfig {
@Bean(name = [batchListenerContainerFactory])
public KafkaListenerContainerFactory<?, ?> batchFactory() {
ConcurrentKafkaListenerContainerFactory<Integer, String> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
// 開啟批量處理
factory.setBatchListener(true);
return factory;
}
@Bean(name = [batchConsumerFactory])
public ConsumerFactory<Integer, String> consumerFactory() {
return new DefaultKafkaConsumerFactory<>(consumerConfigs());
}
@Bean(name = [batchConsumerConfig])
public Map<String, Object> consumerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, embeddedKafka.getBrokersAsString());
...
return props;
}
}
注意點(diǎn):
如果自定義的ContainerFactory其beanName不是kafkaListenerContainerFactory,spring會(huì)通過KafkaAnnotationDrivenConfiguration創(chuàng)建新的bean實(shí)例,所以需要注意的是你最終的@KafkaListener會(huì)使用到哪個(gè)ContainerFactory
單條或在批量處理的ContainerFactory可以共存,默認(rèn)會(huì)使用beanName為kafkaListenerContainerFactory的bean實(shí)例,因此你可以為batch container Factory實(shí)例指定不同的beanName,并在@KafkaListener使用的時(shí)候指定containerFactory即可
總結(jié)
spring為了將kafka融入其生態(tài),方便在spring大環(huán)境下使用kafka,開發(fā)了spring-kafa這一模塊,本質(zhì)上是為了幫助開發(fā)者更好的以spring的方式使用kafka
@KafkaListener就是這么一個(gè)工具,在同一個(gè)項(xiàng)目中既可以有單條的消息處理,也可以配置多條的消息處理,稍微改變下配置即可實(shí)現(xiàn),很是方便
當(dāng)然,@KafkaListener單條或者多條消息處理仍然是spring自行封裝處理,與kafka-client客戶端的拉取機(jī)制無關(guān);比如一次性拉取50條消息,對(duì)于單條處理來說就是循環(huán)50次處理,而多條消息處理則可以一次性處理50條;本質(zhì)上來說這套邏輯都是spring處理的,并不是說單條消費(fèi)就是通過kafka-client一次只拉取一條消息
在使用過程中需要注意spring自動(dòng)的創(chuàng)建的一些bean實(shí)例,當(dāng)然也可以覆蓋其自動(dòng)創(chuàng)建的實(shí)例以滿足特定的需求場(chǎng)景
調(diào)試及相關(guān)源碼版本:
org.springframework.boot::2.3.3.RELEASE
spring-kafka:2.5.4.RELEASE
推薦閱讀
你好,我是程序猿DD,10年開發(fā)老司機(jī)、阿里云MVP、騰訊云TVP、出過書創(chuàng)過業(yè)、國企4年互聯(lián)網(wǎng)6年。從普通開發(fā)到架構(gòu)師、再到合伙人。一路過來,給我最深的感受就是一定要不斷學(xué)習(xí)并關(guān)注前沿。只要你能堅(jiān)持下來,多思考、少抱怨、勤動(dòng)手,就很容易實(shí)現(xiàn)彎道超車!所以,不要問我現(xiàn)在干什么是否來得及。如果你看好一個(gè)事情,一定是堅(jiān)持了才能看到希望,而不是看到希望才去堅(jiān)持。相信我,只要堅(jiān)持下來,你一定比現(xiàn)在更好!如果你還沒什么方向,可以先關(guān)注我,這里會(huì)經(jīng)常分享一些前沿資訊,幫你積累彎道超車的資本。