
深入聊聊Linux五種IO模型
一、相關(guān)概念講解
1、同步與異步
2、堵塞與非堵塞
3、用戶空間與內(nèi)核空間
4、進程切換
5、進程的堵塞
6、文件描述符
7、緩存
二、IO模型
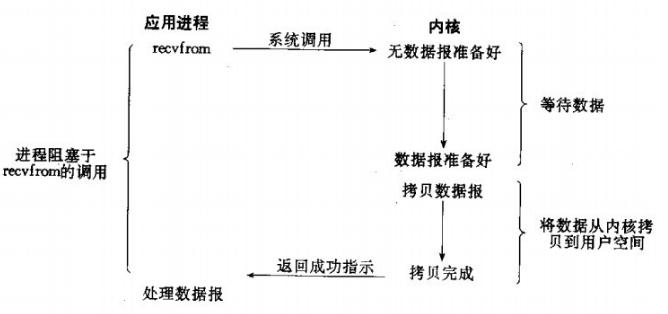
1、堵塞IO模型
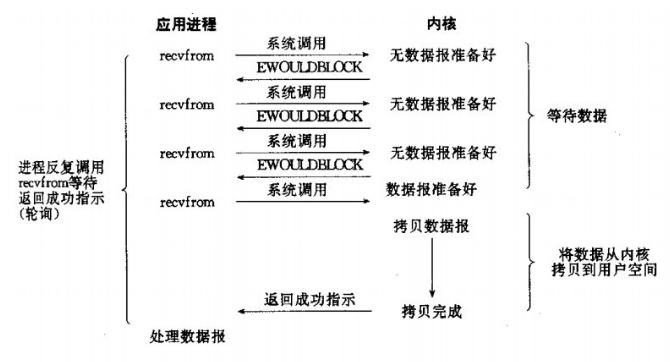
2、非堵塞IO模型
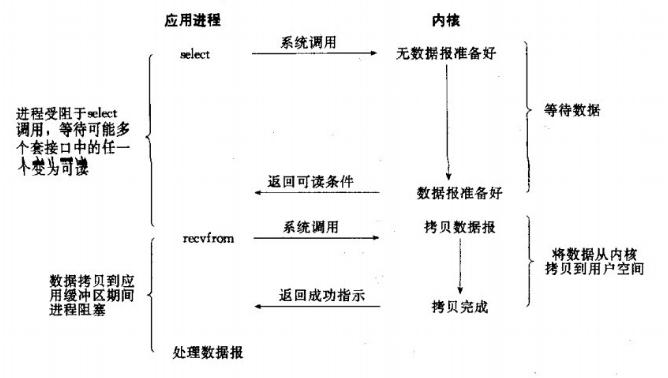
3、IO 復(fù)用模型
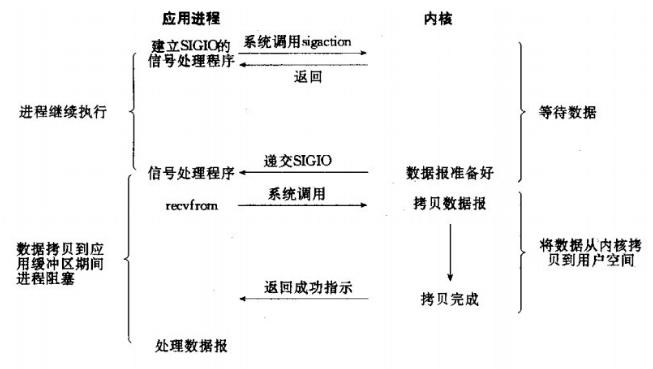
3、信號驅(qū)動IO
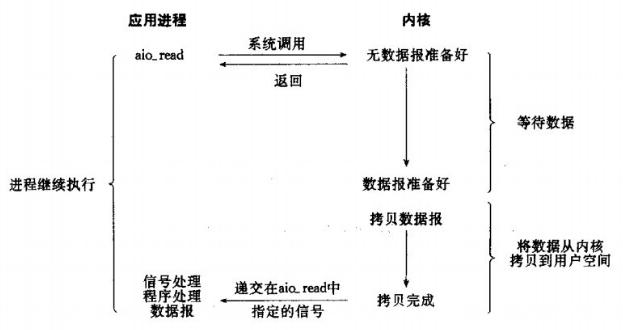
4、異步IO模型
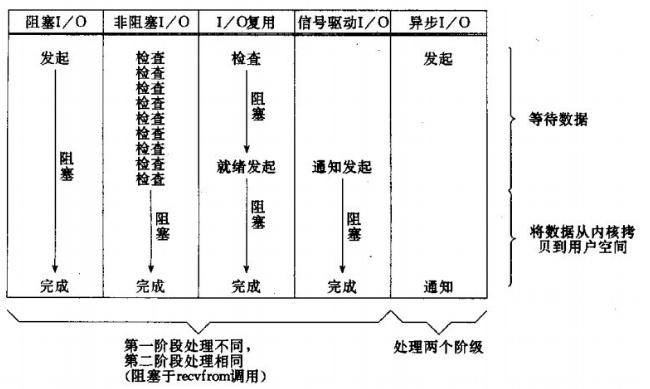
5、5種I/O模型的比較
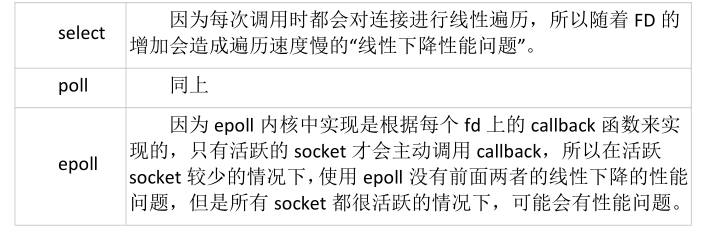
三、select 、poll 、epoll的區(qū)別?


推薦閱讀:
不是你需要中臺,而是一名合格的架構(gòu)師(附各大廠中臺建設(shè)PPT)
企業(yè)IT技術(shù)架構(gòu)規(guī)劃方案
論數(shù)字化轉(zhuǎn)型——轉(zhuǎn)什么,如何轉(zhuǎn)?
企業(yè)10大管理流程圖,數(shù)字化轉(zhuǎn)型從業(yè)者必備!
評論
圖片
表情