
億級流量網(wǎng)站構(gòu)架核心技術(shù)
高并發(fā)原則
無狀態(tài)
拆分
系統(tǒng)維度:根據(jù)系統(tǒng)功能/業(yè)務(wù)進行拆分
功能維度:對一個系統(tǒng)進行功能再拆分
讀寫維度:根據(jù)讀寫比例進行拆分
AOP維度:根據(jù)訪問特征
模塊維度:比如按照基礎(chǔ)或代碼維護特征進行拆分
服務(wù)化:進程內(nèi)服務(wù) -> 單機遠程服務(wù) -> 集群手動注冊服務(wù) -> 自動注冊和發(fā)現(xiàn)服務(wù) -> 服務(wù)的分組/隔離/路由 -> 服務(wù)治理(限流/黑白名單等)
消息隊列:服務(wù)解耦、異步處理、流量削峰/緩沖等
消息隊列進行多個鏡像復(fù)制
重試功能、防重、(冪等性)
失敗處理、日志、報警
大流量緩沖:一般是犧牲強一致性,而保證最終一致性
數(shù)據(jù)校對:數(shù)據(jù)校對與修正來保證數(shù)據(jù)的一致性和完整性
數(shù)據(jù)異構(gòu):形成數(shù)據(jù)閉環(huán),任何依賴系統(tǒng)出問題了,還是能正常工作,只是更新會有積壓,但不影響前端展示
數(shù)據(jù)異構(gòu):通過如MQ接受數(shù)據(jù)變更,然后原子化存儲到合適的存儲引擎,如Redis等。目的是把數(shù)據(jù)從多個數(shù)據(jù)源拿過來
數(shù)據(jù)聚合:可選的,目的是把這些數(shù)據(jù)做聚合,前端可以一個調(diào)用拿到全部數(shù)據(jù),該步驟一般存儲在KV存儲中
前端展示:前端通過一次或少量調(diào)用拿到所需要的數(shù)據(jù)
緩存銀彈
使用接入層提供的緩存機制:對于沒CDN緩存的應(yīng)用來說,可以考慮使用如Nginx搭建一層接入層,可以考慮以下機制:
使用應(yīng)用層提供的緩存機制:使用Tomcat時可以使用堆內(nèi)緩存/堆外緩存;local redis cache在應(yīng)用所在服務(wù)器上部署一組redis,應(yīng)用直接讀取本機Redis數(shù)據(jù),多機之間使用主從機制同步數(shù)據(jù)
使用分布式緩存:數(shù)據(jù)量太大,使用分片機制將流量分散到多臺,或直接使用分布式緩存實現(xiàn)。常見分片機制是一致性哈希
靜態(tài)化/偽靜態(tài)化,使用服務(wù)器操作系統(tǒng)提供的緩存機制
URL重寫:將URL按照指定的順序或格式重寫,去除隨機數(shù)
一致性哈希:按照指定的參數(shù)做一致性哈希,從而保證相同數(shù)據(jù)落到一臺服務(wù)器上
proxy_cache:使用內(nèi)存級/SSD級代理緩存來緩存內(nèi)容
proxy_cache_lock:使用Lock機制,將多個回源合并為一個,以減少回源量,并設(shè)置相應(yīng)的Lock超時時間
shared_dict:如果架構(gòu)使用nginx+lux實現(xiàn),,可考慮使用Lua shared_dict進行cache,最大好處是reload緩存不會丟失
對于托底(或兜底,指降級后顯示的)數(shù)據(jù)或異常數(shù)據(jù),不應(yīng)該讓其緩存,否則用戶會很長一段時間內(nèi)看到這些數(shù)據(jù)
使用代理服務(wù)器(含CDN):一般有兩種機制:推送機制(當(dāng)內(nèi)容變更后主動推送到CDN邊緣節(jié)點),拉取機制(先訪問邊緣節(jié)點,當(dāng)沒有內(nèi)容時,回源到源服務(wù)器拿到內(nèi)容并存儲到節(jié)點上)。使用CDN需要考慮URL的設(shè)計,比如不能有隨機數(shù),否則每次都穿透CDN回源到源服務(wù)器;對于爬蟲,可以返回過期數(shù)據(jù)而不選擇回源
使用鏡像服務(wù)器,使用P2P技術(shù)
使用瀏覽器緩存:設(shè)置請求過期時間,對應(yīng)相應(yīng)頭Expires, Cache-control進行控制,適合于實時性不敏感數(shù)據(jù)
客戶端應(yīng)用緩存:提前將內(nèi)容發(fā)到客戶端進行緩存
客戶端:
客戶端網(wǎng)絡(luò):代理服務(wù)器開啟緩存
廣域網(wǎng):
源站及源站網(wǎng)絡(luò):
并發(fā)化
方式
應(yīng)用級緩存:緩存回收策略(空間/容量/時間),緩存回收算法(FIFO/LRU/LFU),java堆/java堆外/磁盤緩存,Guava/Ehcache/MapDB,緩存使用模式(Cache-Asize/Cache-As-SoR/Copy Pattern)
HTTP緩存:瀏覽器緩存,HttpClient客戶端緩存,nginx代理層緩存
多級緩存:分布式緩存,熱點數(shù)據(jù)與更新緩存,更新緩存與原子性,緩存崩潰與快速修復(fù)
池化:數(shù)據(jù)庫連接池,F(xiàn)ttpClient連接池,線程池
異步并發(fā):同步阻塞調(diào)用,異步Future,異步CallBack,異步編排CompletableFuture,請求緩存,請求合并
擴容:單體應(yīng)用垂直擴容,單體應(yīng)用水平擴容,應(yīng)用拆分,數(shù)據(jù)庫拆分(水平/垂直),使用sharding-jdbc分庫分表/讀寫分離,數(shù)據(jù)異構(gòu),任務(wù)系統(tǒng)擴容(Elastic-Job)
隊列:異步處理/系統(tǒng)解耦/數(shù)據(jù)同步/流量削峰,緩沖隊列/任務(wù)隊列/消息隊列/請求隊列/數(shù)據(jù)總線隊列,Disruptor+Redis隊列,基于Canal實現(xiàn)數(shù)據(jù)異構(gòu)
高可用原則
負載均衡:負載均衡算法、失敗重試機制、健康檢查機制、動態(tài)負載均衡
降級
開關(guān)集中化管理:通過推送機制把開關(guān)推送到各個應(yīng)用
可降級的多級讀服務(wù):比如服務(wù)調(diào)用降級為只讀本地緩存、只讀分布式緩存、只讀默認降級數(shù)據(jù)
開關(guān)前置化:如架構(gòu)師nginx+tomcat,將開關(guān)前置到nginx接入層,請求流量不回源后端tomcat或只小部分流量回源
業(yè)務(wù)降級
降級預(yù)案、自動降級/開關(guān)降級、讀服務(wù)/寫服務(wù)降級、多級降級、配置中心、使用Hystrix降級、使用Hystrix熔斷
限流:
惡意請求流量只訪問到cache
對于穿透到后端的流量可以考慮使用nginx的limit模塊處理
對于惡意IP可以使用nginx deny進行屏蔽
限流算法、應(yīng)用級限流、分布式限流、接入層限流
隔離:進程線程隔離、集群/機房隔離、讀寫隔離、動靜隔離、爬蟲/熱點隔離、使用Hystrix隔離、基于Servlet3的請求隔離
超時與重試:代理層超時與重試、Web容器超時、中間件客戶端超時與重試、數(shù)據(jù)庫客戶端超時、NOSQL客戶端超時、業(yè)務(wù)超時、前端AJAX超時
切流量:
DNS:切換機房入口
HttpDNS:主要APP場景下,在客戶端分配好流量入口,繞過運營商LocalDNS并實現(xiàn)更精準(zhǔn)流量調(diào)度
LVS/HaProxy:切換故障的nginx接入層
Nginx:切換故障的應(yīng)用層
可回滾:版本化的目的是實現(xiàn)可審計可追溯,并且可回滾。如果程序或數(shù)據(jù)出錯時,如果有版本化機制,那就可以通過回滾恢復(fù)到最近一個正確的版本,比如事務(wù)回滾、代碼庫回滾、部署版本回滾、數(shù)據(jù)版本回滾、靜態(tài)資源版本回滾等。
壓測與預(yù)案:系統(tǒng)壓測、系統(tǒng)優(yōu)化與容災(zāi)、應(yīng)急預(yù)案、
監(jiān)控報警:服務(wù)器/系統(tǒng)/JVM/接口監(jiān)控、監(jiān)控時間段、報警閥值、通知方式
業(yè)務(wù)設(shè)計原則
防重設(shè)計:防重key、防重表
冪等設(shè)計
流程可定義:關(guān)聯(lián)、可復(fù)用流程,個性化流程
狀態(tài)與狀態(tài)機
比如訂單交易,會有正向狀態(tài)(待付款/待發(fā)貨/已發(fā)貨/完成)與逆向狀態(tài)(取消/退款),正向狀態(tài)與逆向狀態(tài)根據(jù)系統(tǒng)特征決定要不要分離存儲。狀態(tài)設(shè)計時應(yīng)有狀態(tài)軌跡,方便跟蹤訂單軌跡并記錄相關(guān)日志,萬一出問題時可回溯問題。
比如訂單狀態(tài)的變遷(待支付->待發(fā)貨->已發(fā)貨->完成)。要考慮要不要使用狀態(tài)機來驅(qū)動狀態(tài)的變更和后續(xù)流程節(jié)點操作,尤其當(dāng)狀態(tài)很多的時候使用狀態(tài)機能更好地控制狀態(tài)遷移
考慮并發(fā)狀態(tài)修改問題:一個訂單同時只能有一個修改、狀態(tài)變更的有序性、時間差
后臺系統(tǒng)操作可反饋
后臺系統(tǒng)審計化
文檔和注釋
備份
負載均衡與反向代理
四層負載均衡:首先DNS解析到LVS/F5,然后LVS/F5轉(zhuǎn)發(fā)給Nginx,再由Nginx轉(zhuǎn)發(fā)給后端Real Server
兩層負載均衡是通過改寫報文的目標(biāo)MAC地址為上游服務(wù)器MAC地址,源IP和目標(biāo)IP地址是沒有改變的,負載均衡服務(wù)器和真實服務(wù)器共享同一個VIP,如LVS DR工作模式。
四層負載均衡是根據(jù)端口將報文轉(zhuǎn)發(fā)到上游服務(wù)器(不同的IP地址+端口),如LVS NAT模式、HaProxy。
七層負載均衡是根據(jù)端口號和應(yīng)用層協(xié)議如HTTP協(xié)議的主機名、URL,轉(zhuǎn)發(fā)報文到上游服務(wù)器(不同的IP地址+端口),如HaProxy、Nginx
上游服務(wù)器配置:使用upstream server配置上游服務(wù)器
IP地址和端口
權(quán)重
負載均衡算法:
round-robin輪循
ip_hash
hash key [consistent]:對某一key進行哈希或使用一致性哈希算法
哈希算法:根據(jù)請求uri進行負載均衡,可以使用nginx變量
least_conn
失敗重試機制:配置當(dāng)超時或上游服務(wù)器不存活時,是否需要重試其他上游服務(wù)器
服務(wù)器心跳檢查
TCP心跳檢查
HTTP心跳檢查
隔離
線程隔離:主要是指線程池隔離,實際使用時,會把請求分類,然后交給不同的線程池處理。當(dāng)一種業(yè)務(wù)的請求處理發(fā)生問題時,不會將故障擴散到其他線程池,從而保證其他服務(wù)可用。
進程隔離:過渡方案,較好的解決方案是將系統(tǒng)拆分為多個子系統(tǒng)來實現(xiàn)物理隔離
集群隔離
機房隔離
讀寫隔離:通過主從模式將讀和寫集群分離
動靜隔離:動態(tài)內(nèi)容和靜態(tài)內(nèi)容隔離,一般應(yīng)將靜態(tài)資源放在CDN上
爬蟲隔離:一種方法通過限流解決;另一種方法是在負載均衡層面將爬蟲路由到單獨集群,從而保證正常流量可用,爬蟲流量盡量可用
熱點隔離:秒殺、搶購。讀熱點可用多級緩存,寫熱點可用緩存+隊列模式削峰
資源隔離
其他:
環(huán)境隔離:測試環(huán)境、預(yù)發(fā)布環(huán)境/灰度環(huán)境、正式環(huán)境
壓測隔離:真實數(shù)據(jù)、壓測數(shù)據(jù)
AB測試:不同用戶提供不同版本的服務(wù)
查詢隔離:簡單、批量、復(fù)雜條件查詢分別路由到不同的集群
Hystrix
在一個分布式系統(tǒng)里,許多依賴不可避免的會調(diào)用失敗,比如超時、異常等,如何能夠保證在一個依賴出問題的情況下,不會導(dǎo)致整體服務(wù)失敗,這個就是Hystrix需要做的事情。Hystrix提供了熔斷、隔離、Fallback、cache、監(jiān)控等功能,能夠在一個、或多個依賴同時出現(xiàn)問題時保證系統(tǒng)依然可用。
servlet3異步化模型:
請求解析和業(yè)務(wù)處理線程池分離
業(yè)務(wù)線程池隔離
業(yè)務(wù)線程池監(jiān)控/運維/降級
限流
限流算法:令牌桶算法、漏桶算法
應(yīng)用級限流:
限流總并發(fā)/連接/請求數(shù)
限制總資源數(shù)
限流某個接口的總并發(fā)/請求數(shù)
限流某個接口的時間窗請求數(shù):Guava
平滑限流某個接口的請求數(shù):Guava RateLimiter
分布式限流:redis+lua、 nginx+lua
接入層線路:該層通常指請求流量的入口,主要目的為負載均衡、非法請求過濾、請求聚合、緩存、降級、限流、A/B測試、服務(wù)質(zhì)量監(jiān)控等
節(jié)流:throttleFirst、throttleLast、throttleWithTimeout
降級
超時與重試機制
回滾機制
事務(wù)回滾:事務(wù)表、消息隊列、補償機制(執(zhí)行/回滾)、TCC模式(預(yù)占/確認/取消)、Sagas模式(拆分事務(wù)+補償機制)實現(xiàn)最終一致性
壓測與預(yù)案
應(yīng)用級緩存
緩存回收策略:
基于空間:到達存儲上限后按策略移除數(shù)據(jù)
基于容量:設(shè)置最大大小,當(dāng)緩存條數(shù)超過時,按策略移除
基于時間:TTL存活期、TTI空閑期
基于Java對象引用:軟引用(適合做緩存,從而當(dāng)JVM堆內(nèi)存不足時也可以回收這些對象)、弱引用(相當(dāng)于軟引用,更短的生命周期)
回收算法:FIFO先進先出、LRU最少使用、LFU最不常用
堆緩存(Gauva Cache, Ehcache 3.x)、堆外緩存(Ehcache 3.x, MapDB 3.X)、磁盤緩存(Ehcache 3.x, MapDB 3.X)、分布式緩存(Redis, Ehcache 3.x + Terracotta server)、多級緩存
緩存使用模板
三個名詞:
SoR:記錄系統(tǒng),或者叫數(shù)據(jù)源
Cache:緩存,是SoR的快照數(shù)據(jù)
回源:即回到數(shù)據(jù)源頭獲取數(shù)據(jù)
Cache-Aside:即業(yè)務(wù)代碼圍繞Cache寫,是由業(yè)務(wù)代碼直接維護緩存。適合用AOP模式去實現(xiàn)。
Cache-As-SoR:即把Cache看做SoR, 所有操作都是對Cache進行,然后Cache再委托給SoR進行真實的讀/寫。即代碼中只能看到Cache的操作,看不到關(guān)于SoR相關(guān)的代碼。- Read-Through:業(yè)務(wù)代碼首先調(diào)用Cache,如果Cache不命中,由Cache回源到SoR,而不是業(yè)務(wù)代碼。使用Read-Through模式,需要配置一個CacheLoader組件用來回源到SoR加載數(shù)據(jù) - Write-Through:被稱為穿透寫/直寫模式 ———— 業(yè)務(wù)代碼首先調(diào)用Cache寫數(shù)據(jù),然后由Cache負責(zé)寫緩存和寫SoR,而不是業(yè)務(wù)代碼。需要配置一個CacheLoaderWriter - Write-Behind:稱之為回寫模式,不同于Write-Through是同步寫SoR與Cache,Write-Behind是異步寫。異步之后可以實現(xiàn)批量寫、合并寫、延時和限流
Copy Pattern
Copy-On-Read在讀時復(fù)制
Copy-On-Write在寫時復(fù)制
HTTP緩存
HTTP緩存:
服務(wù)器端響應(yīng)Last-Modified會在下次請求時,將If-Modified-Since請求頭帶到服務(wù)器端進行文檔是否修改的驗證,如果沒有修改則返回304,瀏覽器可以直接使用緩存內(nèi)容
Cache-Control:max-age和Expires用于決定瀏覽器端內(nèi)容緩存多久,即多久過期。過期后則刪除緩存重新從服務(wù)器端獲取最新的。另外可以用于from cache 場景
HTTP/1.1規(guī)范定義的Cache-Control優(yōu)先級高于HTTP/1.0定義的Expires
HTTP/1.1規(guī)范定義ETag為“被請求變量的實體值”,可簡單理解為文檔內(nèi)容摘要,ETag可用來判斷頁面內(nèi)容是否已經(jīng)被修改過了
HttpClient客戶端緩存:
maxCacheEntries
maxObjectSize
asynchronousWorkersCore/asynchronousWorkersMax/revalidationQueueSize
Nginx HTTP緩存設(shè)置:
expires
if-modified-since
nginx proxy_pass
Nginx代理層緩存:
HTTP模塊配置
proxy_cache配置
多級緩存
應(yīng)用Nginx本地緩存、分布式緩存、Tomcat堆緩存
如何緩存數(shù)據(jù):
過期與不過期:
不過期緩存場景一般思路Cache-Aside模式,1.開啟事務(wù) 2.執(zhí)行SQL 3.提交事務(wù) 4.寫緩存
過期緩存機制,如懶加載,一般用于緩存其他系統(tǒng)的數(shù)據(jù)、緩存空間有限、低頻熱點緩存等場景
維度化緩存與增量緩存:只更新變的部分
大Value緩存:多線程實現(xiàn)緩存、對Value壓縮、拆分Value為多個小Value
熱點緩存:掛更多的從緩存,通過負載均衡機制讀取;客戶端所在應(yīng)用/代理層本地存儲一份
單機全量緩存+主從
分布式緩存+應(yīng)用本地緩存
更新緩存與原子性:
更新數(shù)據(jù)時使用更新時間戳或版本對比,如果使用Redis,則可以使用其單線程機制進行原子化更新
使用如canal訂閱數(shù)據(jù)庫binlog
將更新請求按照相應(yīng)的規(guī)則分散到多個隊列,然后每個隊列進行單線程更新,更新時拉取最新的數(shù)據(jù)保存
用分布式鎖,在更新之前獲取相關(guān)的鎖
連接池/線程池
數(shù)據(jù)庫連接池:C3P0、DBCP、Druid等
HttpClient連接池
線程池:
ThreadPoolExecutor:標(biāo)準(zhǔn)線程池
ScheduledThreadPoolExecutor:支持延遲任務(wù)的線程池
ForkJoinPool:類似于ThreadPoolExecutor,但使用work-stealing模式,會為線程池中每個線程創(chuàng)建一個隊列,從而用work-stealing(任務(wù)竊取)算法使得線程可以從其他線程隊列里竊取任務(wù)來執(zhí)行。
提供ExecutorService三種實現(xiàn):
Executors創(chuàng)建簡單線程池
根據(jù)任務(wù)列型是IO密集型還是CPU密集型、CPU核數(shù),來設(shè)置合理的線程池大小、隊列大小、拒絕策略,并進行壓測和不斷調(diào)優(yōu)來決定適合自己場景的參數(shù)
Tomcat線程池
異步并發(fā)
異步Web服務(wù)實現(xiàn):
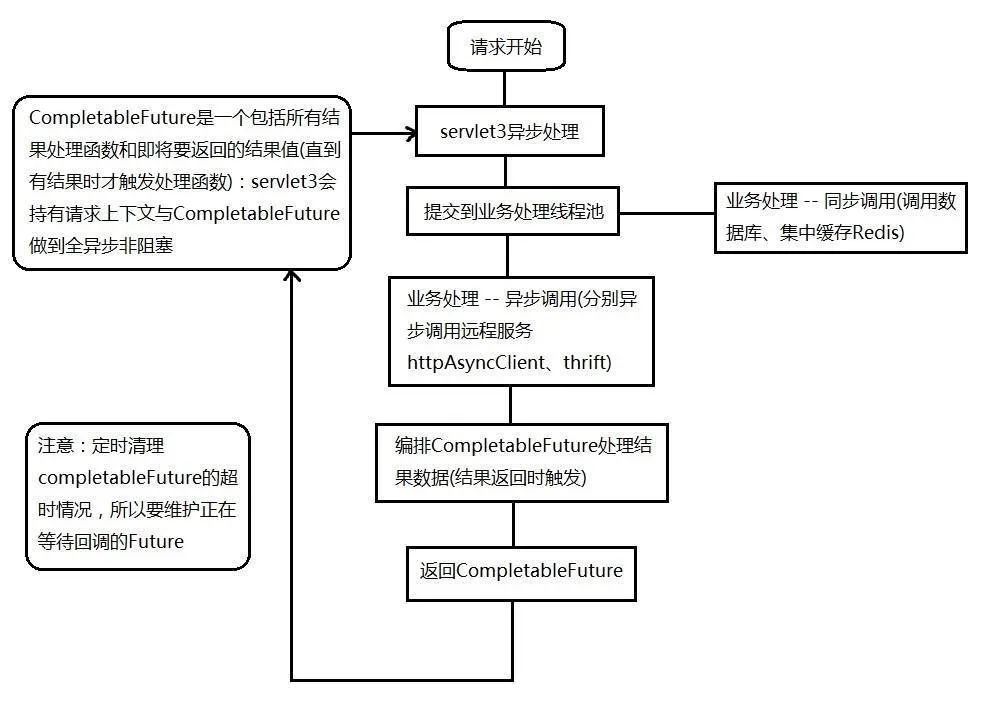
如何擴容
隊列
案例
OpenResty
souce: https://zhouj000.github.io/2018/06/25/coreTechnologyOfWebArchitecture-kaitao/
喜歡,在看