面試官:談談你是怎么理解緩存的?

下面我結(jié)合自己使用緩存的歷程,談談我對緩存的認識。
01?本地緩存
1. 頁面級緩存
我使用緩存的時間很早,2010年左右使用過 OSCache,當時主要用在 JSP 頁面中用于實現(xiàn)頁面級緩存。偽代碼類似這樣:
"foobar" ??????some jsp?content?
中間的那段 JSP 代碼將會以 key="foobar" 緩存在 session 中,這樣其他頁面就能共享這段緩存內(nèi)容。在使用 JSP 這種遠古技術(shù)的場景下,通過引入 OSCache 之后 ,頁面的加載速度確實提升很快。
但隨著前后端分離以及分布式緩存的興起,服務端的頁面級緩存已經(jīng)很少使用了。但是在前端領(lǐng)域,頁面級緩存仍然很流行。
2. 對象緩存
2011年左右,開源中國的紅薯哥寫了很多篇關(guān)于緩存的文章。他提到:開源中國每天百萬的動態(tài)請求,只用 1 臺 4 Core 8G 的服務器就扛住了,得益于緩存框架 Ehcache。
這讓我非常神往,一個簡單的框架竟能將單機性能做到如此這般,讓我欲欲躍試。于是,我參考紅薯哥的示例代碼,在公司的余額提現(xiàn)服務上第一次使用了 Ehcache。
邏輯也很簡單,就是將成功或者失敗狀態(tài)的訂單緩存起來,這樣下次查詢的時候,不用再查詢支付寶服務了。偽代碼類似這樣:
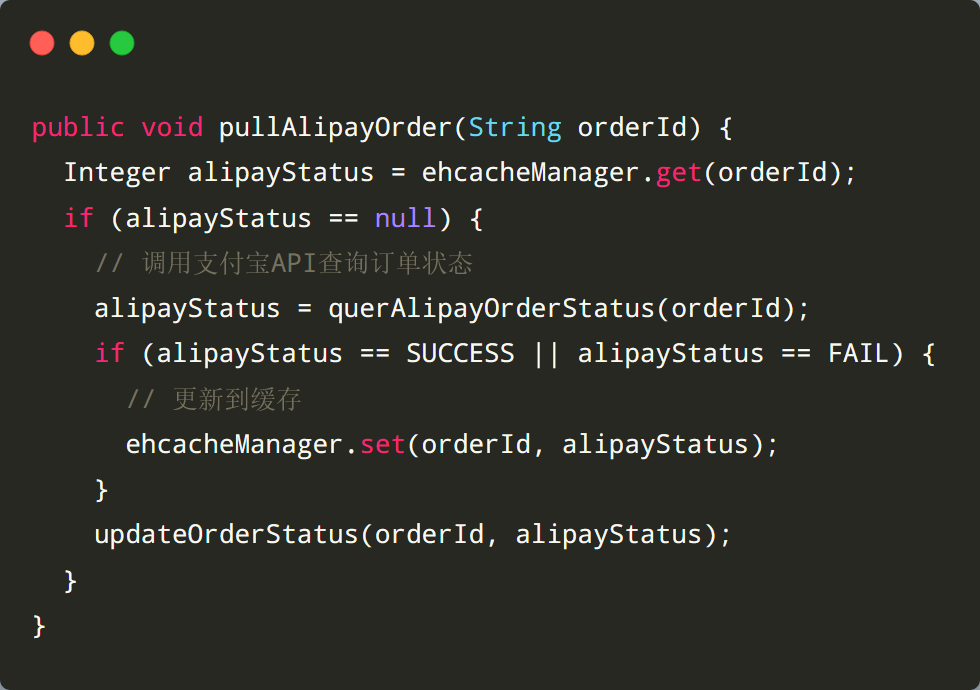
添加緩存之后,優(yōu)化的效果很明顯 , 任務耗時從原來的40分鐘減少到了5~10分鐘。
上面這個示例就是典型的「對象緩存」,它是本地緩存最常見的應用場景。相比頁面緩存,它的粒度更細、更靈活,常用來緩存很少變化的數(shù)據(jù),比如:全局配置、狀態(tài)已完結(jié)的訂單等,用于提升整體的查詢速度。
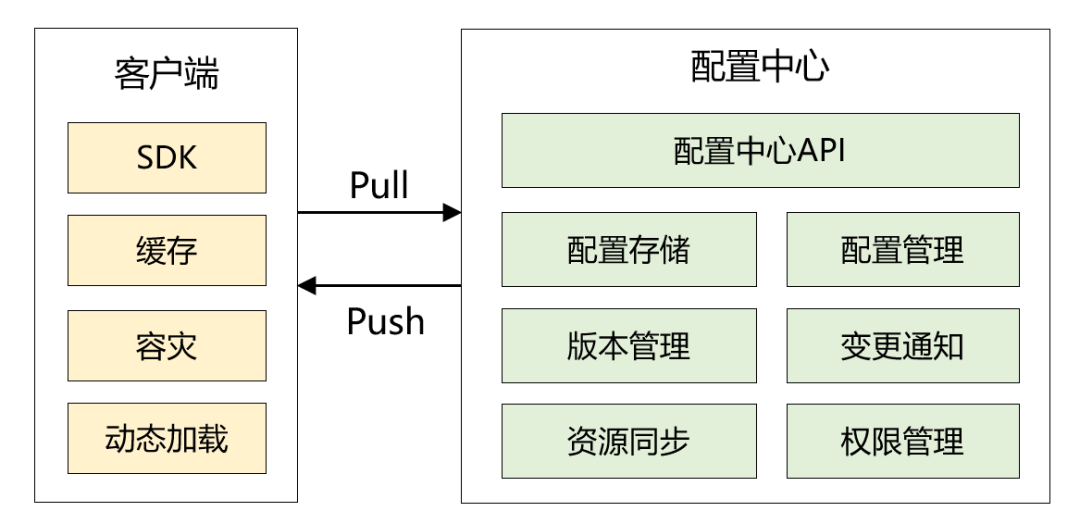
客戶端啟動定時任務,從配置中心拉取數(shù)據(jù)。 當配置中心有數(shù)據(jù)變化時,主動推送給客戶端。這里我并沒有使用websocket,而是使用了 RocketMQ Remoting 通訊框架。
pull 模式必不可少 增量推送大同小異
02 分布式緩存
關(guān)于分布式緩存, memcached 和 Redis 應該是最常用的技術(shù)選型。相信程序員朋友都非常熟悉了,我這里分享兩個案例。
1.? 合理控制對象大小及讀取策略
2013年,我服務一家彩票公司,我們的比分直播模塊也用到了分布式緩存。當時,遇到了一個 Young GC 頻繁的線上問題,通過 jstat 工具排查后,發(fā)現(xiàn)新生代每隔兩秒就被占滿了。
進一步定位分析,原來是某些 key 緩存的 value 太大了,平均在 300K左右,最大的達到了500K。這樣在高并發(fā)下,就很容易導致 GC 頻繁。
找到了根本原因后,具體怎么改呢?我當時也沒有清晰的思路。于是,我去同行的網(wǎng)站上研究他們是怎么實現(xiàn)相同功能的,包括:360彩票,澳客網(wǎng)。我發(fā)現(xiàn)了兩點:
1、數(shù)據(jù)格式非常精簡,只返回給前端必要的數(shù)據(jù),部分數(shù)據(jù)通過數(shù)組的方式返回 2、使用 websocket,進入頁面后推送全量數(shù)據(jù),數(shù)據(jù)發(fā)生變化推送增量數(shù)據(jù)
[{"playId":"2399","guestTeamName":"小牛","hostTeamName":"湖人","europe":"123"}]
[["2399","小牛","湖人","123"]]2.? 分頁列表查詢
列表如何緩存是我非常渴望和大家分享的技能點。這個知識點也是我 2012 年從開源中國上學到的,下面我以「查詢博客列表」的場景為例。
我們先說第 1 種方案:對分頁內(nèi)容進行整體緩存。這種方案會按照頁碼和每頁大小組合成一個緩存key,緩存值就是博客信息列表。假如某一個博客內(nèi)容發(fā)生修改, 我們要重新加載緩存,或者刪除整頁的緩存。
這種方案,緩存的顆粒度比較大,如果博客更新較為頻繁,則緩存很容易失效。下面我介紹下第 2 種方案:僅對博客進行緩存。流程大致如下:
1)先從數(shù)據(jù)庫查詢當前頁的博客id列表,sql類似:
select?id?from?blogs?limit?0,10?2)批量從緩存中獲取博客id列表對應的緩存數(shù)據(jù) ,并記錄沒有命中的博客id,若沒有命中的id列表大于0,再次從數(shù)據(jù)庫中查詢一次,并放入緩存,sql類似:
select?id?from?blogs?where?id?in?(noHitId1,?noHitId2)3)將沒有緩存的博客對象存入緩存中
4)返回博客對象列表
理論上,要是緩存都預熱的情況下,一次簡單的數(shù)據(jù)庫查詢,一次緩存批量獲取,即可返回所有的數(shù)據(jù)。另外,關(guān)于緩存批量獲取,如何實現(xiàn)?
本地緩存:性能極高,for 循環(huán)即可
memcached:使用 mget 命令
Redis:若緩存對象結(jié)構(gòu)簡單,使用 mget 、hmget命令;若結(jié)構(gòu)復雜,可以考慮使用 pipleline,lua腳本模式
第 1 種方案適用于數(shù)據(jù)極少發(fā)生變化的場景,比如排行榜,首頁新聞資訊等。
第 2 種方案適用于大部分的分頁場景,而且能和其他資源整合在一起。舉例:在搜索系統(tǒng)里,我們可以通過篩選條件查詢出博客 id 列表,然后通過如上的方式,快速獲取博客列表。
03 多級緩存
首先要明確為什么要使用多級緩存?
本地緩存速度極快,但是容量有限,而且無法共享內(nèi)存。分布式緩存容量可擴展,但在高并發(fā)場景下,如果所有數(shù)據(jù)都必須從遠程緩存種獲取,很容易導致帶寬跑滿,吞吐量下降。
有句話說得好,緩存離用戶越近越高效!
使用多級緩存的好處在于:高并發(fā)場景下, 能提升整個系統(tǒng)的吞吐量,減少分布式緩存的壓力。
2018年,我服務的一家電商公司需要進行 app 首頁接口的性能優(yōu)化。我花了大概兩天的時間完成了整個方案,采取的是兩級緩存模式,同時利用了 guava 的惰性加載機制,整體架構(gòu)如下圖所示:
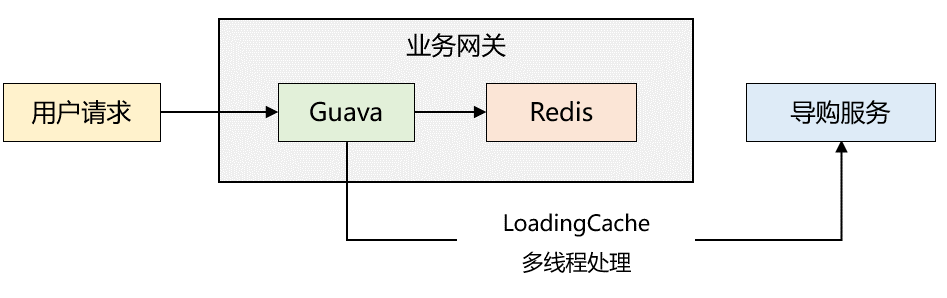
優(yōu)化后,性能表現(xiàn)很好,平均耗時在 5ms 左右。最開始我以為出現(xiàn)問題的幾率很小,可是有一天晚上,突然發(fā)現(xiàn) app 端首頁顯示的數(shù)據(jù)時而相同,時而不同。
也就是說:?雖然 LoadingCache 線程一直在調(diào)用接口更新緩存信息,但是各個服務器本地緩存中的數(shù)據(jù)并非完成一致。說明了兩個很重要的點:?
1、惰性加載仍然可能造成多臺機器的數(shù)據(jù)不一致
2、 LoadingCache 線程池數(shù)量配置的不太合理,? 導致了線程堆積
最終,我們的解決方案是:
1、惰性加載結(jié)合消息機制來更新緩存數(shù)據(jù),也就是:當導購服務的配置發(fā)生變化時,通知業(yè)務網(wǎng)關(guān)重新拉取數(shù)據(jù),更新緩存。
2、適當調(diào)大 LoadigCache 的線程池參數(shù),并在線程池埋點,監(jiān)控線程池的使用情況,當線程繁忙時能發(fā)出告警,然后動態(tài)修改線程池參數(shù)。
緩存是非常重要的一個技術(shù)手段。如果能從原理到實踐,不斷深入地去掌握它,這應該是技術(shù)人員最享受的事情。
我想我更應該和朋友交流的是:如何體系化的學習一門新技術(shù)。
選擇該技術(shù)的經(jīng)典書籍,理解基礎(chǔ)概念? 建立該技術(shù)的知識脈絡(luò)? 知行合一,在生產(chǎn)環(huán)境中實踐或者自己造輪子 不斷復盤,思考是否有更優(yōu)的方案
推薦閱讀:
 喜歡我可以給我設(shè)為星標哦
喜歡我可以給我設(shè)為星標哦