
京東面試官:你是怎么理解 MySQL 的優(yōu)化原理的?
MySQL邏輯架構(gòu)
如果能在頭腦中構(gòu)建一幅MySQL各組件之間如何協(xié)同工作的架構(gòu)圖,有助于深入理解MySQL服務(wù)器。下圖展示了MySQL的邏輯架構(gòu)圖。
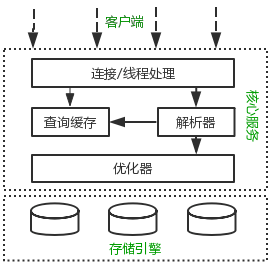
MySQL邏輯架構(gòu)整體分為三層,最上層為客戶端層,并非MySQL所獨(dú)有,諸如:連接處理、授權(quán)認(rèn)證、安全等功能均在這一層處理。
MySQL大多數(shù)核心服務(wù)均在中間這一層,包括查詢解析、分析、優(yōu)化、緩存、內(nèi)置函數(shù)(比如:時(shí)間、數(shù)學(xué)、加密等函數(shù))。所有的跨存儲(chǔ)引擎的功能也在這一層實(shí)現(xiàn):存儲(chǔ)過(guò)程、觸發(fā)器、視圖等。
最下層為存儲(chǔ)引擎,其負(fù)責(zé)MySQL中的數(shù)據(jù)存儲(chǔ)和提取。和Linux下的文件系統(tǒng)類似,每種存儲(chǔ)引擎都有其優(yōu)勢(shì)和劣勢(shì)。中間的服務(wù)層通過(guò)API與存儲(chǔ)引擎通信,這些API接口屏蔽了不同存儲(chǔ)引擎間的差異。
MySQL查詢過(guò)程
我們總是希望MySQL能夠獲得更高的查詢性能,最好的辦法是弄清楚MySQL是如何優(yōu)化和執(zhí)行查詢的。一旦理解了這一點(diǎn),就會(huì)發(fā)現(xiàn):很多的查詢優(yōu)化工作實(shí)際上就是遵循一些原則讓MySQL的優(yōu)化器能夠按照預(yù)想的合理方式運(yùn)行而已。
當(dāng)向MySQL發(fā)送一個(gè)請(qǐng)求的時(shí)候,MySQL到底做了些什么呢?
客戶端/服務(wù)端通信協(xié)議
MySQL客戶端/服務(wù)端通信協(xié)議是“半雙工”的:在任一時(shí)刻,要么是服務(wù)器向客戶端發(fā)送數(shù)據(jù),要么是客戶端向服務(wù)器發(fā)送數(shù)據(jù),這兩個(gè)動(dòng)作不能同時(shí)發(fā)生。一旦一端開(kāi)始發(fā)送消息,另一端要接收完整個(gè)消息才能響應(yīng)它,所以我們無(wú)法也無(wú)須將一個(gè)消息切成小塊獨(dú)立發(fā)送,也沒(méi)有辦法進(jìn)行流量控制。
客戶端用一個(gè)單獨(dú)的數(shù)據(jù)包將查詢請(qǐng)求發(fā)送給服務(wù)器,所以當(dāng)查詢語(yǔ)句很長(zhǎng)的時(shí)候,需要設(shè)置 max_allowed_packet參數(shù)。但是需要注意的是,如果查詢實(shí)在是太大,服務(wù)端會(huì)拒絕接收更多數(shù)據(jù)并拋出異常。
與之相反的是,服務(wù)器響應(yīng)給用戶的數(shù)據(jù)通常會(huì)很多,由多個(gè)數(shù)據(jù)包組成。但是當(dāng)服務(wù)器響應(yīng)客戶端請(qǐng)求時(shí),客戶端必須完整的接收整個(gè)返回結(jié)果,而不能簡(jiǎn)單的只取前面幾條結(jié)果,然后讓服務(wù)器停止發(fā)送。因而在實(shí)際開(kāi)發(fā)中,盡量保持查詢簡(jiǎn)單且只返回必需的數(shù)據(jù),減小通信間數(shù)據(jù)包的大小和數(shù)量是一個(gè)非常好的習(xí)慣,這也是查詢中盡量避免使用 SELECT*以及加上 LIMIT限制的原因之一。
查詢緩存
在解析一個(gè)查詢語(yǔ)句前,如果查詢緩存是打開(kāi)的,那么MySQL會(huì)檢查這個(gè)查詢語(yǔ)句是否命中查詢緩存中的數(shù)據(jù)。如果當(dāng)前查詢恰好命中查詢緩存,在檢查一次用戶權(quán)限后直接返回緩存中的結(jié)果。這種情況下,查詢不會(huì)被解析,也不會(huì)生成執(zhí)行計(jì)劃,更不會(huì)執(zhí)行。
MySQL將緩存存放在一個(gè)引用表(不要理解成 table,可以認(rèn)為是類似于 HashMap的數(shù)據(jù)結(jié)構(gòu)),通過(guò)一個(gè)哈希值索引,這個(gè)哈希值通過(guò)查詢本身、當(dāng)前要查詢的數(shù)據(jù)庫(kù)、客戶端協(xié)議版本號(hào)等一些可能影響結(jié)果的信息計(jì)算得來(lái)。所以兩個(gè)查詢?cè)谌魏巫址系牟煌ɡ纾嚎崭瘛⒆⑨專紩?huì)導(dǎo)致緩存不會(huì)命中。
如果查詢中包含任何用戶自定義函數(shù)、存儲(chǔ)函數(shù)、用戶變量、臨時(shí)表、mysql庫(kù)中的系統(tǒng)表,其查詢結(jié)果 都不會(huì)被緩存。比如函數(shù) NOW()或者 CURRENT_DATE()會(huì)因?yàn)椴煌牟樵儠r(shí)間,返回不同的查詢結(jié)果,再比如包含 CURRENT_USER或者 CONNECION_ID()的查詢語(yǔ)句會(huì)因?yàn)椴煌挠脩舳祷夭煌慕Y(jié)果,將這樣的查詢結(jié)果緩存起來(lái)沒(méi)有任何的意義。
既然是緩存,就會(huì)失效,那查詢緩存何時(shí)失效呢?MySQL的查詢緩存系統(tǒng)會(huì)跟蹤查詢中涉及的每個(gè)表,如果這些表(數(shù)據(jù)或結(jié)構(gòu))發(fā)生變化,那么和這張表相關(guān)的所有緩存數(shù)據(jù)都將失效。正因?yàn)槿绱耍谌魏蔚膶?xiě)操作時(shí),MySQL必須將對(duì)應(yīng)表的所有緩存都設(shè)置為失效。如果查詢緩存非常大或者碎片很多,這個(gè)操作就可能帶來(lái)很大的系統(tǒng)消耗,甚至導(dǎo)致系統(tǒng)僵死一會(huì)兒。而且查詢緩存對(duì)系統(tǒng)的額外消耗也不僅僅在寫(xiě)操作,讀操作也不例外:
任何的查詢語(yǔ)句在開(kāi)始之前都必須經(jīng)過(guò)檢查,即使這條SQL語(yǔ)句永遠(yuǎn)不會(huì)命中緩存
如果查詢結(jié)果可以被緩存,那么執(zhí)行完成后,會(huì)將結(jié)果存入緩存,也會(huì)帶來(lái)額外的系統(tǒng)消耗
基于此,我們要知道并不是什么情況下查詢緩存都會(huì)提高系統(tǒng)性能,緩存和失效都會(huì)帶來(lái)額外消耗,只有當(dāng)緩存帶來(lái)的資源節(jié)約大于其本身消耗的資源時(shí),才會(huì)給系統(tǒng)帶來(lái)性能提升。但要如何評(píng)估打開(kāi)緩存是否能夠帶來(lái)性能提升是一件非常困難的事情,也不在本文討論的范疇內(nèi)。如果系統(tǒng)確實(shí)存在一些性能問(wèn)題,可以嘗試打開(kāi)查詢緩存,并在數(shù)據(jù)庫(kù)設(shè)計(jì)上做一些優(yōu)化,比如:
用多個(gè)小表代替一個(gè)大表,注意不要過(guò)度設(shè)計(jì) 批量插入代替循環(huán)單條插入 合理控制緩存空間大小,一般來(lái)說(shuō)其大小設(shè)置為幾十兆比較合適 可以通過(guò) SQL_CACHE和 SQL_NO_CACHE來(lái)控制某個(gè)查詢語(yǔ)句是否需要進(jìn)行緩存
最后的忠告是不要輕易打開(kāi)查詢緩存,特別是寫(xiě)密集型應(yīng)用。如果你實(shí)在是忍不住,可以將 query_cache_type設(shè)置為 DEMAND,這時(shí)只有加入 SQL_CACHE的查詢才會(huì)走緩存,其他查詢則不會(huì),這樣可以非常自由地控制哪些查詢需要被緩存。
當(dāng)然查詢緩存系統(tǒng)本身是非常復(fù)雜的,這里討論的也只是很小的一部分,其他更深入的話題,比如:緩存是如何使用內(nèi)存的?如何控制內(nèi)存的碎片化?事務(wù)對(duì)查詢緩存有何影響等等,讀者可以自行閱讀相關(guān)資料,這里權(quán)當(dāng)拋磚引玉吧。
語(yǔ)法解析和預(yù)處理
MySQL通過(guò)關(guān)鍵字將SQL語(yǔ)句進(jìn)行解析,并生成一顆對(duì)應(yīng)的解析樹(shù)。這個(gè)過(guò)程解析器主要通過(guò)語(yǔ)法規(guī)則來(lái)驗(yàn)證和解析。比如SQL中是否使用了錯(cuò)誤的關(guān)鍵字或者關(guān)鍵字的順序是否正確等等。預(yù)處理則會(huì)根據(jù)MySQL規(guī)則進(jìn)一步檢查解析樹(shù)是否合法。比如檢查要查詢的數(shù)據(jù)表和數(shù)據(jù)列是否存在等等。
查詢優(yōu)化
經(jīng)過(guò)前面的步驟生成的語(yǔ)法樹(shù)被認(rèn)為是合法的了,并且由優(yōu)化器將其轉(zhuǎn)化成查詢計(jì)劃。多數(shù)情況下,一條查詢可以有很多種執(zhí)行方式,最后都返回相應(yīng)的結(jié)果。優(yōu)化器的作用就是找到這其中最好的執(zhí)行計(jì)劃。
select * from t_message limit 10;...省略結(jié)果集mysql> show status like 'last_query_cost';+-----------------+-------------+| Variable_name | Value |+-----------------+-------------+| Last_query_cost | 6391.799000 |+-----------------+-------------+
示例中的結(jié)果表示優(yōu)化器認(rèn)為大概需要做6391個(gè)數(shù)據(jù)頁(yè)的隨機(jī)查找才能完成上面的查詢。這個(gè)結(jié)果是根據(jù)一些列的統(tǒng)計(jì)信息計(jì)算得來(lái)的,這些統(tǒng)計(jì)信息包括:每張表或者索引的頁(yè)面?zhèn)€數(shù)、索引的基數(shù)、索引和數(shù)據(jù)行的長(zhǎng)度、索引的分布情況等等。
有非常多的原因會(huì)導(dǎo)致MySQL選擇錯(cuò)誤的執(zhí)行計(jì)劃,比如統(tǒng)計(jì)信息不準(zhǔn)確、不會(huì)考慮不受其控制的操作成本(用戶自定義函數(shù)、存儲(chǔ)過(guò)程)、MySQL認(rèn)為的最優(yōu)跟我們想的不一樣(我們希望執(zhí)行時(shí)間盡可能短,但MySQL值選擇它認(rèn)為成本小的,但成本小并不意味著執(zhí)行時(shí)間短)等等。
MySQL的查詢優(yōu)化器是一個(gè)非常復(fù)雜的部件,它使用了非常多的優(yōu)化策略來(lái)生成一個(gè)最優(yōu)的執(zhí)行計(jì)劃:
重新定義表的關(guān)聯(lián)順序(多張表關(guān)聯(lián)查詢時(shí),并不一定按照SQL中指定的順序進(jìn)行,但有一些技巧可以指定關(guān)聯(lián)順序) 優(yōu)化 MIN()和 MAX()函數(shù)(找某列的最小值,如果該列有索引,只需要查找B+Tree索引最左端,反之則可以找到最大值,具體原理見(jiàn)下文) 提前終止查詢(比如:使用Limit時(shí),查找到滿足數(shù)量的結(jié)果集后會(huì)立即終止查詢) 優(yōu)化排序(在老版本MySQL會(huì)使用兩次傳輸排序,即先讀取行指針和需要排序的字段在內(nèi)存中對(duì)其排序,然后再根據(jù)排序結(jié)果去讀取數(shù)據(jù)行,而新版本采用的是單次傳輸排序,也就是一次讀取所有的數(shù)據(jù)行,然后根據(jù)給定的列排序。對(duì)于I/O密集型應(yīng)用,效率會(huì)高很多)
隨著MySQL的不斷發(fā)展,優(yōu)化器使用的優(yōu)化策略也在不斷的進(jìn)化,這里僅僅介紹幾個(gè)非常常用且容易理解的優(yōu)化策略,其他的優(yōu)化策略,大家自行查閱吧。
查詢執(zhí)行引擎
在完成解析和優(yōu)化階段以后,MySQL會(huì)生成對(duì)應(yīng)的執(zhí)行計(jì)劃,查詢執(zhí)行引擎根據(jù)執(zhí)行計(jì)劃給出的指令逐步執(zhí)行得出結(jié)果。整個(gè)執(zhí)行過(guò)程的大部分操作均是通過(guò)調(diào)用存儲(chǔ)引擎實(shí)現(xiàn)的接口來(lái)完成,這些接口被稱為 handler API。查詢過(guò)程中的每一張表由一個(gè) handler實(shí)例表示。實(shí)際上,MySQL在查詢優(yōu)化階段就為每一張表創(chuàng)建了一個(gè) handler實(shí)例,優(yōu)化器可以根據(jù)這些實(shí)例的接口來(lái)獲取表的相關(guān)信息,包括表的所有列名、索引統(tǒng)計(jì)信息等。存儲(chǔ)引擎接口提供了非常豐富的功能,但其底層僅有幾十個(gè)接口,這些接口像搭積木一樣完成了一次查詢的大部分操作。
返回結(jié)果給客戶端
查詢執(zhí)行的最后一個(gè)階段就是將結(jié)果返回給客戶端。即使查詢不到數(shù)據(jù),MySQL仍然會(huì)返回這個(gè)查詢的相關(guān)信息,比如改查詢影響到的行數(shù)以及執(zhí)行時(shí)間等等。
如果查詢緩存被打開(kāi)且這個(gè)查詢可以被緩存,MySQL也會(huì)將結(jié)果存放到緩存中。
結(jié)果集返回客戶端是一個(gè)增量且逐步返回的過(guò)程。有可能MySQL在生成第一條結(jié)果時(shí),就開(kāi)始向客戶端逐步返回結(jié)果集了。這樣服務(wù)端就無(wú)須存儲(chǔ)太多結(jié)果而消耗過(guò)多內(nèi)存,也可以讓客戶端第一時(shí)間獲得返回結(jié)果。需要注意的是,結(jié)果集中的每一行都會(huì)以一個(gè)滿足①中所描述的通信協(xié)議的數(shù)據(jù)包發(fā)送,再通過(guò)TCP協(xié)議進(jìn)行傳輸,在傳輸過(guò)程中,可能對(duì)MySQL的數(shù)據(jù)包進(jìn)行緩存然后批量發(fā)送。
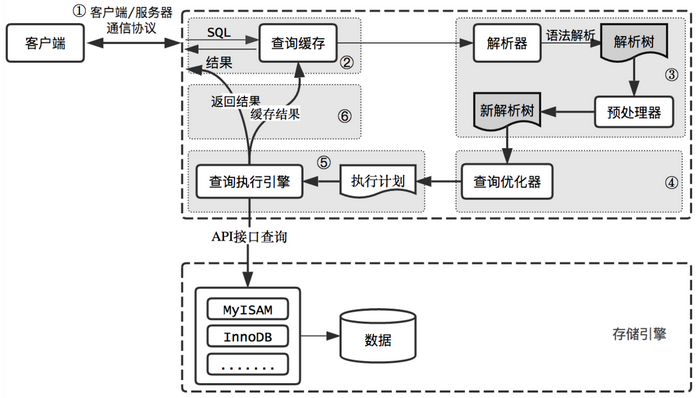
回頭總結(jié)一下MySQL整個(gè)查詢執(zhí)行過(guò)程,總的來(lái)說(shuō)分為6個(gè)步驟:
客戶端向MySQL服務(wù)器發(fā)送一條查詢請(qǐng)求 服務(wù)器首先檢查查詢緩存,如果命中緩存,則立刻返回存儲(chǔ)在緩存中的結(jié)果。否則進(jìn)入下一階段 服務(wù)器進(jìn)行SQL解析、預(yù)處理、再由優(yōu)化器生成對(duì)應(yīng)的執(zhí)行計(jì)劃 MySQL根據(jù)執(zhí)行計(jì)劃,調(diào)用存儲(chǔ)引擎的API來(lái)執(zhí)行查詢 將結(jié)果返回給客戶端,同時(shí)緩存查詢結(jié)果
性能優(yōu)化建議
Scheme設(shè)計(jì)與數(shù)據(jù)類型優(yōu)化
選擇數(shù)據(jù)類型只要遵循小而簡(jiǎn)單的原則就好,越小的數(shù)據(jù)類型通常會(huì)更快,占用更少的磁盤(pán)、內(nèi)存,處理時(shí)需要的CPU周期也更少。越簡(jiǎn)單的數(shù)據(jù)類型在計(jì)算時(shí)需要更少的CPU周期,比如,整型就比字符操作代價(jià)低,因而會(huì)使用整型來(lái)存儲(chǔ)ip地址,使用 DATETIME來(lái)存儲(chǔ)時(shí)間,而不是使用字符串。
這里總結(jié)幾個(gè)可能容易理解錯(cuò)誤的技巧:
通常來(lái)說(shuō)把可為 NULL的列改為 NOT NULL不會(huì)對(duì)性能提升有多少幫助,只是如果計(jì)劃在列上創(chuàng)建索引,就應(yīng)該將該列設(shè)置為 NOT NULL。
對(duì)整數(shù)類型指定寬度,比如 INT(11),沒(méi)有任何卵用。INT使用32位(4個(gè)字節(jié))存儲(chǔ)空間,那么它的表示范圍已經(jīng)確定,所以 INT(1)和 INT(20)對(duì)于存儲(chǔ)和計(jì)算是相同的。
UNSIGNED表示不允許負(fù)值,大致可以使正數(shù)的上限提高一倍。比如 TINYINT存儲(chǔ)范圍是-128 ~ 127,而 UNSIGNED TINYINT存儲(chǔ)的范圍卻是0 - 255。
通常來(lái)講,沒(méi)有太大的必要使用 DECIMAL數(shù)據(jù)類型。即使是在需要存儲(chǔ)財(cái)務(wù)數(shù)據(jù)時(shí),仍然可以使用 BIGINT。比如需要精確到萬(wàn)分之一,那么可以將數(shù)據(jù)乘以一百萬(wàn)然后使用 BIGINT存儲(chǔ)。這樣可以避免浮點(diǎn)數(shù)計(jì)算不準(zhǔn)確和 DECIMAL精確計(jì)算代價(jià)高的問(wèn)題。
TIMESTAMP使用4個(gè)字節(jié)存儲(chǔ)空間, DATETIME使用8個(gè)字節(jié)存儲(chǔ)空間。因而, TIMESTAMP只能表示1970 - 2038年,比 DATETIME表示的范圍小得多,而且 TIMESTAMP的值因時(shí)區(qū)不同而不同。
大多數(shù)情況下沒(méi)有使用枚舉類型的必要,其中一個(gè)缺點(diǎn)是枚舉的字符串列表是固定的,添加和刪除字符串(枚舉選項(xiàng))必須使用 ALTER TABLE(如果只只是在列表末尾追加元素,不需要重建表)。
schema的列不要太多。原因是存儲(chǔ)引擎的API工作時(shí)需要在服務(wù)器層和存儲(chǔ)引擎層之間通過(guò)行緩沖格式拷貝數(shù)據(jù),然后在服務(wù)器層將緩沖內(nèi)容解碼成各個(gè)列,這個(gè)轉(zhuǎn)換過(guò)程的代價(jià)是非常高的。如果列太多而實(shí)際使用的列又很少的話,有可能會(huì)導(dǎo)致CPU占用過(guò)高。
大表 ALTER TABLE非常耗時(shí),MySQL執(zhí)行大部分修改表結(jié)果操作的方法是用新的結(jié)構(gòu)創(chuàng)建一個(gè)張空表,從舊表中查出所有的數(shù)據(jù)插入新表,然后再刪除舊表。尤其當(dāng)內(nèi)存不足而表又很大,而且還有很大索引的情況下,耗時(shí)更久。當(dāng)然有一些奇淫技巧可以解決這個(gè)問(wèn)題,有興趣可自行查閱。
創(chuàng)建高性能索引
索引是提高M(jìn)ySQL查詢性能的一個(gè)重要途徑,但過(guò)多的索引可能會(huì)導(dǎo)致過(guò)高的磁盤(pán)使用率以及過(guò)高的內(nèi)存占用,從而影響應(yīng)用程序的整體性能。應(yīng)當(dāng)盡量避免事后才想起添加索引,因?yàn)槭潞罂赡苄枰O(jiān)控大量的SQL才能定位到問(wèn)題所在,而且添加索引的時(shí)間肯定是遠(yuǎn)大于初始添加索引所需要的時(shí)間,可見(jiàn)索引的添加也是非常有技術(shù)含量的。
接下來(lái)將向你展示一系列創(chuàng)建高性能索引的策略,以及每條策略其背后的工作原理。但在此之前,先了解與索引相關(guān)的一些算法和數(shù)據(jù)結(jié)構(gòu),將有助于更好的理解后文的內(nèi)容。
索引相關(guān)的數(shù)據(jù)結(jié)構(gòu)和算法
通常我們所說(shuō)的索引是指 B-Tree索引,它是目前關(guān)系型數(shù)據(jù)庫(kù)中查找數(shù)據(jù)最為常用和有效的索引,大多數(shù)存儲(chǔ)引擎都支持這種索引。使用 B-Tree這個(gè)術(shù)語(yǔ),是因?yàn)镸ySQL在 CREATE TABLE或其它語(yǔ)句中使用了這個(gè)關(guān)鍵字,但實(shí)際上不同的存儲(chǔ)引擎可能使用不同的數(shù)據(jù)結(jié)構(gòu),比如InnoDB就是使用的 B+Tree。
B+Tree中的B是指 balance,意為平衡。需要注意的是,B+樹(shù)索引并不能找到一個(gè)給定鍵值的具體行,它找到的只是被查找數(shù)據(jù)行所在的頁(yè),接著數(shù)據(jù)庫(kù)會(huì)把頁(yè)讀入到內(nèi)存,再在內(nèi)存中進(jìn)行查找,最后得到要查找的數(shù)據(jù)。
在介紹 B+Tree前,先了解一下二叉查找樹(shù),它是一種經(jīng)典的數(shù)據(jù)結(jié)構(gòu),其左子樹(shù)的值總是小于根的值,右子樹(shù)的值總是大于根的值,如下圖①。如果要在這課樹(shù)中查找值為5的記錄,其大致流程:先找到根,其值為6,大于5,所以查找左子樹(shù),找到3,而5大于3,接著找3的右子樹(shù),總共找了3次。同樣的方法,如果查找值為8的記錄,也需要查找3次。所以二叉查找樹(shù)的平均查找次數(shù)為(3 + 3 + 3 + 2 + 2 + 1) / 6 = 2.3次,而順序查找的話,查找值為2的記錄,僅需要1次,但查找值為8的記錄則需要6次,所以順序查找的平均查找次數(shù)為:(1 + 2 + 3 + 4 + 5 + 6) / 6 = 3.3次,因?yàn)榇蠖鄶?shù)情況下二叉查找樹(shù)的平均查找速度比順序查找要快。
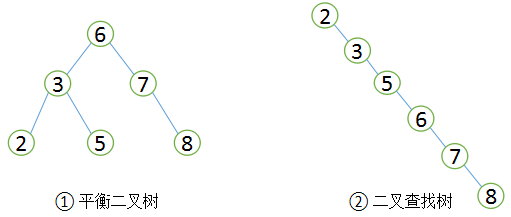
由于二叉查找樹(shù)可以任意構(gòu)造,同樣的值,可以構(gòu)造出如圖②的二叉查找樹(shù),顯然這棵二叉樹(shù)的查詢效率和順序查找差不多。若想二叉查找數(shù)的查詢性能最高,需要這棵二叉查找樹(shù)是平衡的,也即平衡二叉樹(shù)(AVL樹(shù))。
平衡二叉樹(shù)首先需要符合二叉查找樹(shù)的定義,其次必須滿足任何節(jié)點(diǎn)的兩個(gè)子樹(shù)的高度差不能大于1。顯然圖②不滿足平衡二叉樹(shù)的定義,而圖①是一課平衡二叉樹(shù)。平衡二叉樹(shù)的查找性能是比較高的(性能最好的是最優(yōu)二叉樹(shù)),查詢性能越好,維護(hù)的成本就越大。比如圖①的平衡二叉樹(shù),當(dāng)用戶需要插入一個(gè)新的值9的節(jié)點(diǎn)時(shí),就需要做出如下變動(dòng)。

通過(guò)一次左旋操作就將插入后的樹(shù)重新變?yōu)槠胶舛鏄?shù)是最簡(jiǎn)單的情況了,實(shí)際應(yīng)用場(chǎng)景中可能需要旋轉(zhuǎn)多次。至此我們可以考慮一個(gè)問(wèn)題,平衡二叉樹(shù)的查找效率還不錯(cuò),實(shí)現(xiàn)也非常簡(jiǎn)單,相應(yīng)的維護(hù)成本還能接受,為什么MySQL索引不直接使用平衡二叉樹(shù)?
隨著數(shù)據(jù)庫(kù)中數(shù)據(jù)的增加,索引本身大小隨之增加,不可能全部存儲(chǔ)在內(nèi)存中,因此索引往往以索引文件的形式存儲(chǔ)的磁盤(pán)上。這樣的話,索引查找過(guò)程中就要產(chǎn)生磁盤(pán)I/O消耗,相對(duì)于內(nèi)存存取,I/O存取的消耗要高幾個(gè)數(shù)量級(jí)。可以想象一下一棵幾百萬(wàn)節(jié)點(diǎn)的二叉樹(shù)的深度是多少?如果將這么大深度的一顆二叉樹(shù)放磁盤(pán)上,每讀取一個(gè)節(jié)點(diǎn),需要一次磁盤(pán)的I/O讀取,整個(gè)查找的耗時(shí)顯然是不能夠接受的。那么如何減少查找過(guò)程中的I/O存取次數(shù)?
一種行之有效的解決方法是減少樹(shù)的深度,將二叉樹(shù)變?yōu)閙叉樹(shù)(多路搜索樹(shù)),而 B+Tree就是一種多路搜索樹(shù)。理解 B+Tree時(shí),只需要理解其最重要的兩個(gè)特征即可:第一,所有的關(guān)鍵字(可以理解為數(shù)據(jù))都存儲(chǔ)在葉子節(jié)點(diǎn)( LeafPage),非葉子節(jié)點(diǎn)( IndexPage)并不存儲(chǔ)真正的數(shù)據(jù),所有記錄節(jié)點(diǎn)都是按鍵值大小順序存放在同一層葉子節(jié)點(diǎn)上。其次,所有的葉子節(jié)點(diǎn)由指針連接。如下圖為高度為2的簡(jiǎn)化了的 B+Tree。

怎么理解這兩個(gè)特征?MySQL將每個(gè)節(jié)點(diǎn)的大小設(shè)置為一個(gè)頁(yè)的整數(shù)倍(原因下文會(huì)介紹),也就是在節(jié)點(diǎn)空間大小一定的情況下,每個(gè)節(jié)點(diǎn)可以存儲(chǔ)更多的內(nèi)結(jié)點(diǎn),這樣每個(gè)結(jié)點(diǎn)能索引的范圍更大更精確。所有的葉子節(jié)點(diǎn)使用指針鏈接的好處是可以進(jìn)行區(qū)間訪問(wèn),比如上圖中,如果查找大于20而小于30的記錄,只需要找到節(jié)點(diǎn)20,就可以遍歷指針依次找到25、30。如果沒(méi)有鏈接指針的話,就無(wú)法進(jìn)行區(qū)間查找。這也是MySQL使用 B+Tree作為索引存儲(chǔ)結(jié)構(gòu)的重要原因。
MySQL為何將節(jié)點(diǎn)大小設(shè)置為頁(yè)的整數(shù)倍,這就需要理解磁盤(pán)的存儲(chǔ)原理。磁盤(pán)本身存取就比主存慢很多,在加上機(jī)械運(yùn)動(dòng)損耗(特別是普通的機(jī)械硬盤(pán)),磁盤(pán)的存取速度往往是主存的幾百萬(wàn)分之一,為了盡量減少磁盤(pán)I/O,磁盤(pán)往往不是嚴(yán)格按需讀取,而是每次都會(huì)預(yù)讀,即使只需要一個(gè)字節(jié),磁盤(pán)也會(huì)從這個(gè)位置開(kāi)始,順序向后讀取一定長(zhǎng)度的數(shù)據(jù)放入內(nèi)存,預(yù)讀的長(zhǎng)度一般為頁(yè)的整數(shù)倍。
頁(yè)是計(jì)算機(jī)管理存儲(chǔ)器的邏輯塊,硬件及OS往往將主存和磁盤(pán)存儲(chǔ)區(qū)分割為連續(xù)的大小相等的塊,每個(gè)存儲(chǔ)塊稱為一頁(yè)(許多OS中,頁(yè)的大小通常為4K)。主存和磁盤(pán)以頁(yè)為單位交換數(shù)據(jù)。當(dāng)程序要讀取的數(shù)據(jù)不在主存中時(shí),會(huì)觸發(fā)一個(gè)缺頁(yè)異常,此時(shí)系統(tǒng)會(huì)向磁盤(pán)發(fā)出讀盤(pán)信號(hào),磁盤(pán)會(huì)找到數(shù)據(jù)的起始位置并向后連續(xù)讀取一頁(yè)或幾頁(yè)載入內(nèi)存中,然后異常返回,程序繼續(xù)運(yùn)行。
MySQL巧妙利用了磁盤(pán)預(yù)讀原理,將一個(gè)節(jié)點(diǎn)的大小設(shè)為等于一個(gè)頁(yè),這樣每個(gè)節(jié)點(diǎn)只需要一次I/O就可以完全載入。為了達(dá)到這個(gè)目的,每次新建節(jié)點(diǎn)時(shí),直接申請(qǐng)一個(gè)頁(yè)的空間,這樣就保證一個(gè)節(jié)點(diǎn)物理上也存儲(chǔ)在一個(gè)頁(yè)里,加之計(jì)算機(jī)存儲(chǔ)分配都是按頁(yè)對(duì)齊的,就實(shí)現(xiàn)了讀取一個(gè)節(jié)點(diǎn)只需一次I/O。假設(shè) B+Tree的高度為h,一次檢索最多需要 h-1I/O(根節(jié)點(diǎn)常駐內(nèi)存),復(fù)雜度$O(h) = O(\log_{M}N)$。實(shí)際應(yīng)用場(chǎng)景中,M通常較大,常常超過(guò)100,因此樹(shù)的高度一般都比較小,通常不超過(guò)3。
最后簡(jiǎn)單了解下 B+Tree節(jié)點(diǎn)的操作,在整體上對(duì)索引的維護(hù)有一個(gè)大概的了解,雖然索引可以大大提高查詢效率,但維護(hù)索引仍要花費(fèi)很大的代價(jià),因此合理的創(chuàng)建索引也就尤為重要。
仍以上面的樹(shù)為例,我們假設(shè)每個(gè)節(jié)點(diǎn)只能存儲(chǔ)4個(gè)內(nèi)節(jié)點(diǎn)。首先要插入第一個(gè)節(jié)點(diǎn)28,如下圖所示。
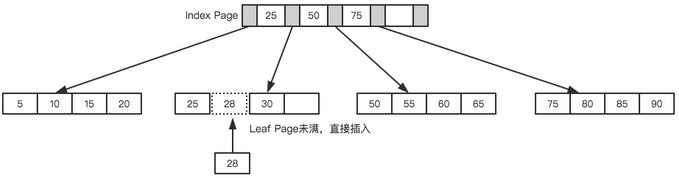
接著插入下一個(gè)節(jié)點(diǎn)70,在Index Page中查詢后得知應(yīng)該插入到50 - 70之間的葉子節(jié)點(diǎn),但葉子節(jié)點(diǎn)已滿,這時(shí)候就需要進(jìn)行也分裂的操作,當(dāng)前的葉子節(jié)點(diǎn)起點(diǎn)為50,所以根據(jù)中間值來(lái)拆分葉子節(jié)點(diǎn),如下圖所示。
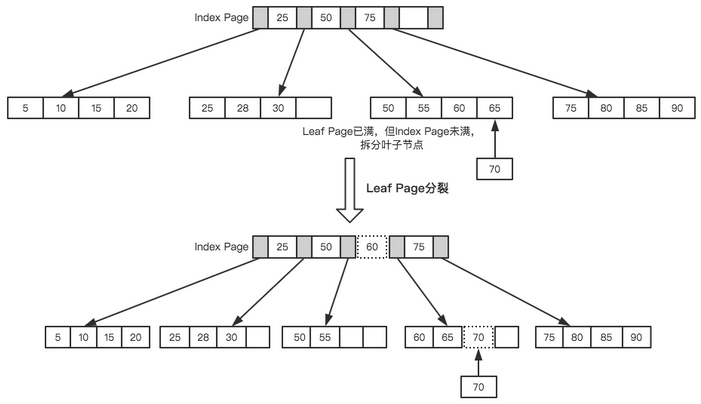
最后插入一個(gè)節(jié)點(diǎn)95,這時(shí)候Index Page和Leaf Page都滿了,就需要做兩次拆分,如下圖所示。
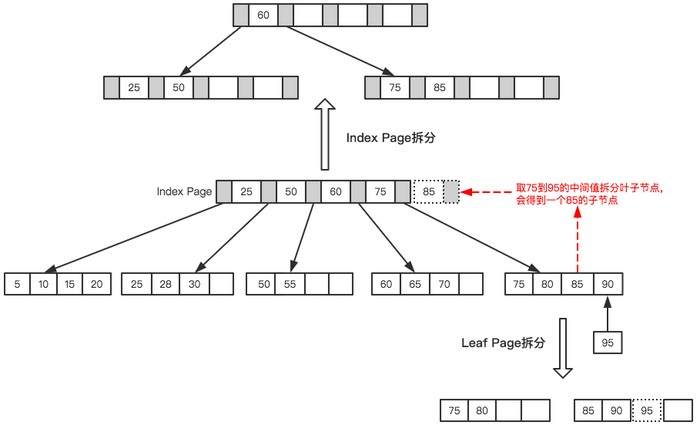
拆分后最終形成了這樣一顆樹(shù)。

B+Tree為了保持平衡,對(duì)于新插入的值需要做大量的拆分頁(yè)操作,而頁(yè)的拆分需要I/O操作,為了盡可能的減少頁(yè)的拆分操作, B+Tree也提供了類似于平衡二叉樹(shù)的旋轉(zhuǎn)功能。當(dāng)Leaf Page已滿但其左右兄弟節(jié)點(diǎn)沒(méi)有滿的情況下, B+Tree并不急于去做拆分操作,而是將記錄移到當(dāng)前所在頁(yè)的兄弟節(jié)點(diǎn)上。通常情況下,左兄弟會(huì)被先檢查用來(lái)做旋轉(zhuǎn)操作。就比如上面第二個(gè)示例,當(dāng)插入70的時(shí)候,并不會(huì)去做頁(yè)拆分,而是左旋操作。
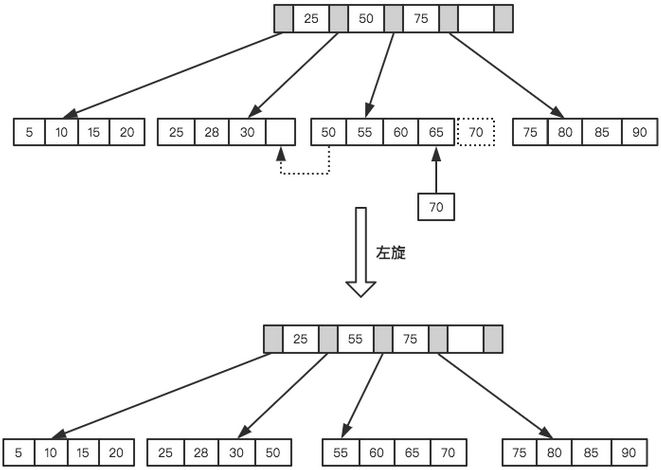
通過(guò)旋轉(zhuǎn)操作可以最大限度的減少頁(yè)分裂,從而減少索引維護(hù)過(guò)程中的磁盤(pán)的I/O操作,也提高索引維護(hù)效率。需要注意的是,刪除節(jié)點(diǎn)跟插入節(jié)點(diǎn)類型,仍然需要旋轉(zhuǎn)和拆分操作,這里就不再說(shuō)明。
高性能策略
CREATE TABLE People(last_name varchar(50) not null,first_name varchar(50) not null,dob date not null,gender enum(`m`,`f`) not null,key(last_name,first_name,dob));
對(duì)于表中每一行數(shù)據(jù),索引中包含了lastname、firstname、dob列的值,下圖展示了索引是如何組織數(shù)據(jù)存儲(chǔ)的。

可以看到,索引首先根據(jù)第一個(gè)字段來(lái)排列順序,當(dāng)名字相同時(shí),則根據(jù)第三個(gè)字段,即出生日期來(lái)排序,正是因?yàn)檫@個(gè)原因,才有了索引的“最左原則”。
1、MySQL不會(huì)使用索引的情況:非獨(dú)立的列
“獨(dú)立的列”是指索引列不能是表達(dá)式的一部分,也不能是函數(shù)的參數(shù)。比如:
select * from where id + 1 = 5
2、前綴索引
如果列很長(zhǎng),通常可以索引開(kāi)始的部分字符,這樣可以有效節(jié)約索引空間,從而提高索引效率。
3、多列索引和索引順序
在多數(shù)情況下,在多個(gè)列上建立獨(dú)立的索引并不能提高查詢性能。理由非常簡(jiǎn)單,MySQL不知道選擇哪個(gè)索引的查詢效率更好,所以在老版本,比如MySQL5.0之前就會(huì)隨便選擇一個(gè)列的索引,而新的版本會(huì)采用合并索引的策略。舉個(gè)簡(jiǎn)單的例子,在一張電影演員表中,在actorid和filmid兩個(gè)列上都建立了獨(dú)立的索引,然后有如下查詢:
select film_id,actor_id from film_actor where actor_id = 1 or film_id = 1老版本的MySQL會(huì)隨機(jī)選擇一個(gè)索引,但新版本做如下的優(yōu)化:
select film_id,actor_id from film_actor where actor_id = 1union allselect film_id,actor_id from film_actor where film_id = 1 and actor_id <> 1
當(dāng)出現(xiàn)多個(gè)索引做相交操作時(shí)(多個(gè)AND條件),通常來(lái)說(shuō)一個(gè)包含所有相關(guān)列的索引要優(yōu)于多個(gè)獨(dú)立索引。
當(dāng)出現(xiàn)多個(gè)索引做聯(lián)合操作時(shí)(多個(gè)OR條件),對(duì)結(jié)果集的合并、排序等操作需要耗費(fèi)大量的CPU和內(nèi)存資源,特別是當(dāng)其中的某些索引的選擇性不高,需要返回合并大量數(shù)據(jù)時(shí),查詢成本更高。所以這種情況下還不如走全表掃描。
因此 explain時(shí)如果發(fā)現(xiàn)有索引合并(Extra字段出現(xiàn) Usingunion),應(yīng)該好好檢查一下查詢和表結(jié)構(gòu)是不是已經(jīng)是最優(yōu)的,如果查詢和表都沒(méi)有問(wèn)題,那只能說(shuō)明索引建的非常糟糕,應(yīng)當(dāng)慎重考慮索引是否合適,有可能一個(gè)包含所有相關(guān)列的多列索引更適合。
前面我們提到過(guò)索引如何組織數(shù)據(jù)存儲(chǔ)的,從圖中可以看到多列索引時(shí),索引的順序?qū)τ诓樵兪侵陵P(guān)重要的,很明顯應(yīng)該把選擇性更高的字段放到索引的前面,這樣通過(guò)第一個(gè)字段就可以過(guò)濾掉大多數(shù)不符合條件的數(shù)據(jù)。
索引選擇性是指不重復(fù)的索引值和數(shù)據(jù)表的總記錄數(shù)的比值,選擇性越高查詢效率越高,因?yàn)檫x擇性越高的索引可以讓MySQL在查詢時(shí)過(guò)濾掉更多的行。唯一索引的選擇性是1,這時(shí)最好的索引選擇性,性能也是最好的。
理解索引選擇性的概念后,就不難確定哪個(gè)字段的選擇性較高了,查一下就知道了,比如:
SELECT * FROM payment where staff_id = 2 and customer_id = 584
是應(yīng)該創(chuàng)建 (staff_id,customer_id)的索引還是應(yīng)該顛倒一下順序?執(zhí)行下面的查詢,哪個(gè)字段的選擇性更接近1就把哪個(gè)字段索引前面就好。
select count(distinct staff_id)/count(*) as staff_id_selectivity,count(distinct customer_id)/count(*) as customer_id_selectivity,count(*) from payment
多數(shù)情況下使用這個(gè)原則沒(méi)有任何問(wèn)題,但仍然注意你的數(shù)據(jù)中是否存在一些特殊情況。舉個(gè)簡(jiǎn)單的例子,比如要查詢某個(gè)用戶組下有過(guò)交易的用戶信息:
select user_id from trade where user_group_id = 1 and trade_amount > 0
MySQL為這個(gè)查詢選擇了索引 (user_group_id,trade_amount),如果不考慮特殊情況,這看起來(lái)沒(méi)有任何問(wèn)題,但實(shí)際情況是這張表的大多數(shù)數(shù)據(jù)都是從老系統(tǒng)中遷移過(guò)來(lái)的,由于新老系統(tǒng)的數(shù)據(jù)不兼容,所以就給老系統(tǒng)遷移過(guò)來(lái)的數(shù)據(jù)賦予了一個(gè)默認(rèn)的用戶組。這種情況下,通過(guò)索引掃描的行數(shù)跟全表掃描基本沒(méi)什么區(qū)別,索引也就起不到任何作用。
推廣開(kāi)來(lái)說(shuō),經(jīng)驗(yàn)法則和推論在多數(shù)情況下是有用的,可以指導(dǎo)我們開(kāi)發(fā)和設(shè)計(jì),但實(shí)際情況往往會(huì)更復(fù)雜,實(shí)際業(yè)務(wù)場(chǎng)景下的某些特殊情況可能會(huì)摧毀你的整個(gè)設(shè)計(jì)。
4、避免多個(gè)范圍條件
實(shí)際開(kāi)發(fā)中,我們會(huì)經(jīng)常使用多個(gè)范圍條件,比如想查詢某個(gè)時(shí)間段內(nèi)登錄過(guò)的用戶:
select user.* from user where login_time > '2017-04-01' and age between 18 and 30;這個(gè)查詢有一個(gè)問(wèn)題:它有兩個(gè)范圍條件,logintime列和age列,MySQL可以
使用logintime列的索引或者age列的索引,但無(wú)法同時(shí)使用它們。
5、覆蓋索引
如果一個(gè)索引包含或者說(shuō)覆蓋所有需要查詢的字段的值,那么就沒(méi)有必要再回表查詢,這就稱為覆蓋索引。覆蓋索引是非常有用的工具,可以極大的提高性能,因?yàn)椴樵冎恍枰獟呙杷饕龝?huì)帶來(lái)許多好處:
索引條目遠(yuǎn)小于數(shù)據(jù)行大小,如果只讀取索引,極大減少數(shù)據(jù)訪問(wèn)量
索引是有按照列值順序存儲(chǔ)的,對(duì)于I/O密集型的范圍查詢要比隨機(jī)從磁盤(pán)讀取每一行數(shù)據(jù)的IO要少的多
6、使用索引掃描來(lái)排序
MySQL有兩種方式可以生產(chǎn)有序的結(jié)果集,其一是對(duì)結(jié)果集進(jìn)行排序的操作,其二是按照索引順序掃描得出的結(jié)果自然是有序的。如果explain的結(jié)果中
type列的值為 index表示使用了索引掃描來(lái)做排序。
掃描索引本身很快,因?yàn)橹恍枰獜囊粭l索引記錄移動(dòng)到相鄰的下一條記錄。但如果索引本身不能覆蓋所有需要查詢的列,那么就不得不每掃描一條索引記錄就回表查詢一次對(duì)應(yīng)的行。這個(gè)讀取操作基本上是隨機(jī)I/O,因此按照索引順序讀取數(shù)據(jù)的速度通常要比順序地全表掃描要慢。
在設(shè)計(jì)索引時(shí),如果一個(gè)索引既能夠滿足排序,有滿足查詢,是最好的。
只有當(dāng)索引的列順序和 ORDER BY子句的順序完全一致,并且所有列的排序方向也一樣時(shí),才能夠使用索引來(lái)對(duì)結(jié)果做排序。如果查詢需要關(guān)聯(lián)多張表,則只有 ORDER BY子句引用的字段全部為第一張表時(shí),才能使用索引做排序。ORDER BY子句和查詢的限制是一樣的,都要滿足最左前綴的要求(有一種情況例外,就是最左的列被指定為常數(shù),下面是一個(gè)簡(jiǎn)單的示例),其他情況下都需要執(zhí)行排序操作,而無(wú)法利用索引排序。
// 最左列為常數(shù),索引:(date,staff_id,customer_id)select staff_id,customer_id from demo where date = '2015-06-01' order by staff_id,customer_id
7、冗余和重復(fù)索引
冗余索引是指在相同的列上按照相同的順序創(chuàng)建的相同類型的索引,應(yīng)當(dāng)盡量避免這種索引,發(fā)現(xiàn)后立即刪除。比如有一個(gè)索引 (A,B),再創(chuàng)建索引 (A)就是冗余索引。冗余索引經(jīng)常發(fā)生在為表添加新索引時(shí),比如有人新建了索引 (A,B),但這個(gè)索引不是擴(kuò)展已有的索引 (A)。
大多數(shù)情況下都應(yīng)該盡量擴(kuò)展已有的索引而不是創(chuàng)建新索引。但有極少情況下出現(xiàn)性能方面的考慮需要冗余索引,比如擴(kuò)展已有索引而導(dǎo)致其變得過(guò)大,從而影響到其他使用該索引的查詢。
8、刪除長(zhǎng)期未使用的索引
定期刪除一些長(zhǎng)時(shí)間未使用過(guò)的索引是一個(gè)非常好的習(xí)慣。
關(guān)于索引這個(gè)話題打算就此打住,最后要說(shuō)一句,索引并不總是最好的工具,只有當(dāng)索引幫助提高查詢速度帶來(lái)的好處大于其帶來(lái)的額外工作時(shí),索引才是有效的。對(duì)于非常小的表,簡(jiǎn)單的全表掃描更高效。對(duì)于中到大型的表,索引就非常有效。對(duì)于超大型的表,建立和維護(hù)索引的代價(jià)隨之增長(zhǎng),這時(shí)候其他技術(shù)也許更有效,比如分區(qū)表。最后的最后, explain后再提測(cè)是一種美德。
特定類型查詢優(yōu)化
優(yōu)化COUNT()查詢
COUNT()可能是被大家誤解最多的函數(shù)了,它有兩種不同的作用,其一是統(tǒng)計(jì)某個(gè)列值的數(shù)量,其二是統(tǒng)計(jì)行數(shù)。統(tǒng)計(jì)列值時(shí),要求列值是非空的,它不會(huì)統(tǒng)計(jì)NULL。如果確認(rèn)括號(hào)中的表達(dá)式不可能為空時(shí),實(shí)際上就是在統(tǒng)計(jì)行數(shù)。最簡(jiǎn)單的就是當(dāng)使用 COUNT(*)時(shí),并不是我們所想象的那樣擴(kuò)展成所有的列,實(shí)際上,它會(huì)忽略所有的列而直接統(tǒng)計(jì)所有的行數(shù)。
我們最常見(jiàn)的誤解也就在這兒,在括號(hào)內(nèi)指定了一列卻希望統(tǒng)計(jì)結(jié)果是行數(shù),而且還常常誤以為前者的性能會(huì)更好。但實(shí)際并非這樣,如果要統(tǒng)計(jì)行數(shù),直接使用 COUNT(*),意義清晰,且性能更好。
有時(shí)候某些業(yè)務(wù)場(chǎng)景并不需要完全精確的 COUNT值,可以用近似值來(lái)代替,EXPLAIN出來(lái)的行數(shù)就是一個(gè)不錯(cuò)的近似值,而且執(zhí)行EXPLAIN并不需要真正地去執(zhí)行查詢,所以成本非常低。通常來(lái)說(shuō),執(zhí)行 COUNT()都需要掃描大量的行才能獲取到精確的數(shù)據(jù),因此很難優(yōu)化,MySQL層面還能做得也就只有覆蓋索引了。如果不還能解決問(wèn)題,只有從架構(gòu)層面解決了,比如添加匯總表,或者使用redis這樣的外部緩存系統(tǒng)。
優(yōu)化關(guān)聯(lián)查詢
在大數(shù)據(jù)場(chǎng)景下,表與表之間通過(guò)一個(gè)冗余字段來(lái)關(guān)聯(lián),要比直接使用 JOIN有更好的性能。如果確實(shí)需要使用關(guān)聯(lián)查詢的情況下,需要特別注意的是:
確保 ON和 USING字句中的列上有索引。在創(chuàng)建索引的時(shí)候就要考慮到關(guān)聯(lián)的順序。當(dāng)表A和表B用列c關(guān)聯(lián)的時(shí)候,如果優(yōu)化器關(guān)聯(lián)的順序是A、B,那么就不需要在A表的對(duì)應(yīng)列上創(chuàng)建索引。沒(méi)有用到的索引會(huì)帶來(lái)額外的負(fù)擔(dān),一般來(lái)說(shuō),除非有其他理由,只需要在關(guān)聯(lián)順序中的第二張表的相應(yīng)列上創(chuàng)建索引(具體原因下文分析)。
確保任何的 GROUP BY和 ORDER BY中的表達(dá)式只涉及到一個(gè)表中的列,這樣MySQL才有可能使用索引來(lái)優(yōu)化。
要理解優(yōu)化關(guān)聯(lián)查詢的第一個(gè)技巧,就需要理解MySQL是如何執(zhí)行關(guān)聯(lián)查詢的。當(dāng)前MySQL關(guān)聯(lián)執(zhí)行的策略非常簡(jiǎn)單,它對(duì)任何的關(guān)聯(lián)都執(zhí)行嵌套循環(huán)關(guān)聯(lián)操作,即先在一個(gè)表中循環(huán)取出單條數(shù)據(jù),然后在嵌套循環(huán)到下一個(gè)表中尋找匹配的行,依次下去,直到找到所有表中匹配的行為為止。然后根據(jù)各個(gè)表匹配的行,返回查詢中需要的各個(gè)列。
太抽象了?以上面的示例來(lái)說(shuō)明,比如有這樣的一個(gè)查詢:
SELECT A.xx,B.yyFROM A INNER JOIN B USING(c)WHERE A.xx IN (5,6)
假設(shè)MySQL按照查詢中的關(guān)聯(lián)順序A、B來(lái)進(jìn)行關(guān)聯(lián)操作,那么可以用下面的偽代碼表示MySQL如何完成這個(gè)查詢:
outer_iterator = SELECT A.xx,A.c FROM A WHERE A.xx IN (5,6);outer_row = outer_iterator.next;while(outer_row) {inner_iterator = SELECT B.yy FROM B WHERE B.c = outer_row.c;inner_row = inner_iterator.next;while(inner_row) {output[inner_row.yy,outer_row.xx];inner_row = inner_iterator.next;}outer_row = outer_iterator.next;}
可以看到,最外層的查詢是根據(jù) A.xx列來(lái)查詢的, A.c上如果有索引的話,整個(gè)關(guān)聯(lián)查詢也不會(huì)使用。再看內(nèi)層的查詢,很明顯 B.c上如果有索引的話,能夠加速查詢,因此只需要在關(guān)聯(lián)順序中的第二張表的相應(yīng)列上創(chuàng)建索引即可。
優(yōu)化LIMIT分頁(yè)
當(dāng)需要分頁(yè)操作時(shí),通常會(huì)使用 LIMIT加上偏移量的辦法實(shí)現(xiàn),同時(shí)加上合適的 ORDER BY字句。如果有對(duì)應(yīng)的索引,通常效率會(huì)不錯(cuò),否則,MySQL需要做大量的文件排序操作。
一個(gè)常見(jiàn)的問(wèn)題是當(dāng)偏移量非常大的時(shí)候,比如:LIMIT1000020這樣的查詢,MySQL需要查詢10020條記錄然后只返回20條記錄,前面的10000條都將被拋棄,這樣的代價(jià)非常高。
SELECT film_id,description FROM film ORDER BY title LIMIT 50,5;
SELECT film.film_id,film.descriptionFROM film INNER JOIN (SELECT film_id FROM film ORDER BY title LIMIT 50,5) AS tmp USING(film_id);
這里的延遲關(guān)聯(lián)將大大提升查詢效率,讓MySQL掃描盡可能少的頁(yè)面,獲取需要訪問(wèn)的記錄后在根據(jù)關(guān)聯(lián)列回原表查詢所需要的列。
SELECT id FROM t LIMIT 10000, 10;改為:SELECT id FROM t WHERE id > 10000 LIMIT 10;
其他優(yōu)化的辦法還包括使用預(yù)先計(jì)算的匯總表,或者關(guān)聯(lián)到一個(gè)冗余表,冗余表中只包含主鍵列和需要做排序的列。
優(yōu)化UNION
MySQL處理 UNION的策略是先創(chuàng)建臨時(shí)表,然后再把各個(gè)查詢結(jié)果插入到臨時(shí)表中,最后再來(lái)做查詢。因此很多優(yōu)化策略在 UNION查詢中都沒(méi)有辦法很好的時(shí)候。經(jīng)常需要手動(dòng)將 WHERE、 LIMIT、 ORDER BY等字句“下推”到各個(gè)子查詢中,以便優(yōu)化器可以充分利用這些條件先優(yōu)化。
除非確實(shí)需要服務(wù)器去重,否則就一定要使用 UNION ALL,如果沒(méi)有 ALL關(guān)鍵字,MySQL會(huì)給臨時(shí)表加上 DISTINCT選項(xiàng),這會(huì)導(dǎo)致整個(gè)臨時(shí)表的數(shù)據(jù)做唯一性檢查,這樣做的代價(jià)非常高。當(dāng)然即使使用ALL關(guān)鍵字,MySQL總是將結(jié)果放入臨時(shí)表,然后再讀出,再返回給客戶端。雖然很多時(shí)候沒(méi)有這個(gè)必要,比如有時(shí)候可以直接把每個(gè)子查詢的結(jié)果返回給客戶端。
結(jié)語(yǔ)
理解查詢是如何執(zhí)行以及時(shí)間都消耗在哪些地方,再加上一些優(yōu)化過(guò)程的知識(shí),可以幫助大家更好的理解MySQL,理解常見(jiàn)優(yōu)化技巧背后的原理。希望本文中的原理、示例能夠幫助大家更好的將理論和實(shí)踐聯(lián)系起來(lái),更多的將理論知識(shí)運(yùn)用到實(shí)踐中。
其他也沒(méi)啥說(shuō)的了,給大家留兩個(gè)思考題吧,可以在腦袋里想想答案,這也是大家經(jīng)常掛在嘴邊的,但很少有人會(huì)思考為什么?
1.有非常多的程序員在分享時(shí)都會(huì)拋出這樣一個(gè)觀點(diǎn):盡可能不要使用存儲(chǔ)過(guò)程,存儲(chǔ)過(guò)程非常不容易維護(hù),也會(huì)增加使用成本,應(yīng)該把業(yè)務(wù)邏輯放到客戶端。既然客戶端都能干這些事,那為什么還要存儲(chǔ)過(guò)程?
2.JOIN本身也挺方便的,直接查詢就好了,為什么還需要視圖呢?
參考資料
[1] 姜承堯 著;MySQL技術(shù)內(nèi)幕-InnoDB存儲(chǔ)引擎;機(jī)械工業(yè)出版社,2013
[2] Baron Scbwartz 等著;寧海元 周振興等譯;高性能MySQL(第三版); 電子工業(yè)出版社, 2013
[3] 由 B-/B+樹(shù)看 MySQL索引結(jié)構(gòu)
感謝您的閱讀,也歡迎您發(fā)表關(guān)于這篇文章的任何建議,關(guān)注我,技術(shù)不迷茫!小編到你上高速。
正文結(jié)束
1.不認(rèn)命,從10年流水線工人,到谷歌上班的程序媛,一位湖南妹子的勵(lì)志故事
3.從零開(kāi)始搭建創(chuàng)業(yè)公司后臺(tái)技術(shù)棧
5.37歲程序員被裁,120天沒(méi)找到工作,無(wú)奈去小公司,結(jié)果懵了...
6.IntelliJ IDEA 2019.3 首個(gè)最新訪問(wèn)版本發(fā)布,新特性搶先看
一個(gè)人學(xué)習(xí)、工作很迷茫?
點(diǎn)擊「閱讀原文」加入我們的小圈子!
