
深入淺出Yolov3和Yolov4
點擊下方卡片,關(guān)注“新機器視覺”公眾號
視覺/圖像重磅干貨,第一時間送達
因為工作原因,項目中經(jīng)常遇到目標(biāo)檢測的任務(wù),因此對目標(biāo)檢測算法會經(jīng)常使用和關(guān)注,比如Yolov3、Yolov4算法。
當(dāng)然,實際項目中很多的第一步,也都是先進行目標(biāo)檢測任務(wù),比如人臉識別、多目標(biāo)追蹤、REID、客流統(tǒng)計等項目。因此目標(biāo)檢測是計算機視覺項目中非常重要的一部分。
從2018年Yolov3年提出的兩年后,在原作者聲名放棄更新Yolo算法后,俄羅斯的Alexey大神扛起了Yolov4的大旗。
在此,大白將項目中,需要了解的Yolov3、Yolov4系列相關(guān)知識點以及相關(guān)代碼進行完整的匯總,希望和大家共同學(xué)習(xí)探討。
版權(quán)申明:轉(zhuǎn)載及引用本文相關(guān)圖片,需經(jīng)作者江大白授權(quán)。
本文包含圖片,都為作者江大白所繪制,如需高清圖片,可郵箱發(fā)送信息,需要哪部分的圖片。
江大白郵箱:[email protected]
???1.論文匯總
???2.YoloV3核心基礎(chǔ)內(nèi)容
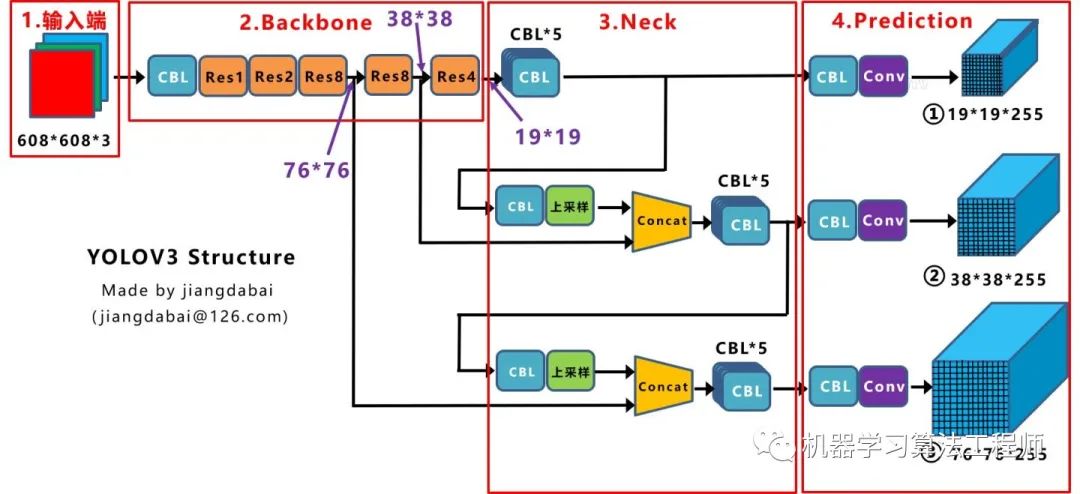
2.1 網(wǎng)絡(luò)結(jié)構(gòu)可視化
2.2 網(wǎng)絡(luò)結(jié)構(gòu)圖
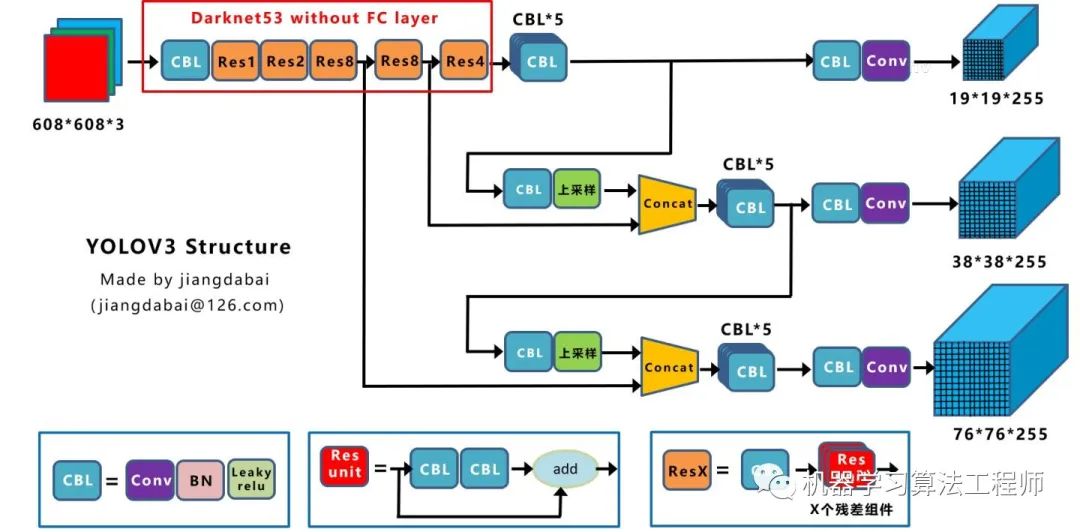
CBL:Yolov3網(wǎng)絡(luò)結(jié)構(gòu)中的最小組件,由Conv+Bn+Leaky_relu激活函數(shù)三者組成。 Res unit:借鑒Resnet網(wǎng)絡(luò)中的殘差結(jié)構(gòu),讓網(wǎng)絡(luò)可以構(gòu)建的更深。 ResX:由一個CBL和X個殘差組件構(gòu)成,是Yolov3中的大組件。每個Res模塊前面的CBL都起到下采樣的作用,因此經(jīng)過5次Res模塊后,得到的特征圖是608->304->152->76->38->19大小。
Concat:張量拼接,會擴充兩個張量的維度,例如26*26*256和26*26*512兩個張量拼接,結(jié)果是26*26*768。Concat和cfg文件中的route功能一樣。 add:張量相加,張量直接相加,不會擴充維度,例如104*104*128和104*104*128相加,結(jié)果還是104*104*128。add和cfg文件中的shortcut功能一樣。
2.3?核心基礎(chǔ)內(nèi)容
???3.YoloV3相關(guān)代碼
3.1 python代碼
3.2 C++代碼
3.3 python版本的Tensorrt代碼
(1)Tensort中的加速案例
(2)Github上的tensorrt加速
3.4?C++版本的Tensorrt代碼
???4.YoloV4核心基礎(chǔ)內(nèi)容
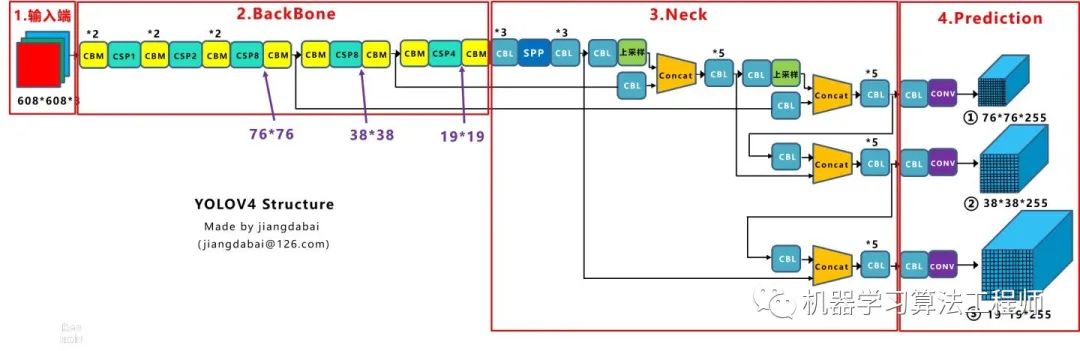
4.1 網(wǎng)絡(luò)結(jié)構(gòu)可視化
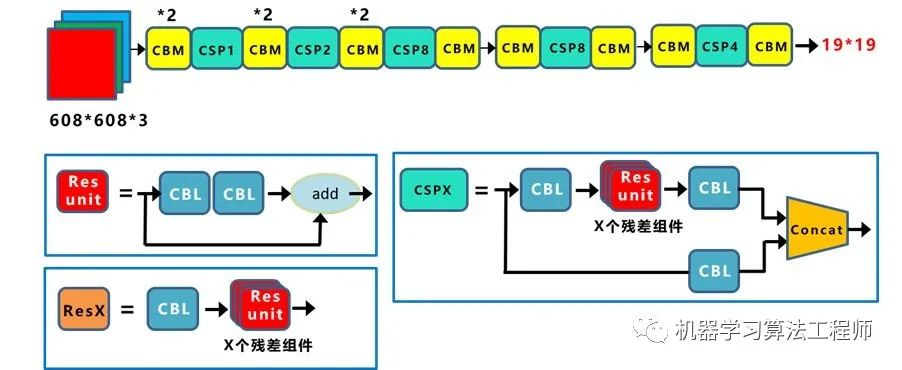
4.2 網(wǎng)絡(luò)結(jié)構(gòu)圖
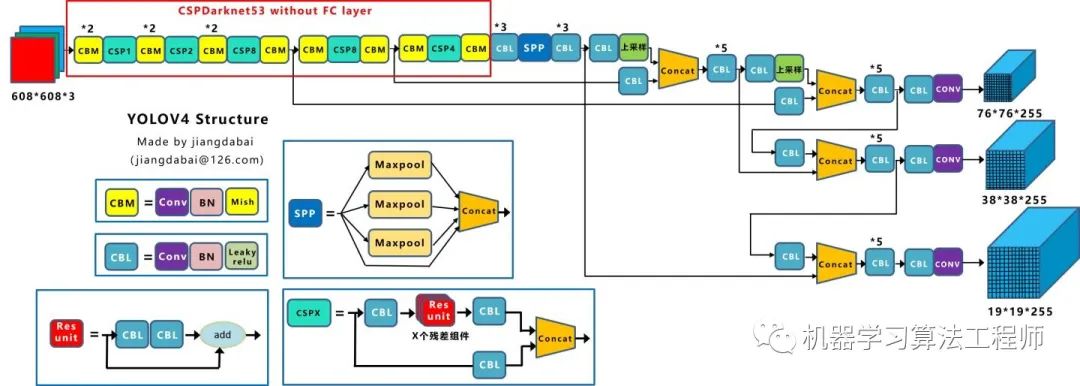
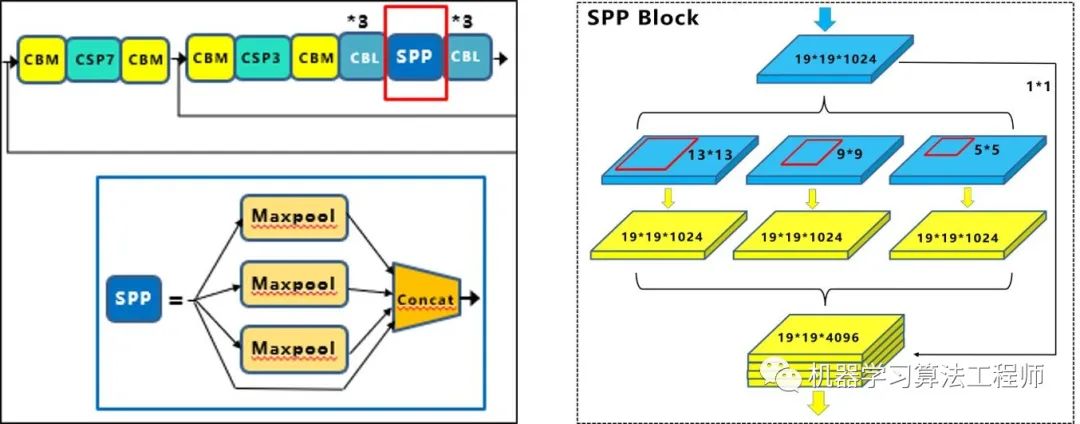
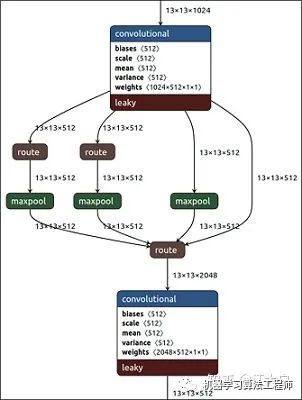
CBM:Yolov4網(wǎng)絡(luò)結(jié)構(gòu)中的最小組件,由Conv+Bn+Mish激活函數(shù)三者組成。 CBL:由Conv+Bn+Leaky_relu激活函數(shù)三者組成。 Res unit:借鑒Resnet網(wǎng)絡(luò)中的殘差結(jié)構(gòu),讓網(wǎng)絡(luò)可以構(gòu)建的更深。 CSPX:借鑒CSPNet網(wǎng)絡(luò)結(jié)構(gòu),由三個卷積層和X個Res unint模塊Concate組成。 SPP:采用1×1,5×5,9×9,13×13的最大池化的方式,進行多尺度融合。
Concat:張量拼接,維度會擴充,和Yolov3中的解釋一樣,對應(yīng)于cfg文件中的route操作。 add:張量相加,不會擴充維度,對應(yīng)于cfg文件中的shortcut操作。
4.3 核心基礎(chǔ)內(nèi)容
第一種:面目一新的創(chuàng)新,比如Yolov1、Faster-RCNN、Centernet等,開創(chuàng)出新的算法領(lǐng)域,不過這種也是最難的
第二種:守正出奇的創(chuàng)新,比如將圖像金字塔改進為特征金字塔
第三種:各種先進算法集成的創(chuàng)新,比如不同領(lǐng)域發(fā)表的最新論文的tricks,集成到自己的算法中,卻發(fā)現(xiàn)有出乎意料的改進
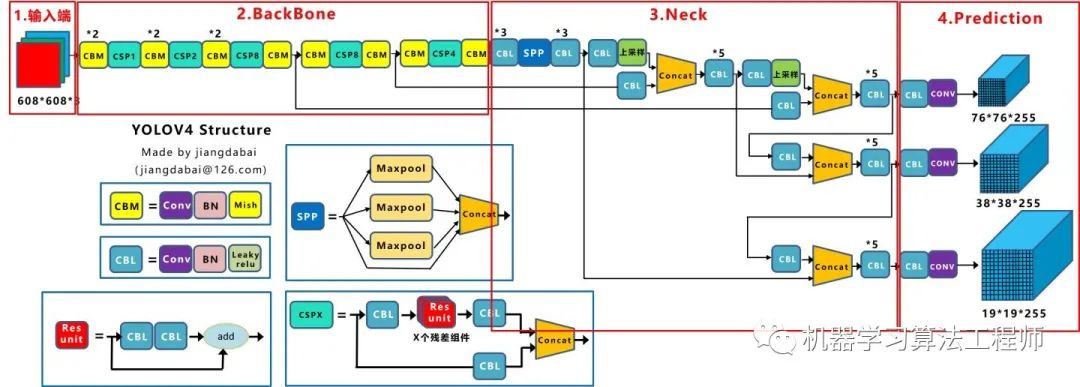
輸入端:這里指的創(chuàng)新主要是訓(xùn)練時對輸入端的改進,主要包括Mosaic數(shù)據(jù)增強、cmBN、SAT自對抗訓(xùn)練
BackBone主干網(wǎng)絡(luò):將各種新的方式結(jié)合起來,包括:CSPDarknet53、Mish激活函數(shù)、Dropblock
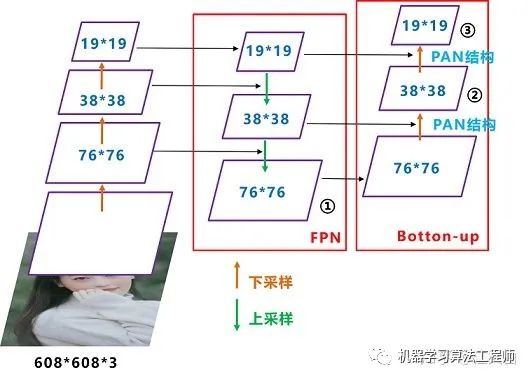
Neck:目標(biāo)檢測網(wǎng)絡(luò)在BackBone和最后的輸出層之間往往會插入一些層,比如Yolov4中的SPP模塊、FPN+PAN結(jié)構(gòu)
Prediction:輸出層的錨框機制和Yolov3相同,主要改進的是訓(xùn)練時的損失函數(shù)CIOU_Loss,以及預(yù)測框篩選的nms變?yōu)?span style="outline: 0px;font-weight: 600;">DIOU_nms
4.3.1 輸入端創(chuàng)新
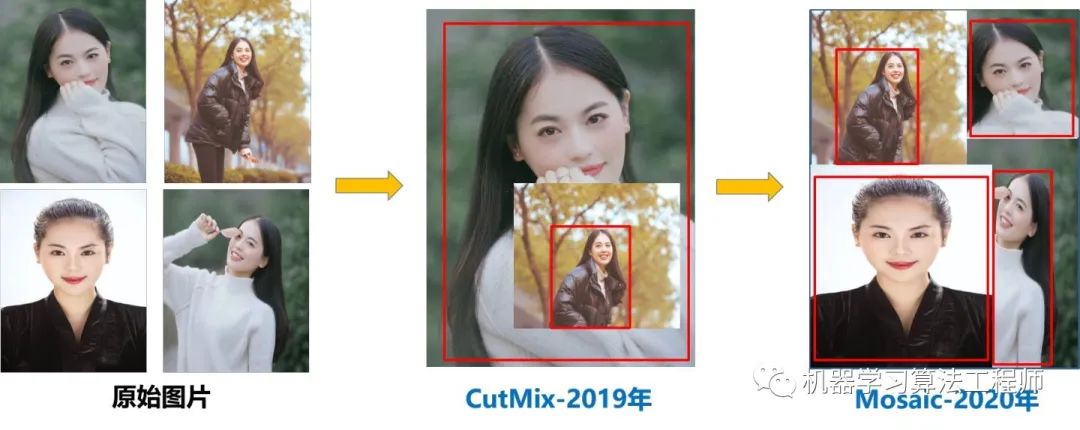
(1)Mosaic數(shù)據(jù)增強
2019年發(fā)布的論文《Augmentation for small object detection》對此進行了區(qū)分:
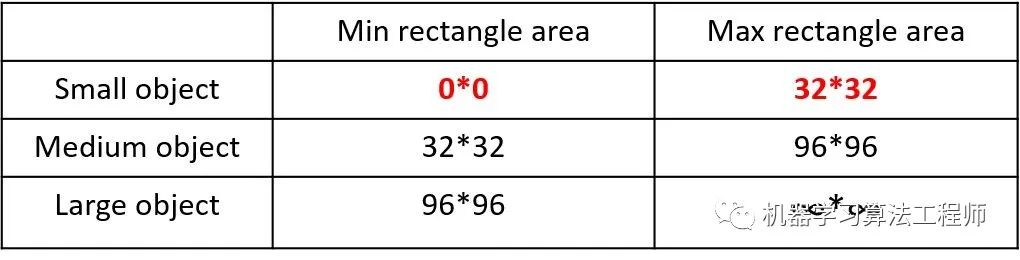

如上表所示,Coco數(shù)據(jù)集中小目標(biāo)占比達到41.4%,數(shù)量比中目標(biāo)和大目標(biāo)都要多。
豐富數(shù)據(jù)集:隨機使用4張圖片,隨機縮放,再隨機分布進行拼接,大大豐富了檢測數(shù)據(jù)集,特別是隨機縮放增加了很多小目標(biāo),讓網(wǎng)絡(luò)的魯棒性更好。
減少GPU:可能會有人說,隨機縮放,普通的數(shù)據(jù)增強也可以做,但作者考慮到很多人可能只有一個GPU,因此Mosaic增強訓(xùn)練時,可以直接計算4張圖片的數(shù)據(jù),使得Mini-batch大小并不需要很大,一個GPU就可以達到比較好的效果。
4.3.2 BackBone創(chuàng)新
(1)CSPDarknet53
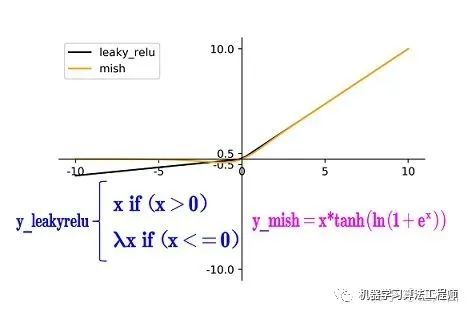
(2)Mish激活函數(shù)

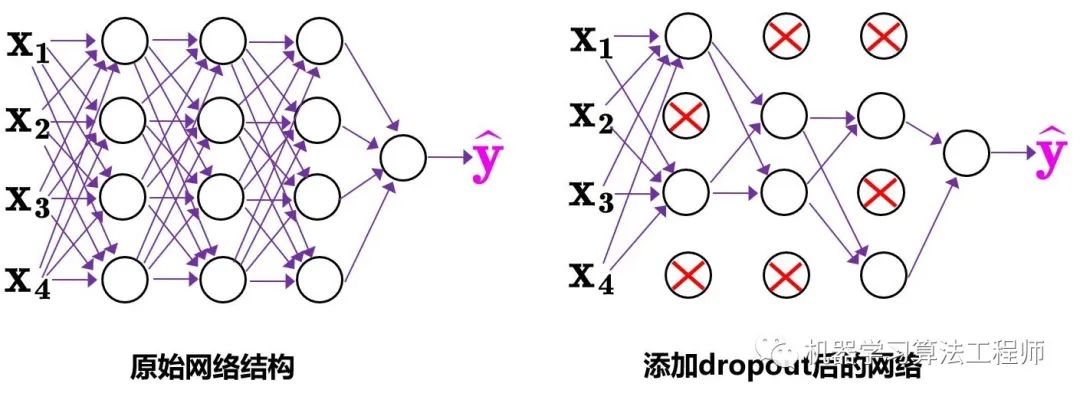
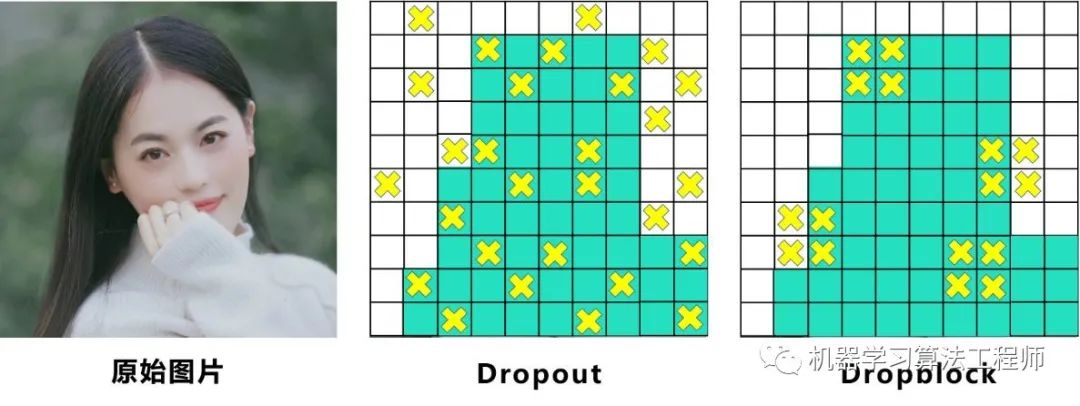
(3)Dropblock

4.3.3 Neck創(chuàng)新
(1)SPP模塊
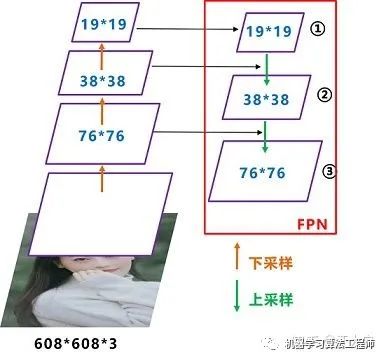
(2)FPN+PAN
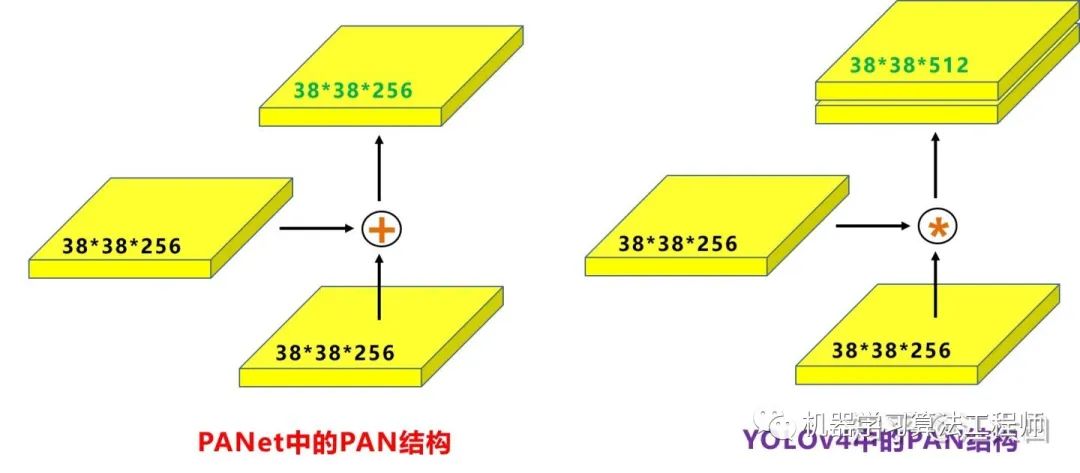
4.3.4 Prediction創(chuàng)新
(1)CIOU_loss
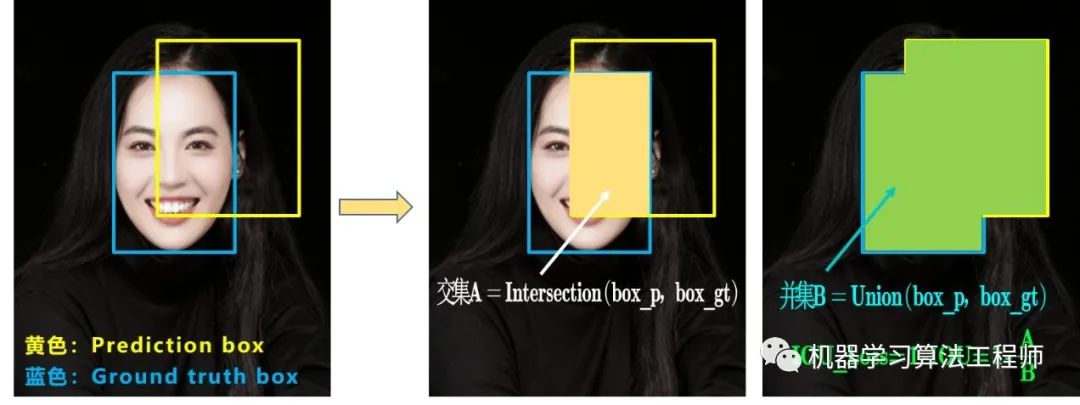

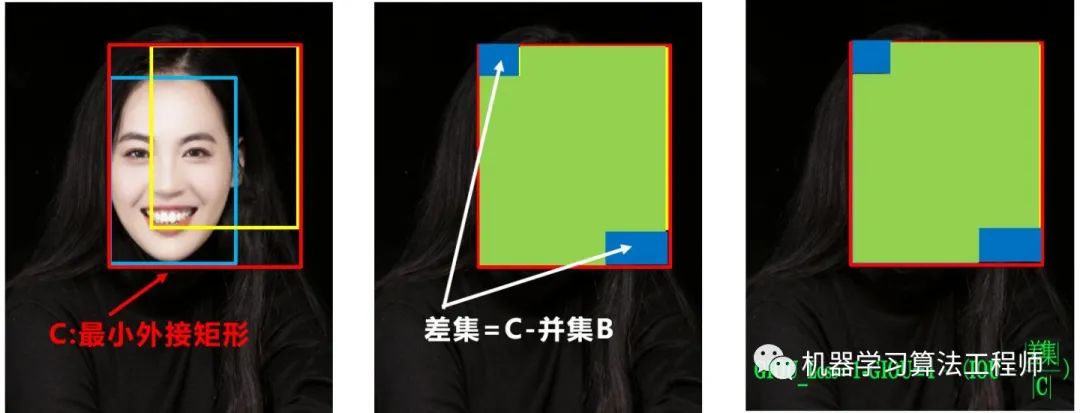

基于這個問題,2020年的AAAI又提出了DIOU_Loss。

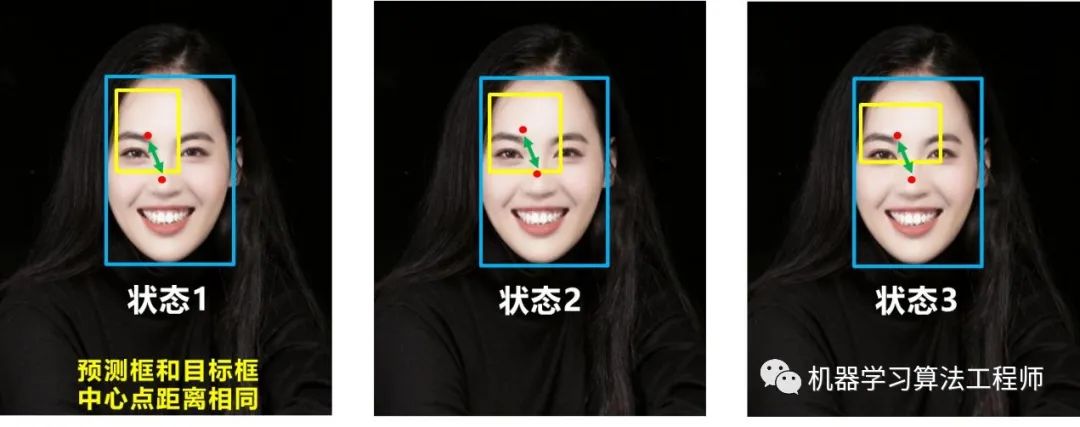
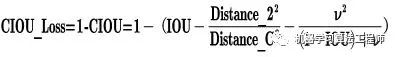
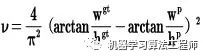
(2)DIOU_nms
