
Delta 性能 | Delta vs Iceberg:到底哪個性能更強?

上周大數(shù)據(jù)領域的大事毫無疑問就是一年一度的Spark Summit(現(xiàn)在改名叫Data + AI Summit)。Databricks在大會上宣布了很多重磅消息,如新的數(shù)據(jù)共享方式Data Cleanroom[1],新的Spark Streaming處理引擎Lightspeed[2],MLflow 2.0[3]等,但其中最重磅的莫過于Delta Lake宣布完整開源[4],包括之前只有付費版才有的Z-ordering等功能也都開源了(上周剛說Databricks藏著掖著不愿開源,沒想到打臉來得如此迅速)。
Databricks選擇在這個時間點開源,很明顯的是因為感受到來自Iceberg等開源項目的挑戰(zhàn)。因此在官宣文章中特意強調(diào)Delta 2.0可以直接和Flink,Presto,Trino等交互,不依賴于Spark(因為Delta之前常被詬病為強綁定Spark)。也支持通過Python,Rust,Ruby等語言進行直接讀寫。
至于為什么對手是Iceberg,那是因為Iceberg這兩年的發(fā)展勢頭非常迅猛,還有Dremio,Cloudera等Databricks的競爭對手強力助推,應該是讓Databricks感到了威脅。盡管在官宣文章里沒有直接提到Iceberg,但處處都有影射(例如“Delta Lake始終提供無人可比的,開箱即用的高性能體驗,無論是批處理還是流處理——相比于其他存儲系統(tǒng)快至多4.3倍”),甚至在新功能列表里還有一項:Iceberg to Delta converter。

新功能列表里就有一項:Iceberg to Delta converter。
正好性能也是我很感興趣的話題,這周又碰巧看到一篇比較Delta和Iceberg性能的文章,覺得很有參考價值,因此翻譯過來,希望幫助大家更好地做技術選型。
介紹
數(shù)據(jù)湖倉是一種開放的數(shù)據(jù)架構,它同時帶來數(shù)據(jù)湖的可擴展性和低成本,與數(shù)據(jù)倉庫的可靠性和高性能——在一個數(shù)據(jù)平臺上。
簡單地說,數(shù)據(jù)湖倉是唯一一種數(shù)據(jù)架構,允許你在數(shù)據(jù)湖中存儲所有類型的:非結構化的、半結構化的和結構化的數(shù)據(jù),又同時保持數(shù)據(jù)倉庫的數(shù)據(jù)質量和治理標準。
數(shù)據(jù)湖的關鍵支柱之一就是它的開放格式。數(shù)據(jù)的存儲格式可能是建設數(shù)據(jù)湖倉時需要做的最重要的決定。想想看,僅僅只是改變數(shù)據(jù)的存儲格式,就可以獲得新的功能,并提高整個系統(tǒng)的性能,這是多么令人激動的一件事。
不幸的是,在所有關于Delta和Iceberg之間對比的文章,比較的范圍都僅限于功能。這就是為什么我們想對這兩種格式進行性能層面的比較,通過使用TPC-DS的基準測試,模擬真實世界的場景。
什么是TPC-DS?
TPC-DS是一個數(shù)據(jù)倉庫的基準測試,由Transaction Processing Performance Council(TPC)定義。TPC是一個非營利性組織,由數(shù)據(jù)庫社區(qū)在20世紀80年代末成立的,其目標是開發(fā)可以客觀地用于通過模擬真實世界場景來測試數(shù)據(jù)庫系統(tǒng)性能的基準。TPC已經(jīng)對數(shù)據(jù)庫行業(yè)產(chǎn)生了重大影響。
"幫助決策"(Decision Support)是TPC-DS中的"DS"所代表的含義。TPC-DS共包含99個查詢,從簡單的聚合到高級模式分析。
環(huán)境搭建
在這個基準測試中,我們使用了Delta 1.0和Iceberg 0.13.0,環(huán)境配置列于下表。

如前所述,我們使用了Delta Oss的開源TPC-DS基準測試[5],并對其進行了擴展以支持Iceberg。我們記錄了Load性能,也就是將數(shù)據(jù)從Parquet格式加載到Delta/Iceberg表中所需的時間。然后,我們也記錄了Query性能。每個TPC-DS查詢被運行三次,使用平均運行時間作為結果。
測試結果
1. 整體性能
在完成基準測試后,我們發(fā)現(xiàn)無論是Load還是Query,整體性能都是Delta更優(yōu),因為它比Iceberg快3.5倍。將數(shù)據(jù)加載到Delta并執(zhí)行TPC-DS查詢需要1.68小時,而Iceberg則需要5.99小時。
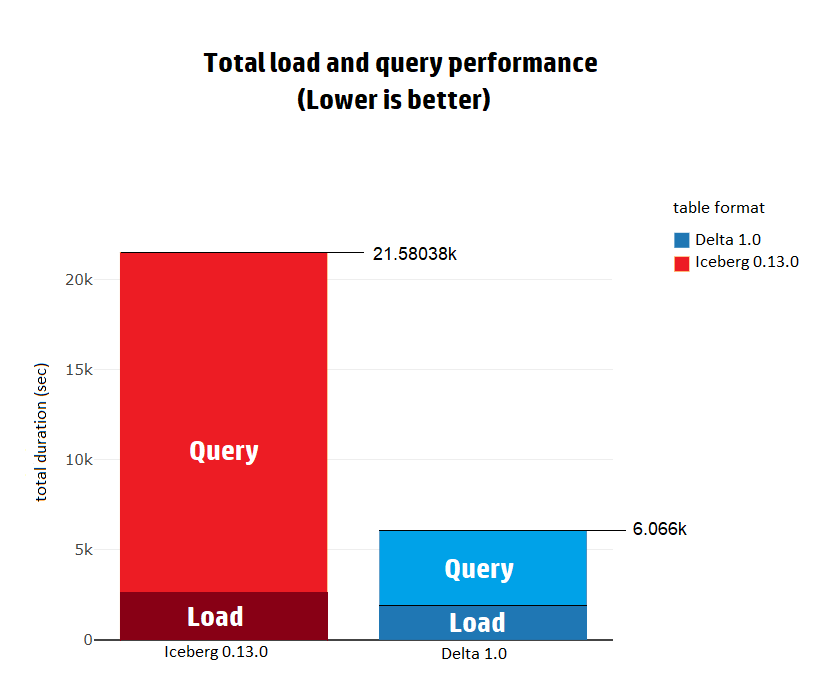
2. Load性能
當從Parquet文件加載數(shù)據(jù)到兩種格式時,Delta在整體性能上比Iceberg快1.3倍。
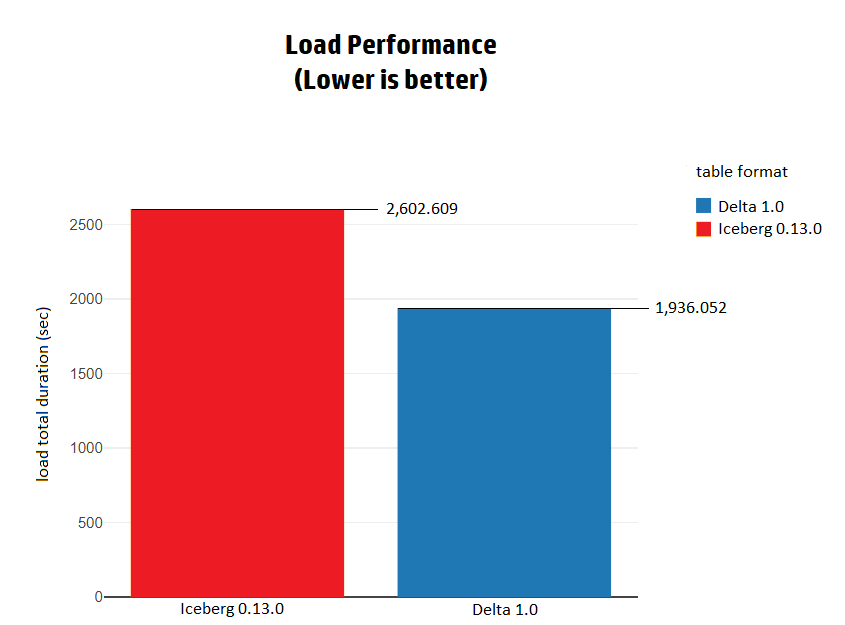
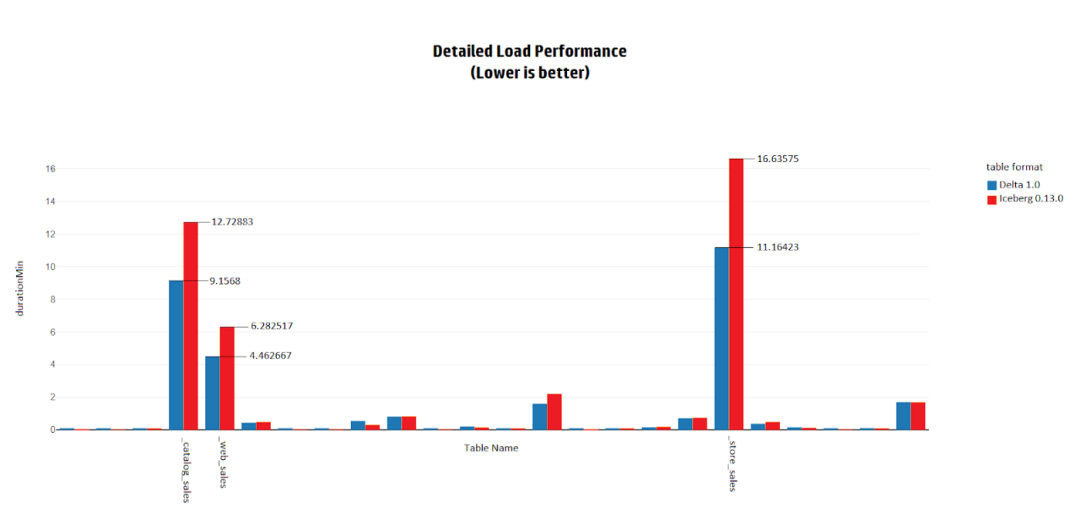
為了進一步分析Load性能的結果,我們深入研究了每張表的詳細加載結果,并注意到當表的大小變大時,加載時間的差異會變大。例如,當加載customer表時,Delta和Iceberg的性能實際上是一樣的。另一方面,在加載store_sales表,也就是TPC-DS基準中最大的表之一時,Delta比Iceberg快1.5倍。
這表明,在加載數(shù)據(jù)時,Delta比Iceberg更快、擴展性更好。
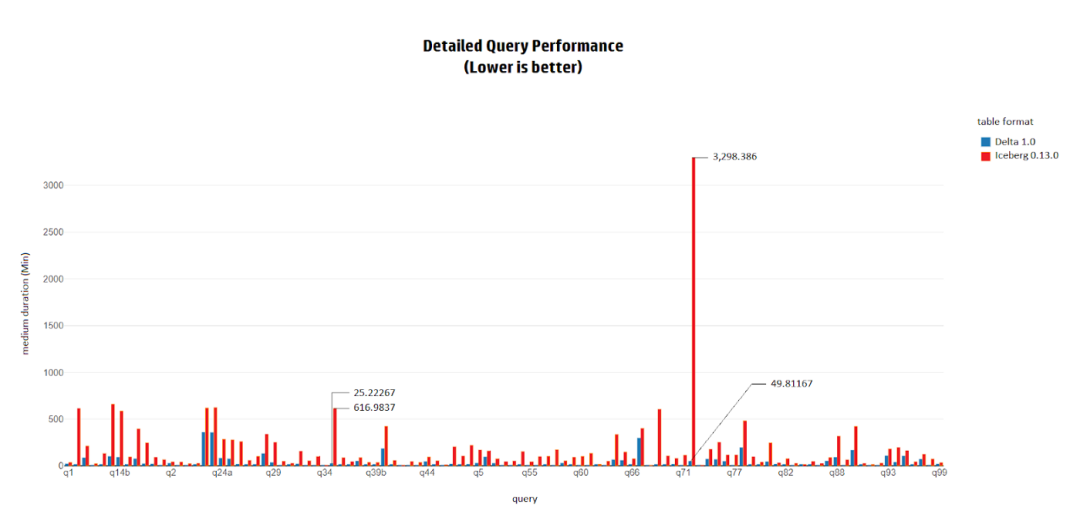
3. Query性能
在執(zhí)行TPC-DS查詢時,Delta的整體性能比Iceberg快4.5倍。在Delta上執(zhí)行所有查詢需要1.14小時,而在Iceberg上執(zhí)行同樣的查詢需要5.27小時。
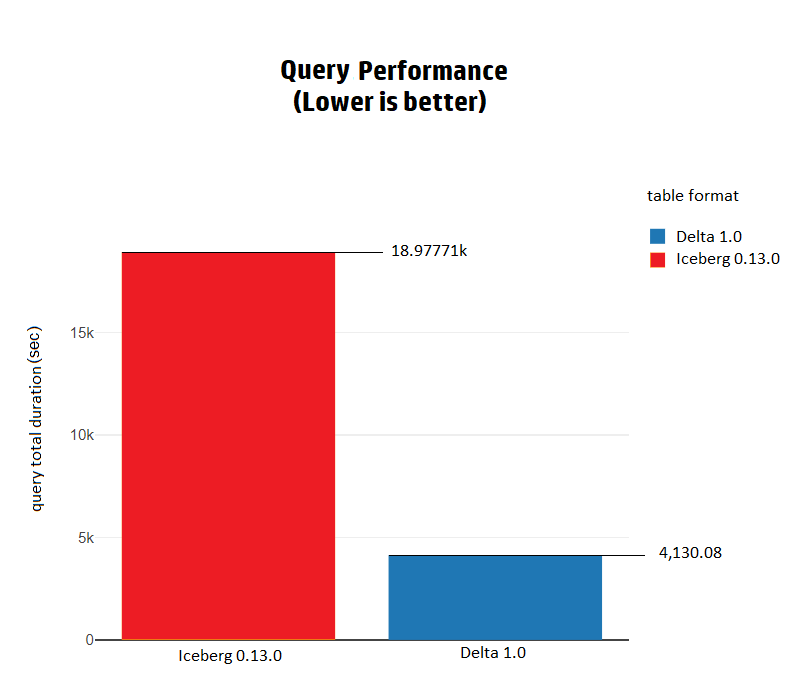
Iceberg和Delta在query34、query41、query46和query68中表現(xiàn)出基本相同的性能。在這些查詢中的差異小于1秒。
然而,在其他的TPC-DS查詢中,Delta都比Iceberg快,而且差異水平各有不同。
在一些查詢中,如query72,Delta比Iceberg快66倍。
而在其他的查詢中,Delta和Iceberg之間的差異在1.1倍到24倍之間,都是Delta更快。
總結
在運行該基準測試后,Delta在可擴展性和性能方面都超過了Iceberg,并且幅度有時候意想不到地大。這個基準測試對我們和我們的客戶來說提供了一個明確的答案,在構建數(shù)據(jù)湖倉時應該選擇哪種解決方案。
同樣需要指出的是,Iceberg和Delta都在不斷地改進,隨著他們的改進,我們將持續(xù)關注他們的性能表現(xiàn),并在更廣泛的社區(qū)分享我們的結果。
如果你希望進一步分析并從這個基準測試結果中提煉你的見解,你可以在這里下載完整的基準測試報告[6]。
原文地址:
如果覺得這篇文章對你有所幫助,
請點一下贊或在看,是對我的肯定和支持~
參考資料
Introducing Data Cleanrooms for the Lakehouse: https://databricks.com/blog/2022/06/28/introducing-data-cleanrooms-for-the-lakehouse.html
[2]Project Lightspeed: Faster and Simpler Stream Processing With Apache Spark: https://databricks.com/blog/2022/06/28/project-lightspeed-faster-and-simpler-stream-processing-with-apache-spark.html
[3]MLflow 2.0 with MLflow Pipelines: https://databricks.com/blog/2022/06/29/introducing-mlflow-pipelines-with-mlflow-2-0.html
[4]Open Sourcing All of Delta Lake: https://databricks.com/blog/2022/06/30/open-sourcing-all-of-delta-lake.html
[5]benchmarks: https://github.com/delta-io/delta/tree/master/benchmarks
[6]TPC-DS-Benchmark: https://github.com/saifeddine1992/TPC-DS-Benchmark-report.gi
一個專注于大數(shù)據(jù)領域頂層認知和底層實現(xiàn)的公眾號: