
特性大PK?Hudi vs Delta Lake vs Iceberg
簡介
隨著 Lakehouse 的日益普及,人們對分析和比較作為該數(shù)據(jù)架構(gòu)核心的開源項目的興趣日益濃厚:Apache Hudi、Delta Lake 和 Apache Iceberg。
目前發(fā)表的大多數(shù)比較文章似乎僅將這些項目評估為傳統(tǒng)的僅附加工作負(fù)載的表/文件格式,而忽略了一些對現(xiàn)代數(shù)據(jù)湖平臺至關(guān)重要的品質(zhì)和特性,這些平臺需要通過連續(xù)的表管理來支持更新繁重的工作負(fù)載。本文將更深入地介紹 Apache Hudi 的技術(shù)差異以及它如何成為一個成熟的數(shù)據(jù)湖平臺,領(lǐng)先于其他平臺。
特性比較
首先讓我們看一個整體的功能比較。在您閱讀時,請注意 Hudi 社區(qū)如何在湖存儲格式之上投入巨資開發(fā)綜合平臺服務(wù)。雖然格式對于標(biāo)準(zhǔn)化和互操作性至關(guān)重要,但表/平臺服務(wù)為您提供了一個強大的工具包,可以輕松開發(fā)和管理您的數(shù)據(jù)湖部署。
特性亮點
當(dāng)然,構(gòu)建數(shù)據(jù)湖平臺不僅僅是功能可用性的復(fù)選框。讓我們選擇上面的一些差異化功能,用簡單的英語深入研究用例和真正的好處。
增量管道
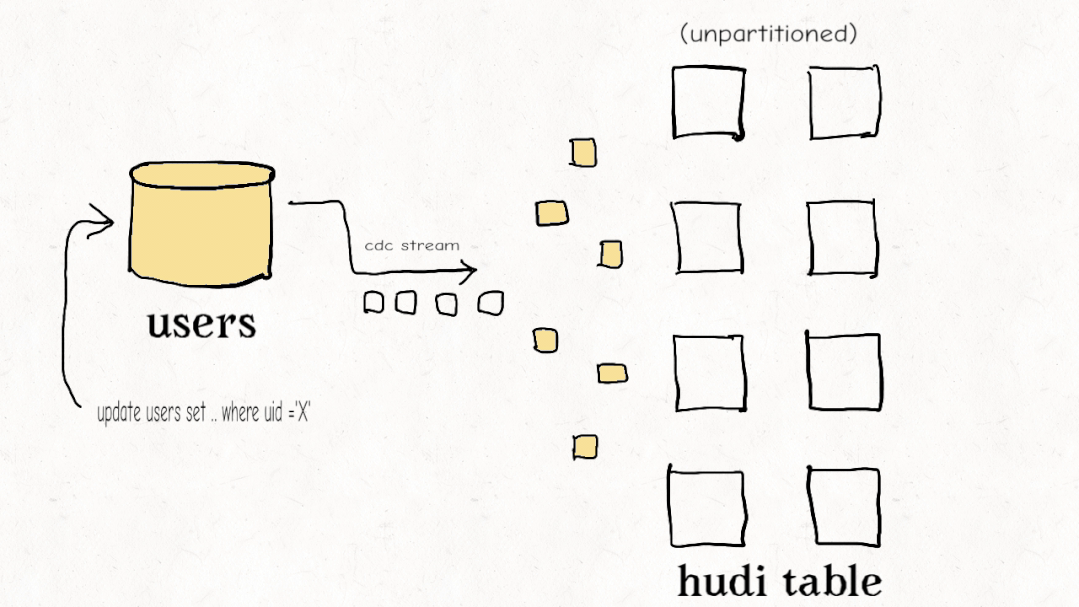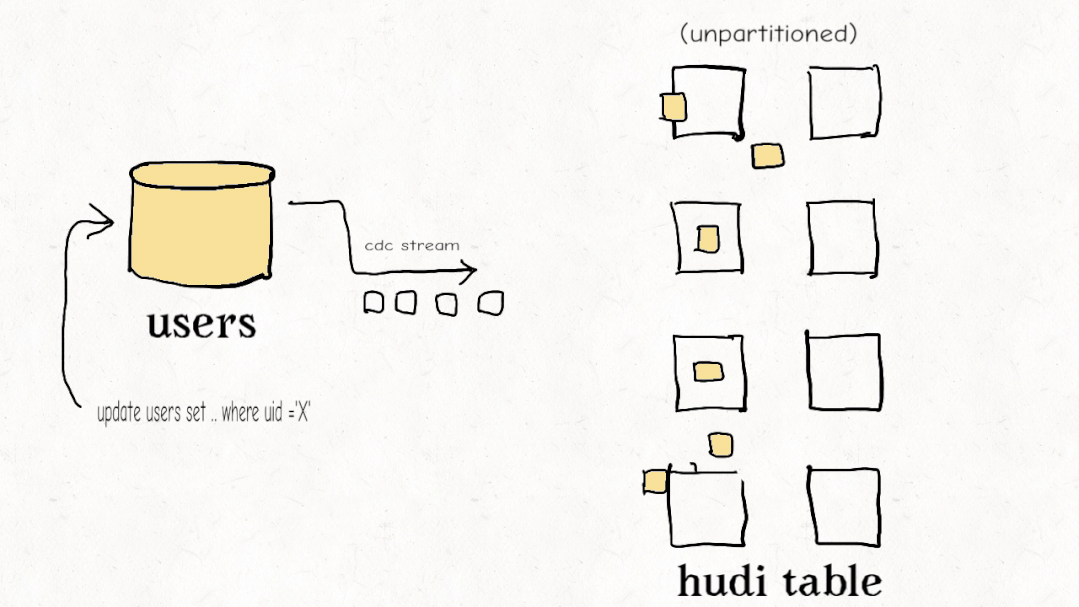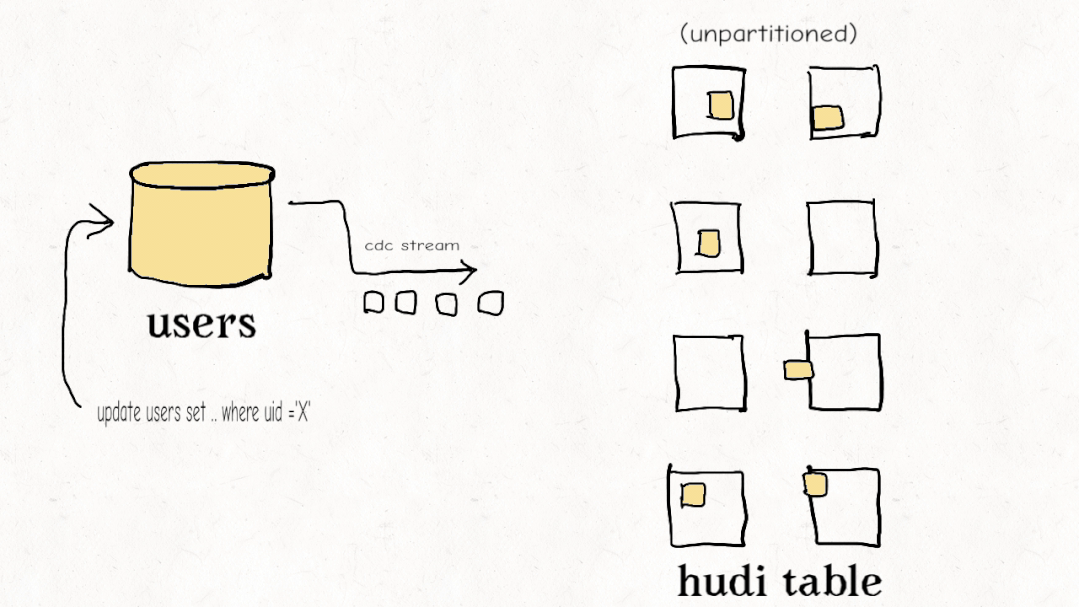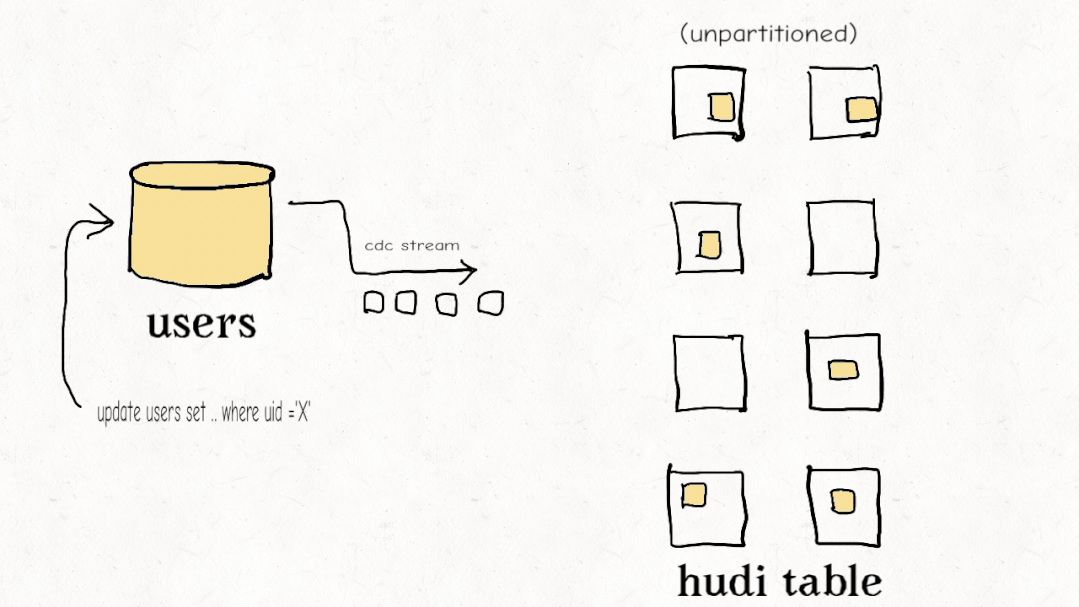
今天的大多數(shù)數(shù)據(jù)工程師都覺得他們必須在流式處理和老式批處理 ETL 管道之間做出選擇。Apache Hudi 開創(chuàng)了一種稱為增量管道的新范例。開箱即用,Hudi 跟蹤所有更改(追加、更新、刪除)并將它們公開為更改流。使用記錄級索引,您可以更有效地利用這些更改流來避免重新計算數(shù)據(jù)并僅以增量方式處理更改。雖然其他數(shù)據(jù)湖平臺可能會提供一種增量消費更改的方式,但 Hudi 的設(shè)計初衷是為了有效地實現(xiàn)增量化,從而以更低的延遲實現(xiàn)具有成本效益的 ETL 管道。
Databricks 最近開發(fā)了一個類似的功能,他們稱之為Change Data Feed,他們一直持有該功能,直到最終在 Delta Lake 2.0 中開源。Iceberg 有增量讀取,但它只允許您讀取增量附加,沒有更新/刪除,這對于真正的變更數(shù)據(jù)捕獲和事務(wù)數(shù)據(jù)至關(guān)重要。
并發(fā)控制
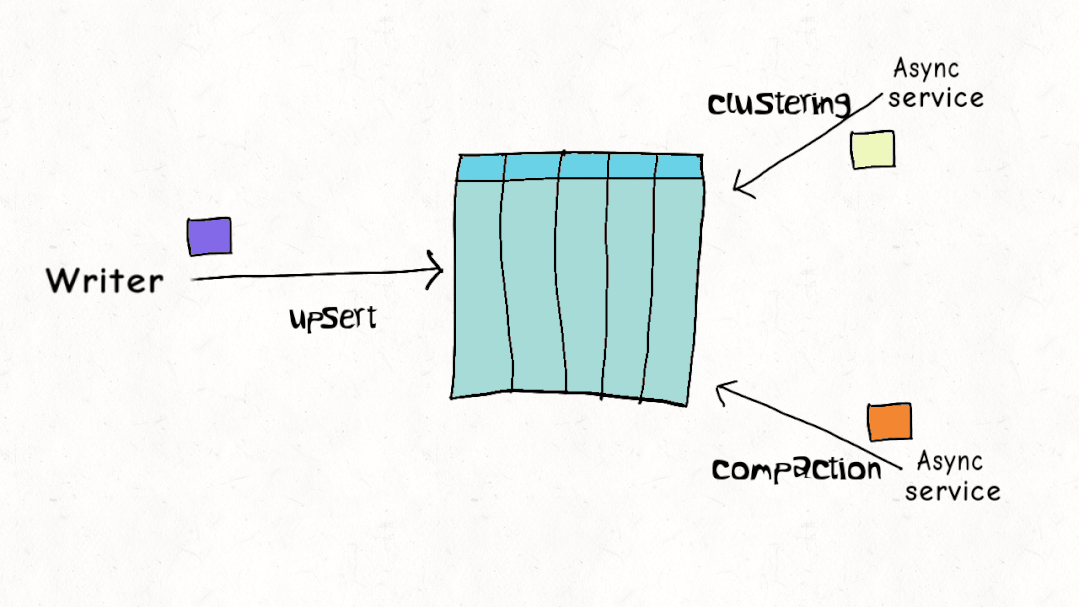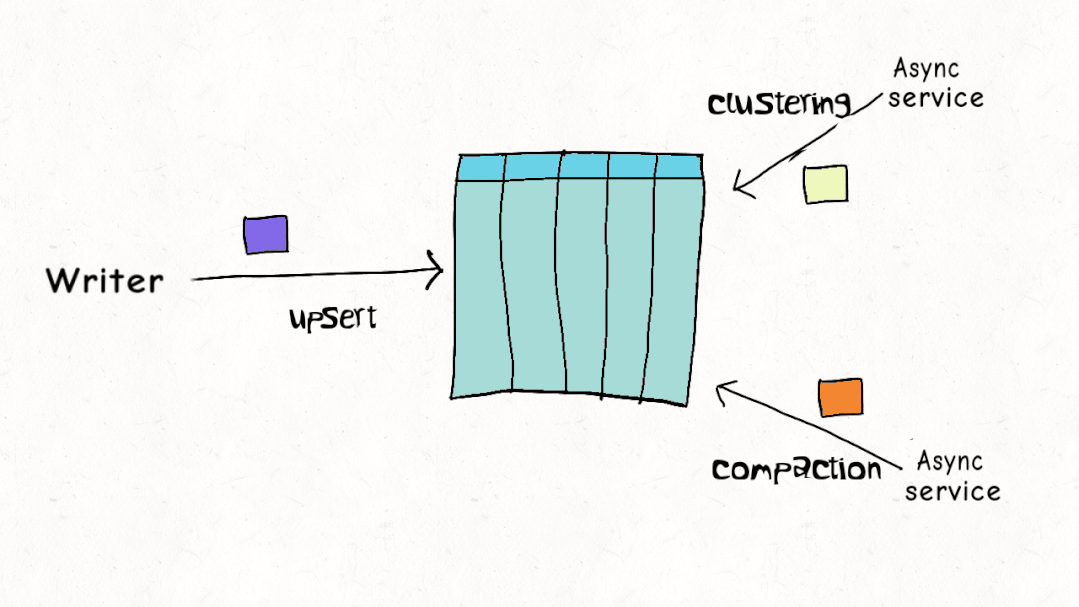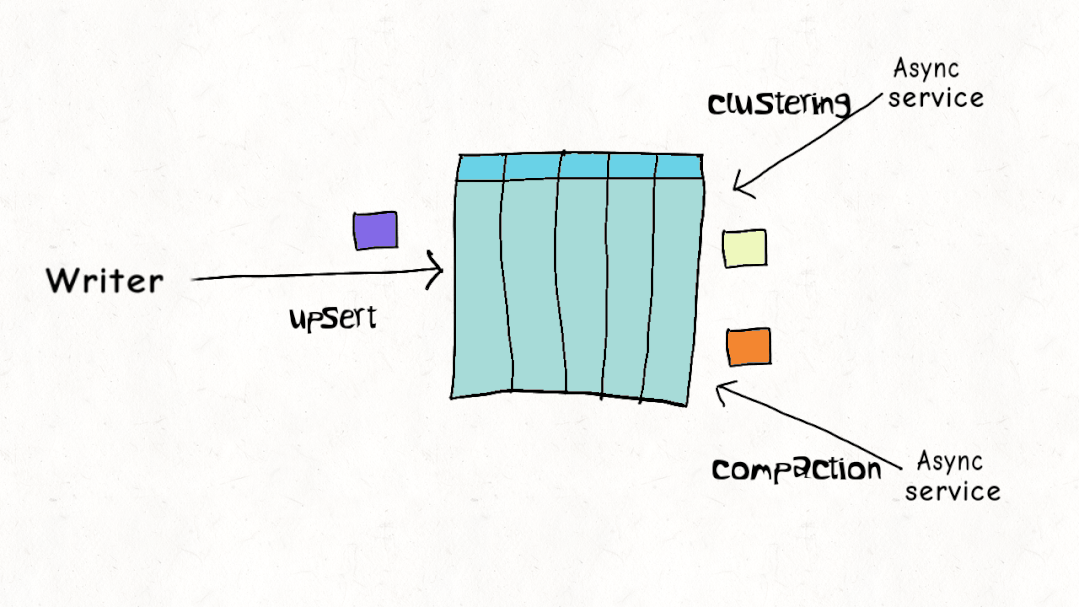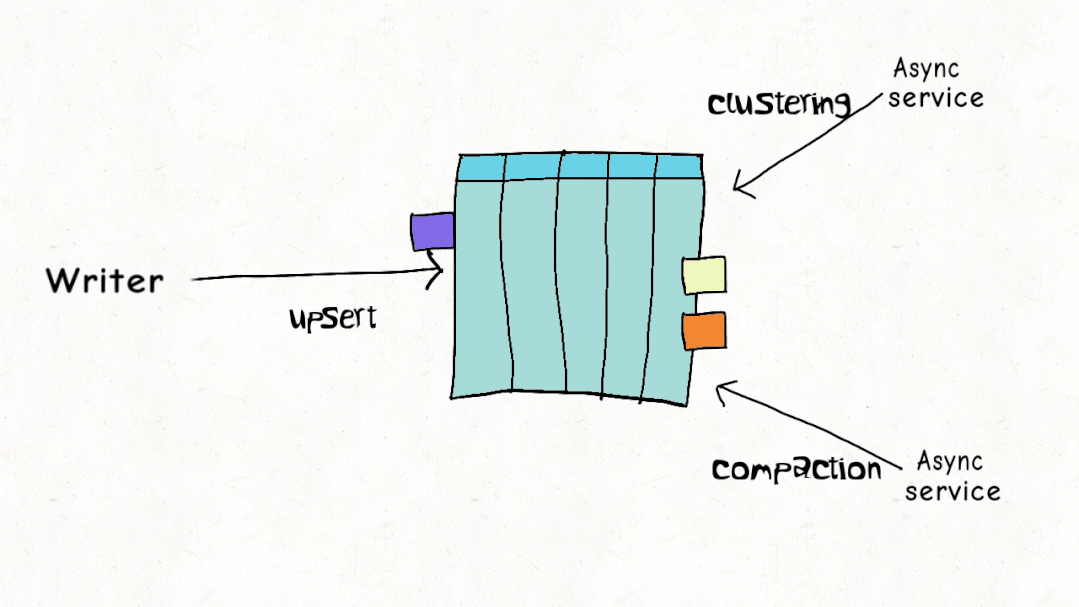
ACID 事務(wù)和并發(fā)控制是 Lakehouse 的關(guān)鍵特征,但與現(xiàn)實世界的工作負(fù)載相比,當(dāng)前的設(shè)計實際上是如何疊加的?Hudi、Delta 和 Iceberg 都支持樂觀并發(fā)控制(OCC)。在樂觀并發(fā)控制中,編寫者檢查他們是否有重疊的文件,如果存在沖突,他們就會使操作失敗并重試。以 Delta Lake 為例,這只是一個 Apache Spark 驅(qū)動程序節(jié)點上的 JVM 級別鎖,這意味著直到最近,您在單個集群之外還沒有 OCC 。
雖然這可能適用于僅附加的不可變數(shù)據(jù)集,但樂觀并發(fā)控制在現(xiàn)實世界場景中遇到困難,由于數(shù)據(jù)加載模式或重組數(shù)據(jù)以提高查詢性能,因此需要頻繁更新和刪除。通常,讓編寫器離線以進(jìn)行表管理以確保表的健康和高性能是不切實際的。Apache Hudi 并發(fā)控制比其他數(shù)據(jù)湖平臺(文件級別)更精細(xì),并且針對多個小更新/刪除進(jìn)行了優(yōu)化的設(shè)計,在大多數(shù)現(xiàn)實世界的情況下,沖突的可能性可以大大降低到可以忽略不計。您可以在此博客中閱讀更多詳細(xì)信息,如何在多寫入器場景中使用異步表服務(wù)進(jìn)行操作,而無需暫停寫入器。這非常接近標(biāo)準(zhǔn)數(shù)據(jù)庫支持的并發(fā)級別。
Merge on Read
任何好的數(shù)據(jù)庫系統(tǒng)都支持寫入和查詢性能之間的不同權(quán)衡。Hudi 社區(qū)在為整個行業(yè)的數(shù)據(jù)湖存儲定義這些概念方面做出了一些開創(chuàng)性的貢獻(xiàn)。Hudi、Delta 和 Iceberg 都將數(shù)據(jù)寫入和存儲在 parquet 文件中。發(fā)生更新時,這些 parquet 文件會進(jìn)行版本控制和重寫。這種寫模式模式就是業(yè)界現(xiàn)在所說的寫時復(fù)制 (CoW)。此模型非常適合優(yōu)化查詢性能,但可能會限制寫入性能和數(shù)據(jù)新鮮度。除了 CoW,Apache Hudi 還支持另一種表存儲布局,稱為Merge On Read(鐵道部)。MoR 使用列式 parquet 文件和基于行的 Avro 日志文件的組合來存儲數(shù)據(jù)。更新可以在日志文件中批量處理,以后可以同步或異步壓縮到新的 parquet 文件中,以平衡最大查詢性能和降低寫入放大。
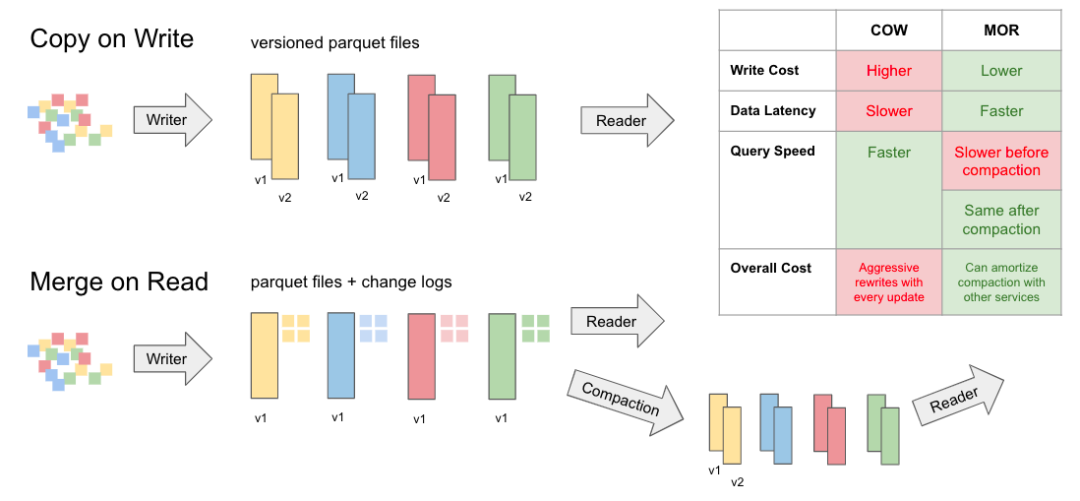
因此,對于近乎實時的流式工作負(fù)載,Hudi 可以使用更高效的面向行的格式,而對于批處理工作負(fù)載,hudi 格式使用可矢量化的面向列的格式,并在需要時無縫合并兩種格式。許多用戶轉(zhuǎn)向 Apache Hudi,因為它是唯一具有此功能的項目,可讓他們實現(xiàn)無與倫比的寫入性能和 E2E 數(shù)據(jù)管道延遲。
分區(qū)演進(jìn)
Apache Iceberg 經(jīng)常強調(diào)的一個特性是隱藏分區(qū),它解鎖了所謂的分區(qū)演化。基本思想是當(dāng)您的數(shù)據(jù)開始演變,或者您只是沒有從當(dāng)前分區(qū)方案中獲得所需的性能價值時,分區(qū)演變允許您更新分區(qū)以獲取新數(shù)據(jù)而無需重寫數(shù)據(jù)。當(dāng)你進(jìn)化你的分區(qū)時,舊數(shù)據(jù)會留在舊的分區(qū)方案中,只有新數(shù)據(jù)會隨著你的進(jìn)化而分區(qū)。如果用戶不了解演化歷史,則以多種方式分區(qū)的表會將復(fù)雜性推給用戶,并且無法保證一致的性能。
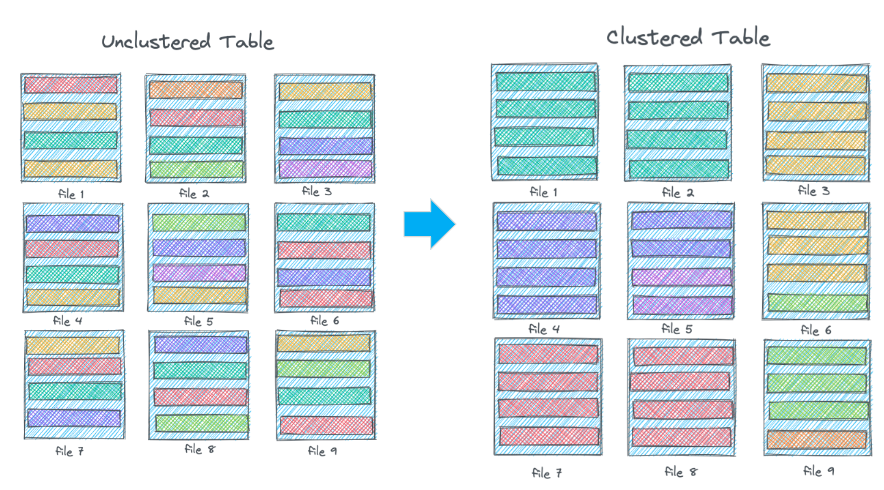
Apache Hudi 采用不同的方法來解決隨著數(shù)據(jù)隨著集群的發(fā)展而調(diào)整數(shù)據(jù)布局的問題。您可以選擇粗粒度的分區(qū)策略,甚至不分區(qū),并在每個分區(qū)內(nèi)使用更細(xì)粒度的集群策略。集群可以同步或異步運行,并且可以在不重寫任何數(shù)據(jù)的情況下進(jìn)行演進(jìn)。這種方法可以與Snowflake的微分區(qū)和集群策略相媲美。
多模式索引

索引是數(shù)據(jù)庫和數(shù)據(jù)倉庫不可或缺的組成部分,但在數(shù)據(jù)湖中基本上不存在。在最近的版本中,Apache Hudi 為 Lakehouse 創(chuàng)建了首創(chuàng)的高性能索引子系統(tǒng),我們稱之為Hudi 多模式索引。Apache Hudi 提供了一種異步索引機制,允許您在不影響寫入延遲的情況下構(gòu)建和更改索引。這種索引機制具有可擴展性和可擴展性,可以支持任何流行的索引技術(shù),例如 Bloom、Hash、Bitmap、R-tree 等。
這些索引存儲在Hudi 元數(shù)據(jù)表中,該表存儲在數(shù)據(jù)旁邊的云存儲中。在這個新版本中,元數(shù)據(jù)以優(yōu)化的索引文件格式編寫,與 Delta 或 Iceberg 通用文件格式相比,點查找的性能提高了 10-100 倍。在測試真實世界的工作負(fù)載時,這個新的索引子系統(tǒng)可將整體查詢性能提高 10-30 倍。
攝取工具
數(shù)據(jù)平臺與數(shù)據(jù)格式的不同之處在于可用的運營服務(wù)。Apache Hudi 的一個與眾不同之處是名為DeltaStreamer的強大攝取實用程序。DeltaStreamer 經(jīng)過實戰(zhàn)測試并在生產(chǎn)中使用,以構(gòu)建當(dāng)今地球上一些最大的數(shù)據(jù)湖。DeltaStreamer 是一個獨立的實用程序,它允許您從各種來源(如 DFS、Kafka、數(shù)據(jù)庫更改日志、S3 事件、JDBC 等)增量攝取上游更改。
Iceberg 沒有托管攝取實用程序的解決方案,而 Delta Autoloader 仍然是 Databricks 的專有功能,僅支持 S3 等云存儲源。
User Cases: 來自社區(qū)的案例
功能比較和基準(zhǔn)測試可以幫助新手確定可用的技術(shù)選擇,但更重要的是評估您的個人用例和工作負(fù)載,以找到適合您的數(shù)據(jù)架構(gòu)的合適方式。所有這三種技術(shù),Hudi、Delta、Iceberg,對于某些用例都有不同的起源故事和優(yōu)勢。Iceberg 誕生于 Netflix,旨在解決文件列表等云存儲規(guī)模問題。Delta 誕生于 Databricks,它在使用 Databricks Spark 運行時具有深度集成和加速功能。Hudi 誕生于 Uber,旨在為近乎實時的 PB 級數(shù)據(jù)湖提供支持,并提供無痛的表管理。
經(jīng)過多年在社區(qū)中參與現(xiàn)實世界的比較評估,當(dāng)您擁有超越簡單的僅附加插入的成熟工作負(fù)載時,Apache Hudi 通常具有技術(shù)優(yōu)勢。一旦您開始處理許多更新、開始添加真正的并發(fā)性或嘗試減少管道的 E2E 延遲,Apache Hudi 就會在性能和功能集方面成為行業(yè)領(lǐng)導(dǎo)者。
以下是來自社區(qū)的幾個示例和故事,他們獨立評估并決定使用 Apache Hudi:
亞馬遜Package Delivery System
“ATS 面臨的最大挑戰(zhàn)之一是處理 PB 級數(shù)據(jù),需要以最小的時間延遲進(jìn)行持續(xù)的插入、更新和刪除,這反映了真實的業(yè)務(wù)場景和數(shù)據(jù)包向下游數(shù)據(jù)消費者的移動。”
“在這篇文章中,我們展示了我們?nèi)绾我悦啃r數(shù)百 GB 的速度實時攝取數(shù)據(jù),并使用使用 AWS Glue Spark 作業(yè)和其他方法加載的Apache Hudi表在 PB 級數(shù)據(jù)湖上運行插入、更新和刪除操作。AWS 無服務(wù)器服務(wù),包括 AWS Lambda、Amazon Kinesis Data Firehose 和 Amazon DynamoDB”
字節(jié)跳動/抖音
“在我們的場景中,性能挑戰(zhàn)是巨大的。單表最大數(shù)據(jù)量達(dá)到400PB+,日增量為PB級,總數(shù)據(jù)量達(dá)到EB級。”
“吞吐量比較大。單表吞吐量超過100GB/s,單表需要PB級存儲。數(shù)據(jù)模式很復(fù)雜。數(shù)據(jù)是高維和稀疏的。表格列的數(shù)量范圍從 1,000 到 10,000+。而且有很多復(fù)雜的數(shù)據(jù)類型。”
“在決定引擎時,我們檢查了三個最流行的數(shù)據(jù)湖引擎,Hudi、Iceberg 和 DeltaLake。這三者在我們的場景中各有優(yōu)缺點。最終選擇Hudi作為存儲引擎是基于Hudi對上下游生態(tài)的開放性、對全局索引的支持,以及針對某些存儲邏輯的定制化開發(fā)接口。”
沃爾瑪
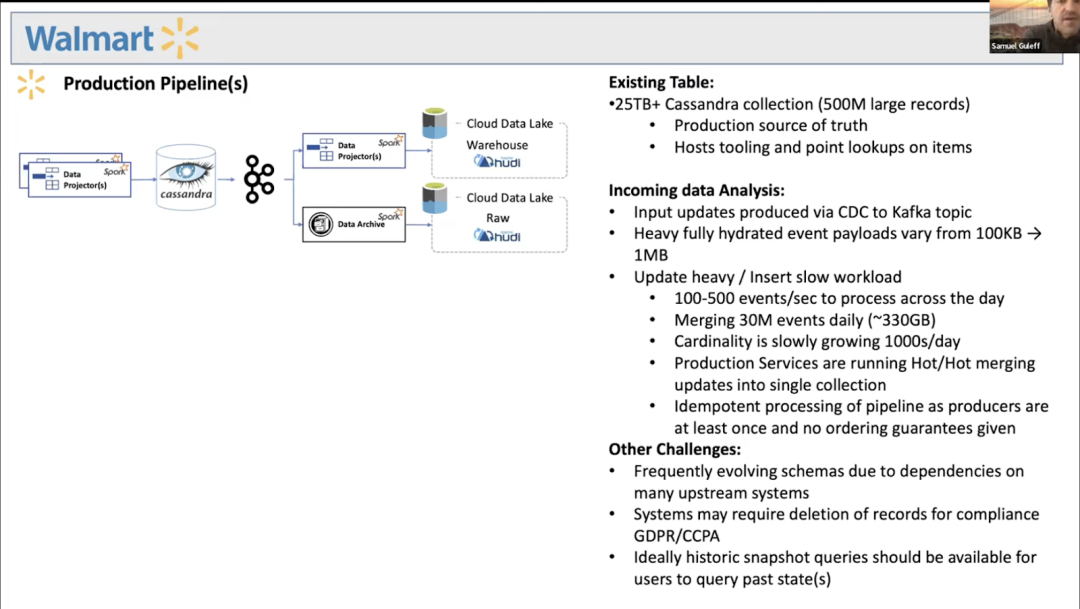
從視頻轉(zhuǎn)錄:
“好吧,是什么讓我們?yōu)槲覀兲峁┝酥С郑瑸槭裁次覀冋娴暮芟矚g在其他用例中解鎖了這一功能的Hudi功能?我們喜歡我們可以使用的樂觀并發(fā)或 mvcc 控件。我們圍繞異步壓縮做了很多工作。我們正在考慮對讀取表的合并進(jìn)行異步壓縮而不是內(nèi)聯(lián)壓縮。
我們還希望減少延遲,因此我們顯著利用了讀取表上的合并,因為這使我們能夠更快地追加數(shù)據(jù)。我們也喜歡對刪除的原生支持。這是我們?yōu)?ccpa 和 gdpr 之類的東西構(gòu)建的自定義框架,有人會在其中放入服務(wù)臺票,我們必須構(gòu)建一個自動化流程來從 hdfs 中刪除記錄,這對我們來說是開箱即用的。
行版本控制非常重要,顯然我們的很多管道都有亂序數(shù)據(jù),我們需要顯示最新的記錄,因此我們提供版本密鑰作為我們框架的一部分,用于將所有 upsert 插入到hudi 表中。
客戶可以選擇要保留多少行版本,從而能夠提供快照查詢并獲得增量更新(例如過去五個小時內(nèi)更新的內(nèi)容),這一事實對很多用戶來說真的很強大”
羅賓漢
“Robinhood 確實需要保持?jǐn)?shù)據(jù)湖的低數(shù)據(jù)新鮮度。許多過去在市場時間之后或之前以每日節(jié)奏運行的批處理管道必須以每小時或更高的頻率運行,以支持不斷發(fā)展的用例。很明顯,我們需要更快的攝取管道將在線數(shù)據(jù)庫復(fù)制到數(shù)據(jù)湖。”
“我們正在使用Apache Hudi從 Kafka 增量攝取變更日志,以創(chuàng)建數(shù)據(jù)湖表。Apache Hudi 是一個統(tǒng)一的數(shù)據(jù)湖平臺,用于在數(shù)據(jù)湖上執(zhí)行批處理和流處理。Apache Hudi 帶有一個功能齊全的基于 Spark 的開箱即用的攝取系統(tǒng),稱為 Deltastreamer,具有一流的 Kafka 集成和一次性寫入功能。與不可變數(shù)據(jù)不同,我們的 CDC 數(shù)據(jù)有相當(dāng)大比例的更新和刪除。Hudi Deltastreamer 利用其可插入的記錄級索引在 Data Lake 表上執(zhí)行快速高效的 upserts。”
Zendesk
“數(shù)據(jù)湖管道將 Zendesk 高度分布式數(shù)據(jù)庫中的數(shù)據(jù)整合到數(shù)據(jù)湖中進(jìn)行分析。
Zendesk 使用 Amazon Database Migration Service (AWS DMS) 從 8 個 AWS 區(qū)域的 1,800 多個 Amazon Aurora MySQL 數(shù)據(jù)庫中捕獲變更數(shù)據(jù) (CDC)。它使用 Amazon EMR 和Hudi檢測事務(wù)更改并將其應(yīng)用到數(shù)據(jù)湖。
Zendesk 票證數(shù)據(jù)包含超過 100 億個事件和 PB 級數(shù)據(jù)。Amazon S3 中的數(shù)據(jù)湖文件以Apache Hudi格式進(jìn)行轉(zhuǎn)換和存儲,并在 AWS Glue 目錄中注冊,可用作數(shù)據(jù)湖表,用于通過 Amazon Athena 進(jìn)行分析查詢和使用。”
GE航空
“在 AWS 中引入更無縫的Apache Hudi體驗對我們的團(tuán)隊來說是一個巨大的勝利。我們一直忙于將 Hudi 整合到我們的 CDC 交易管道中,并且對結(jié)果感到非常興奮。我們能夠花更少的時間編寫代碼來管理我們的數(shù)據(jù)存儲,而將更多的時間集中在我們系統(tǒng)的可靠性上。這對我們的擴展能力至關(guān)重要。隨著我們接近另一個主要的生產(chǎn)切換,我們的開發(fā)管道已超過 10,000 個表和 150 多個源系統(tǒng)。”
最后,鑒于 Lakehouse 技術(shù)的發(fā)展速度有多快,重要的是要考慮該領(lǐng)域的開源創(chuàng)新來自何處。以下是一些起源于 Hudi 的基本思想和功能,現(xiàn)在正在被其他項目采用。
?
事實上,除了表元數(shù)據(jù)(文件列表、列統(tǒng)計信息)支持之外,Hudi 社區(qū)還開創(chuàng)了構(gòu)成當(dāng)今湖屋的大多數(shù)其他關(guān)鍵功能。在過去的 4 年里,該社區(qū)已經(jīng)支持了 1500 多個用戶問題和 5500 多個 slack 支持線程,并且正在以雄心勃勃的愿景迅速發(fā)展壯大。用戶可以將這種創(chuàng)新記錄視為未來的領(lǐng)先指標(biāo)。
在為您的 Lakehouse 選擇技術(shù)時,對您自己的個人用例進(jìn)行評估非常重要。功能比較電子表格和基準(zhǔn)測試不應(yīng)該是最終的決定因素,因此我們希望這篇博文只是為您在決策過程中提供一個起點和參考。Apache Hudi 具有創(chuàng)新性,久經(jīng)沙場,并且會一直存在。加入我們的Hudi Slack,您可以在其中提出問題并與來自全球的充滿活力的社區(qū)合作。
如果您希望通過一對一咨詢深入了解您的用例和架構(gòu),請隨時通過[email protected] 聯(lián)系。在 Onehouse,我們在設(shè)計、構(gòu)建和運營世界上一些最大的分布式數(shù)據(jù)系統(tǒng)方面擁有數(shù)十年的經(jīng)驗。我們認(rèn)識到這些技術(shù)很復(fù)雜且發(fā)展迅速。很可能我們錯過了某個功能,或者可能在上述一些比較中錯誤地閱讀了文檔。如果您看到以上任何需要更正的比較,請給[email protected] 留言,以便我們在本文中保持事實的準(zhǔn)確性。