Mysql的explain,你真的會用嗎?
引言
數(shù)據(jù)庫性能優(yōu)化是每個后端程序猿必備的基礎技能之一,而Mysql中的explain堪稱Mysql的性能優(yōu)化分析神器,我們可以通過它來分析SQL語句的對應的執(zhí)行計劃在Mysql底層到底是如何執(zhí)行的,它對于我們評估SQL的執(zhí)行效率以及確定Mysql的性能優(yōu)化方向具有重要的意義。但是很多同學對于如何根據(jù)explain對已有SQL進行深度的執(zhí)行分析還是丈二和尚摸不著頭腦,因此本文詳細闡述通過explain分析定位數(shù)據(jù)庫性能問題。
explain基礎
對于每個SQL來說,當它被客戶端發(fā)送到Mysql服務端之后,會經過Mysql的優(yōu)化器部件的分析,主要包括一些特殊的處理、執(zhí)行順序的改變以確保最優(yōu)的執(zhí)行效率,最終生成對應的執(zhí)行計劃。所謂的執(zhí)行計劃,實際就是在存儲引擎層面如何獲取數(shù)據(jù)的,是通過索引獲取數(shù)據(jù)還是進行全表掃描獲取數(shù)據(jù),獲取到數(shù)據(jù)后需不需要回表,等等,簡單理解就是Mysql獲取數(shù)據(jù)的過程。
接下來我們來詳細看下,這個explain到底是何方神圣,為什么能指導我們進行性能優(yōu)化。當我們執(zhí)行如下語句:
explain?SELECT?*?FROM?user_info?where?NAME='mufeng'explain?SELECT?*?FROM?user_info?where?NAME='mufeng'
執(zhí)行explain語句之后,我們會得到如下的執(zhí)行結果,這個類似數(shù)據(jù)庫表的12個字段實際上就是對Mysql執(zhí)行怎樣的執(zhí)行計劃的詳細描述。下面我們來好好研究下這12個字段分別代表什么意思,只有搞清楚它們的含義,我們才能明確Mysql到底是怎么執(zhí)行數(shù)據(jù)查詢的。

1、id
實際上每次select查詢都會對應一個id,它代表著SQL執(zhí)行的順序,如果id值越大,說明對應的SQL語句執(zhí)行的優(yōu)先級越高。在一些復雜的查詢SQL語句中常常包含一些子查詢,那么id序號就會遞增,如果出現(xiàn)嵌套查詢,我們可以發(fā)現(xiàn)最里層的查詢對應的id最大,因此也優(yōu)先被執(zhí)行。

如上圖所示,SQL查詢語句中,第一個執(zhí)行計劃的id為1,第二個執(zhí)行計劃的id為2,id為1的執(zhí)行計劃對應的table為order,id為2的執(zhí)行計劃對應的table是user_info,結合SQL語句,我們知道先執(zhí)行子查詢select id from user_info,而后再執(zhí)行關于表order的數(shù)據(jù)查詢。
2、select_type
select_type表示的執(zhí)行計劃的對應的查詢是什么類型,常見的查詢類型主要包括普通查詢、聯(lián)合查詢以及子查詢等。SIMPLE(查詢語句為簡單的查詢不包含子查詢)、PRIMARY(當查詢語句中包含子查詢的時候,對應最外層的查詢類型)、UNION(union之后出現(xiàn)的select語句對應的查詢類型會標記此類型)、SUBQUERY(子查詢會被標記為此類型)、DEPENDENT SUBQUERY(取決于外面的查詢 )。

3、table
table代表表名稱,表示要查詢哪張表。當然不一定是真實的表的名稱,也可能是表的別名或者臨時表。
4、partitions
partitions代表的是分區(qū)的概念,表示在進行查詢時,如果對應的表存在分區(qū)表,那么這里就會顯示具體的分區(qū)信息。
5、type
type是非常核心的屬性,需要重點掌握。它表示的是當前通過什么樣的方式對數(shù)據(jù)庫表進行分訪問。

(1)system
該表只有一行(相當于系統(tǒng)表),數(shù)據(jù)量很小,查詢速度很快,system是const類型的特例。
(2)const
如果type是const,說明在進行數(shù)據(jù)查詢的時候,命中了primary key或唯一索引,此類數(shù)據(jù)查詢速度非常快。

(3)eq_ref
在進行數(shù)據(jù)查詢的過程中,如果SQL語句中在表連接情況下可以基于聚簇索引或者非null值的唯一索引記性數(shù)據(jù)掃描,那么此時type對應的值就會顯示為eq_ref。
(4)ref
數(shù)據(jù)查詢的時候如果命中的索引是二級索引不是唯一索引,測試查詢速度也會很快,但是type是ref。另外如果是多字段的聯(lián)合索引,那么根據(jù)最左匹配原則,從聯(lián)合索引的最左側開始連續(xù)多個列的字段進行等值比較也是ref的類型。

(5)ref_or_null
這種連接類型類似于 ref,區(qū)別在于 MySQL會額外搜索包含NULL值的行。
(7)unique_subquery
在where條件中的關于in的子查詢條件集合
(8)index_subquery
區(qū)別于unique_subquery,用于非唯一索引,可以返回重復值。
(9)range
使用索引進行行數(shù)據(jù)檢索,只對指定范圍內的行數(shù)據(jù)進行檢索。換句話說就是針對一個有索引的字段,在指定范圍中檢索數(shù)據(jù)。在where語句中使用 bettween...and、<、>、<=、in 等條件查詢 type 都是 range。

(10)index
Index 與ALL 其實都是讀全表,區(qū)別在于index是遍歷索引樹讀取,而ALL是從硬盤中讀取。
(11)all
遍歷全表進行數(shù)據(jù)匹配,此時的數(shù)據(jù)查詢性能最差。
6、possible_keys
表示哪些索引可以被Mysql的優(yōu)化器進行選擇,也就是索引候選者有哪些。
7、key
在possible_keys中實際選擇的索引
8、key_len
表示索引的長度,和實際的字段屬性以及是否為null都有關系。
9、ref
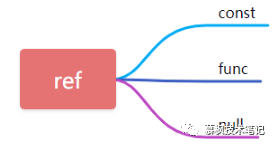
當使用字段進行常量等值查詢時ref此處為const,當查詢條件中使用了表達式或者函數(shù)則ref顯示為func,則其他的顯示為null。
10、rows
rows列顯示MySQL認為它執(zhí)行查詢時必須檢查的行數(shù)。行數(shù)越少,效率越高!
11、filtered
filtered 這個是一個百分比的值,表里符合條件的記錄數(shù)的百分比。簡單點說,這個字段表示存儲引擎返回的數(shù)據(jù)在經過過濾后,剩下的記錄滿足條件的記錄數(shù)量的比例。
12、extra
在其他列不顯示額外信息在此列進行展示。
(1)Using index
在進行數(shù)據(jù)查詢的時候,數(shù)據(jù)庫使用了覆蓋索引,就是查詢的列被索引覆蓋,使用到覆蓋索引查詢速度會非常快。不是使用select * ,而是使用select phone_number,就會用到覆蓋索引。

(2)Using where
?查詢時未找到可用的索引,進而通過where條件過濾獲取所需數(shù)據(jù),但要注意的是并不是所有帶where語句的查詢都會顯示Using where。

(3)Using temporary
表示查詢后結果需要使用臨時表來存儲,一般在排序或者分組查詢時用到。
(4)Using filesort
此類型表示無法利用索引完成指定的排序操作,也就是ORDER BY的字段實際沒有索引,因此此類SQL是需要進行優(yōu)化的。
explain分析實戰(zhàn)
上文中我們闡述了explain在分析SQL語句時,可以通過12個屬性來分析SQL的大致執(zhí)行過程,并以此來判斷SQL存在的性能問題。那么接下來我們通過一個實際的例子,來具體看下如何結合explain來實現(xiàn)SQL的性能分析。
其實所謂的Mysql性能問題,大部分都指的是平臺出現(xiàn)了慢查詢問題。慢查詢實際上是可以通過配置進行記錄的,把執(zhí)行時間超過某個設定的閾值的sql都記錄下來,當出現(xiàn)問題的時候可以通過記錄的慢查詢日志進行問題的定位。但是有的時候,出現(xiàn)大量慢查詢會導致數(shù)據(jù)庫連接被占滿,導致整個平臺的出現(xiàn)異常。
實際上我們在產品評價表product_evaluation中是建立了索引的,正常來說應該是可以使用到對應的索引字段進行查詢的。但是實際上查詢耗時有幾十秒的時間,遠遠超過我們的預期。那我們猜測是不是由于某種原因導致Mysql優(yōu)化器沒有選擇對應的索引進行數(shù)據(jù)檢索,最后造成慢查詢的發(fā)生。到底執(zhí)行計劃是怎樣的,還是得借助于explain來看下。

如上文所說,雖然explain有12個字段屬性幫助我們進行執(zhí)行計劃的分析,但是實際上常用的核心字段也就幾個。我們可以看的出來在possible_key中實際上包含了我們設置的索引的,但是實際上Mysql卻選擇了PRIMARY作為其實際使用的。那么問題來了,為什么明明設置了索引,但是實際并沒有用上,被Mysql吃了嗎?另外為什么之前的業(yè)務中沒有出現(xiàn)這個問題,而現(xiàn)在出現(xiàn)了?我們需要進行進一步的分析。
我們所建立的idx_evaluation_type實際上是一個二級索引(葉子節(jié)點是主鍵id),對于數(shù)千萬一張的大表來說,實際上這個二級索引也是非常大的,而且這個字段本身的值就三個,變化不大。因此Mysql的優(yōu)化器在分析這個SQL的時候發(fā)現(xiàn),如果按照SQL中的索引來獲取數(shù)據(jù)后再根據(jù)where條件進行篩選,篩選后的數(shù)據(jù)還需要回表到聚簇索引中獲取實際的數(shù)據(jù)。
假如通過二級索引篩選出來的數(shù)據(jù)有幾萬條,而后還需要進行排序,這些操作都是基于臨時磁盤我恩建進行的,Mysql判斷這種方式的性能可能會很差,因此優(yōu)化器放棄了原有的數(shù)據(jù)查詢方式,直接通過主鍵id對應的聚簇索引來進行數(shù)據(jù)的獲取,因為id本身就是有序的。
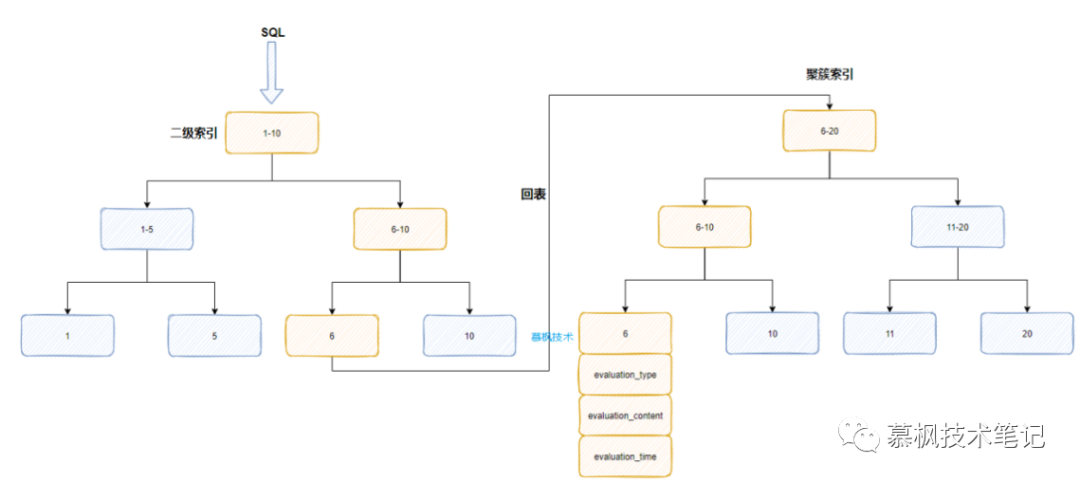
那么知道了查詢慢的原因,我們應該怎么進行優(yōu)化呢?實際上可以在SQL語句中增加force idnex,強制Mysql使用我們設置的二級索引。
SELECT?*?FROM?product_evaluation?force?index(idx_product_id)WHERE?product_id?=1?and?evaluation_type='GOOD'??ORDER?BY?id?desc?LIMIT?200SELECT?*?FROM?product_evaluation?force?index(idx_product_id)WHERE?product_id?=1?and?evaluation_type='GOOD'??ORDER?BY?id?desc?LIMIT?200
總結
通過上文對于explain使用的介紹,大家在遇到慢SQL問題的時候,可以先通過explain來進行初步的分析,主要明確SQL在Mysql中實際的執(zhí)行過程是怎樣的,如果查詢字段沒有索引則增加索引,如果有索引就要分析為什么沒有用到索引。只要明確具體的執(zhí)行過程,我們才能確定具體的查詢優(yōu)化方案。