
MySQL的varchar水真的太深了,你真的會用嗎?
點擊上方“程序員大白”,選擇“星標”公眾號
重磅干貨,第一時間送達


來源:liuchenyang0515.blog.csdn.net/article/
details/117524328
1. InnoDB是干嘛的?
InnoDB是一個將表中的數(shù)據(jù)存儲到磁盤上的存儲引擎。
2. InnoDB是如何讀寫數(shù)據(jù)的?
InnoDB處理數(shù)據(jù)的過程是發(fā)生在內存中的,需要把磁盤中的數(shù)據(jù)加載到內存中,如果是處理寫入或修改請求的話,還需要把內存中的內容刷新到磁盤上。
讀寫磁盤的速度非常慢,和內存讀寫差了幾個數(shù)量級,所以當我們想從表中獲取某些記錄時,InnoDB存儲引擎將數(shù)據(jù)劃分為若干個頁,以頁作為磁盤和內存之間交互的基本單位,InnoDB中頁的大小默認為 16 KB。也就是在一般情況下,一次最少從磁盤中讀取16KB的內容到內存中,或者一次最少把內存中的16KB內容刷新到磁盤中。
所以當你用postman測試一個分頁查詢接口時,發(fā)現(xiàn)第一次打印耗時300 ~ 400ms,往后不停的查找下一頁都是30 ~ 40ms,原因就是第一次請求接口時,讀數(shù)據(jù)庫的時候需要讀磁盤,從磁盤加載16KB的數(shù)據(jù)到內存,往后下一頁的數(shù)據(jù)都是從內存中獲取,沒有再讀磁盤,除非在內存中的16KB的數(shù)據(jù)中找不到,才會再次讀磁盤獲取下一個16KB的數(shù)據(jù)到內存中。
我們不討論mysql 8.0舍棄的查詢緩存特性,我測試過mysql 5.7中關閉了查詢緩存,也仍然是第一次慢,后續(xù)查詢很快,查詢時間相差大概10倍的樣子
溫馨提示:分頁查詢和數(shù)據(jù)庫的一頁16KB中的"頁"是兩個概念。
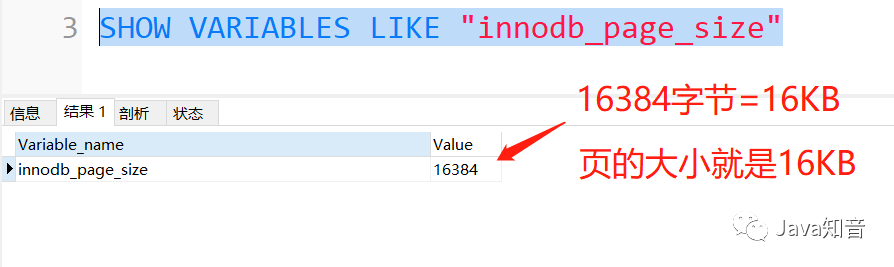
注意:innodb_page_size變量在服務器運行過程中不可以更改,只能在第一次初始化MySQL數(shù)據(jù)目錄時指定。所以頁在運行時的大小不可更改。
3. varchar疑問千千萬——InnoDB行格式
看到這里,你一定有著和我相同的疑問,比如varchar(255)后面這個最大長度應該怎么選擇呢?為什么不能varchar(65535)而最大只能varchar(16383)呢?我來帶你看!
我們平時是以記錄為單位來向表中插入數(shù)據(jù)的,這些記錄在磁盤上的存放方式也被稱為行格式或者記錄格式。行格式有4種,分別是Dynamic、Compact、Redundant和Compressed
MySQL 5+默認行格式都是Dynamic, 在MySQL 5 和 MySQL 8經(jīng)過驗證確實是的。
SHOW?VARIABLES?LIKE?"innodb_default_row_format"

大家在業(yè)務中和平時使用中都幾乎沒有修改過或者注意過InnoDB行格式,那么我就只重點講默認行格式dynamic,讓大家更深層次理解平時開發(fā)中的varchar。
請記住這個表結構,后面會圍繞這個來講
CREATE?TABLE?test?(?
c1?VARCHAR(10),?
c2?VARCHAR(10)?NOT?NULL,?
c3?CHAR(10),?
c4?VARCHAR(10))?CHARSET?=?utf8mb4;
現(xiàn)在業(yè)務數(shù)據(jù)庫字符集都是utf8mb4,我就以這個來講,把理解難度降到最低。
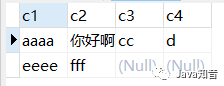
INSERT?INTO?test?(?c1,?c2,?c3,?c4?)
VALUES('aaaa',?'你好啊',?'cc',?'d'),('eeee',?'fff',?NULL,?NULL);
現(xiàn)在,表中的記錄就是這樣
3.1 dynamic——innodb默認行格式

關于記錄的額外信息這部分,是服務器為了描述這條記錄而不得不額外添加的一些信息,這些額外信息分為3類,分別是變長字段長度列表、NULL值列表和記錄頭信息。
在這里我只講變長字段長度列表、NULL值列表。因為記錄頭信息非常的繞和本篇沒多大關系。
3.2 innodb怎么知道varchar真正有多長?——變長字段長度列表
一些變長的數(shù)據(jù)類型,比如VARCHAR(M)、各種TEXT類型,各種BLOB類型,變長數(shù)據(jù)類型的字段中存儲多少字節(jié)的數(shù)據(jù)是不固定的,在存儲真實數(shù)據(jù)的時候需要把這些數(shù)據(jù)占用的字節(jié)數(shù)也存起來。
就像設計String類型,不僅僅是存放真實數(shù)據(jù)的char數(shù)組,還有l(wèi)ength變量去記錄字符串長度。又比如input輸入框最大限制500字,但是你還得有一個變量去統(tǒng)計真實在輸入框內有多少字符。同理,varchar也有記錄真實數(shù)據(jù)長度的變量(假設為L,后文沿用方便描述),L表示varchar真實占用的字節(jié)數(shù),innodb最多分配2個字節(jié)去表示這個L,就像unsigned short類型,2個字節(jié),寄存器最多只有16位來讓你存這個長度,所以L記錄范圍是2^16 - 1 = 65535。
這些變長字段(比如varchar)占用的存儲空間分為兩部分:
真正的數(shù)據(jù)內容部分,放在對應的列 真實占用的字節(jié)數(shù),放在變長字段列表部分
我們拿test表中的第一條記錄來舉個例子。因為test表的c1、c2、c4列都是VARCHAR(10)類型的,說明最大10個字符,所以這三個列的值的長度都需要保存在記錄開頭處,因為test表中的各個列都使用的是utf8mb4字符集,每個字符最大需要4個字節(jié)來進行編碼(不使用utf8而是utf8mb4是因為可能存儲emoji表情,如果只是文字,utf8就足夠),來看一下第一條記錄各變長字段內容的長度:

怎么確定這些字段有多少字節(jié)?
比如這里c2的"你好啊",使用如下sql可以確定
SELECT?LENGTH(c2)?from?test?where?c1='aaaa';


各變長字段數(shù)據(jù)占用的字節(jié)數(shù)按照列的順序逆序存放!!
由于第一行記錄中c1、c2、c4列中的字符串都比較短,也就是說varchar真實占用的字節(jié)數(shù)比較小,L用1個字節(jié)(8個bit位) 就可以表示,但是如果varchar真實占用的字節(jié)數(shù)比較多,L可能就需要用2個字節(jié)(16個bit位) 來表示。到底varchar能存多少字節(jié)呢?繼續(xù)往下看。
3.3 varchar(M) 能存多少個字符,為什么提示最大16383?
首先要理解varchar(M)的M是說字符個數(shù),而不是字節(jié)。
為什么不能varchar(20000)之類的,是20000個字符放不下嗎?
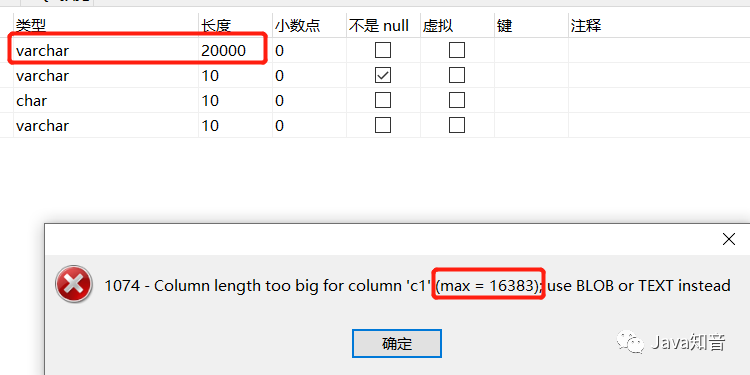
為什么提示只能最大16383個字符呢?這個數(shù)字是怎么算出來的?
這個我就得和你好好嘮嗑了!
varchar是變長的,varchar(64) 能存放0~64個字符不等,并不一定是存了最大64個字符,誰知道這個類型到底存了幾個字符呢?
innodb設計的時候,就已經(jīng)考慮到了,不過是用字節(jié)作為單位,后續(xù)我們可以根據(jù)對應字符集轉變?yōu)樽址麃砝斫猓琲nnodb必須記錄變長字段varchar真實占用的字節(jié)數(shù)L。前面說過了,innodb最多分配2個字節(jié)(16個bit位)的空間去記錄這個L。
InnoDB有它的一套規(guī)則,我們引入W、M和L這幾個符號:
假設某個字符集中最多需要W字節(jié)來表示一個字符 utf8mb4字符集中的W就是4 utf8字符集中W就是3 gbk字符集中的W就是2 ascii字符集中的W就是1。 對于變長類型VARCHAR(M)來說,這種類型表示能存儲最多M個字符(注意是字符不是字節(jié)) 所以這個類型能表示的字符串最多占用的字節(jié)數(shù)就是M × W。 假設它實際存儲的字符串占用的字節(jié)數(shù)是L。
來看極限邊界情況,innodb為了記錄一下varchar真實存儲多少個字節(jié),最多分配2個字節(jié)的空間去記錄,2個字節(jié)16個比特位,全部為1,最大能記錄的數(shù)字是2^16-1是65535個,innodb最大能記錄varchar占用的字節(jié)數(shù)就是65535個,utf8mb4字符集一個字符是最大是4個字節(jié),65535 / 4 = 16383.75,只要varchar字符數(shù)不超過16383個,innodb就可以記錄真實占用的長度L,再多就記錄不了了!所以就能解釋剛剛的圖了,varchar(20000)不行,最大也就16383個字符
但是!這里強調是有但是的!
行最大長度是65535字節(jié),行里面有很多東西,包括變長字段列表、NULL值列表、記錄頭信息。你得考慮該字段如果允許為NULL,NULL值列表會占用一個字節(jié)(只要沒超過8個字段),每一列字段的變長字段實際長度會花費1~2個字節(jié),如果該字段的數(shù)據(jù)太大,會變成溢出列,該字段的數(shù)據(jù)會分成很多行存儲(后面會講,你可以看完NULL值列表和溢出列后再回來看這個例子)。所以即便提示16383個字符,你也絕對不可能存到16383。
我做了個測試
create?table?t2?(?name?varchar(16383))charset=utf8mb4;
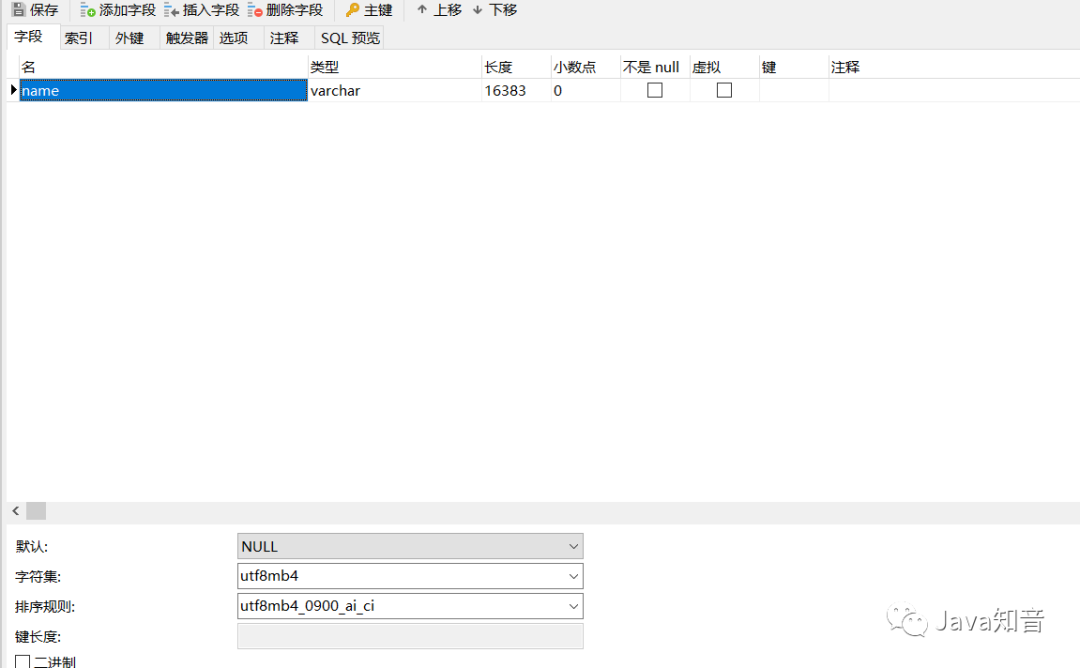
不斷往這個字段添加字符保存測試,最后發(fā)現(xiàn),這些字符總長度到極限也就是48545字節(jié)。
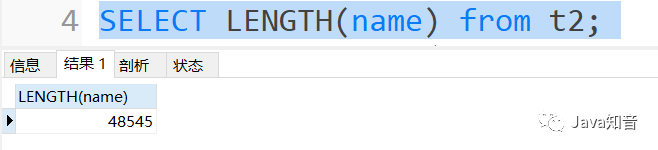
如果超過就會報錯
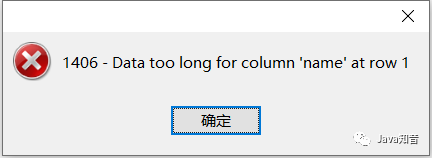
這里48545個字節(jié),再多一個字符就會報錯,遠不到65535字節(jié),差了1W多字節(jié)。主要是因為溢出列的原因,數(shù)據(jù)分散在不同的行中,所以,很長的數(shù)據(jù),建議往text類型考慮。這個現(xiàn)象可以看出,varchar(M)的M很大,實際是達不到M這個邊界值的。
下面說明一下規(guī)則(講解中字符集用utf8mb4,W=4)
規(guī)則一:如果允許存儲的最大字節(jié)數(shù)M × W <= 255,varchar占用的真實字節(jié)數(shù)L只分配1個字節(jié)來表示。
有人說,允許存儲的最大字節(jié)數(shù)M × W <= 255,即允許存儲的最大字符數(shù) <= ?255 / 4? = 63個時,varchar占用的真實字節(jié)數(shù)L僅分配1個字節(jié)就能表示。這個結論正確嗎?
顯然錯誤,因為這里255 / 4,你怎么知道每個存儲的一個字符是4個字節(jié)呢?難道全部存的emoji表情?不存字母漢字啥的?
InnoDB在讀記錄的變長字段長度列表時先查看表結構,如果某個變長字段允許存儲的最大字節(jié)數(shù)不大于255時,只用1個字節(jié)來表示真實數(shù)據(jù)占用的字節(jié)。
規(guī)則二:如果允許存儲的最大字節(jié)數(shù)M × W > 255,則分為兩種情況:
如果實際存儲字節(jié)L <= 127,varchar占用的真實字節(jié)數(shù)L僅分配1個字節(jié)就能表示。(? … ?表示向下取整)
有人說,實際存儲字節(jié)L <= 127,即實際存儲字符 <= ?127 / 4? = 31個時,varchar占用的真實字節(jié)數(shù)L僅分配1個字節(jié)就能表示。這個結論正確嗎?
顯然錯誤,因為這里127 / 4,你怎么知道實際存儲的一個字符是4個字節(jié)呢?難道全部存的emoji表情?不存字母漢字啥的?
如果實際存儲字節(jié)L > 127,varchar占用的真實字節(jié)數(shù)L需要分配2個字節(jié)才能表示。
另外需要注意的是,變長字段列表只存儲非NULL的列的長度。
表記錄是這樣的
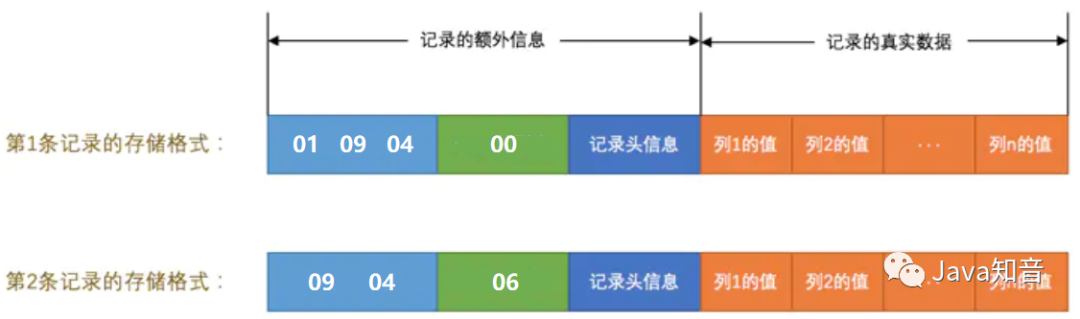
對于第二條記錄,c4列值為NULL,所以只存儲c1和c2列即可。
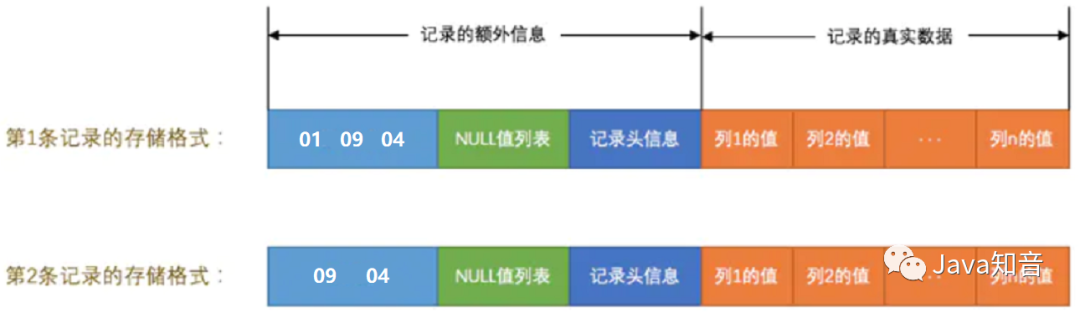
第一條記錄的變長字段長度列表部分占用3字節(jié)空間,因為有c1、c2、c4列,且內容都很少,每列真實占用字節(jié)數(shù)用1個字節(jié)可以表示,加起來就是3個字節(jié),第二條記錄變長字段長度列表部分占用2字節(jié)。
當然,并不是所有記錄都有這個變長字段長度列表部分,比方說表中所有的列都不是變長的數(shù)據(jù)類型或者 所有列的值都是NULL 的話,這一部分就不需要有。實際業(yè)務開發(fā)中,幾乎沒有不使用varchar的,所以實際開發(fā)中的記錄都會有變長字段長度列表部分
3.4 記錄為NULL,innodb如何處理?——NULL值列表
能仔細看到這里,你肯定是個高手了。如果你和我一樣開發(fā)規(guī)范中不推薦NULL,一般都寫NOT NULL,其實記錄中就不存在NULL值列表了,也節(jié)省了空間。
如果表中的某些列可能存儲NULL值,把這些NULL值都放到記錄的真實數(shù)據(jù)中存儲會很占地方,所以dynamic行格式把這些值為NULL的列統(tǒng)一管理起來,存儲到NULL值列表中,它的處理過程是這樣的:
1.統(tǒng)計表中允許存儲NULL的列有哪些。
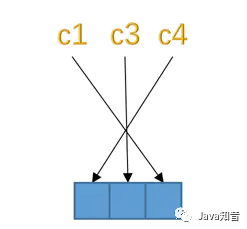
主鍵列、被NOT NULL修飾的列都是不可以存儲NULL值的,所以在統(tǒng)計的時候不會把這些列算進去。比方說表test的3個列c1、c3、c4都是允許存儲NULL值的,而c2列是被NOT NULL修飾,不允許存儲NULL值。
2.如果表中沒有允許存儲 NULL 的列,則 NULL值列表也不存在了,否則將每個允許存儲NULL的列對應一個二進制位,二進制位按照列的順序逆序排列。二進制位的值為1時,代表該列的值為NULL,為0時,代表該列的值不為NULL。因為表test的c1、c3、c4都是允許存儲NULL值的允許為NULL的列,所以這3個列和二進制位的對應關系就是這樣:
3.NULL值列表必須用整數(shù)個字節(jié)的位表示,如果使用的二進制位個數(shù)不是整數(shù)個字節(jié),則在字節(jié)的高位補0。
也就是說,表test只有3個字段允許為NULL,對應3個二進制位,不足1字節(jié),那么就在高位補0即可。
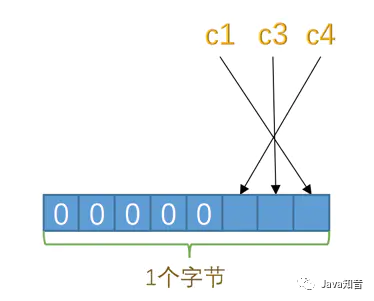
以此類推,如果表中有9個字段都允許為NULL,那么這個記錄的NULL值列表就需要2個字節(jié)來表示,高字節(jié)高位補0。
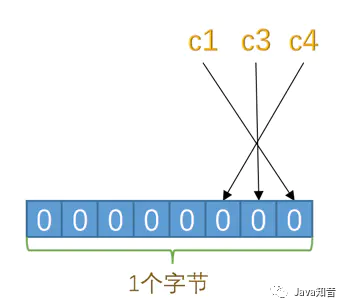
對于第一條記錄,c1、c3、c4都不為NULL,對應的為進制位為0,十六進制表示就是0x00
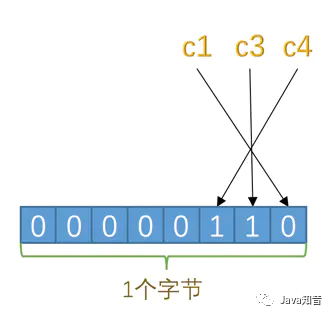
對于第二條記錄,c3、c4都是NULL,對應的二進制位為1,十六進制表示就是0x06
這兩條記錄在填充了NULL值列表后示意圖如下:
3.5 某個列數(shù)據(jù)占用的字節(jié)數(shù)非常多怎么辦?——dynamic行格式的溢出列
如果某個列中存儲的數(shù)據(jù)占用的字節(jié)數(shù)非常多,該列就可能稱為溢出列。
對于占用存儲空間非常多的列,在記錄真實數(shù)據(jù)時,該列只會用20字節(jié)空間,而這20字節(jié)的空間不存儲數(shù)據(jù),因為數(shù)據(jù)都分散存儲在其他幾行中了。這20字節(jié)的空間存儲的是分散行的地址和占用的字節(jié)數(shù)。分散行記錄是單鏈表連接的結構。
后續(xù)
如果大家對innodb存儲結構其他行格式感興趣,或者我沒說的記錄頭信息,可以去閱讀《MySQL是怎樣運行的》一書,我和書中不同的是,書中講的Compact格式,字符集是ascii,我選用的是平時開發(fā)中用到的默認dynamic格式,字符集是utf8mb4,字符集變化后所有的數(shù)據(jù)我在文中和圖中都有重新計算。大家平時或許沒關注過行格式,那么就是按照dynamic格式理解就可以,更貼近實際開發(fā)。
最后,再給大家推薦一個GitHub項目,該項目整理了上千本常用技術PDF,技術書籍都可以在這里找到。 GitHub地址:https://github.com/hello-go-maker/cs-books
推薦閱讀
關于程序員大白
程序員大白是一群哈工大,東北大學,西湖大學和上海交通大學的碩士博士運營維護的號,大家樂于分享高質量文章,喜歡總結知識,歡迎關注[程序員大白],大家一起學習進步!