
PPO算法的一個(gè)簡(jiǎn)單實(shí)現(xiàn):對(duì)話機(jī)器人
-
入門強(qiáng)化學(xué)習(xí)所需掌握的基本概念
-
MDP的前置知識(shí):隨機(jī)過(guò)程、馬爾可夫過(guò)程、馬爾可夫獎(jiǎng)勵(lì)
動(dòng)態(tài)規(guī)劃法--通過(guò)動(dòng)態(tài)規(guī)劃法求解最優(yōu)策略
引入優(yōu)勢(shì)演員-評(píng)論家算法(Advantage Actor-Criti):為避免獎(jiǎng)勵(lì)總為正增加基線
基于信任區(qū)域的TRPO:加進(jìn)KL散度解決兩個(gè)分布相差大或步長(zhǎng)難以確定的問(wèn)題
綜上,PPO算法是一種具體的Actor-Critic算法實(shí)現(xiàn),比如在對(duì)話機(jī)器人中,輸入的prompt是state,輸出的response是action,想要得到的策略就是怎么從prompt生成action能夠得到最大的reward,也就是擬合人類的偏好。具體實(shí)現(xiàn)時(shí),可以按如下兩大步驟實(shí)現(xiàn)
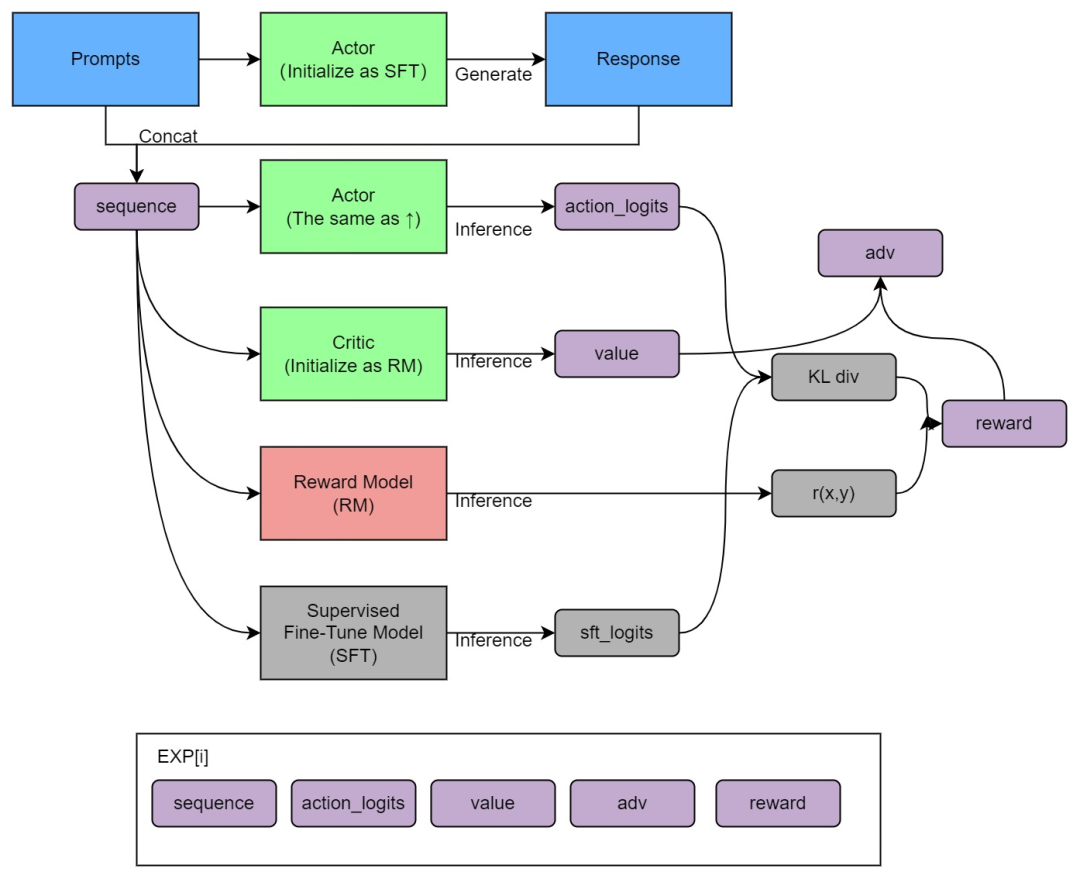
這4個(gè)模型分別為Actor、SFT、Critic、RM,其中:
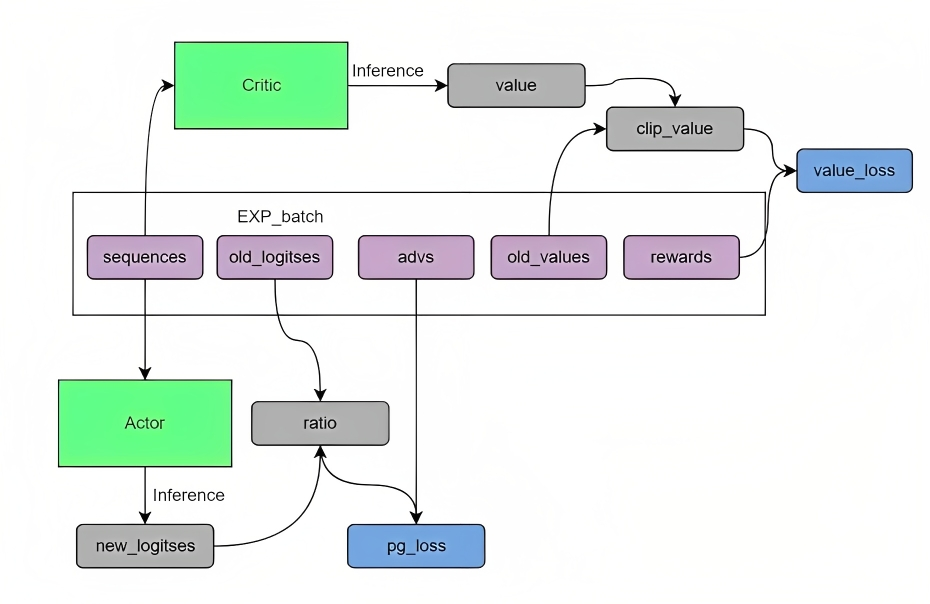
代碼實(shí)現(xiàn)需要的話可以私蘇蘇老師V:julyedukefu008
?
好消息
學(xué)術(shù)/學(xué)業(yè)/職稱論文,申碩/申博,1V1輔導(dǎo)現(xiàn)在需求也越來(lái)越旺,如果你有論文需求,別猶豫,七月在線論文保發(fā);國(guó)內(nèi)外求職1V1輔導(dǎo)也如火如荼進(jìn)行中

有意找蘇蘇老師(VX:julyedukefu008 )或七月在線其他老師申請(qǐng)?jiān)嚶?了解課程
(掃碼聯(lián)系蘇蘇老師)
點(diǎn)擊“閱讀原文”了解更多 -

評(píng)論
圖片
表情