
Prometheus 如何做到“活學(xué)活用”,大牛總結(jié)的避坑指南
公眾號(hào)關(guān)注“杰哥的IT之旅”,
選擇“星標(biāo)”,重磅干貨,第一時(shí)間送達(dá)!

作者丨徐亞松? 來(lái)源丨h(huán)ttp://www.xuyasong.com/?p=1921
監(jiān)控是基礎(chǔ)設(shè)施,目的是為了解決問(wèn)題,不要只朝著大而全去做,尤其是不必要的指標(biāo)采集,浪費(fèi)人力和存儲(chǔ)資源(To B商業(yè)產(chǎn)品例外)。
需要處理的告警才發(fā)出來(lái),發(fā)出來(lái)的告警必須得到處理。
簡(jiǎn)單的架構(gòu)就是最好的架構(gòu),業(yè)務(wù)系統(tǒng)都掛了,監(jiān)控也不能掛。Google Sre 里面也說(shuō)避免使用 Magic 系統(tǒng),例如機(jī)器學(xué)習(xí)報(bào)警閾值、自動(dòng)修復(fù)之類(lèi)。這一點(diǎn)見(jiàn)仁見(jiàn)智吧,感覺(jué)很多公司都在搞智能 AI 運(yùn)維。
Prometheus 是基于 Metric 的監(jiān)控,不適用于日志(Logs)、事件(Event)、調(diào)用鏈(Tracing)。
Prometheus 默認(rèn)是 Pull 模型,合理規(guī)劃你的網(wǎng)絡(luò),盡量不要轉(zhuǎn)發(fā)。
對(duì)于集群化和水平擴(kuò)展,官方和社區(qū)都沒(méi)有銀彈,需要合理選擇 Federate、Cortex、Thanos等方案。
監(jiān)控系統(tǒng)一般情況下可用性大于一致性,容忍部分副本數(shù)據(jù)丟失,保證查詢(xún)請(qǐng)求成功。這個(gè)后面說(shuō) Thanos 去重的時(shí)候會(huì)提到。
Prometheus 不一定保證數(shù)據(jù)準(zhǔn)確,這里的不準(zhǔn)確一是指 rate、histogram_quantile 等函數(shù)會(huì)做統(tǒng)計(jì)和推斷,產(chǎn)生一些反直覺(jué)的結(jié)果,這個(gè)后面會(huì)詳細(xì)展開(kāi)。二來(lái)查詢(xún)范圍過(guò)長(zhǎng)要做降采樣,勢(shì)必會(huì)造成數(shù)據(jù)精度丟失,不過(guò)這是時(shí)序數(shù)據(jù)的特點(diǎn),也是不同于日志系統(tǒng)的地方。
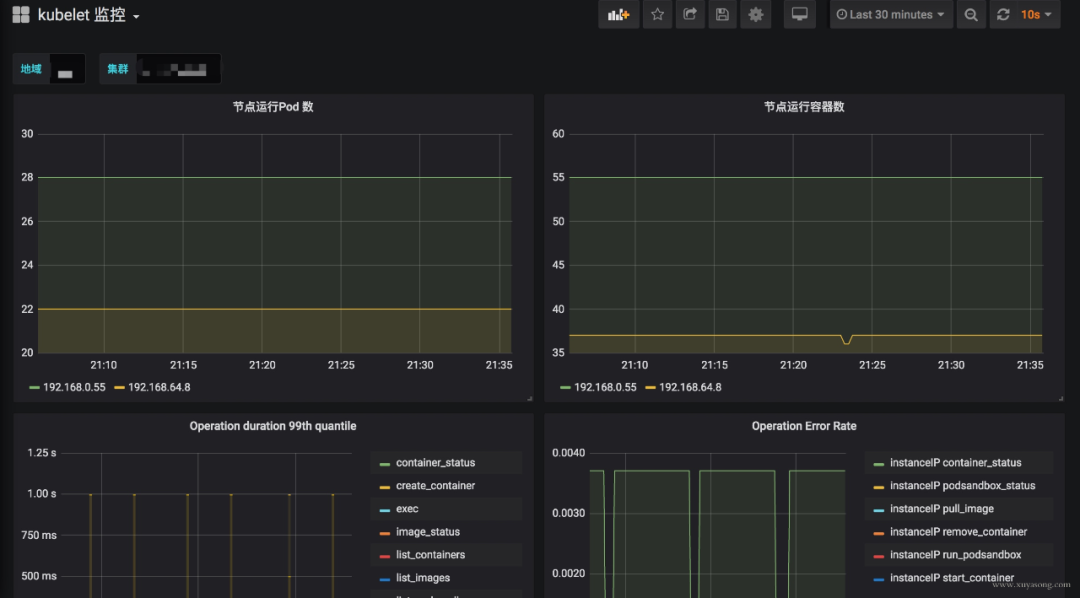
cadvisor: 集成在 Kubelet 中。
kubelet: 10255為非認(rèn)證端口,10250為認(rèn)證端口。
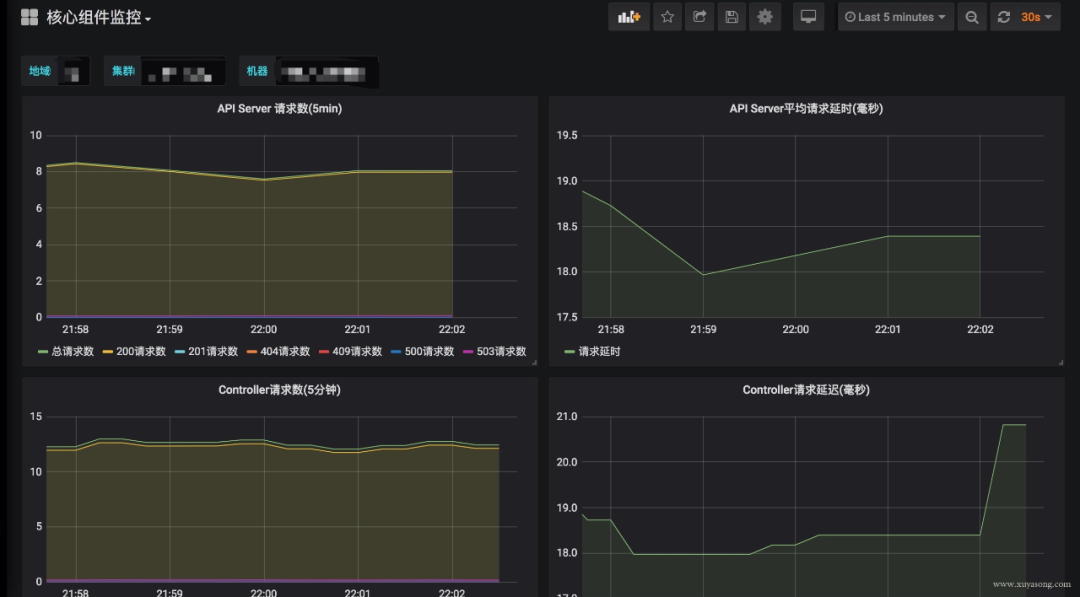
apiserver: 6443端口,關(guān)心請(qǐng)求數(shù)、延遲等。
scheduler: 10251端口。
controller-manager: 10252端口。
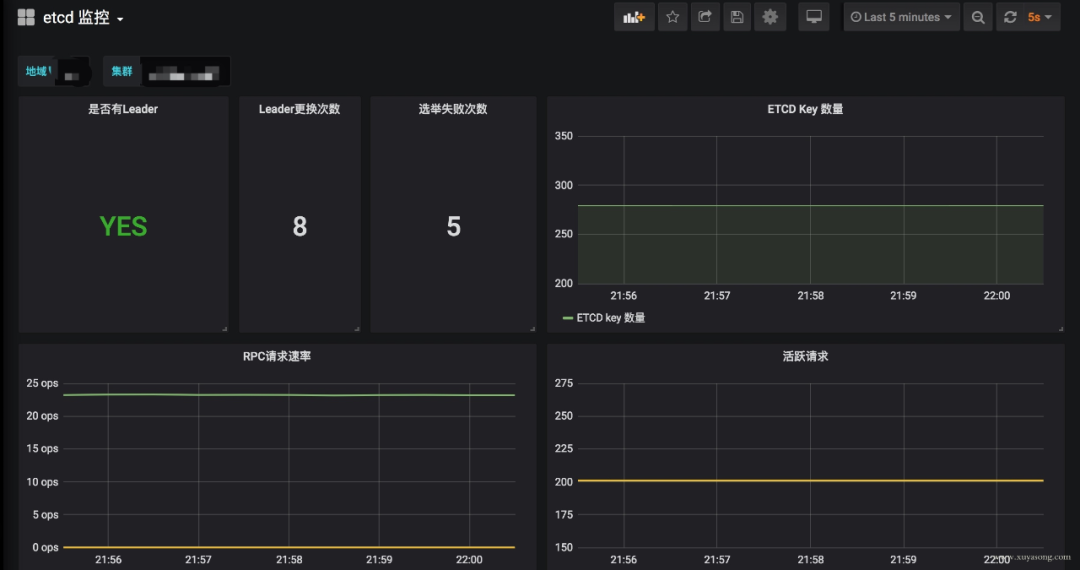
etcd: 如etcd 寫(xiě)入讀取延遲、存儲(chǔ)容量等。
docker: 需要開(kāi)啟 experimental 實(shí)驗(yàn)特性,配置 metrics-addr,如容器創(chuàng)建耗時(shí)等指標(biāo)。
kube-proxy: 默認(rèn) 127 暴露,10249端口。外部采集時(shí)可以修改為 0.0.0.0 監(jiān)聽(tīng),會(huì)暴露:寫(xiě)入 iptables 規(guī)則的耗時(shí)等指標(biāo)。
kube-state-metrics: K8S 官方項(xiàng)目,采集pod、deployment等資源的元信息。
node-exporter: Prometheus 官方項(xiàng)目,采集機(jī)器指標(biāo)如 CPU、內(nèi)存、磁盤(pán)。
blackbox_exporter: Prometheus 官方項(xiàng)目,網(wǎng)絡(luò)探測(cè),dns、ping、http監(jiān)控
process-exporter: 采集進(jìn)程指標(biāo)
nvidia exporter: 我們有 gpu 任務(wù),需要 gpu 數(shù)據(jù)監(jiān)控
node-problem-detector: 即 npd,準(zhǔn)確的說(shuō)不是 exporter,但也會(huì)監(jiān)測(cè)機(jī)器狀態(tài),上報(bào)節(jié)點(diǎn)異常打 taint
應(yīng)用層 exporter: mysql、nginx、mq等,看業(yè)務(wù)需求。

通過(guò)主進(jìn)程拉起N個(gè) Exporter 進(jìn)程,仍然可以跟著社區(qū)版本做更新、bug fix。
用Telegraf來(lái)支持各種類(lèi)型的 Input,N 合 1。
Use 方法:Utilization、Saturation、Errors。如 Cadvisor 數(shù)據(jù)
Red 方法:Rate、Errors、Duration。如 Apiserver 性能指標(biāo)
在線服務(wù):如 Web 服務(wù)、數(shù)據(jù)庫(kù)等,一般關(guān)心請(qǐng)求速率,延遲和錯(cuò)誤率即 RED 方法。
離線服務(wù):如日志處理、消息隊(duì)列等,一般關(guān)注隊(duì)列數(shù)量、進(jìn)行中的數(shù)量,處理速度以及發(fā)生的錯(cuò)誤即 Use 方法。
批處理任務(wù):和離線任務(wù)很像,但是離線任務(wù)是長(zhǎng)期運(yùn)行的,批處理任務(wù)是按計(jì)劃運(yùn)行的,如持續(xù)集成就是批處理任務(wù),對(duì)應(yīng) K8S 中的 job 或 cronjob, 一般關(guān)注所花的時(shí)間、錯(cuò)誤數(shù)等,因?yàn)檫\(yùn)行周期短,很可能還沒(méi)采集到就運(yùn)行結(jié)束了,所以一般使用 Pushgateway,改拉為推。
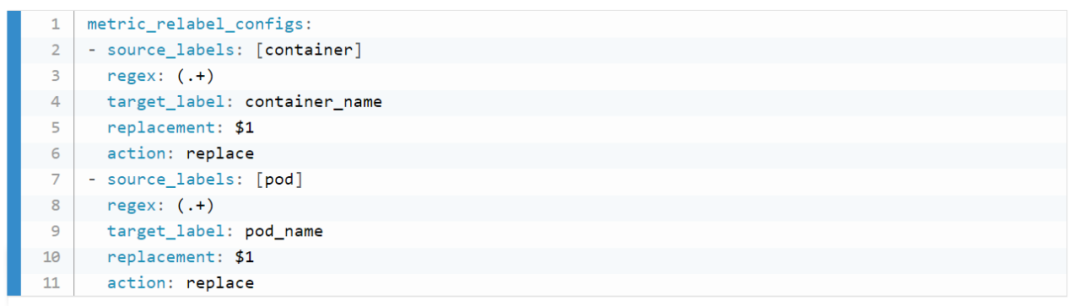



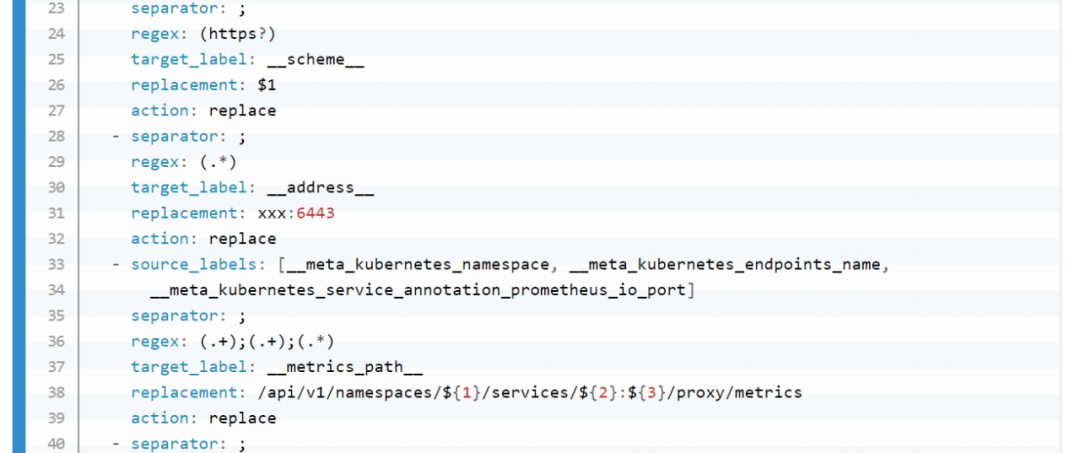
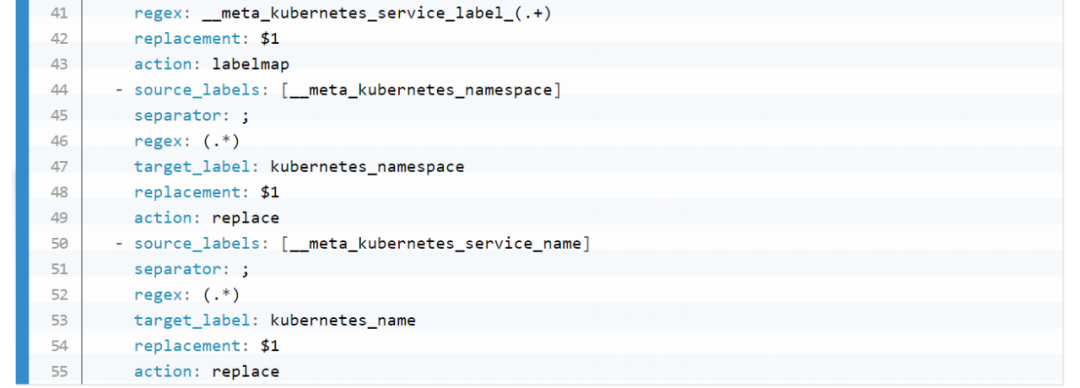
role:node 的,包括 cadvisor、 node-exporter、kubelet 的 summary、kube-proxy、docker 等指標(biāo)。
role:endpoint 的,包括 kube-state-metric 以及其他自定義 Exporter。
普通采集:包括Etcd、Apiserver 性能指標(biāo)、進(jìn)程指標(biāo)等。

如果做可視化,Grafana是可以做時(shí)區(qū)轉(zhuǎn)換的。
如果是調(diào)接口,拿到了數(shù)據(jù)中的時(shí)間戳,你想怎么處理都可以。
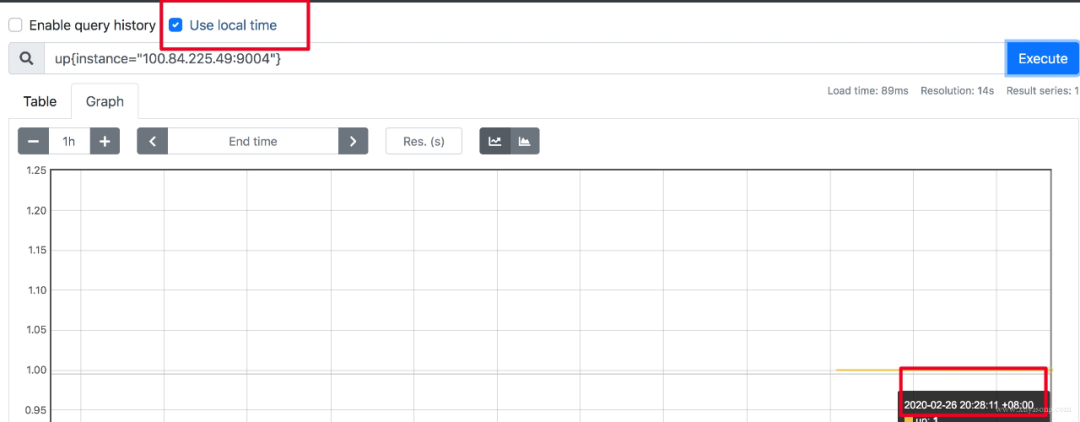
如果因?yàn)?Prometheus 自帶的 UI 不是本地時(shí)間,看著不舒服,2.16 版本的新版 Web UI已經(jīng)引入了Local Timezone 的選項(xiàng),區(qū)別見(jiàn)下圖。
如果你仍然想改 Prometheus 代碼來(lái)適應(yīng)自己的時(shí)區(qū),可以參考《修改源碼更改prometheus的時(shí)區(qū)問(wèn)題》。

RS 的服務(wù)加 Sidecar Proxy,或者本機(jī)增加 Proxy 組件,保證 Prometheus 能訪問(wèn)到。
LB 增加 /backend1 和 /backend2請(qǐng)求轉(zhuǎn)發(fā)到兩個(gè)單獨(dú)的后端,再由 Prometheus 訪問(wèn) LB 采集。
Prometheus 的內(nèi)存消耗主要是因?yàn)槊扛?小時(shí)做一個(gè) Block 數(shù)據(jù)落盤(pán),落盤(pán)之前所有數(shù)據(jù)都在內(nèi)存里面,因此和采集量有關(guān)。
加載歷史數(shù)據(jù)時(shí),是從磁盤(pán)到內(nèi)存的,查詢(xún)范圍越大,內(nèi)存越大。這里面有一定的優(yōu)化空間。
一些不合理的查詢(xún)條件也會(huì)加大內(nèi)存,如 Group 或大范圍 Rate。
作者給了一個(gè)計(jì)算器,設(shè)置指標(biāo)量、采集間隔之類(lèi)的,計(jì)算 Prometheus 需要的理論內(nèi)存值:計(jì)算公式。


Sample 數(shù)量超過(guò)了 200 萬(wàn),就不要單實(shí)例了,做下分片,然后通過(guò) Victoriametrics,Thanos,Trickster 等方案合并數(shù)據(jù)。
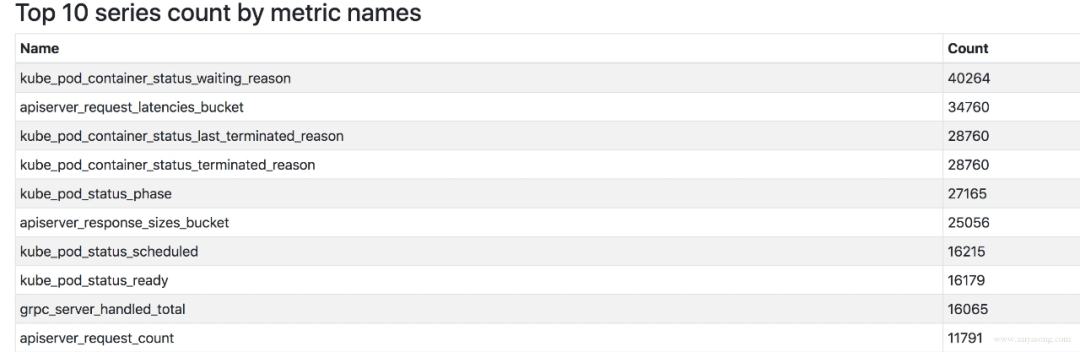
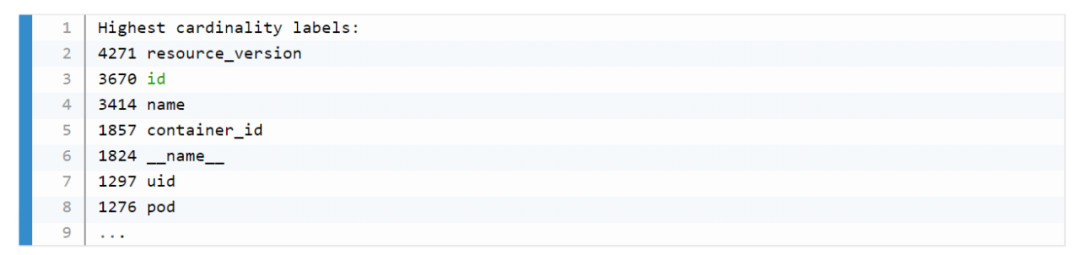
評(píng)估哪些 Metric 和 Label 占用較多,去掉沒(méi)用的指標(biāo)。2.14 以上可以看 Tsdb 狀態(tài)。
查詢(xún)時(shí)盡量避免大范圍查詢(xún),注意時(shí)間范圍和 Step 的比例,慎用 Group。
如果需要關(guān)聯(lián)查詢(xún),先想想能不能通過(guò) Relabel 的方式給原始數(shù)據(jù)多加個(gè) Label,一條Sql 能查出來(lái)的何必用Join,時(shí)序數(shù)據(jù)庫(kù)不是關(guān)系數(shù)據(jù)庫(kù)。
通過(guò) pprof分析:https://www.robustperception.io/optimising-prometheus-2-6-0-memory-usage-with-pprof
1.X 版本的內(nèi)存:https://www.robustperception.io/how-much-ram-does-my-prometheus-need-for-ingestion
https://groups.google.com/forum/#!searchin/prometheus-users/memory%7Csort:date/prometheus-users/q4oiVGU6Bxo/uifpXVw3CwAJ
https://github.com/prometheus/prometheus/issues/5723
https://github.com/prometheus/prometheus/issues/1881
如果是單機(jī)Prometheus,計(jì)算本地磁盤(pán)使用量。
如果是 Remote-Write,和已有的 Tsdb 共用即可。
如果是 Thanos 方案,本地磁盤(pán)可以忽略(2H),計(jì)算對(duì)象存儲(chǔ)的大小就行。


采集頻率 30s,機(jī)器數(shù)量1000,Metric種類(lèi)6000,1000600026024 約 200 億,30G 左右磁盤(pán)。
只采集需要的指標(biāo),如 match[], 或者統(tǒng)計(jì)下最常使用的指標(biāo),性能最差的指標(biāo)。
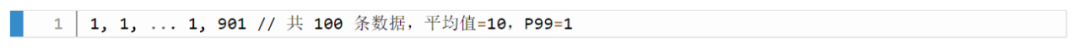



大量使用 join 來(lái)組合指標(biāo)或者增加 label,如將 kube-state-metric 中的一些 meta label和 node-exporter 中的節(jié)點(diǎn)屬性 label加入到 cadvisor容器數(shù)據(jù)里,像統(tǒng)計(jì) pod 內(nèi)存使用率并按照所屬節(jié)點(diǎn)的機(jī)器類(lèi)型分類(lèi),或按照所屬 rs 歸類(lèi)。
范圍查詢(xún)時(shí),大的時(shí)間范圍 step 值卻很小,導(dǎo)致查詢(xún)到的數(shù)量過(guò)大。
rate 會(huì)自動(dòng)處理 counter 重置的問(wèn)題,最好由 promql 完成,不要自己拿出來(lái)全部元數(shù)據(jù)在程序中自己做 rate 計(jì)算。
在使用 rate 時(shí),range duration要大于等于step,否則會(huì)丟失部分?jǐn)?shù)據(jù)
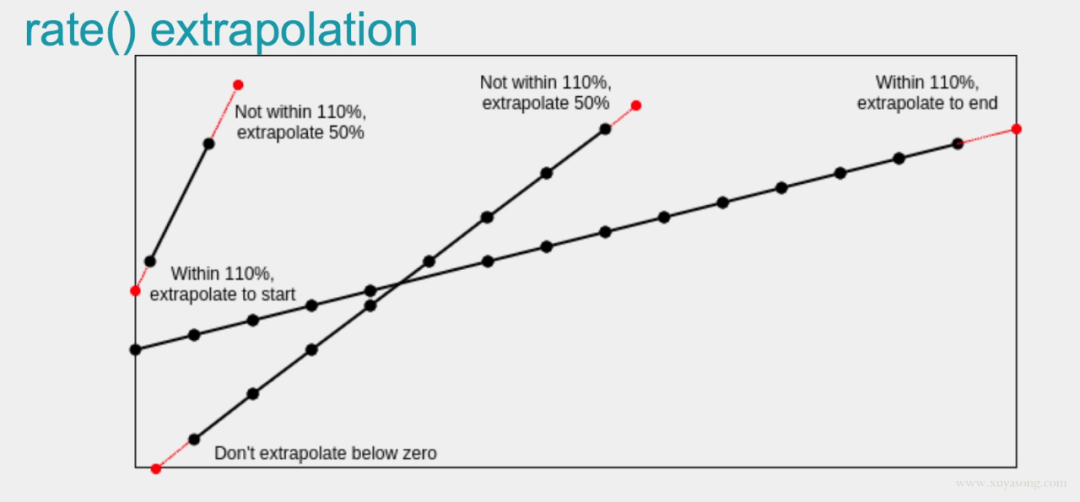
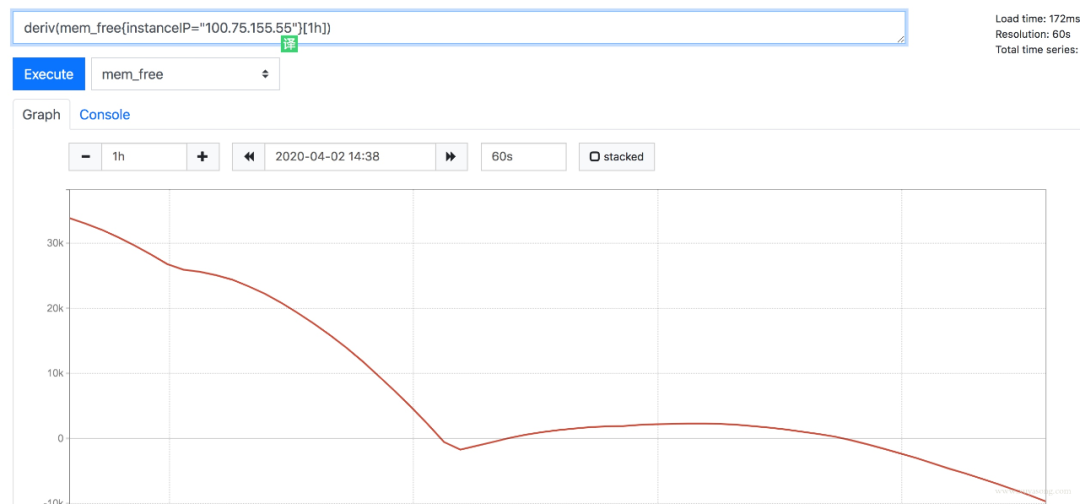
prometheus 是有基本預(yù)測(cè)功能的,如deriv和predict_linear(更準(zhǔn)確)可以根據(jù)已有數(shù)據(jù)預(yù)測(cè)未來(lái)趨勢(shì)
如果比較復(fù)雜且耗時(shí)的sql,可以使用 record rule 減少指標(biāo)數(shù)量,并使查詢(xún)效率更高,但不要什么指標(biāo)都加 record,一半以上的 metric 其實(shí)不太會(huì)查詢(xún)到。同時(shí) label 中的值不要加到 record rule 的 name 中。









node-exporter 不支持進(jìn)程監(jiān)控,這個(gè)前面已經(jīng)提到了。
node-exporter 只支持 unix 系統(tǒng),windows機(jī)器 請(qǐng)使用 wmi_exporter。因此以 yaml 形式不是 node-exporter 的時(shí)候,node-selector 要表明os類(lèi)型。
因?yàn)閚ode_exporter是比較老的組件,有一些最佳實(shí)踐并沒(méi)有merge進(jìn)去,比如符合Prometheus命名規(guī)范,因此建議使用較新的0.16和0.17版本。

一是在機(jī)器上啟動(dòng)兩個(gè)版本的node-exporter,都讓prometheus去采集。
二是使用指標(biāo)轉(zhuǎn)換器,他會(huì)將舊指標(biāo)名稱(chēng)轉(zhuǎn)換為新指標(biāo)







對(duì)于一些簡(jiǎn)單的需求,我們使用了 Grafana 的報(bào)警能力,所見(jiàn)即所得,直接在圖表下面配置告警即可,報(bào)警閾值和狀態(tài)很清晰。不過(guò) Grafana 的報(bào)警能力很弱,只是實(shí)驗(yàn)功能,可以作為調(diào)試使用。
對(duì)于常見(jiàn)的 pod 或應(yīng)用監(jiān)控,我們做了一些表單化,如下圖所示:提取了 CPU、內(nèi)存、磁盤(pán) IO 等常見(jiàn)的指標(biāo)作為選擇項(xiàng),方便配置。

使用 webhook 擴(kuò)展報(bào)警能力,改造 alertmanager, 在 send message 時(shí)做加密和認(rèn)證,對(duì)接內(nèi)部已有報(bào)警能力,并聯(lián)動(dòng)用戶(hù)體系,做限流和權(quán)限控制。
調(diào)用 alertmanager api 查詢(xún)報(bào)警事件,進(jìn)行展示和統(tǒng)計(jì)。

增加了 Queue 組件,多了一層依賴(lài),如果 App與 Queue 之間連接失敗,難道要在 App 本地緩存監(jiān)控?cái)?shù)據(jù)?
抓取時(shí)間可能會(huì)不同步,延遲的數(shù)據(jù)將會(huì)被標(biāo)記為陳舊數(shù)據(jù),當(dāng)然你可以通過(guò)添加時(shí)間戳來(lái)標(biāo)識(shí),但就失去了對(duì)陳舊數(shù)據(jù)的處理邏輯。
擴(kuò)展性問(wèn)題:Prometheus 適合大量小目標(biāo),而不是一個(gè)大目標(biāo),如果你把所有數(shù)據(jù)都放在了 Exposer 中,那么 Prometheus 的單個(gè) Job 拉取就會(huì)成為 CPU 瓶頸。這個(gè)和 Pushgateway 有些類(lèi)似,沒(méi)有特別必要的場(chǎng)景,都不是官方建議的方式。
缺少了服務(wù)發(fā)現(xiàn)和拉取控制,Prom 只知道一個(gè) Exposer,不知道具體是哪些 Target,不知道他們的 UP 時(shí)間,無(wú)法使用 Scrape_* 等指標(biāo)做查詢(xún),也無(wú)法用scrape_limit做限制。
因?yàn)槭?operator,所以依賴(lài) K8S 集群,如果你需要二進(jìn)制部署你的 Prometheus,如集群外部署,就很難用上prometheus-operator了,如多集群場(chǎng)景。當(dāng)然你也可以在 K8S 集群中部署 operator 去監(jiān)控其他的 K8S 集群,但這里面坑不少,需要修改一些配置。
operator 屏蔽了太多細(xì)節(jié),這個(gè)對(duì)用戶(hù)是好事,但對(duì)于理解 Prometheus 架構(gòu)就有些 gap 了,比如碰到一些用戶(hù)一鍵安裝了operator,但 Grafana 圖表異常后完全不知道如何排查,record rule 和 服務(wù)發(fā)現(xiàn)還不了解的情況下就直接配置,建議在使用 operator 之前,最好熟悉 prometheus 的基礎(chǔ)用法。
operator 方便了 Prometheus 的擴(kuò)展和配置,對(duì)于 alertmanager 和 exporter 可以很方便的做到多實(shí)例高可用,但是沒(méi)有解決 Prometheus 的高可用問(wèn)題,因?yàn)闊o(wú)法處理數(shù)據(jù)不一致,operator目前的定位也還不是這個(gè)方向,和 Thanos、Cortex 等方案的定位是不同的,下面會(huì)詳細(xì)解釋。
基本 HA:即兩套 Prometheus 采集完全一樣的數(shù)據(jù),外邊掛負(fù)載均衡
HA + 遠(yuǎn)程存儲(chǔ):除了基礎(chǔ)的多副本 Prometheus,還通過(guò) Remote Write 寫(xiě)入到遠(yuǎn)程存儲(chǔ),解決存儲(chǔ)持久化問(wèn)題
聯(lián)邦集群:即 Federation,按照功能進(jìn)行分區(qū),不同的 Shard 采集不同的數(shù)據(jù),由Global節(jié)點(diǎn)來(lái)統(tǒng)一存放,解決監(jiān)控?cái)?shù)據(jù)規(guī)模的問(wèn)題。
使用 Thanos 或者 Victoriametrics,來(lái)解決全局查詢(xún)、多副本數(shù)據(jù) Join 問(wèn)題。
官方建議數(shù)據(jù)做 Shard,然后通過(guò)Federation來(lái)實(shí)現(xiàn)高可用,
但是邊緣節(jié)點(diǎn)和Global節(jié)點(diǎn)依然是單點(diǎn),需要自行決定是否每一層都要使用雙節(jié)點(diǎn)重復(fù)采集進(jìn)行保活。也就是仍然會(huì)有單機(jī)瓶頸。
另外部分敏感報(bào)警盡量不要通過(guò)Global節(jié)點(diǎn)觸發(fā),畢竟從Shard節(jié)點(diǎn)到Global節(jié)點(diǎn)傳輸鏈路的穩(wěn)定性會(huì)影響數(shù)據(jù)到達(dá)的效率,進(jìn)而導(dǎo)致報(bào)警實(shí)效降低。
例如服務(wù)Updown狀態(tài),Api請(qǐng)求異常這類(lèi)報(bào)警我們都放在Shard節(jié)點(diǎn)進(jìn)行報(bào)警。
集群的后端有 A 和 B 兩個(gè)實(shí)例,A 和 B 之間沒(méi)有數(shù)據(jù)同步。A 宕機(jī)一段時(shí)間,丟失了一部分?jǐn)?shù)據(jù),如果負(fù)載均衡正常輪詢(xún),請(qǐng)求打到A 上時(shí),數(shù)據(jù)就會(huì)異常。
如果 A 和 B 的啟動(dòng)時(shí)間不同,時(shí)鐘不同,那么采集同樣的數(shù)據(jù)時(shí)間戳也不同,就不是多副本同樣數(shù)據(jù)的概念了
就算用了遠(yuǎn)程存儲(chǔ),A 和 B 不能推送到同一個(gè) TSDB,如果每人推送自己的 TSDB,數(shù)據(jù)查詢(xún)走哪邊就是問(wèn)題了。
存儲(chǔ)角度:如果使用 Remote Write 遠(yuǎn)程存儲(chǔ), A 和 B后面可以都加一個(gè) Adapter,Adapter做選主邏輯,只有一份數(shù)據(jù)能推送到 TSDB,這樣可以保證一個(gè)異常,另一個(gè)也能推送成功,數(shù)據(jù)不丟,同時(shí)遠(yuǎn)程存儲(chǔ)只有一份,是共享數(shù)據(jù)。
查詢(xún)角度:上邊的方案實(shí)現(xiàn)很復(fù)雜且有一定風(fēng)險(xiǎn),因此現(xiàn)在的大多數(shù)方案在查詢(xún)層面做文章,比如 Thanos 或者 Victoriametrics,仍然是兩份數(shù)據(jù),但是查詢(xún)時(shí)做數(shù)據(jù)去重和 Join。只是 Thanos 是通過(guò) Sidecar 把數(shù)據(jù)放在對(duì)象存儲(chǔ),Victoriametrics 是把數(shù)據(jù) Remote Write 到自己的 Server 實(shí)例,但查詢(xún)層 Thanos-Query 和 Victor 的 Promxy的邏輯基本一致。
日志采集與推送:一般是Fluentd/Fluent-Bit/Filebeat等采集推送到 ES、對(duì)象存儲(chǔ)、kafaka,日志就該交給專(zhuān)業(yè)的 EFK 來(lái)做,分為容器標(biāo)準(zhǔn)輸出、容器內(nèi)日志。
日志解析轉(zhuǎn) metric:可以提取一些日志轉(zhuǎn)為 Prometheus 格式的指標(biāo),如解析特定字符串出現(xiàn)次數(shù),解析 Nginx 日志得到 QPS 、請(qǐng)求延遲等。常用方案是 mtail 或者 grok
sidecar 方式:和業(yè)務(wù)容器共享日志目錄,由 sidecar 完成日志推送,一般用于多租戶(hù)場(chǎng)景。
daemonset 方式:機(jī)器上運(yùn)行采集進(jìn)程,統(tǒng)一推送出去。
1.15 及以下:/var/log/pods/{pod_uid}/
1.15 以上:var/log/pods/{pod_name+namespace+rs+uuid}/
使用 kube-eventer 之類(lèi)的組件采集 Events 并推送到 ES
使用 event_exporter 之類(lèi)的組件將Events 轉(zhuǎn)化為 Prometheus Metric,同類(lèi)型的還有谷歌云的 stackdriver 下的 event-exporter
參考資料
https://tech.meituan.com/2018/11/01/cat-in-depth-java-application-monitoring.html
https://dbaplus.cn/news-134-1462-1.html
https://www.infoq.cn/article/P3A5EuKl6jowO9v4_ty1
https://zhuanlan.zhihu.com/p/60791449
http://download.xuliangwei.com/jiankong.html#0-%E7%9B%91%E6%8E%A7%E7%9B%AE%E6%A0%87
https://aleiwu.com/post/prometheus-bp/
https://www.infoq.cn/article/1AofGj2SvqrjW3BKwXlN
http://bos.itdks.com/e8792eb0577b4105b4c9d19eb0dd1892.pdf
https://www.infoq.cn/article/ff46l7LxcWAX698zpzB2
https://www.robustperception.io/putting-queues-in-front-of-prometheus-for-reliability
https://www.slideshare.net/cadaam/devops-taiwan-monitor-tools-prometheus
https://www.robustperception.io/how-much-disk-space-do-prometheus-blocks-use
https://www.imooc.com/article/296613
https://dzone.com/articles/what-is-high-cardinality
https://www.robustperception.io/cardinality-is-key
https://www.robustperception.io/using-tsdb-analyze-to-investigate-churn-and-cardinality
https://blog.timescale.com/blog/prometheus-ha-postgresql-8de68d19b6f5/
https://asktug.com/t/topic/2618
往期資源回顧 需要可自取
推薦閱讀
點(diǎn)個(gè)[在看],是對(duì)杰哥最大的支持!
