
BatchNorm的避坑指南(下)
 點(diǎn)藍(lán)色字關(guān)注“機(jī)器學(xué)習(xí)算法工程師”
點(diǎn)藍(lán)色字關(guān)注“機(jī)器學(xué)習(xí)算法工程師”
設(shè)為星標(biāo),干貨直達(dá)!
Batch from Different Domains
包含BatchNorm的模型訓(xùn)練過(guò)程包含兩個(gè)學(xué)習(xí)過(guò)程:一是模型主體參數(shù)是通過(guò)SGD學(xué)習(xí)得到的(SGD training),二是全局統(tǒng)計(jì)量是通過(guò)EMA或者PreciseBN從訓(xùn)練數(shù)據(jù)中學(xué)習(xí)得到(population statistics training)。當(dāng)訓(xùn)練數(shù)據(jù)和測(cè)試數(shù)據(jù)分布不同時(shí),我們稱之為domain shift,這個(gè)時(shí)候?qū)W習(xí)得到的全局統(tǒng)計(jì)量就可能會(huì)在測(cè)試時(shí)失效,這個(gè)問(wèn)題已經(jīng)有論文提出要采用Adaptive BatchNorm來(lái)解決,即在測(cè)試數(shù)據(jù)上重新計(jì)算全局統(tǒng)計(jì)量。這里還是以ResNet50為例(SGD batch size為1024,NBS為32),用ImageNet-C數(shù)據(jù)集(ImageNet的擾動(dòng)版本,共三種類型:contrast,gaussian noise和jpeg compression)來(lái)評(píng)估domain shift問(wèn)題,結(jié)果如下:
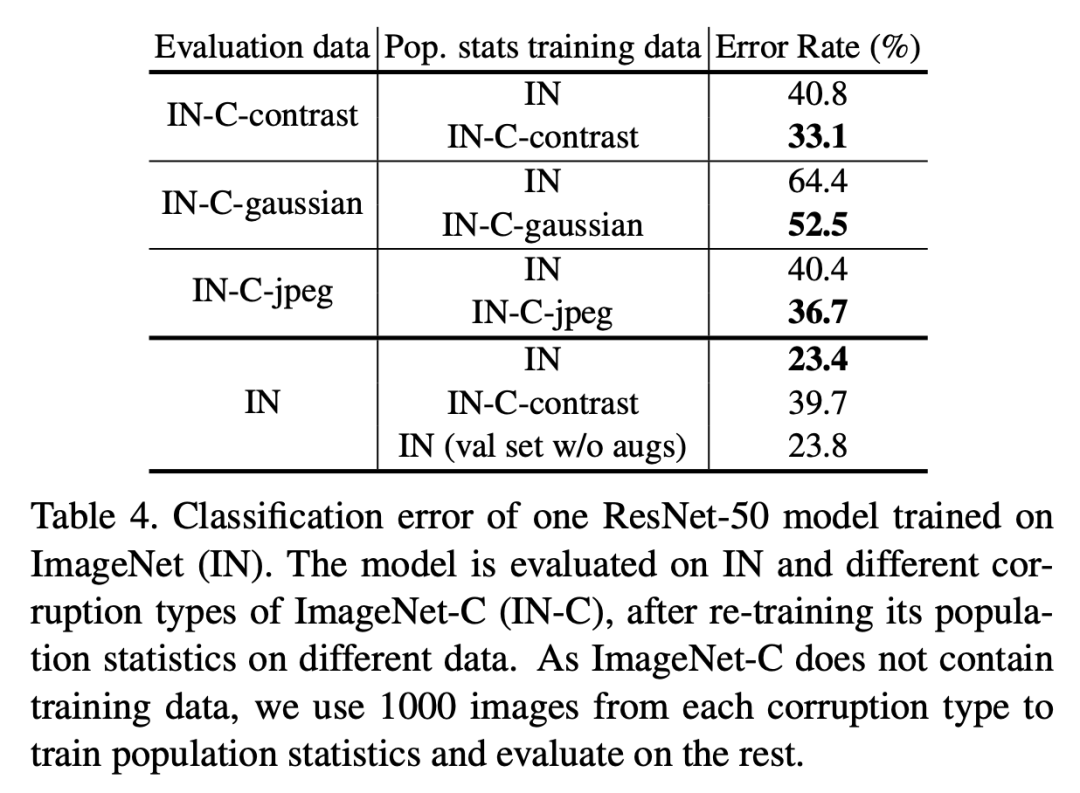
從表中可以明顯看出:當(dāng)出現(xiàn)domain shift問(wèn)題后,采用Adaptive BatchNorm在target domain數(shù)據(jù)集上重新計(jì)算全局統(tǒng)計(jì)量可以提升模型效果。不過(guò)從表最后一行可以看到,如果在ImageNet驗(yàn)證集上重新計(jì)算統(tǒng)計(jì)量(直接采用inference-time預(yù)處理),最終效果要稍微差于原來(lái)結(jié)果(23.4 VS 23.8),這可能說(shuō)明如果不存在明顯的domain shift,原始處理方式是最好的。
除了domain shift,訓(xùn)練數(shù)據(jù)存在multi-domain也會(huì)對(duì)BatchNorm產(chǎn)生影響,這個(gè)問(wèn)題更復(fù)雜了。這里以RetinaNet模型來(lái)說(shuō)明multi-domain的出現(xiàn)可能出現(xiàn)的問(wèn)題。RetinaNet的head包含4個(gè)卷積層以及最終的分類器和回歸器,其輸入是來(lái)自不同尺度的5個(gè)特征(),這可以kan'chehead在5個(gè)特征上是共享的,默認(rèn)head是不包含BatchNorm,當(dāng)我們?cè)诿總€(gè)卷積后加上BatchNorm后,問(wèn)題就變得復(fù)雜了。首先,首先就是訓(xùn)練過(guò)程mini-batch統(tǒng)計(jì)量的計(jì)算,明顯有兩種不同處理方式,一是對(duì)不同domain的特征輸入單獨(dú)計(jì)算mini-batch統(tǒng)計(jì)量并單獨(dú)歸一化,二是將所有domain的特征concat在一起,計(jì)算一個(gè)mini-batch統(tǒng)計(jì)量來(lái)歸一化。這兩種處理方式如下所示:
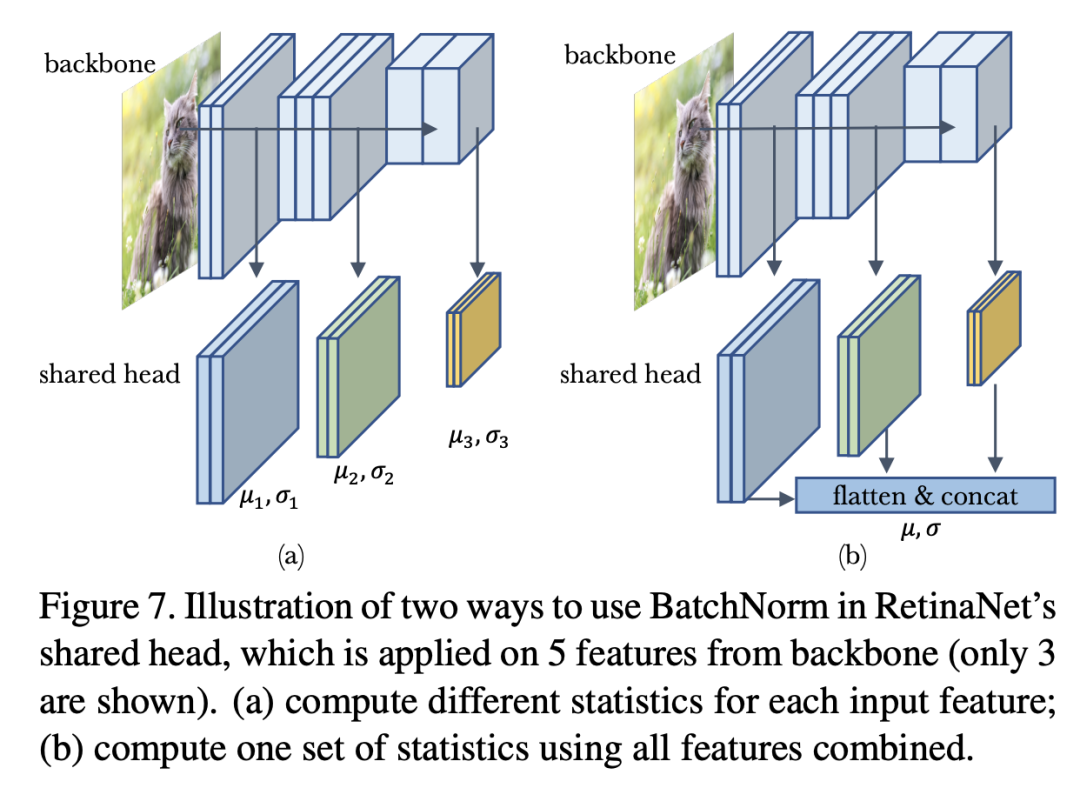
這里記SGD訓(xùn)練過(guò)程中的兩種方式分別為domain-specific statistics和shared statistics。對(duì)于學(xué)習(xí)全局統(tǒng)計(jì)量,同樣存在對(duì)應(yīng)的兩種方式,即每個(gè)domain的特征單獨(dú)學(xué)習(xí)一套全局統(tǒng)計(jì)量,還是共享一套全局統(tǒng)計(jì)量。對(duì)于BatchNorm的affine transform layer也存在兩種選擇:每個(gè)domain一套參數(shù)還是共享參數(shù)。不同組合的模型效果如下表所示:

從表中結(jié)果可以總結(jié)兩個(gè)結(jié)論:(1)SGD training和population statistics training保持一致非常重要,此時(shí)都可以取得較好的結(jié)果(行1,行4和行6);(2)affine transform layer無(wú)論單獨(dú)參數(shù)還是共享基本不影響結(jié)果。這里的一個(gè)小插曲是如果直接在head中加上BatchNorm,其實(shí)對(duì)應(yīng)的是行3,其實(shí)這是因?yàn)椴煌叨鹊奶卣魇切蛄刑幚淼模@就造成了SGD training其實(shí)是domain-specific的,此時(shí)效果就較差,所以大部分實(shí)現(xiàn)中要不然不用norm,要不然就用BatchNorm。不同組合的實(shí)現(xiàn)代碼如下:
# 簡(jiǎn)單地加上BN,注意forward時(shí),不同特征是串行處理的,那么SGD training其實(shí)是domain-specific的,
# 但是只維持一套全局統(tǒng)計(jì)量,所以測(cè)試時(shí)又是共享的
class RetinaNetHead_Row3:
def __init__(self, num_conv, channel):
head = []
for _ in range(num_conv):
head.append(nn.Conv2d(channel, channel, 3))
head.append(nn.BatchNorm2d(channel))
self.head = nn.Sequential(?head)
def forward(self, inputs: List[Tensor]):
return [self.head(i) for i in inputs]
# 如果要共享,那么在forward時(shí)對(duì)特征進(jìn)行concat來(lái)統(tǒng)一計(jì)算并歸一化
class RetinaNetHead_Row1(RetinaNetHead_Row3):
def forward(self, inputs: List[Tensor]):
for mod in self.head:
if isinstance(mod, nn.BatchNorm2d):
# for BN layer, normalize all inputs together
shapes = [i.shape for i in inputs]
spatial_sizes = [s[2] ? s[3] for s in shapes]
x = [i.flatten(2) for i in inputs]
x = torch.cat(x, dim=2).unsqueeze(3)
x = mod(x).split(spatial_sizes, dim=2)
inputs = [i.view(s) for s, i in zip(shapes, x)]
else:
# for conv layer, apply it separately
inputs = [mod(i) for i in inputs]
return inputs
# 另外一種簡(jiǎn)單的處理方式是每個(gè)特征采用各自的BN
class RetinaNetHead_Row6:
def __init__(self, num_conv, channel, num_features):
# num_features: number of features coming from
# different FPN levels, e.g. 5
heads = [[] for _ in range(num_levels)]
for _ in range(num_conv):
conv = nn.Conv2d(channel, channel, 3)
for h in heads:
# add a shared conv and a domain?specific BN
h.extend([conv, nn.BatchNorm2d(channel)])
self.heads = [nn.Sequential(?h) for h in heads]
def forward(self, inputs: List[Tensor]):
# end up with one head for each input
return [head(i) for head, i in
zip(self.heads, inputs)]
對(duì)于行2和行4,可以通過(guò)訓(xùn)練好的行1和行3模型重新在訓(xùn)練數(shù)據(jù)上計(jì)算domain-specific全局統(tǒng)計(jì)量即可,在實(shí)現(xiàn)時(shí),可以如下:
class CycleBatchNormList(nn.ModuleList):
"""
A hacky way to implement domain-specific BatchNorm
if it's guaranteed that a fixed number of domains will be
called with fixed order.
"""
def __init__(self, length, channels):
super().__init__([nn.BatchNorm2d(channels, affine=False) for k in range(length)])
# shared affine, domain-specific BN
self.weight = nn.Parameter(torch.ones(channels))
self.bias = nn.Parameter(torch.zeros(channels))
self._pos = 0
def forward(self, x):
ret = self[self._pos](x)
self._pos = (self._pos + 1) % len(self)
w = self.weight.reshape(1, -1, 1, 1)
b = self.bias.reshape(1, -1, 1, 1)
return ret * w + b
# 訓(xùn)練好模型,我們可以重新將BN層換成以上實(shí)現(xiàn),就可以在訓(xùn)練數(shù)據(jù)上重新計(jì)算domain-specific全局統(tǒng)計(jì)量
RetinaNet面臨的其實(shí)是特征層面的multi-domain問(wèn)題,而且每個(gè)batch中的各個(gè)domain是均勻的。如果是數(shù)據(jù)層面的multi-domain,其面臨的問(wèn)題將會(huì)復(fù)雜,此時(shí)domain的分布比例也是多變的,但是總的原則是盡量減少不一致性,因?yàn)?strong style="line-height: 1.6 !important;">consistency is crucial。
Information Leakage within a Batch
BatchNorm面臨的另外一個(gè)挑戰(zhàn),就是可能出現(xiàn)信息泄露,這里所說(shuō)的信息泄露指的是模型學(xué)習(xí)到了利用mini-batch的信息來(lái)做預(yù)測(cè),而這些其實(shí)并不是我們要學(xué)習(xí)的,因?yàn)檫@樣模型可能難以對(duì)mini-batch里的每個(gè)sample單獨(dú)做預(yù)測(cè)。
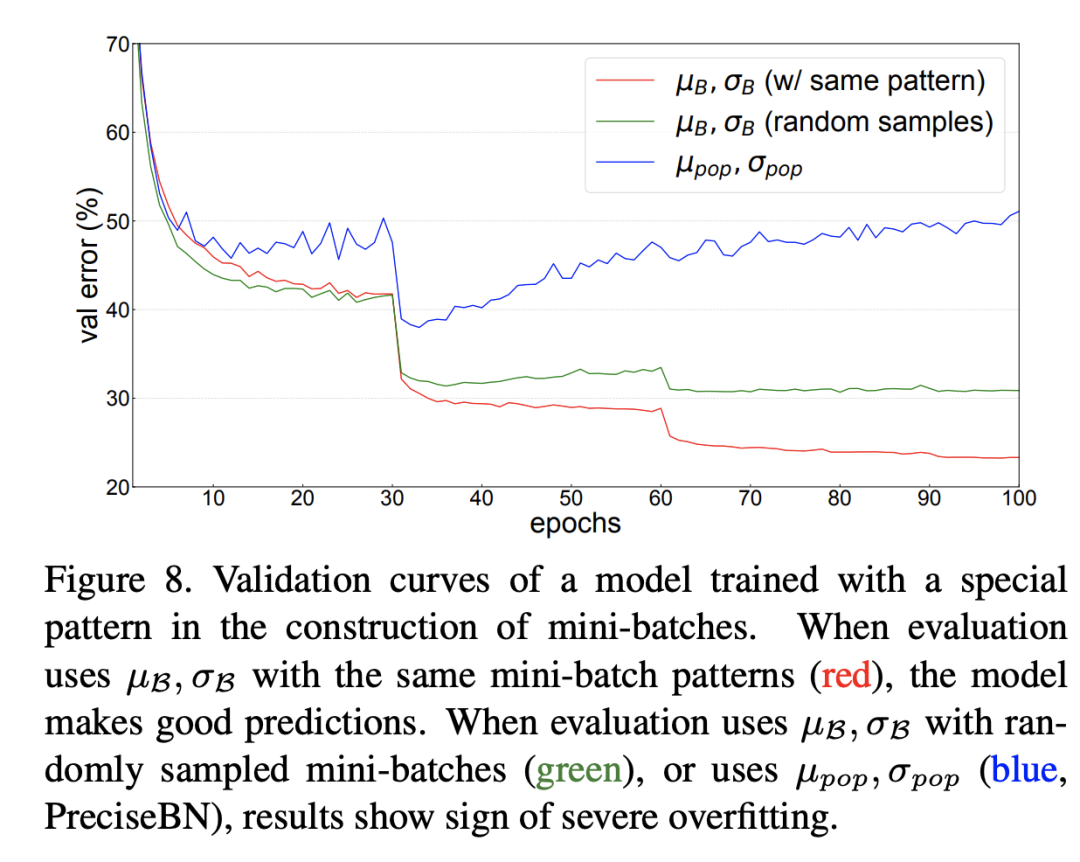
比如BatchNorm的作者曾做過(guò)這樣一個(gè)實(shí)驗(yàn),在ResNet50的訓(xùn)練過(guò)程中,NBS=32,但是保證里面包含16個(gè)類別,每個(gè)類別有2個(gè)圖像,這樣一種特殊的設(shè)計(jì)要模型在訓(xùn)練過(guò)程中強(qiáng)制記憶了這種模式(可能是每個(gè)mini-batch中必須有同類別存在),那么在測(cè)試時(shí)如果輸入不是這種設(shè)計(jì),效果就會(huì)變差。這個(gè)在驗(yàn)證集上不同處理結(jié)果如上所示,可以看到測(cè)試時(shí)無(wú)論是采用全局統(tǒng)計(jì)量還是random mini-batch統(tǒng)計(jì)量,效果均較差,但是如果采用和訓(xùn)練過(guò)程同樣的模式,效果就比較好。這其實(shí)也從側(cè)面說(shuō)明保持一致是多么的重要。
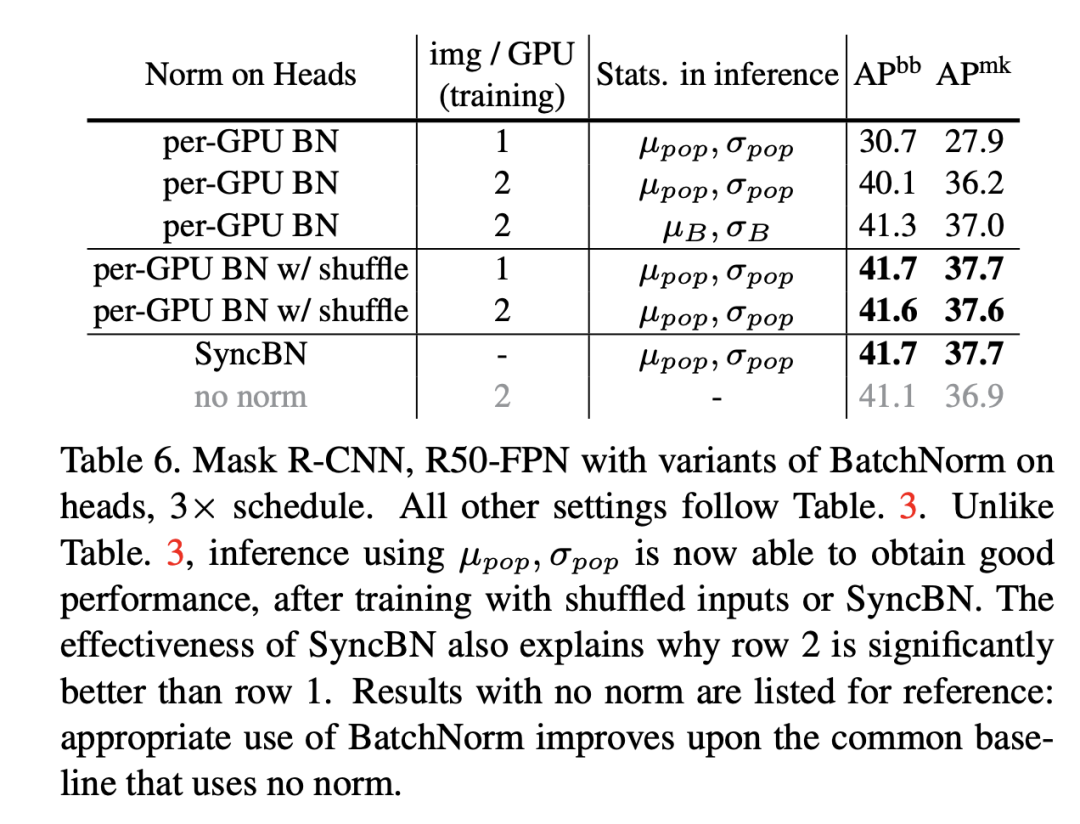
前面說(shuō)過(guò),如果在R-CNN的head加入BatchNorm,那么在測(cè)試時(shí)采用mini-batch統(tǒng)計(jì)量會(huì)比全局統(tǒng)計(jì)量會(huì)效果更好,這里面其實(shí)也存在信息泄露的問(wèn)題。對(duì)于每個(gè)GPU只有一個(gè)image的情況,每個(gè)mini-batch里面的RoIs全部來(lái)自于一個(gè)圖像,這時(shí)候模型就可能依賴mini-batch來(lái)做預(yù)測(cè),那么測(cè)試時(shí)采用全局統(tǒng)計(jì)量效果就會(huì)差了,對(duì)于每個(gè)GPU有多個(gè)圖像時(shí),情況還稍好一些,所以原來(lái)的結(jié)果中單卡單圖像效果最差。一種解決方案是采用shuffle BN,就是head進(jìn)行處理前,先隨機(jī)打亂所有卡上的RoIs特征,每個(gè)卡分配隨機(jī)的RoIs,這樣就避免前面那個(gè)可能出現(xiàn)的信息泄露,head處理完后再shuffle回來(lái),具體處理流程如下所示:
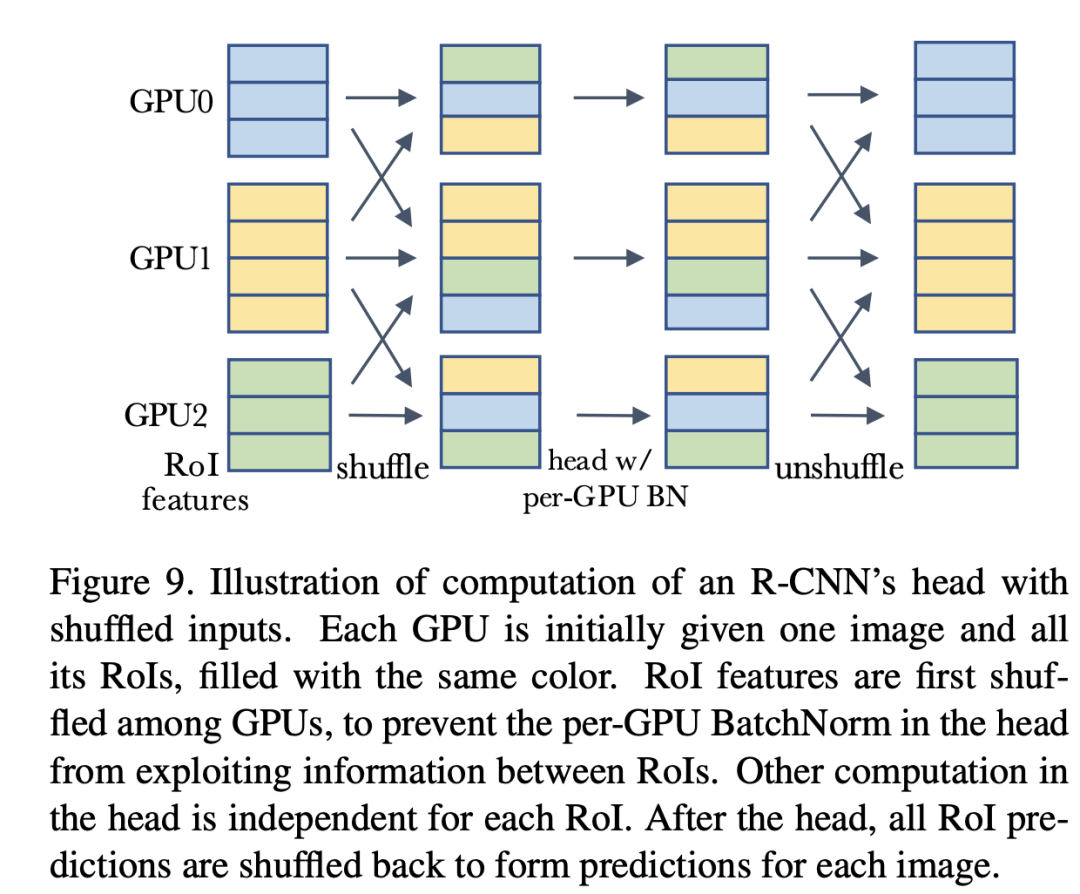
這個(gè)具體的代碼實(shí)現(xiàn)見mask_rcnn_BNhead_shuffle.py。其實(shí)在MoCo中也使用了shuffle BN來(lái)防止信息泄露。另外還是可以采用SyncBN來(lái)避免這種問(wèn)題。具體的對(duì)比結(jié)果如下所示,可以看到采用shuffle BN和SyncBN均可以避免信息泄露,得到較好的效果。注意shuffle BN的 cross-GPU synchronization要比SyncBN要少,效率更高一些。
另外一個(gè)常見的場(chǎng)景是對(duì)比學(xué)習(xí)中信息泄露,因?yàn)閷?duì)比學(xué)習(xí)往往需要對(duì)同一個(gè)圖像做不同的augmentations來(lái)作為正樣本,這其實(shí)一個(gè)sample既當(dāng)輸入又當(dāng)目標(biāo),mini-batch可能會(huì)泄露信息導(dǎo)致模型學(xué)習(xí)不到好的特征。MoCo采用的是shuffle BN,而SimCLR和BYOL采用的是SyncBN。另外曠視提出的Momentum^2 Teacher來(lái)采用moving average statistics來(lái)防止信息泄露。
總結(jié)
一個(gè)簡(jiǎn)單的BatchNorm,如果我們使用不當(dāng),往往會(huì)出現(xiàn)一些讓人意料的結(jié)果,所以要謹(jǐn)慎處理。總結(jié)來(lái)看,主要有如下結(jié)論和指南:
模型在未收斂時(shí)使用EMA統(tǒng)計(jì)量來(lái)評(píng)估模型是不穩(wěn)定的,一種替代方案是PreciseBN; BatchNorm本身存在訓(xùn)練和測(cè)試的不一致性,特別是NBS較少時(shí),這種不一致會(huì)更強(qiáng),可用的方案是測(cè)試時(shí)也采用mini-batch統(tǒng)計(jì)量或者采用FrozenBN; 在domain shift場(chǎng)景中,最好基于target domain數(shù)據(jù)重新計(jì)算全局統(tǒng)計(jì)量,在multi-domain數(shù)據(jù)訓(xùn)練時(shí),要特別注意處理的一致性; BatchNorm會(huì)存在信息泄露的風(fēng)險(xiǎn),這處理mini-batch時(shí)要防止特殊的出現(xiàn)。
參考
Rethinking "Batch" in BatchNorm
detectron2/projects/Rethinking-BatchNorm
推薦閱讀
谷歌AI用30億數(shù)據(jù)訓(xùn)練了一個(gè)20億參數(shù)Vision Transformer模型,在ImageNet上達(dá)到新的SOTA!
DETR:基于 Transformers 的目標(biāo)檢測(cè)
Transformer在語(yǔ)義分割上的應(yīng)用
"未來(lái)"的經(jīng)典之作ViT:transformer is all you need!
PVT:可用于密集任務(wù)backbone的金字塔視覺transformer!
漲點(diǎn)神器FixRes:兩次超越ImageNet數(shù)據(jù)集上的SOTA
不妨試試MoCo,來(lái)替換ImageNet上pretrain模型!
機(jī)器學(xué)習(xí)算法工程師
一個(gè)用心的公眾號(hào)
