
激光雷達(dá):點(diǎn)云語(yǔ)義分割算法
點(diǎn)擊下方卡片,關(guān)注“新機(jī)器視覺”公眾號(hào)
視覺/圖像重磅干貨,第一時(shí)間送達(dá)
1. 前言
之前的文章中介紹了基于LiDAR點(diǎn)云的物體檢測(cè)算法。物體檢測(cè)的輸出是場(chǎng)景中感興趣物體的信息,包括位置,大小,類別,速度等。相對(duì)于點(diǎn)云數(shù)據(jù)來(lái)說(shuō),這些輸出結(jié)果是非常稀疏的,只描述了場(chǎng)景內(nèi)的一部分信息。對(duì)于全自動(dòng)駕駛的應(yīng)用場(chǎng)景,這些稀疏的信息是遠(yuǎn)遠(yuǎn)不夠的。
首先,物體只是場(chǎng)景中的一部分內(nèi)容,還有很多重要的信息是以非物體的形式存在的,比如說(shuō)道路,建筑物,樹木等等。如果沒有這些信息,車輛就無(wú)法識(shí)別可以行駛的區(qū)域,也無(wú)法規(guī)避所有的障礙物,自動(dòng)駕駛的功能也就會(huì)受到很多限制,比如說(shuō)只能完成一般的AEB(自動(dòng)緊急剎車)功能。
其次,即使是在物體級(jí)別,3D物體框也是一個(gè)粗略的表示。在需要更為精細(xì)的空間信息時(shí)(比如自動(dòng)泊車應(yīng)用),物體框的精度就不太夠了,尤其是對(duì)于形狀可變的物體,比如說(shuō)鉸接式公交車。
因此,除了物體檢測(cè)以外,自動(dòng)駕駛的環(huán)境感知還包括另外一個(gè)重要的組成部分,那就是語(yǔ)義分割。準(zhǔn)確的說(shuō),這部分有三個(gè)不同的任務(wù):語(yǔ)義分割(semantic segmentation),實(shí)例分割(instance segmentation)和全景分割(panoramic segmentation)。語(yǔ)義分割的任務(wù)是給場(chǎng)景中的每個(gè)位置(圖像中的每個(gè)像素,或者點(diǎn)云中的每個(gè)點(diǎn))指定一個(gè)類別標(biāo)簽,比如車輛,行人,道路,建筑物等。實(shí)例分割的任務(wù)類似于物體檢測(cè),但輸出的不是物體框,而是每個(gè)點(diǎn)的類別標(biāo)簽和實(shí)例標(biāo)簽。全景分割任務(wù)則是語(yǔ)義分割和實(shí)例分割的結(jié)合。算法需要區(qū)分物體上的點(diǎn)(前景點(diǎn))和非物體上的點(diǎn)(背景點(diǎn)),對(duì)于前景點(diǎn)還需要區(qū)分不同的實(shí)例。
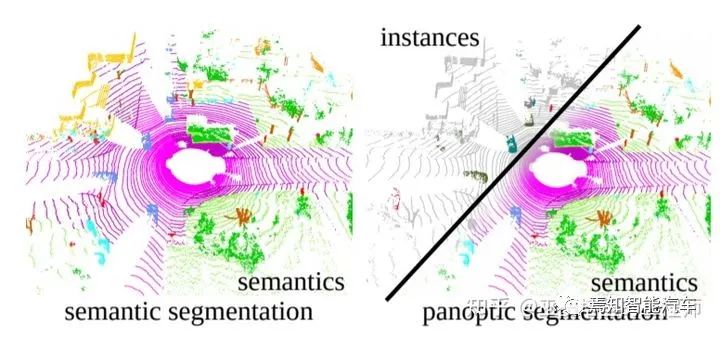
基于LiDAR點(diǎn)云的不同的分割任務(wù)(圖片來(lái)源于參考文獻(xiàn)[15])
2. 語(yǔ)義分割
語(yǔ)義分割和物體檢測(cè)這兩個(gè)任務(wù)有著很多的相似之處,其關(guān)鍵之處都在于如何有效的從原始點(diǎn)云數(shù)據(jù)中提取場(chǎng)景中的有用信息,以此對(duì)不同位置的語(yǔ)義信息進(jìn)行解析。
在深度學(xué)習(xí)流行之前,語(yǔ)義分割一般是通過傳統(tǒng)的監(jiān)督學(xué)習(xí)算法(supervised learning)來(lái)解決的。其流程主要分為兩步:首先,通過聚類算法找到每個(gè)點(diǎn)的鄰域,在該鄰域范圍內(nèi)進(jìn)行特征提取,以此特征為基礎(chǔ)對(duì)每個(gè)點(diǎn)進(jìn)行分類。機(jī)器學(xué)習(xí)領(lǐng)域中經(jīng)典的分類器,比如SVM,AdaBoost,Random Forest等等都可以采用。這一步驟與傳統(tǒng)的點(diǎn)云物體檢測(cè)方法非常類似。其次,以上的特征提取和分類并沒有考慮大范圍的上下文信息,而這部分信息對(duì)語(yǔ)義分割來(lái)說(shuō)是不可或缺的。因此,在局部分類的基礎(chǔ)上,還需要一個(gè)上下文模型來(lái)提高分割結(jié)果的正確性和平滑性。這里最常用的模型是Conditional Random Fields (CRF)。
一般來(lái)說(shuō),CFR可以作為一個(gè)正則項(xiàng)與局部分類器的優(yōu)化目標(biāo)相結(jié)合,從而將兩個(gè)步驟整合為一個(gè)優(yōu)化問題來(lái)求解。
進(jìn)入深度學(xué)習(xí)時(shí)代以后,特征提取和分類的任務(wù)基本上交給神經(jīng)網(wǎng)絡(luò)來(lái)完成。我們需要設(shè)計(jì)的主要是原始數(shù)據(jù)的組織形式以及神經(jīng)網(wǎng)格的細(xì)節(jié)。與點(diǎn)云物體檢測(cè)算法類似,按照輸入數(shù)據(jù)的不同組織形式,語(yǔ)義分割的方法也可以分為基于點(diǎn)的方法,基于網(wǎng)格的方法,以及基于投影的方法。當(dāng)然,兩個(gè)任務(wù)也有很多不同。
最顯著的一點(diǎn)是,語(yǔ)義分割任務(wù)需要比物體檢測(cè)任務(wù)更大范圍的上下文信息。舉例來(lái)說(shuō),一個(gè)車輛的檢測(cè)只需要觀測(cè)其局部鄰域(最多幾十米)的范圍即可,與更遠(yuǎn)范圍的場(chǎng)景因素關(guān)聯(lián)性較弱。但是,如果要進(jìn)行道路的分割,那就得觀測(cè)整個(gè)場(chǎng)景,場(chǎng)景中任何一個(gè)位置的因素都有可能對(duì)道路分割的結(jié)果產(chǎn)生影響。這個(gè)特點(diǎn)也決定了語(yǔ)義分割的特征提取網(wǎng)絡(luò)必須要具備更大的感受野。
2.1 基于點(diǎn)的方法
對(duì)于直接處理點(diǎn)的方法來(lái)說(shuō),PointNet[2]和PointNet++[3]是最具有代表性的。PointNet首先通過共享的MLP來(lái)提取每個(gè)點(diǎn)特征,然后利用池化操作再將所有點(diǎn)的特征合并為一個(gè)全局特征向量。對(duì)于分類任務(wù)來(lái)說(shuō),可以直接以此向量作為特征,用MLP進(jìn)行分類。對(duì)于分割任務(wù)來(lái)說(shuō),需要把點(diǎn)特征與全局特征進(jìn)行拼接,然后用MLP對(duì)每個(gè)點(diǎn)進(jìn)行分類(也就是分配一個(gè)語(yǔ)義標(biāo)簽)。
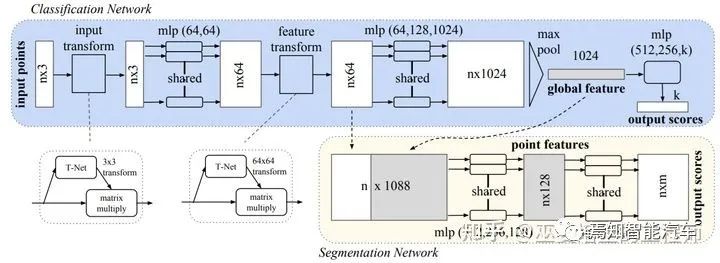
PointNet網(wǎng)絡(luò)結(jié)構(gòu)
從上面的描述中不難看出,雖然點(diǎn)分類的時(shí)候采用了全局+點(diǎn)特征,但是PointNet中的點(diǎn)特征提取是對(duì)每個(gè)點(diǎn)獨(dú)立進(jìn)行的,這個(gè)過程并沒有用到鄰域的信息。
因此,局部上下文信息在整個(gè)特征提取過程中是被忽略的,這對(duì)語(yǔ)義分割來(lái)說(shuō)影響比較大。作為PointNet的升級(jí)版本,PointNet++用聚類的方式來(lái)產(chǎn)生多個(gè)點(diǎn)云子集,在每個(gè)子集內(nèi)采用PointNet來(lái)提取點(diǎn)的特征。這個(gè)過程以一種層級(jí)化的方式重復(fù)多次,每一次聚類算法輸出的多個(gè)點(diǎn)集都被當(dāng)做抽象后的點(diǎn)云再進(jìn)行下一次處理(Set Abstraction,SA)。這樣得到的點(diǎn)特征具有較大的感受野,包含了局部鄰域內(nèi)豐富的上下文信息。對(duì)于分割任務(wù)來(lái)說(shuō),下一步我們需要將聚類后的點(diǎn)云和學(xué)習(xí)到的高層次特征再映射回原始的點(diǎn)云上(Point Feature Propagation)。與SA的過程類似,propagation也是一個(gè)迭代的過程。在把第L層的點(diǎn)云映射回L-1層時(shí),對(duì)于L-1層的每一個(gè)點(diǎn),需要從L層點(diǎn)云中選取其K近鄰(文章中取K=3),通過插值的辦法得到propagation后的特征,插值的權(quán)重根據(jù)點(diǎn)與點(diǎn)之間的距離來(lái)計(jì)算。然后,將propagation的特征與L-1層原始的特征進(jìn)行拼接(skip link),并利用一個(gè)共享的全連接網(wǎng)絡(luò)來(lái)做進(jìn)一步的特征提取。這個(gè)過程重復(fù)多次,直至回到原始的點(diǎn)云層。最后,再用一個(gè)全連接網(wǎng)絡(luò)來(lái)輸出每個(gè)點(diǎn)的類別。
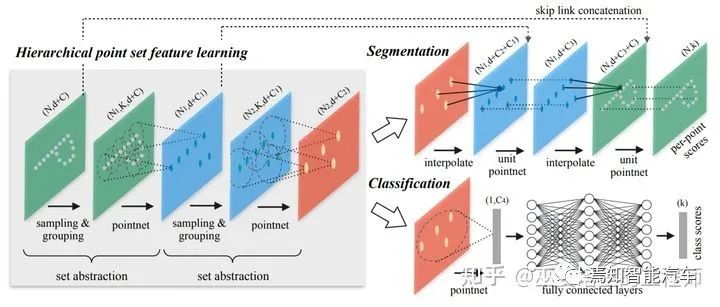
PointNet++網(wǎng)絡(luò)結(jié)構(gòu)
PointNet++的網(wǎng)絡(luò)結(jié)構(gòu)非常簡(jiǎn)潔,也具有很好的上下文特征提取能力。但是,這個(gè)系列的方法一般只能用來(lái)處理小規(guī)模的點(diǎn)云。在自動(dòng)駕駛應(yīng)用中,考慮到復(fù)雜的道路交通場(chǎng)景,百萬(wàn)級(jí)別的點(diǎn)云數(shù)量,以及對(duì)實(shí)時(shí)性的嚴(yán)苛要求,這類方法就不太適用了。這里主要的問題有兩個(gè):一個(gè)是點(diǎn)采樣的方法(比如farthest-point sampling)對(duì)點(diǎn)云規(guī)模的可擴(kuò)展性較差,另外一個(gè)是局部特征的學(xué)習(xí)無(wú)法適應(yīng)自動(dòng)駕駛中的復(fù)雜場(chǎng)景(學(xué)習(xí)能力不夠或者感受野不夠)。RandLA-Net[4]采用了隨機(jī)采樣的策略,極大的降低了點(diǎn)采樣過程的計(jì)算復(fù)雜度。同時(shí),通過局部空間編碼和基于注意力機(jī)制的池化,對(duì)局部特征提取進(jìn)行優(yōu)化。在SemanticKITTI(點(diǎn)云數(shù)量約10萬(wàn)/幀)的測(cè)試上,RandLA-Net的速度是PointNet++的50倍,達(dá)到22FPS。語(yǔ)義分割的準(zhǔn)確性方面也比PointNet++提升了一倍多(mIoU指標(biāo):53.9% vs. 20.1% )。
除了PointNet++系列以外,對(duì)點(diǎn)云的直接處理還可以通過Point卷積的方式進(jìn)行。這類方法的主要思路是將卷積操作從網(wǎng)格數(shù)據(jù)移植到點(diǎn)云上。在傳統(tǒng)的卷積操作中,卷積核中的權(quán)重是輸入數(shù)據(jù)在空間位置上一一對(duì)應(yīng)的,因此可以進(jìn)行一對(duì)一的操作,比如加權(quán)求和,從而得到相應(yīng)位置的輸出。對(duì)于點(diǎn)云數(shù)據(jù)來(lái)說(shuō),點(diǎn)的位置是不固定的,卷積操作也無(wú)法在空間位置上找到對(duì)應(yīng)關(guān)系。KPConv[5]提出在一個(gè)領(lǐng)域范圍內(nèi)定義相對(duì)位置固定的一些kernel points(類比傳統(tǒng)的卷積核)。由于在空間位置上無(wú)法與點(diǎn)云對(duì)齊,因此鄰域中每個(gè)點(diǎn)的卷積權(quán)重需要對(duì)所有kernel points權(quán)重進(jìn)行加權(quán)求和來(lái)得到。這里的權(quán)重通過點(diǎn)和kernel points的空間距離來(lái)確定。KPConv的輸入和輸出都是點(diǎn)云,點(diǎn)的數(shù)量也不變,但是點(diǎn)特征被增強(qiáng)了。對(duì)于語(yǔ)義分割任務(wù),我們可以采用與PointNet++中類似的策略,也就是sampling,pooling,upsampling這樣的結(jié)構(gòu)進(jìn)一步擴(kuò)大感受野,并最終得到每一個(gè)點(diǎn)的類別輸出。
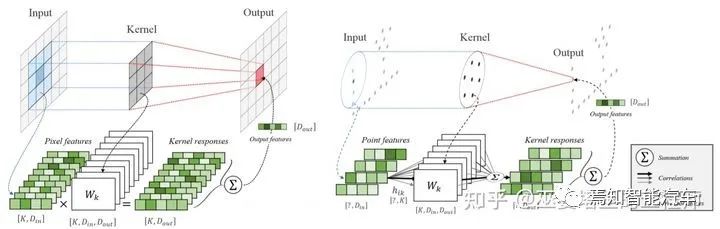
傳統(tǒng)Conv與KPConv的對(duì)比
此外,還有一些方法采用循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)或者圖神經(jīng)網(wǎng)絡(luò)(GNN)來(lái)更好的提取上下文信息,但是這些方法一般計(jì)算復(fù)雜度比較高,通常只適用于室內(nèi)小規(guī)模場(chǎng)景的處理,這里就不做介紹了。
2.2 基于網(wǎng)格的方法
在3D物體檢測(cè)領(lǐng)域的經(jīng)典方法VoxelNet中,點(diǎn)云被量化為均勻的3D網(wǎng)格(voxel)。配合上3D卷積,圖像語(yǔ)義分割中的全卷積網(wǎng)絡(luò)結(jié)構(gòu)就可以用來(lái)處理3D的voxel數(shù)據(jù)。
FCPN[6]在三維空間進(jìn)行均勻采樣,每個(gè)采樣的位置收集鄰域內(nèi)固定數(shù)量的點(diǎn)用來(lái)提取點(diǎn)特征。這里與VoxelNet中的方式略有不同:VoxelNet中的網(wǎng)格也是均勻位置采樣,鄰域的大小是固定的,但點(diǎn)的數(shù)量則是不固定的。所以,VoxelNet中的網(wǎng)格數(shù)據(jù)是稀疏的,而FCPN中的網(wǎng)格數(shù)據(jù)則是稠密的。但是,無(wú)論哪種方式,最后得到的數(shù)據(jù)形式都是4D的張量,也就是3D網(wǎng)格+特征。這種數(shù)據(jù)形式可以采用3D卷積來(lái)處理,并通過一個(gè)U-Shape Net的結(jié)構(gòu)來(lái)提取不同尺度的信息,最終得到原始量化尺度下的分割結(jié)果。每個(gè)網(wǎng)格會(huì)被分配一個(gè)類別標(biāo)簽,網(wǎng)格中所有的點(diǎn)共享此標(biāo)簽。
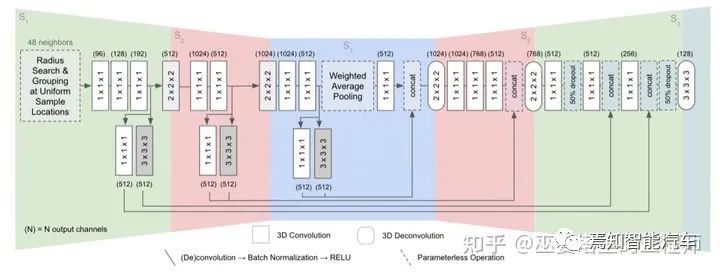
FCPN網(wǎng)絡(luò)結(jié)構(gòu)
Voxel的表示方式優(yōu)點(diǎn)在于數(shù)據(jù)規(guī)整,可以采用標(biāo)準(zhǔn)的卷積操作來(lái)處理,多尺度的信息也可以很容易的通過pyramid結(jié)構(gòu)來(lái)獲取。其缺點(diǎn)在于非常依賴網(wǎng)格大小的選取:網(wǎng)格較小導(dǎo)致數(shù)據(jù)維度較大,影響計(jì)算速度;網(wǎng)格較大會(huì)丟失信息,影響分割精度。當(dāng)采用較小的網(wǎng)格時(shí),數(shù)據(jù)會(huì)變得非常稀疏。所以可以通過稀疏卷積的方式來(lái)提高運(yùn)算效率,比如LatticeNet[7]。
2.3 基于投影的方法
點(diǎn)云是存在于3D空間的,具有完整的空間信息,因此可以將其投影到不同的二維視圖上。比如,我們可以假設(shè)3D空間中存在多個(gè)虛擬的攝像頭,每個(gè)攝像頭所看到的點(diǎn)云形成一幅2D圖像,圖像的特征可以包括深度和顏色(如果通過RGB-D設(shè)備采集)等信息。對(duì)這些2D圖像進(jìn)行語(yǔ)義分割,然后再將分割結(jié)果投影回3D空間,我們就得到了點(diǎn)云的分割結(jié)果。這個(gè)基于多視圖的方法缺點(diǎn)在于非常依賴于虛擬視角的選擇,無(wú)法充分的利用空間和結(jié)構(gòu)信息,而且物體間會(huì)相互遮擋。
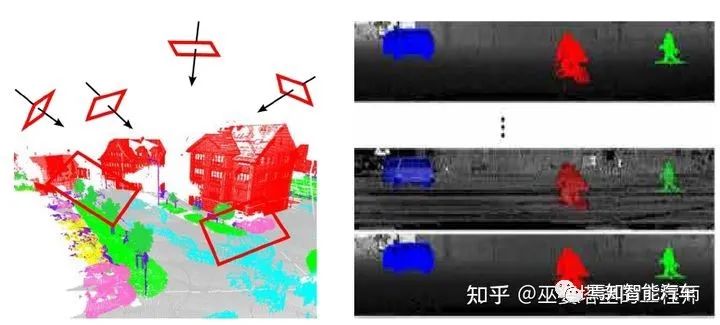
Multi-view(左)和Range-View(右)
此外,我們還可以將3D點(diǎn)云投影到RangeView。對(duì)于采用水平和垂直掃描的LiDAR來(lái)說(shuō),點(diǎn)云中的每個(gè)掃描點(diǎn)自然的就有水平和垂直兩個(gè)角度,而且這些角度都是離散的,其個(gè)數(shù)取決于相應(yīng)的分辨率。比如128線的LiDAR,其垂直角度個(gè)數(shù)就是128。假設(shè)其水平角度分辨率為0.5度,那么其掃描一周就產(chǎn)生了720個(gè)角度。將點(diǎn)云映射到以水平和垂直角度為XY坐標(biāo)的二維網(wǎng)格上,就得到了一個(gè)720x128像素的Range圖像,其像素值可以是點(diǎn)的距離,反射強(qiáng)度等。
RangeNet++[8]是基于RangeView的一個(gè)典型方法。在將點(diǎn)云轉(zhuǎn)換為range圖像之后,經(jīng)典的hourglass全卷積網(wǎng)絡(luò)被用來(lái)對(duì)圖像進(jìn)行語(yǔ)義分割。之后將分割結(jié)果投影回3D空間后,再進(jìn)行一些后處理,以提高分割結(jié)果的局部一致性。
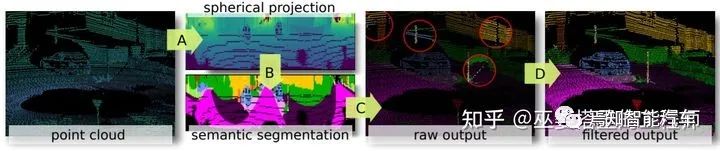
RangeNet++的組成模塊
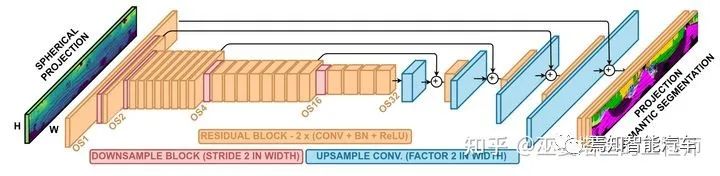
RangeNet++網(wǎng)絡(luò)結(jié)構(gòu)圖
SqueezeSeg[9](及其改進(jìn)版本SqueezeSegV2[10])也是基于RangeView的方法。在轉(zhuǎn)換后的range圖像上采用SqueezeNet網(wǎng)絡(luò)來(lái)得到語(yǔ)義分割的結(jié)果,然后采用CRF對(duì)分割結(jié)果進(jìn)行優(yōu)化(用RNN來(lái)實(shí)現(xiàn)CRF)。實(shí)例級(jí)別的輸出則是通過傳統(tǒng)的聚類算法得到的。V2版本在網(wǎng)絡(luò)結(jié)構(gòu),損失函數(shù),批標(biāo)準(zhǔn)化(BN)以及額外的輸入特征方面進(jìn)行了改進(jìn),并利用了合成數(shù)據(jù)以及域適應(yīng)學(xué)習(xí)(Domain Adaptation)。
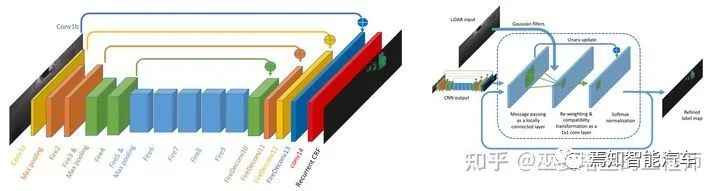
SqueezeSeg網(wǎng)絡(luò)結(jié)構(gòu)以及基于RNN的CRF實(shí)現(xiàn)
RangeView是一種非常緊致的數(shù)據(jù)表示,有利于減低算法的計(jì)算量,這對(duì)于自動(dòng)駕駛的應(yīng)用來(lái)說(shuō)非常重要。因此,近年來(lái)RangeView在3D物體檢測(cè)領(lǐng)域也受到了很多的關(guān)注。

3. 實(shí)例分割
與語(yǔ)義分割相比,實(shí)例分割需要對(duì)對(duì)點(diǎn)云進(jìn)行更為精細(xì)的處理:在賦予每個(gè)點(diǎn)不同語(yǔ)義標(biāo)簽的同時(shí),還需要區(qū)分不同的物體實(shí)例。實(shí)例分割可以通過兩種方式來(lái)實(shí)現(xiàn):自頂向下的方式和自底向上的方式。前者需要一個(gè)物體檢測(cè)模型來(lái)給出候選物體框,然后再找到屬于物體上的所有點(diǎn);后者從語(yǔ)義分割的結(jié)果出發(fā),通過聚類的方法來(lái)確定屬于各個(gè)物體上的點(diǎn)。
3.1 自頂向下的方法
對(duì)于這類方法,物體檢測(cè)是第一步也是至關(guān)重要的一步,檢測(cè)結(jié)果的質(zhì)量直接影響分割的效果。考慮到運(yùn)行效率,對(duì)于室外大規(guī)模點(diǎn)云的實(shí)例分割一般會(huì)采用網(wǎng)格結(jié)構(gòu)來(lái)表示點(diǎn)云,并采用類似VoxelNet中方法來(lái)進(jìn)行物體檢測(cè)。
LiDARSeg[11]提出了一個(gè)很典型的自頂向下的實(shí)例分割流程。首先,輸入的點(diǎn)云數(shù)據(jù)被量化為2D網(wǎng)格結(jié)構(gòu),這樣可以避免計(jì)算量很大的3D卷積操作。與一般的網(wǎng)格量化不同,LiDARSeg的每個(gè)網(wǎng)格包含了固定數(shù)量的點(diǎn),這些點(diǎn)通過計(jì)算網(wǎng)格中心的K近鄰得到。這樣一來(lái),每個(gè)網(wǎng)格中都有點(diǎn),避免了網(wǎng)格數(shù)據(jù)過于稀疏的問題。在點(diǎn)特征設(shè)計(jì)方面,與VoxelNet類似,原始特征包括網(wǎng)格中心的位置,點(diǎn)相對(duì)于網(wǎng)格中心的偏移,點(diǎn)的高度以及反射率。
PointFC和VFE層被用來(lái)提取提取點(diǎn)特征以及網(wǎng)格內(nèi)的局部信息。但是,與VoxelNet中最后采用pooling的方法來(lái)將點(diǎn)特征合并為網(wǎng)格特征不同,LiDARSeg采用類似加權(quán)求和的方式來(lái)合并網(wǎng)格內(nèi)的點(diǎn),權(quán)重通過self-attention機(jī)制自動(dòng)學(xué)習(xí)得到。Backbone網(wǎng)絡(luò)是兩個(gè)hourglass結(jié)構(gòu)的組合,并且兩個(gè)結(jié)構(gòu)之間也有一些shortcut連接。
理論上說(shuō),物體檢測(cè)模塊輸出的3D物體框可以直接用來(lái)做實(shí)例分割:可以簡(jiǎn)單的認(rèn)為物體框內(nèi)的點(diǎn)就是實(shí)例上的點(diǎn)。但是,就算是手工標(biāo)注的物體框,其內(nèi)的點(diǎn)也會(huì)有大約12-16%左右是outlier(文章[11]中的統(tǒng)計(jì))。因此,直接通過檢測(cè)結(jié)果來(lái)生成實(shí)例分割是不準(zhǔn)確的。在LiDARSeg中,每個(gè)網(wǎng)格都會(huì)輸出預(yù)測(cè)的物體中心點(diǎn)位置和高度的范圍。將臨近的中心點(diǎn)(小于0.3m)以及其包含的點(diǎn)進(jìn)行合并,并按照網(wǎng)絡(luò)預(yù)測(cè)的高度范圍對(duì)其進(jìn)行過濾,去除outlier,這樣就得到了精確的實(shí)例分割結(jié)果。
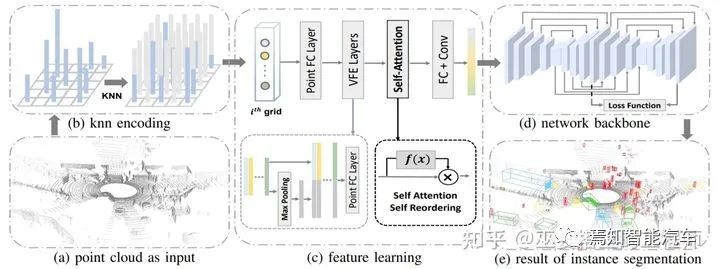
LiDARSeg網(wǎng)絡(luò)結(jié)構(gòu)圖
3.2 自底向上的方法
在這類方法中沒有物體檢測(cè)模塊,實(shí)例分割是通過對(duì)底層語(yǔ)義分割結(jié)果進(jìn)行聚類得到的。聚類算法假設(shè)同一個(gè)實(shí)例上的點(diǎn)具有較大的相似度,因此如何學(xué)習(xí)更具有區(qū)分能力的點(diǎn)特征,以及如何將點(diǎn)組合成物體是這類方法研究中的重點(diǎn)。
SGPN[12]是這個(gè)方向早期的一個(gè)典型工作。它首先通過PointNet++來(lái)學(xué)習(xí)點(diǎn)的特征,這些特征作為后續(xù)三個(gè)分支的輸入。語(yǔ)義分割的分支比較直觀,就是通過點(diǎn)特征來(lái)預(yù)測(cè)每個(gè)點(diǎn)的語(yǔ)義標(biāo)簽。另外還有兩個(gè)分支,一個(gè)用來(lái)生成相似度矩陣,用來(lái)得到每個(gè)點(diǎn)周圍的聚類,另一個(gè)生成每個(gè)點(diǎn)的置信度,用來(lái)過濾不屬于物體實(shí)例的聚類。
這個(gè)方法的關(guān)鍵在于相似度矩陣的這個(gè)分支。它首先要學(xué)習(xí)更具有區(qū)分性的點(diǎn)特征,然后以此為基礎(chǔ)生成相似度矩陣。損失函數(shù)分為三個(gè)部分,分別對(duì)應(yīng)三種不同的點(diǎn)對(duì):屬于相同語(yǔ)義且相同實(shí)例的點(diǎn)對(duì),屬于相同語(yǔ)義但是不同實(shí)例的點(diǎn)對(duì),以及不屬于相同語(yǔ)義的點(diǎn)對(duì)。特征學(xué)習(xí)的目標(biāo)則是要使第一類點(diǎn)對(duì)的特征相似度較高,第二類和第三類則相對(duì)較低(這兩類的權(quán)重也不盡相同)。最后,將通過相似度矩陣得到的聚類進(jìn)行后處理(合并和過濾),以得到最終的實(shí)例分割結(jié)果。
SGPN由于要計(jì)算每?jī)蓚€(gè)點(diǎn)之間的相似度,計(jì)算復(fù)雜度(O(n*n))會(huì)隨著點(diǎn)數(shù)量的增加而急劇增加,因此只適用于室內(nèi)小規(guī)模的點(diǎn)云處理。這其實(shí)也是這一類方法的一般性問題:聚類算法對(duì)于點(diǎn)云規(guī)模的擴(kuò)展性較差。因此,對(duì)于自動(dòng)駕駛場(chǎng)景中的大規(guī)模點(diǎn)云分割,一般還是會(huì)采用自頂向下的方式。

SGPN網(wǎng)絡(luò)結(jié)構(gòu)圖
4. 全景分割
全景分割可以看作語(yǔ)義分割和實(shí)例分割的結(jié)合。基于LiDAR點(diǎn)云的全景分割研究處于剛起步的階段,其主要需求來(lái)源于自動(dòng)駕駛,機(jī)器人等領(lǐng)域。尤其是在自動(dòng)駕駛應(yīng)用中,點(diǎn)云的空間覆蓋范圍和數(shù)量規(guī)模都很大,場(chǎng)景中包含大量不同尺寸的物體,背景非常復(fù)雜,對(duì)算法的精確度和實(shí)時(shí)性的要求也非常高。
點(diǎn)云的全景分割一般從語(yǔ)義分割出發(fā),通過聚類來(lái)得到物體的分割結(jié)果,這個(gè)思路其實(shí)與實(shí)例分割中的自底向上的方法是非常類似的,比如前面提到的SGPN。但是其聚類算法的計(jì)算復(fù)雜度太高,導(dǎo)致其無(wú)法應(yīng)用到大規(guī)模的點(diǎn)云上。下面介紹一個(gè)最新的點(diǎn)云全景分割算法,讓我們來(lái)看看它是如何顯著降低計(jì)算復(fù)雜度的。
Panoptic-PolarNet[13] 該方法采用BEV下的2D網(wǎng)格來(lái)表示數(shù)據(jù),這樣可以利用2D卷積提高數(shù)據(jù)處理效率,高度方向也基本不會(huì)有重疊的物體,因此也不會(huì)丟失信息。但是,一般的2D網(wǎng)格采用笛卡爾坐標(biāo),而該方法中采用極坐標(biāo),這樣可以在近距離區(qū)域降低量化誤差,提高特征提取能力。除此之外,點(diǎn)特征的提取采用MLP加MaxPooling的方式,最終每個(gè)網(wǎng)格得到一個(gè)定長(zhǎng)的特征向量(C=512)。整個(gè)特征提取過程只包含了量化,MLP和Pooling,非常的簡(jiǎn)潔,計(jì)算復(fù)雜度非常低。
主干網(wǎng)絡(luò)方面,同樣是采用結(jié)構(gòu)非常的簡(jiǎn)單的U-Net,并且語(yǔ)義和實(shí)例分支共享除了最后一層之外的所有特征,這也對(duì)減少計(jì)算量非常有幫助。語(yǔ)義分支在每一個(gè)網(wǎng)格位置都輸出多個(gè)預(yù)測(cè),并映射回3D網(wǎng)格,以區(qū)分不同高度的語(yǔ)義類別(比如物體和路面)。訓(xùn)練過程中的loss也是在3D網(wǎng)格空間計(jì)算的。實(shí)例分支類似于視覺任務(wù)中流行的CenterNet結(jié)構(gòu),在每個(gè)2D網(wǎng)格處輸出物體中心出現(xiàn)的置信度(heatmap)和中心點(diǎn)相對(duì)于網(wǎng)格中心位置的偏移(offset)。
有了以上信息以后,全景分割的模塊首先在heatmap上通過NMS生成top K個(gè)物體中心點(diǎn),并根據(jù)offset來(lái)確定它們的精確位置,然后在語(yǔ)義分割結(jié)果上提取前景mask。前景中的每一個(gè)點(diǎn)找到距離最近的物體中心,并以此進(jìn)行聚類,每個(gè)聚類的類別由其中點(diǎn)的語(yǔ)義類別來(lái)決定。所有這些操作都可以在GPU中進(jìn)行,計(jì)算效率很高。
最后,我們來(lái)總結(jié)一下。在Panoptic-PolarNet中,語(yǔ)義分支提供了3D的語(yǔ)義分割結(jié)果,每個(gè)點(diǎn)都有一個(gè)語(yǔ)義標(biāo)簽。實(shí)例分支提供物體中心位置,與語(yǔ)義分支輸出的前景點(diǎn)相結(jié)合得到每個(gè)實(shí)例的分割結(jié)果。這樣,全景分割的任務(wù)就完成了。此外,網(wǎng)絡(luò)中所包括的2D網(wǎng)格數(shù)據(jù)結(jié)構(gòu),U-Net,中心點(diǎn)預(yù)測(cè)等都是非常簡(jiǎn)潔的結(jié)構(gòu),可以在GPU中高效的實(shí)現(xiàn),因此整個(gè)系統(tǒng)的速度也就提升了上來(lái),達(dá)到約12FPS。由于一般LiDAR的工作頻率是10FPS,Panoptic-PolarNet的速度已經(jīng)可以滿足實(shí)時(shí)的要求。
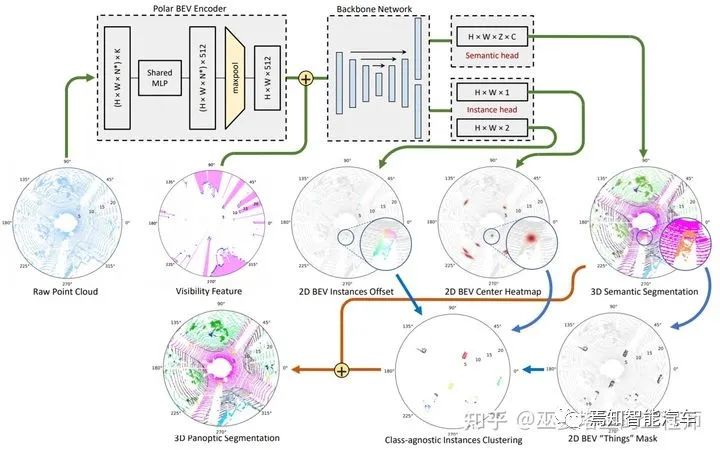
Panoptic-PolarNet網(wǎng)絡(luò)結(jié)構(gòu)圖
3D點(diǎn)云的全景分割是一個(gè)比較新的研究方向,而圖像的全景分割研究則相對(duì)成熟。因此,與語(yǔ)義分割類似,有的方法(比如[14])會(huì)將3D點(diǎn)云轉(zhuǎn)換為range視圖,在此數(shù)據(jù)上進(jìn)行圖像全景分割,再把分割的結(jié)果映射回3D空間。此外,還有的方法(比如[15])研究如何利用時(shí)序信息來(lái)提高全景分割的效果,這也是與自動(dòng)駕駛應(yīng)用場(chǎng)景非常相關(guān)的。
5. 數(shù)據(jù)庫(kù)和算法對(duì)比
以上的部分主要介紹了不同分割任務(wù)中的代表性算法,以及它們的優(yōu)缺點(diǎn),主要都是定性的分析。這部分會(huì)系統(tǒng)的介紹點(diǎn)云分割任務(wù)的常用數(shù)據(jù)庫(kù)和評(píng)測(cè)指標(biāo),并對(duì)上文提到的典型算法進(jìn)行對(duì)比。點(diǎn)云數(shù)據(jù)庫(kù)按照不同的場(chǎng)景和不同的采集設(shè)備可以分為很多種類。這里只關(guān)注室外道路場(chǎng)景,面向自動(dòng)駕駛應(yīng)用,由車載LiDAR采集的點(diǎn)云數(shù)據(jù)庫(kù),以及相關(guān)的算法對(duì)比。
5.1 數(shù)據(jù)庫(kù)
SemanticKITTI
KITTI是圖像和點(diǎn)云檢測(cè)領(lǐng)域最常用的數(shù)據(jù)庫(kù)之一。SemanticKITTI[16]將KITTI數(shù)據(jù)庫(kù)中Visual Odometry Benchmark中的所有LiDAR點(diǎn)云序列進(jìn)行標(biāo)注,是第一個(gè)大規(guī)模的面向自動(dòng)駕駛場(chǎng)景的3D點(diǎn)云語(yǔ)義分割數(shù)據(jù)庫(kù)。
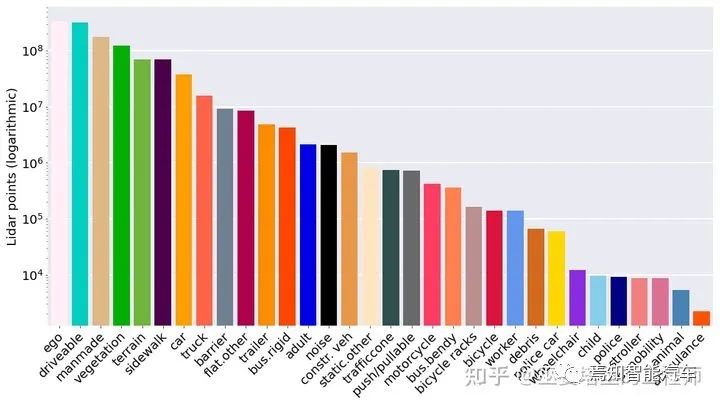
SemanticKITTI的點(diǎn)云數(shù)據(jù)是通過Velodyne64線激光雷達(dá)采集,共有22個(gè)序列,訓(xùn)練集和測(cè)試集分別包含23021和20351幀點(diǎn)云,每幀大約10萬(wàn)個(gè)點(diǎn),標(biāo)注的語(yǔ)義類別為28個(gè)。之后,SemanticKITTI又增加了實(shí)例級(jí)別的標(biāo)注,實(shí)例的ID在時(shí)序上也是一致的,可以用來(lái)作為全景分割和物體跟蹤的評(píng)測(cè)[17]。

SemanticKITTI數(shù)據(jù)庫(kù)的標(biāo)注分布(可移動(dòng)物體在靜止?fàn)顟B(tài)時(shí)用實(shí)心柱表示)
nuScenes
nuScenes[18]數(shù)據(jù)庫(kù)由知名的汽車零部件供應(yīng)商APTIV旗下的子公司Motional發(fā)布,專門面向自動(dòng)駕駛應(yīng)用,包含了1000段城市道路交通場(chǎng)景,數(shù)據(jù)由6個(gè)攝像頭,5個(gè)毫米波雷達(dá)和1個(gè)激光雷達(dá)采集。這也是第一個(gè)包含了自動(dòng)駕駛?cè)齻€(gè)主要傳感器的公開數(shù)據(jù)庫(kù)。
nuScenes的點(diǎn)云數(shù)據(jù)在全部1000個(gè)序列的40000個(gè)關(guān)鍵幀上進(jìn)行了標(biāo)注,每幀大約3萬(wàn)個(gè)點(diǎn)。標(biāo)注的語(yǔ)義類別共有32個(gè),其中包括23個(gè)前景類別和9個(gè)背景類別。nuScenes目前沒有公開的實(shí)例標(biāo)注,研究者一般會(huì)自己進(jìn)行額外的實(shí)例標(biāo)注,以測(cè)試全景分割算法。
nuScenes數(shù)據(jù)庫(kù)的標(biāo)注分布
5.2 評(píng)價(jià)指標(biāo)
在語(yǔ)義分割任務(wù)中,點(diǎn)云中的每個(gè)點(diǎn)被算法賦予一個(gè)預(yù)測(cè)的語(yǔ)義標(biāo)簽。將此預(yù)測(cè)的標(biāo)簽與人工標(biāo)注的標(biāo)簽進(jìn)行對(duì)比,對(duì)于每個(gè)類別我們統(tǒng)計(jì)三個(gè)指標(biāo):TP(True Positive),F(xiàn)P(False Positive)和FN(False Negative)。語(yǔ)義分割中常用的mean IoU指標(biāo)可以通過下面的公式來(lái)計(jì)算,這里的C是類別的個(gè)數(shù)。
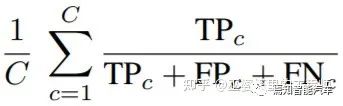
在全景分割任務(wù)中,算法不僅給每個(gè)點(diǎn)分配一個(gè)語(yǔ)義標(biāo)簽,還需要給屬于物體類別的點(diǎn)一個(gè)實(shí)例標(biāo)簽(ID)。這種情況下,一個(gè)常用的評(píng)測(cè)指標(biāo)是PQ (Panoptic Quality),其計(jì)算方式如下。其中S和S'分別表示標(biāo)注和預(yù)測(cè)的實(shí)例點(diǎn)集,當(dāng)兩個(gè)集合的IoU大于一個(gè)閾值時(shí)(比如0.5),則認(rèn)為是TP。FP和FN也可以通過類似的方式得到。這與物體檢測(cè)領(lǐng)域的評(píng)測(cè)是非常類似的。PQ這個(gè)指標(biāo)對(duì)于每個(gè)類別單獨(dú)計(jì)算,然后取其均值作為最終的指標(biāo)。在PQ指標(biāo)中,非物體類別是作為一個(gè)大類來(lái)計(jì)算的,因此并不區(qū)分這些類之間的分割錯(cuò)誤。這些錯(cuò)誤可以通過語(yǔ)義分割的指標(biāo)mIoU來(lái)衡量。
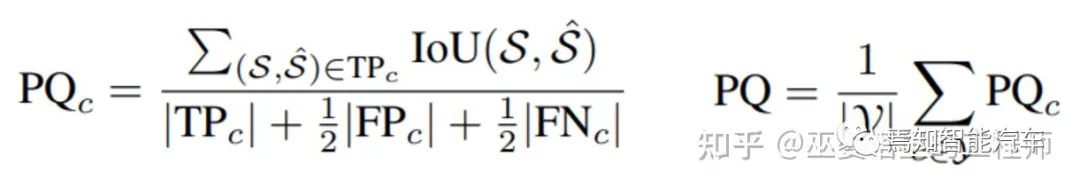
5.3 算法對(duì)比
有了數(shù)據(jù)庫(kù)和評(píng)價(jià)指標(biāo),下面我們就來(lái)對(duì)比一下前文提到的一些典型算法。
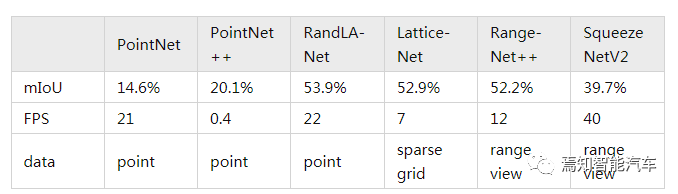
對(duì)于語(yǔ)義分割任務(wù),下表對(duì)比了不同算法在SemanticKITTI上單幀的準(zhǔn)確度(mIoU)和速度(FPS)指標(biāo)。從這個(gè)對(duì)比中可以看出,基于Point的RandLA-Net和基于RangeView的RangeNet++在準(zhǔn)確度和速度方面有著比較好的平衡。
對(duì)于全景分割任務(wù),由于其研究剛剛起步,因此可用來(lái)對(duì)比的方法并不多。這里我們采用SemanticKITTI中定義的兩個(gè)全景分割的baseline算法:KPConv + PointPillars和RangeNet++ ?+ PointPillars。這些算法前面都介紹過,分別是語(yǔ)義分割和物體檢測(cè)領(lǐng)域的經(jīng)典算法。所以說(shuō),這兩個(gè)全景分割的baseline其實(shí)就是語(yǔ)義分割和物體檢測(cè)算法的組合。從下表的對(duì)比中可以看出,前面介紹的Panoptic-PolarNet無(wú)論是在準(zhǔn)確度(PQ)還是速度(FPS)方面,相比于baseline算法有了很大程度的提升。

參考文獻(xiàn)
—版權(quán)聲明—
僅用于學(xué)術(shù)分享,版權(quán)屬于原作者。
若有侵權(quán),請(qǐng)聯(lián)系微信號(hào):yiyang-sy 刪除或修改!