
最全語義分割概覽
點擊上方“程序員大白”,選擇“星標”公眾號
重磅干貨,第一時間送達


語義分割是指對圖片中的像素進行類別上的分類,有別于實例分割,不能區(qū)分同一類別的不同個體。本文對從FCN開始的語義分割網(wǎng)絡(luò)進行了一些總結(jié),有沒寫到的網(wǎng)絡(luò)還希望大家留言給我。
借鑒自?https://zhuanlan.zhihu.com/p/27794982
一、FCN:CNN語義分割的開山之作
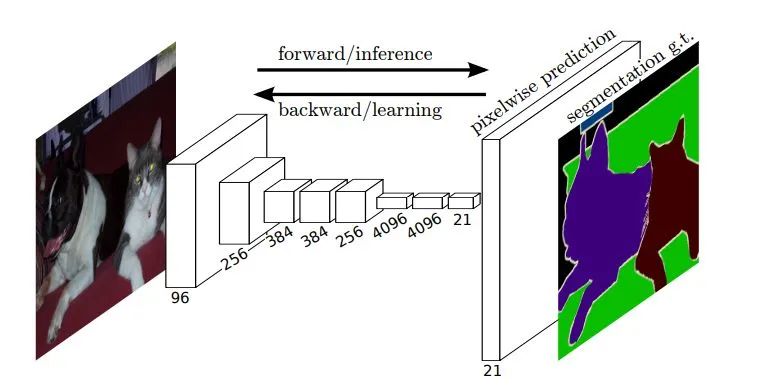
結(jié)構(gòu):
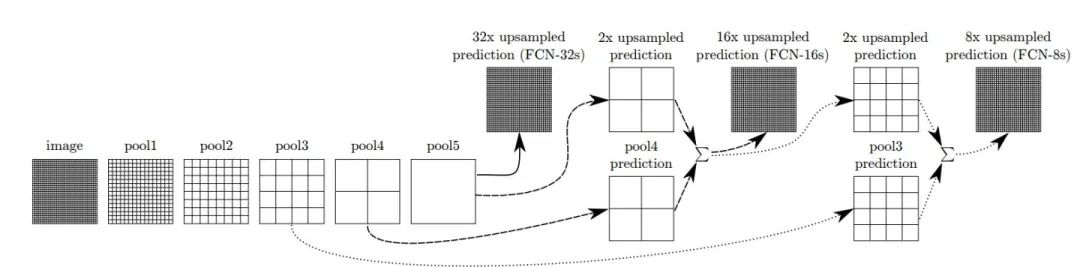
簡單來說,F(xiàn)CN在網(wǎng)絡(luò)上的改變就是基于當時最好的圖像分類模型,將最后的全連接層替換成了卷積層,這樣最后匯聚到一個點的網(wǎng)絡(luò)結(jié)構(gòu),變成了匯聚成縮小一定比例的分類圖,并且最后一層的21個通道代表著最后的21個分類結(jié)果。同時也揭示了伴隨著端到端語義分割的一個主流矛盾:既需要全局的感受野來完成分類任務(wù),又需要在邊緣部位,用局部信息和低層的低級視覺信息來達到準確的邊緣分割。
特點:
?用全卷積替代了全連接
為了彌補下采樣操作造成的損失,使用了反轉(zhuǎn)卷積的操作來恢復信息
單純地使用反轉(zhuǎn)卷積無法得到好的效果,用下采樣之前的特征圖與上采樣之后的圖片進行融合這樣可以指引上采樣過程恢復到比較好的效果。即高低通道特征融合。恢復低級視覺信息
使用全卷積網(wǎng)絡(luò)做語義分割的矛盾就在于,圖片中的語義信息在大的感受野條件下,可以得到很好的分類結(jié)果。但是過大的感受野會丟失細節(jié)信息,丟失邊緣,局部信息,又不利于局部分割信息的恢復,如何設(shè)計網(wǎng)絡(luò)平衡這個矛盾是個比較重要的問題。毫無疑問,F(xiàn)CN提過了一個很不錯的方法和方向。即Encoder-Decoder并強調(diào)高低通道特征的融合。
二、Deeplab_v1
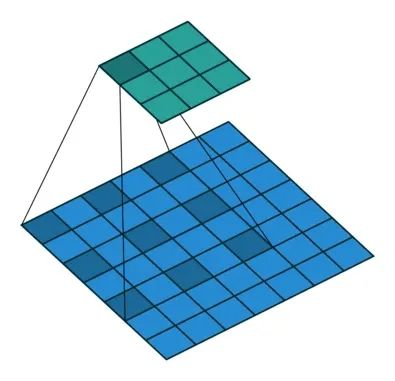
空洞卷積
因為主流的網(wǎng)絡(luò)為了獲取較大的感受野(理論上來說大的感受野有助于分類),都采用了conv中加上stride,或者采用pool(池化)來讓神經(jīng)網(wǎng)絡(luò)高層獲得的感受野更大,這樣分類結(jié)果會更準確,但帶來的缺點就是圖像分辨率會下降,同時maxpool這個操作會丟失圖像的部分細節(jié)信息,不利于分割任務(wù),所以在deeplab中大范圍用空洞卷積來擴大感受野,同時也盡量避免降低圖像分辨率的操作,這樣更容易恢復到原始分辨率大小。
特點:
空洞卷積,就是上圖這個東西,不損失分辨率和邊緣信息的情況下增大感受野
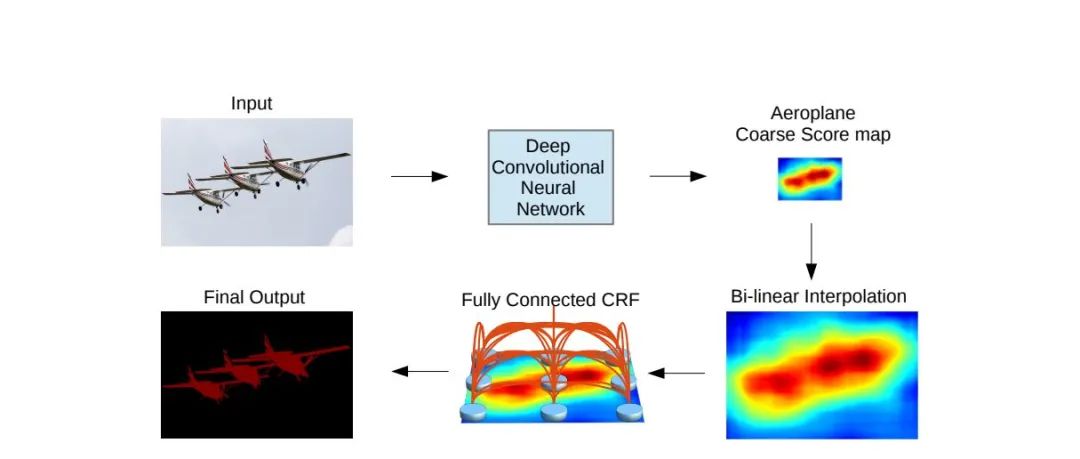
條件隨機場,雖然使用空洞卷積,但仍然存在著池化操作,并且卷積本身就會讓邊緣信息弱化一些,使用傳統(tǒng)的CRF條件隨機場能讓模糊的邊界信息更清晰,使圖像更加精細化,相當于網(wǎng)絡(luò)中的Decoder部分的功能。實際實驗中,CRF對于Deeplab的準確率提升非常顯著。
在deeplab中對于縮小后的圖像并沒有使用神經(jīng)網(wǎng)絡(luò)實現(xiàn)和fcn一樣的解碼器結(jié)構(gòu),而是使用了上頭的條件隨機場這個偏向傳統(tǒng)視覺處理的方法。后續(xù)的deeplabv3版本中已經(jīng)不使用該方法。
三、U-Net
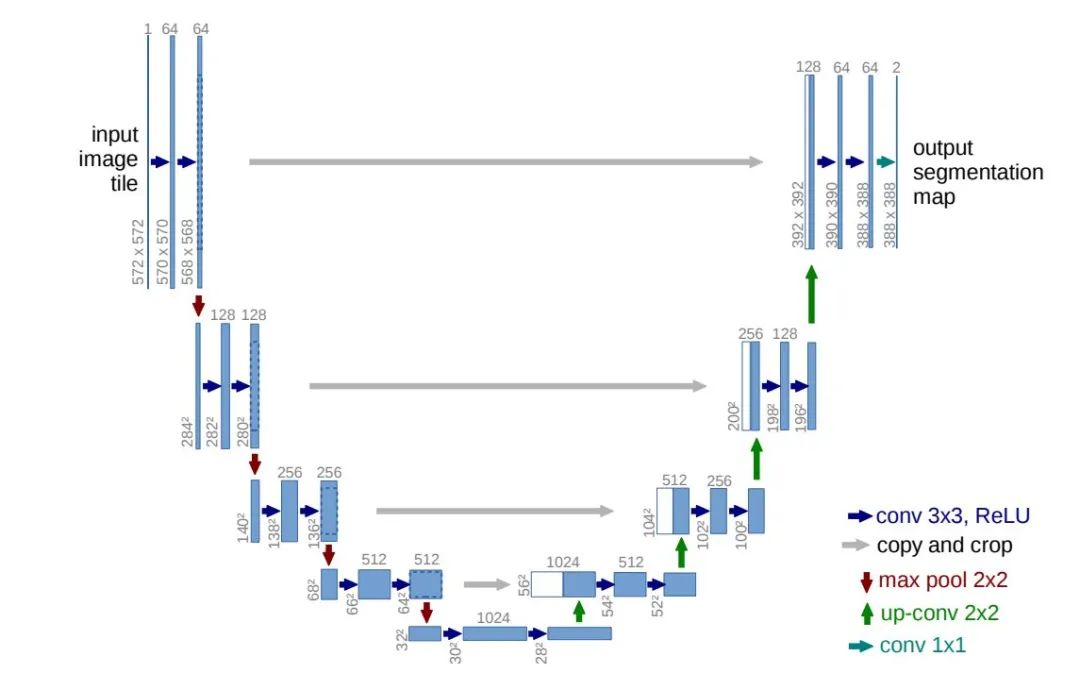
特點:
U-net的結(jié)構(gòu)非常對稱,優(yōu)雅,清晰。作者論文中的圖片簡明易懂,畫的真是太好看了好吧!!!
該網(wǎng)絡(luò)結(jié)構(gòu)強化了FCN中特征融合的思想,很明顯,每一層中都加入了低級通道的特征圖,并且,采用了通道疊加,而不是直接加和的思想,這樣給了網(wǎng)絡(luò)充足的能力去選擇不同的區(qū)域疊加不同的通道,而不是暴力加和,這個應(yīng)該是改進比較好的地方。
U-net在loss中引入了加權(quán)權(quán)重的思想,這個想法是很好的,因為由于感受野的問題,最后的特征圖的邊緣信息會弱一些,因為感受野捕獲到的邊界背景信息與主體信息幾乎是一半一半可以說,邊緣信息會弱化,那么增大邊緣部分的loss權(quán)重,會促使網(wǎng)絡(luò)在邊緣部分多留意,這樣會讓邊緣效果稍好一些。嗯就這樣。這也是大的感受野,與細分邊緣之間的矛盾。
可以看到這個網(wǎng)絡(luò)結(jié)構(gòu)還是比較淺的,不想其他主流網(wǎng)絡(luò)堆得很深,目前在醫(yī)療圖像分割領(lǐng)域用U-net的非常多,分割效果也很不錯,但在分類任務(wù)很復雜的的語義分割數(shù)據(jù)集中表現(xiàn)的并不是很好,這跟網(wǎng)絡(luò)本身比較淺也有關(guān)系。同時,正是由于U-net本身比較淺,很多低層視覺信息很重要,被保存了下來,所以在醫(yī)療圖像分割上可以達到很精準的邊緣提取,等等分割任務(wù)。
四、Seg-Net
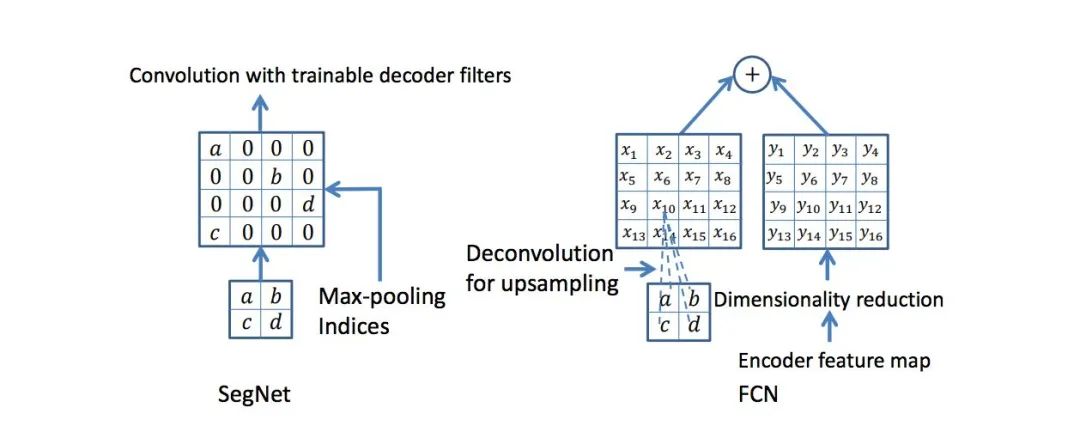
特點
在上采樣步驟那,進行了一個所謂的坐標上采樣功能,這樣恢復后的上采樣特征圖會將像素恢復在之前的坐標處,然后再結(jié)合低層的特征圖,得到比之前直接上采樣的效果會好一些,實際上這樣做性能是大幅提升了,速度快了很多,計算量和參數(shù)都少了很多,不過準確率只能說一般吧。
五、Deeplab_v2
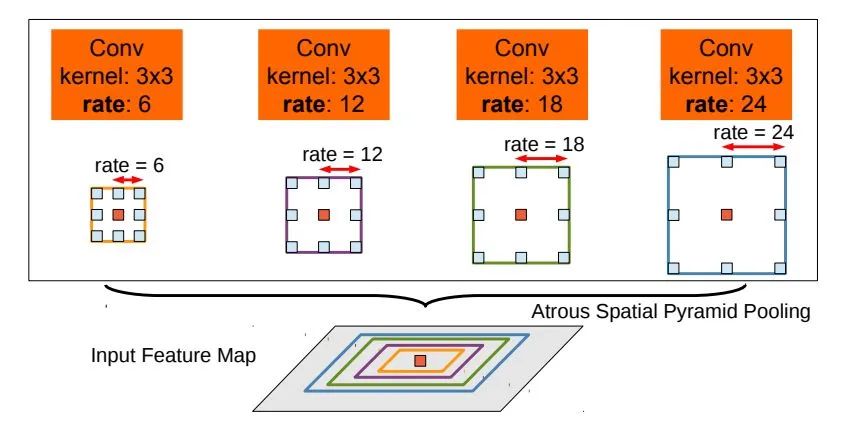
特點
用了新的Resnet結(jié)構(gòu),并將卷積替換成了空洞卷積部分。
ASPP模塊,也就是使用不同擴張率的空洞卷積來獲取最終特征圖上的不同大小的物體,還是關(guān)于感受野的問題,作者認為之前一味地提高感受野也不是好事,因為畢竟有大的物體,和小的物體,不能通過一個固定不變的感受野來解決問題,所以不同尺度的感受野很重要,所以大概設(shè)計了四種不同大小的感受野來找到對應(yīng)的物體。這個想法很不錯,很work,并且之前大家似乎都沒有提到,也沒有改進。
還是傳統(tǒng)的CRF,沒怎么看。。。
最大的改進就是ASPP模塊了,之前提到擴大感受野對于正確的分類有很大的好處,但是也不是一味地提升感受野,這樣必然會導致泛化能力太弱,圖片中的物體大小自然是不一樣的,用相同的感受野只能說對于某個大小的物體識別比較準確,一旦有比較大的,或者很小的自然效果很差,作者考慮到這個問題,在特征圖的最后加入了ASPP,簡單理解就是通過不同大小的空洞卷積模塊來達到不同的感受野的目的,這樣就可以對不同大小的物體都能做到比較準確地檢測,進而提高準確率,事實也證明這個網(wǎng)絡(luò)模塊非常有效!!
Fcis:基于實例分割的分割,其實實例分割有很多好處,實例分割,可以將分類和分割兩件事分離開來,正如何凱明在論文中提到的類間競爭,分割的時候只負責分割,然后類的事交給專門的分類網(wǎng)絡(luò)判斷,這樣可以減少相互之間的干擾,分類可以有較大的感受野,分割可以去獲得低層的視覺信息。也是種不錯的選擇吧。
特點
沒仔細看,覺得實例分割改善分割效果應(yīng)該會有幫助。最終語義分割也是要走向?qū)嵗指畹模▊€人覺得),并且實例分割帶來的分類和分割準確度的提升應(yīng)該很大,具體可以看mask-rcnn中對這一問題的闡述,我覺得何凱明大神的觀察真是非常透徹!!
六、RefineNet
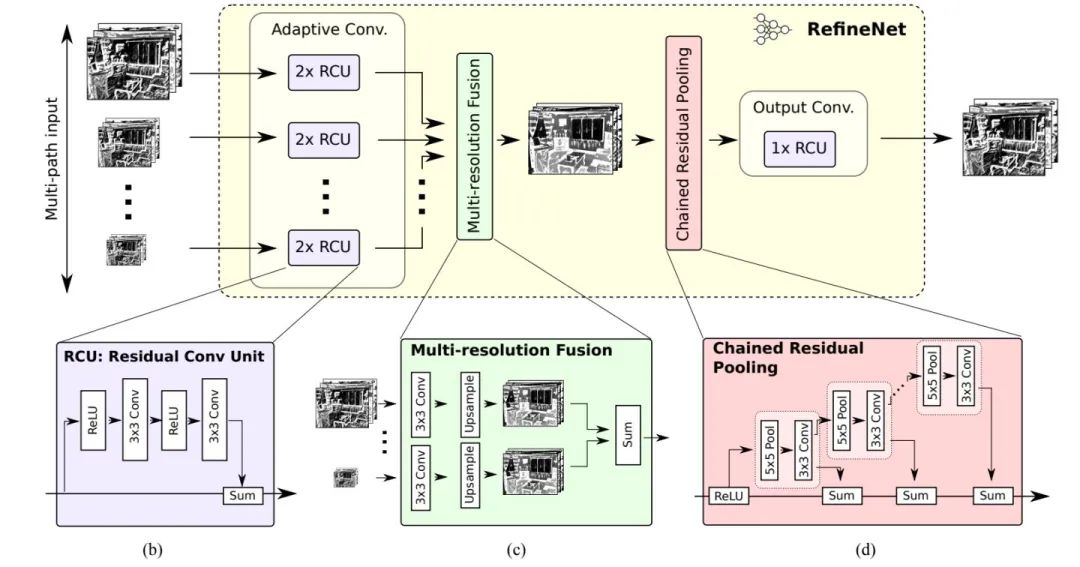
特點
整個網(wǎng)絡(luò)都是用Res-Net結(jié)構(gòu)的參差思想設(shè)計每個模塊,這是個很不錯的想法,如果某個地方學不到有用的信息,那就不要添亂嘛,直接映射原來的信息,可以讓網(wǎng)絡(luò)的信息流傳遞更加健康。
基本思路還是高低特征融合,也就加了點自己的pool鏈在里頭,還是根據(jù)何凱明的那個參差思想做的一個最大池化操作,這個操作還是比較有用的,增大了整個特征圖的感受野,有助于正確的分類結(jié)果
在每一個stage階段都進行了conv3的卷積操作,可能對于任務(wù)過渡也有一定的好處,這樣可以使網(wǎng)絡(luò)更加平滑地過渡到下一個功能階段。
附加loss是個不錯的決定,這樣加強了對網(wǎng)絡(luò)內(nèi)部層的監(jiān)督,這樣可能會導致更有效的結(jié)果,并能加快網(wǎng)絡(luò)的收斂吧。
七、Large Kernel Matters
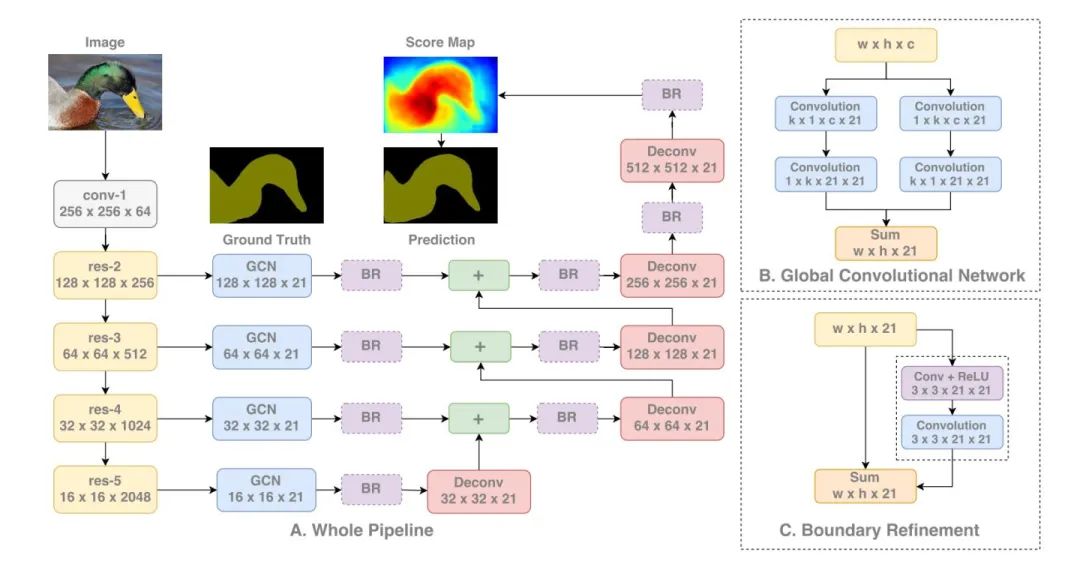
特點
?對于large kernel 的卷積模塊做了具體地解釋,盡管卷積操作能夠理論上到來較高的感受野,但實際上由于卷積的反向傳播,不重要的偏向邊緣信息由于在逐層的卷積和連接過程中,會慢慢地被削弱,這就涉及到文中提及的有效感受野問題,具體在一片論文中專門研究了實際有效感受野的問題。
當然直接在某一層使用大的感受野的卷積核,是一個非常直接、有效的擴充感受野的方法,但直接用大內(nèi)核會帶來很大的計算量。實際上之前googlenet中也介紹了這個問題,使用小的卷積核堆疊很多層來近似為一個大內(nèi)核的來達到這樣的效果。
在分類任務(wù)上,文中專門對如何設(shè)計大的內(nèi)核做了大量的詳細實驗,包括kxk,kx1與1xk相結(jié)合,3x3 的堆疊,實際上證明只有1xk-kx1是work的,甚至直接kxk的這樣的結(jié)構(gòu)效果都不夠好,這個和xception中提到的想法類似,都是講兩個操作分離化,這樣既減少了計算量,同時甚至帶來了效果上的提升,至于為什么會帶來很大的提升,作者說的都是我們猜,我們假設(shè),神經(jīng)網(wǎng)絡(luò)本來很多東西都是基于經(jīng)驗,基于實驗嘛,哈哈,大家自己想一想吧。
同時網(wǎng)絡(luò)中為了細化邊緣還引入了一個叫BR的邊緣定義模塊,其實就是一個普通的參差模塊嗎,可能這個模塊放在底高層的特征圖融合后,能夠剛好配合反向傳播學到一些對邊緣細化有用的信息,也就是大家都在做的對decoder模塊的各種各樣的小改進,有效果就好。個人覺得不是太重要的東西。
八、deeplabv3
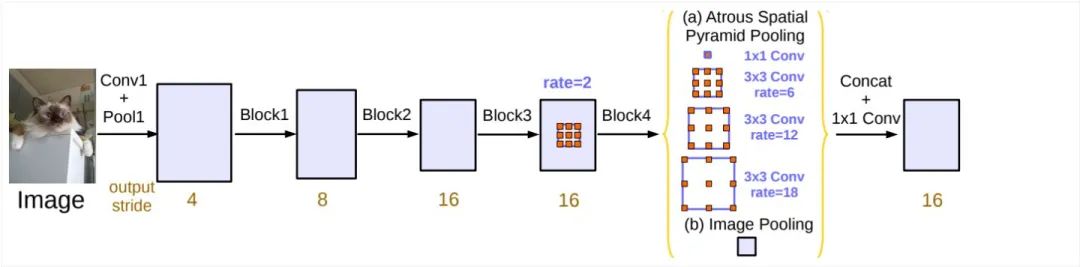
特點
加入了像素級別的特征圖以及原始的圖片信息在ASPP模塊中,實際上沒改什么東西,也就是把特征融合地更多了,這有點顯而易見,必然結(jié)合的特征越多,對于效果的提升越來越大。
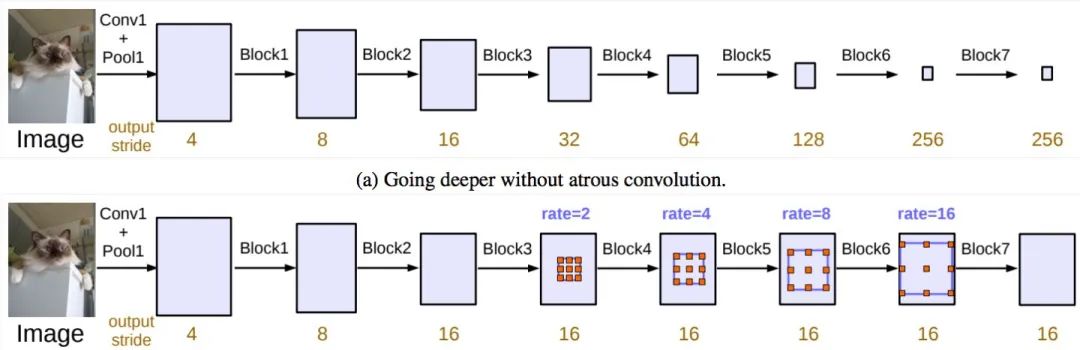
嘗試了級聯(lián)空洞卷積模塊,實際應(yīng)用中發(fā)現(xiàn)是不work得,從res的四個模塊加到了7個模塊后沒有發(fā)現(xiàn)較大的性能提升。當然這樣一味地增大感受野沒有ASPP那樣對不同層次,和不同大小的有效感受野從理論上和實踐上有效果。
去掉了CRF模塊,證明網(wǎng)絡(luò)已經(jīng)基本上與其他的end to end網(wǎng)絡(luò)達到了同樣性能,沒有CRF這樣的黑科技的加成下,哈哈。
本來個人認為,語義分割就是用神經(jīng)網(wǎng)絡(luò)來實習端到端的分割結(jié)果,來找出每個像素的分類結(jié)果,盡可能保留主要語音信息,邊緣稍微有些混亂,也是正常現(xiàn)象,通過各種各樣傳統(tǒng)視覺算法中的trick當然可以細化這個邊緣結(jié)果,讓效果更好,不過既然大家主要都是研究神經(jīng)網(wǎng)絡(luò),那就只用神經(jīng)網(wǎng)絡(luò)這塊的性能提升來比較客觀、公正一些。
九、deeplabv3+
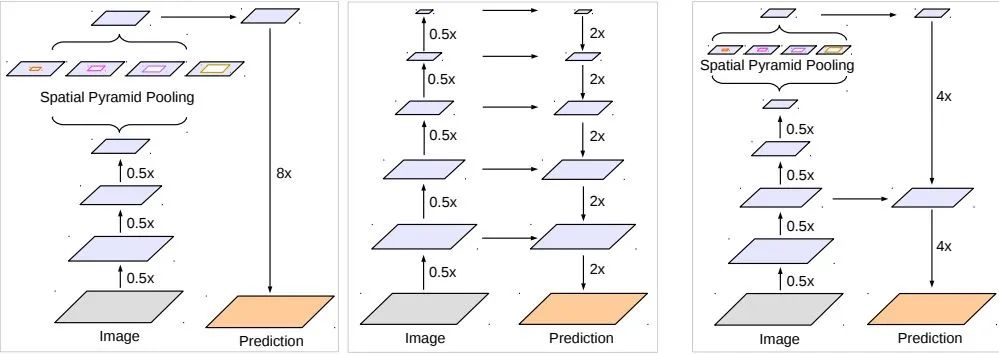
特點
主干網(wǎng)絡(luò)采取了Xception,并融入了他的空洞卷積操作
采用了Decoder模塊,那為什么沒有像其他網(wǎng)絡(luò)一樣經(jīng)過了很多個低級特征到高級特征的融合呢?在4倍到原始分辨率的時候,我猜這是因為可能再低級的信息缺乏價值???可能我看的不夠仔細吧,明明我覺得中間的解碼結(jié)構(gòu)是很好的,沒有看到作者介紹(可能我沒仔細看--)。或者對于deeplab這樣的結(jié)構(gòu)來說兩次解碼已經(jīng)可以達到很好的效果,再多的信息可能沒有什么提升吧。
推薦閱讀
關(guān)于程序員大白
程序員大白是一群哈工大,東北大學,西湖大學和上海交通大學的碩士博士運營維護的號,大家樂于分享高質(zhì)量文章,喜歡總結(jié)知識,歡迎關(guān)注[程序員大白],大家一起學習進步!