
深度探討CrossFormer如何解決跨尺度問題

極市導讀
浙大聯合騰訊等開源的新視覺模塊CrossFormer最近開源,該工作通過提出兩個模塊:CEL和LSDA,彌補了以往架構在建立跨尺度注意力方面的缺陷。本文作者對其進行了詳細的分析,介紹了各模塊的設計原理模型結構,更深入的了解工作的核心。 >>加入極市CV技術交流群,走在計算機視覺的最前沿

1. 出發(fā)點
Transformers模型在處理視覺任務方面已經取得了很大的進展。然而,現有的vision transformers仍然不具備一種對視覺輸入很重要的能力:在不同尺度的特征之間建立注意力。
每層的輸入嵌入都是等比例的,沒有跨尺度的特征; 一些transformers模型為了減少self-attention的計算量,衰減了key和value的部分特征表達。
2. 怎么做
為了解決上面的問題,提出了幾個模塊。
Cross-scale Embedding Layer (CEL) Long Short Distance Attention (LSDA) Dynamic Position Bias (DPB)
這里1和2都是為了彌補了以往架構在建立跨尺度注意力方面的缺陷,3的話和上面的問題無關,是為了使相對位置偏差更加靈活,更好的適合不定尺寸的圖像和窗口。這篇文章還挺講究,不僅提出兩個模塊來解決跨尺度特征attention,還附送了一個模塊來搞一個搞位置編碼。
3. 模型結構

模型整體的結構圖如上所示,與swin-transformers和pvt基本整體結構一致,都是采用了層級的結構,這樣的好處是可以遷移到dense任務上去,做檢測,分割等。整體結構由以下組成:
Cross-scale embeeding layer (CEL) , 用來做patch embeeding和patch merging(下采樣)。 CrossFrom block, 看上圖(b),整體看是兩個transformer結構的block所組成,其中第一個transformer block采用的是SDA,也就是short distance attention,并且引入了一個DPB模塊,第二個transformer block采用的則是LDA,也就是long distance attention,同樣也引入了一個DPB模塊,兩個transformer block串行,組成一個CrossFormer block。 Classification Head, 就是常規(guī)的分類MLP,沒啥可說的。
3.1 Cross-scale embeeding layer (CEL)
Q&A
Question:既然是層級結構,那么就一定會有尺度上的下采樣,那crossformers是怎么做的呢?
Answer: 簡單回顧一下pvt和swin的做法
pvt: 假設feature map為, 那么我們就可以做一個stride為2的一個convolution, 變換為,由于patchsize固定,所以,featuremap下采樣,對應的就是token的下采樣。
swin: swin由于是基于windows做attention,為了達到下采樣的效果,選擇直接對featuremap上采樣,每個4鄰域都會分別采樣到另一個map里面去,最后則有變換為,也可以看做是stride為2帶有空洞的卷積操作。
Question: 萬變不離其宗,所以為了達到下采樣的效果,用卷積其實就可以了。那么CrossFormer為了實現下采樣是怎么做的呢?
Answer:
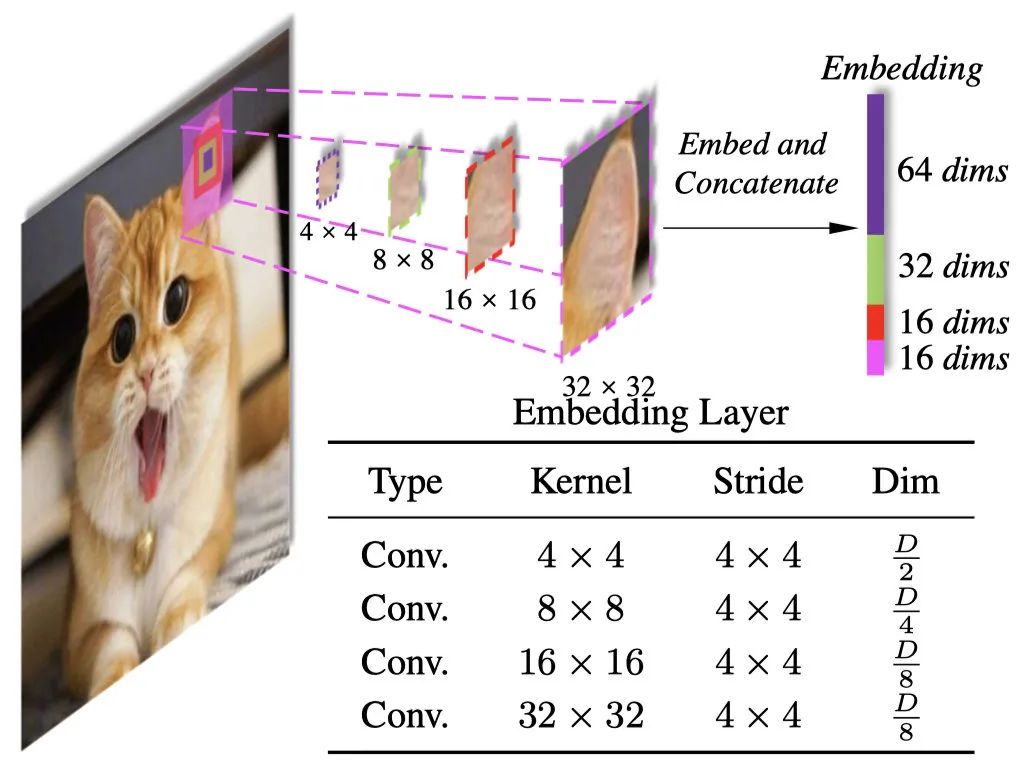
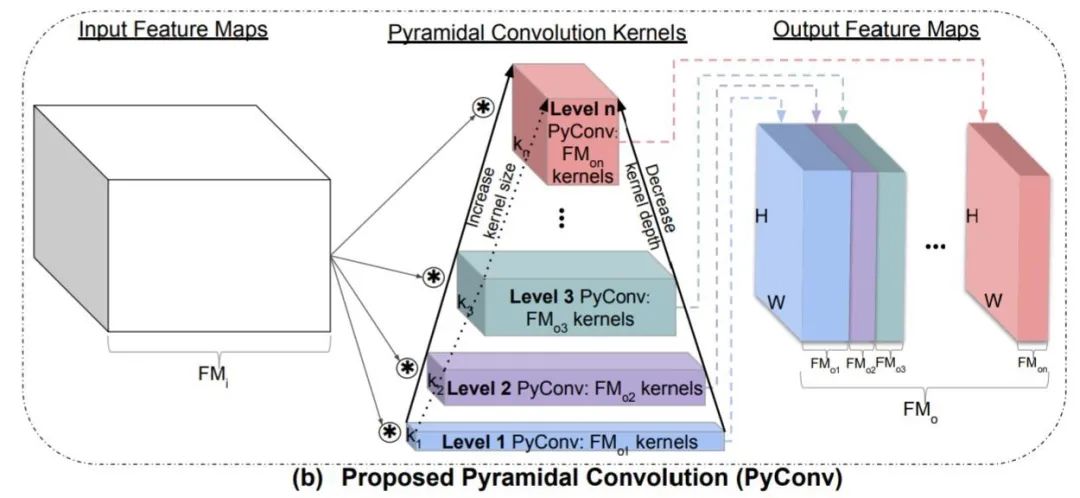
看上圖,很明顯,直接用不同卷積核來對輸入的圖片做卷積,得到卷積后的結果,直接concat一起,作為我們的patch embeeding。想法很簡單,實現的話也很樸素,通過不同卷積核的卷積,來獲取不同尺度特征的信息,對于變化尺度的物體相對來說是比較友好的,這個可行性其實在很多paper里面都有用到過,比如Pyramidal Convolution, 如下圖所示。
ps: 這里除了patch embeeding,也就是第一個CEL用的是4個卷積核stride為4來做多尺度,其余的CEL也就是patch merge用的都是2個卷積核stride為2來做的多尺度。兩個操作基本相同,只看一份代碼即可,核心代碼如下:
class PatchEmbed(nn.Module):
def __init__(self, img_size=224, patch_size=[4], in_chans=3, embed_dim=96, norm_layer=None):
super().__init__()
...
self.projs = nn.ModuleList()
for i, ps in enumerate(patch_size):
if i == len(patch_size) - 1:
dim = embed_dim // 2 ** i
else:
dim = embed_dim // 2 ** (i + 1)
stride = patch_size[0]
padding = (ps - patch_size[0]) // 2
self.projs.append(nn.Conv2d(in_chans, dim, kernel_size=ps, stride=stride, padding=padding))
if norm_layer is not None:
self.norm = norm_layer(embed_dim)
else:
self.norm = None
def forward(self, x):
B, C, H, W = x.shape
# FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
xs = []
for i in range(len(self.projs)):
tx = self.projs[i](x).flatten(2).transpose(1, 2)
xs.append(tx) # B Ph*Pw C
x = torch.cat(xs, dim=2)
if self.norm is not None:
x = self.norm(x)
return x
代碼做了兩件事情:
初始化幾個不同kernel,不同padding,相同stride的conv 對輸入進行卷積操作后得到的feature,做concat
這樣, 以輸入為224x224為例, 我們通過patch embeeding, 得到了一個56x56的featuremap,輸入到第一個stage,輸出繼續(xù)做一個patchmerging,得到了一個28x28的featuremap,輸入到第二個stage,輸出繼續(xù)做一個patchmerging,得到了一個14x14的featuremap, 輸入到第三個stage, 輸出再次做一個patchmerging,得到一個7x7的featuremap,在輸入到最后一個stage,最后的輸出做分類即可,基本上都是這么一個套路了,大同小異。那么stage里面是怎么做的,看下一節(jié)。
3.2 Stage block
對于標準的transformerblock來說,假設輸入為, 經過transformer后,我們的輸出還是,輸入和輸出是沒有變化的,唯一的尺度變換都在patch embeeding和patch merging。那么我們在改動transformer block的時候,也是要遵守這一原則,對應的,如果想有resolution上的變化,那么就要借助于reshape或者view等操作,好了,不說廢話,看這篇文章的crossformer block是怎樣的。
CrossFormer Block
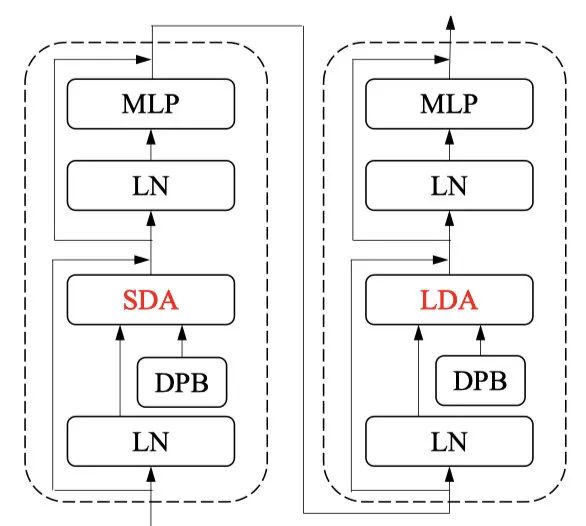
CrossFormer block由兩個transformer的block堆疊而成,兩個transformer block的self-attention都是基于windows來做的,不同之處在于一個考慮的是局部內的信息,一個則是考慮的是全局的信息。這個思想并沒有什么突出的地方,目前來說transformer做局部和全局的串聯,已經屢見不鮮。
Q&A
Question: 問題來了,怎樣實現呢,既要保證基于windows做self-attention,又想要全局的信息?
Answer: 使用一個固定的步長step,比如2或者3,對行和列分別按步長采樣,這樣可以得到多個全局的信息,同時基于一個大小的windows。這樣最大可能的利用到了featuremap的全局性,同時節(jié)省了計算的復雜度,假設輸入為,step為,那么windows的窗口大小為,原始的復雜度為, 那么基于窗口的attention的復雜度為。
CrossFormerblock中的基石: windows self-attention
Short Distance Attention(SDA)

SDA 對于一個的feautremap,如果我們想要實現self-attention, 需要先轉換為的向量,那么這里就是所謂的long-range的attention,也就是全局的。但是對于MHA來說,部分head還是更多的focus到short-range,結合swin和twins的結論可以驗證,局部attention不僅可以達到很好的效果同時還會節(jié)省計算。那么怎么獲得局部的attention,很簡單,如上圖所示,只需要把原始的做reshape操作, 既可以得到,那么我們只需要對4個做attention即可,最后在reshape回原始形狀,代碼如下:
x = x.reshape(B, H // G, G, W // G, G, C).permute(0, 1, 3, 2, 4, 5)
x = attention(x)
....Long Distance Attention(LDA)

LDA 從上面的SDA, 我們得到了局部attention,但是也說了,部分head是局部友好的,也就是說,對于self-attention來說,long-range始終是必不可少的,所以還是需要引入long distance attention。如上圖所示,顏色一致的部分表示的是歸屬于同一個sub-windows的,對于原始的,使用step為2進行采樣,得到了4個, 可以抽象成兩種計算方法,一種是空洞卷積,一種則是1x1的卷積,stride為step,對于圖像來說,相鄰的位置,像素所表達的信息接近,所以兩種得到的都是全局的一個感受野,所以對應我們的attention,也會得到一個近乎全局的attention,代碼如下:
x = x.reshape(B, G, H // G, G, W // G, C).permute(0, 2, 4, 1, 3, 5)
x = attention(x)
...直接看這個代碼可能不太好理解,我們用
einops簡單改寫一下,代碼如下: 輸入:
x[0,:,:,0]
tensor([[ 1, 2, 3, 4],
[ 2, 4, 6, 8],
[ 3, 6, 9, 12],
[ 4, 8, 12, 16]])
x.shape
torch.Size([1, 4, 4, 1])
a1 = rearrange(x, ' b (h g1) (w g2) c -> b h w g1 g2 c ', g1=2, g2=2)
a1[0,:,:,:,:,0]
tensor([[[[ 1, 2],
[ 2, 4]],
[[ 3, 4],
[ 6, 8]]],
[[[ 3, 6],
[ 4, 8]],
[[ 9, 12],
[12, 16]]]])
a2 = rearrange(x, ' b (g1 h) (g2 w) c -> b h w g1 g2 c ', g1=2, g2=2)
a2[0,:,:,:,:,0]
tensor([[[[ 1, 3],
[ 3, 9]],
[[ 2, 4],
[ 6, 12]]],
[[[ 2, 6],
[ 4, 12]],
[[ 4, 8],
[ 8, 16]]]])
CrossFormerblock中的位置編碼: Dynamic Position Bias(DPB)
Relative position bias (RPB)隨著位置編碼技術的不斷發(fā)展,相對位置編碼偏差逐漸的應用到了transformers中,很多的vision transformers均采用RPB來替換原始的APE,好處是可以直接插入到我們的attention中,不需要很繁瑣的公式計算,并且可學習性高,魯棒性強,公式如下:
Dynamic Position Bias (DPB)

DPB 舉個栗子,如果我們的窗口大小為, 那么我們希望的相對位置范圍為假設我們不考慮截斷距離,如果我們的窗口突然放大到了,那么我們實際的相對位置所表達的信息只是中間的一部分窗口,失去了對外層數據位置的訪問。DPB的思想則是,我們不希望通過用實際的相對位置來做embeeidng,而是希望通過隱空間先對位置偏差進行學習,如上圖所示。
DPB,由3個線性層+LayerNorm+ReLU組成的block堆疊而成,最后接一個輸出為1的線性層做bias的表征,輸入是,由于self-attention是由多個head組成的,所以輸出為,代碼如下:
先得到一個相對位置偏差的矩陣,假設group_size的大小為,那么bias的維度為
self.pos = DynamicPosBias(self.dim // 4, self.num_heads, residual=False)
# generate mother-set
position_bias_h = torch.arange(1 - self.group_size[0], self.group_size[0])
position_bias_w = torch.arange(1 - self.group_size[1], self.group_size[1])
biases = torch.stack(torch.meshgrid([position_bias_h, position_bias_w])) # 2, 2Wh-1, 2Wh-1
biases = biases.flatten(1).transpose(0, 1).float()
self.register_buffer("biases", biases)
biases:
tensor([[-6., -6.],
[-6., -5.],
[-6., -4.],
[-6., -3.],
[-6., -2.],
[-6., -1.],
...
[ 6., 4.],
[ 6., 5.],
[ 6., 6.]])構建索引矩陣, 得到了一個的一個索引,從右上角為0開始,向左和向下遞增。
coords_h = torch.arange(self.group_size[0])
coords_w = torch.arange(self.group_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.group_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += self.group_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.group_size[1] - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index", relative_position_index)
relateive_position_index:
tensor([[ 84, 83, 82, ..., 2, 1, 0],
[ 85, 84, 83, ..., 3, 2, 1],
[ 86, 85, 84, ..., 4, 3, 2],
...,
[166, 165, 164, ..., 84, 83, 82],
[167, 166, 165, ..., 85, 84, 83],
[168, 167, 166, ..., 86, 85, 84]])初始化DBP模塊
pos = DynamicPosBias(64 // 4, 8, residual=False)通過DBP生成bias的embeeding,通過索引矩陣進行取值,最后與attn相加
pos = self.pos(self.biases) # 2Wh-1 * 2Ww-1, heads
# select position bias
relative_position_bias = pos[self.relative_position_index.view(-1)].view(
self.group_size[0] * self.group_size[1], self.group_size[0] * self.group_size[1], -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
attn = attn + relative_position_bias.unsqueeze(0)Rethinking: 對于PE來說,目前的形成方法都是通過embeeding來構建bias矩陣,對于VIT來說,直接使用絕對位置的embeeding,通過學習來更新,對于swins來說,直接使用embeeding而不是相對bias的值,相當于,其實本質上沒有太大的差異, 從消融實驗結果上來看,DBP和RBP的性能一樣。唯一的作用,就是embeeding是后驗而不是先驗,對于變換的尺寸來說,可能更加友好,只不過這個paper里面沒有給出結論,還需要更多的實驗來驗證。

DBP&RBP
綜上,我們每個stageblock里面,都是由SDA+DBP&LDA+DBP堆疊而成,與swin類似,奇數layer走SDAblock,偶數layer走LDAblock,從結構上來看,先局部attention,再全局attention,有一點點由點到面的既視感。
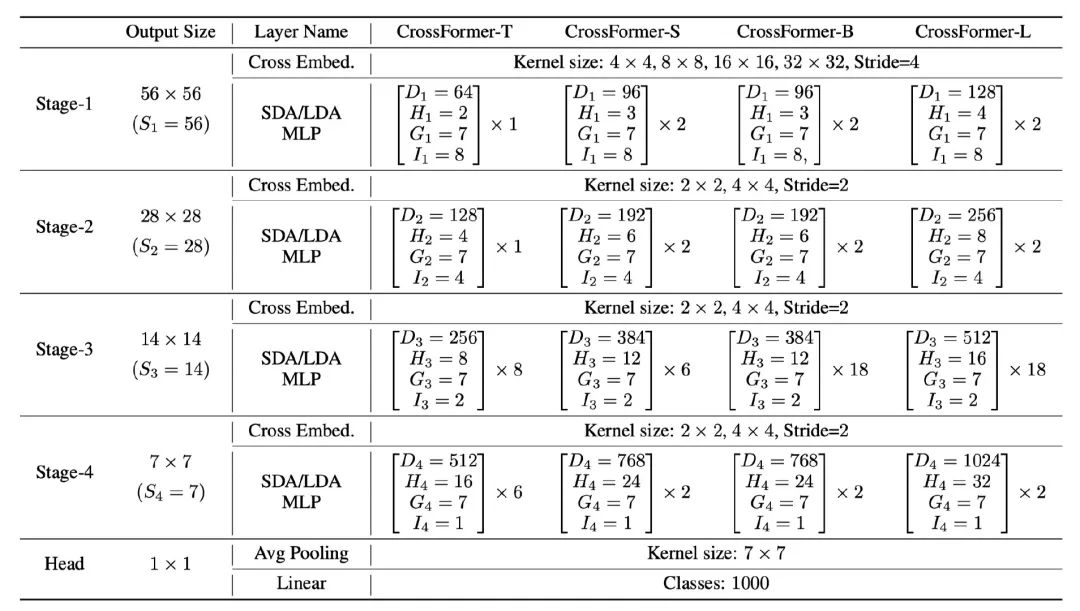
與其他的paper大同小異了,設計了4種不同FLOPs的模型,Tiny, Small, Big和Large 用來和其他的模型在同等FLOPs下公平比較。表示的是維度,表示的是attention頭的個數,表示的是attention窗口的大小,表示的是滑動窗口的間隔。
4. 實驗結果

CrossFormer都是再224x224的圖片大小下進行訓練,使用的類似DeiT的訓練策略,不過采用了更大的warmup(20個,DeiT是5), 學習率為1e-3, weightdecay為5e-2, 與DeiT不同的是,這里隨著模型大小的改變,分別采用了0.1,0.2,0.3,0.5的drop path rate。可以看到,在同等數量級的FLOPs的情況下,CF在imagenet上都取得了SOTA的效果。
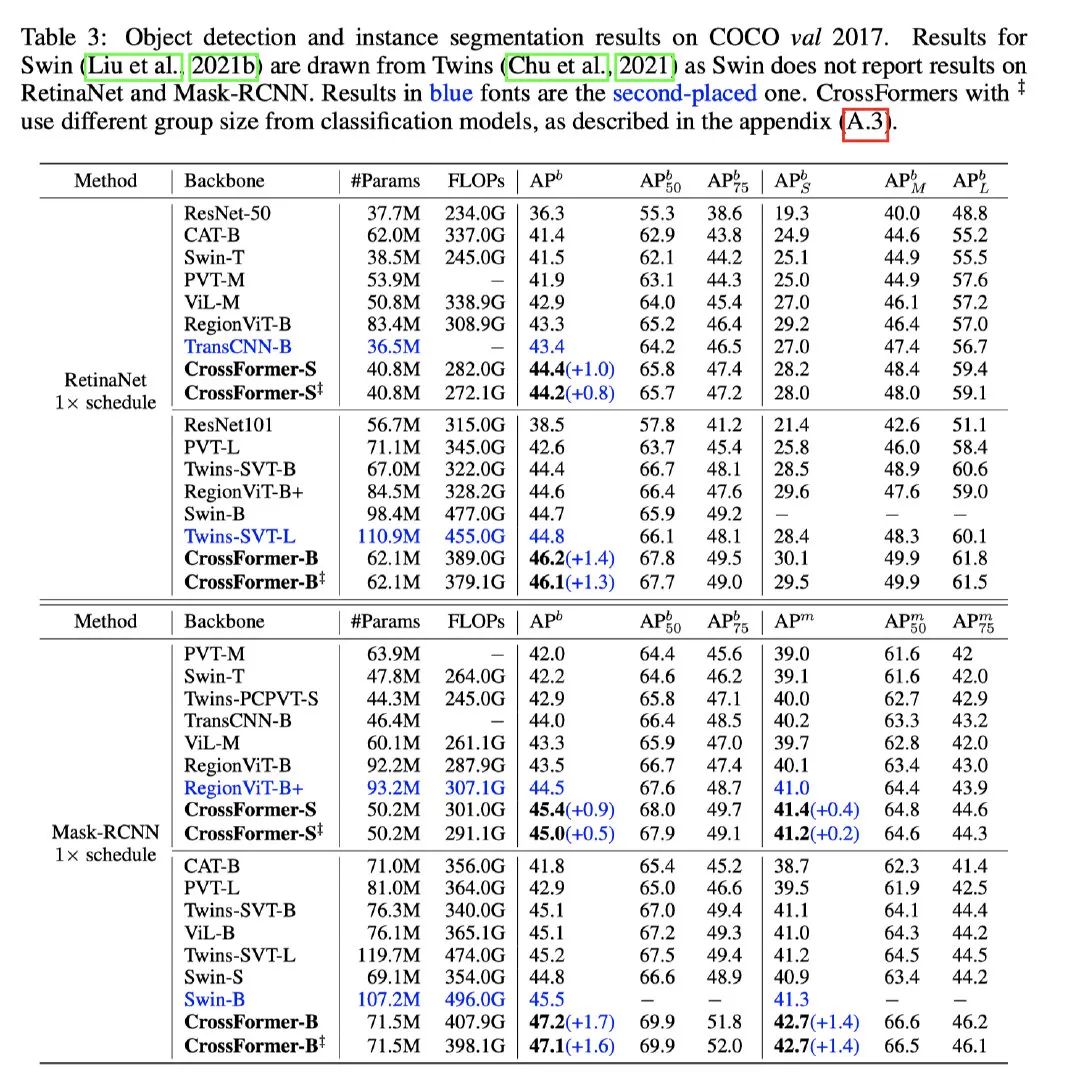
可以看到CrossFromer在coco2017上基于RetinaNet架構,也可以達到SOTA的效果,高于Twins模型1.4個ap之多。實例分割則是基于Mask-Rcnn的架構,也是SOTA,超過Swin 1.7個ap。相比而言參數量和FLOPs都更少,性能更好。

語義分割上,可以看到可以看到最多提升3.3%的MIOU,非常厲害了。

消融實驗上,可以看到,當CEL和LSDA一起使用的時候,性能最高。不過這實驗也很明顯了,CrossFormer參考了PVT和swin的設計思想。使用了LSDA,相比于Swin提升了0.6%個點,設計比swin更加樸實,不錯的提升。
5. 結論
本文提出了一個新的transformers架構稱為CrossFormer。其核心設計包括一個跨尺度嵌入層(CEL)和長短距離注意(LSDA)模塊。此外,我們提出了動態(tài)位置偏置(DPB),使相對位置偏置適用于任何輸入尺寸。實驗表明,CrossFormer在幾個有代表性的視覺任務上取得了SOTA。特別是,CrossFormer在檢測和分割方面有很大的改進,這表明跨尺度嵌入和LSDA對于密集預測的視覺任務特別重要。
如果覺得有用,就請分享到朋友圈吧!
公眾號后臺回復“CVPR21檢測”獲取CVPR2021目標檢測論文下載~

# 極市平臺簽約作者#

FlyEgle
知乎:FlyEgle
歡聚時代算法工程師
領域:OCR, 圖像視頻內容理解,超分
github: https://github.com/FlyEgle
