
如何解決TOP-K問題
最近在開發(fā)一個功能:動態(tài)展示的訂單數(shù)量排名前10的城市,這是一個典型的Top-k問題,其中k=10,也就是說找到一個集合中的前10名。實際生活中Top-K的問題非常廣泛,比如:微博熱搜的前100名、抖音直播的小時榜前50名、百度熱搜的前10條、博客園點贊最多的blog前10名,等等如何解決這類問題呢?初步的想法是將這個數(shù)據(jù)集合排序,然后直接取前K個返回。這樣解法可以,但是會存在一個問題:排序了很多不需要去排序的數(shù)據(jù),時間復(fù)雜度過高.假設(shè)有數(shù)據(jù)100萬,對這個集合進行排序需要很長的時間,即便使用快速排序,時間復(fù)雜度也是O(nlogn),那么這個問題如何解決呢?解決方法就是以空間換時間,使用優(yōu)先級隊列
一:認識PriorityQueue
1.1:PriorityQueue位于java.util包下,繼承自Collection,因此它具有集合的屬性,并且繼承自Queue隊列,擁有add/offer/poll/peek等一系列操作元素的能力,它的默認大小是11,底層使用Object[] 來保存元素,數(shù)組的話肯定會有擴容,當(dāng)添加元素的時候大小超過數(shù)組的容量,就會擴容,擴容的大小為原數(shù)組的大小加上,如果元素的數(shù)量小于64,則每次加2,如果大于64,則每次增加一半的容量。
1.2:PriorityQueue的構(gòu)造方法
public PriorityQueue(Comparator<? super E> comparator) {this(DEFAULT_INITIAL_CAPACITY, comparator);}
public PriorityQueue(int initialCapacity,Comparator<? super E> comparator) {// Note: This restriction of at least one is not actually needed,// but continues for 1.5 compatibilityif (initialCapacity < 1)throw new IllegalArgumentException();this.queue = new Object[initialCapacity];this.comparator = comparator;}
比較常用的就是這兩個構(gòu)造方法,其中第一個構(gòu)造方法中需要構(gòu)造一個比較器,第二個構(gòu)造方法添加初始容量和比較器,比較器可以自定義任何元素的優(yōu)先級,按照需要增加元素的優(yōu)先級展示
1.3:PriorityQueue的常用API

1.3.1:offer方法和add方法用于添加元素,本質(zhì)上offer方法和add方法是相同的:
public boolean add(E e) {return offer(e);}
offer方法主要步驟就是判空、擴容、添加元素,添加元素的話,siftup方法里會根據(jù)構(gòu)造方法,如果有比較器就進行比較,沒有比較器的話就給元素賦予比較能力,并且根據(jù)構(gòu)造的大小,也就是
initialCapacity進行比較,如果比較器的compare方法不符合定義的規(guī)則,直接break;符合的話會給數(shù)組的元素進行賦值
public boolean offer(E e) {if (e == null)throw new NullPointerException();modCount++;int i = size;if (i >= queue.length)grow(i + 1);size = i + 1;if (i == 0)queue[0] = e;elsesiftUp(i, e);return true;}
1.3.2:poll方法和peek方法都是返回頭元素,不同之處在于poll方法會返回頭頂元素并且移除元素,peek方法不會移除頭頂元素:
public E poll() {if (size == 0)return null;int s = --size;modCount++;E result = (E) queue[0];E x = (E) queue[s];queue[s] = null;if (s != 0)siftDown(0, x);return result;}public E peek() {return (size == 0) ? null : (E) queue[0];}
二:PriorityQueue解決問題
2.1:數(shù)組的前K大值

代碼:
import java.util.PriorityQueue;public class TopK {//找出前k個最大數(shù),采用小頂堆實現(xiàn)public static int[] findKMax(int[] nums, int k) {PriorityQueue<Integer> pq = new PriorityQueue<>(k);//隊列默認自然順序排列,小頂堆,不必重寫comparefor (int num : nums) {if (pq.size() < k) {pq.offer(num);//如果堆頂元素 < 新數(shù),則刪除堆頂,加入新數(shù)入堆,保持堆中存儲著大值} else if (pq.peek() < num) {pq.poll();pq.offer(num);}}int[] result = new int[k];for (int i = 0; i < k && !pq.isEmpty(); i++) {result[i] = pq.poll();}return result;}}
測試:
public static void main(String[] args) {int[] arr = new int[]{1, 6, 2, 3, 5, 4, 8, 7, 9};System.out.println(Arrays.toString(findKMax(arr, 3)));}
//輸出:

優(yōu)先級隊列是如何解決這個問題的呢?
PriorityQueue默認是小頂堆,那么什么是小頂堆?什么是大頂堆?假設(shè)有3、7、8三個數(shù),需要存儲在優(yōu)先級隊列里,畫個圖大家理解下:
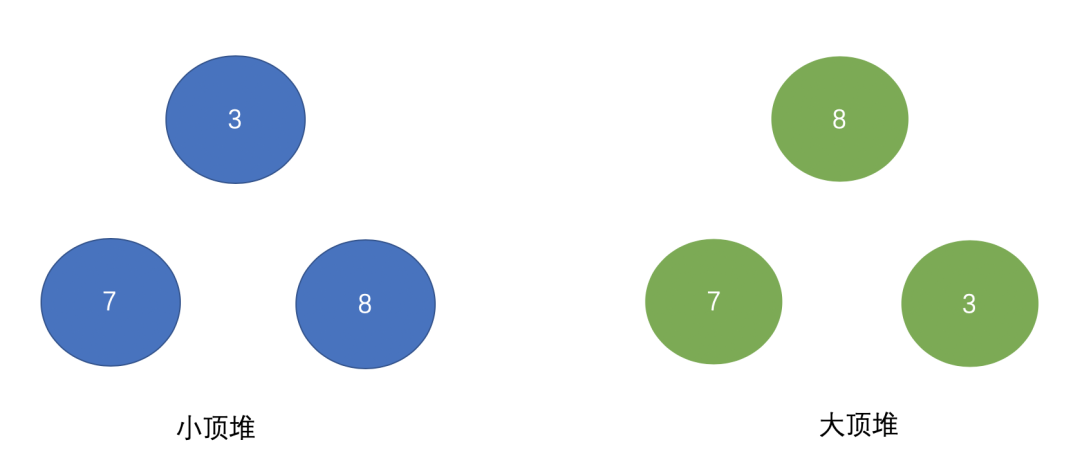
可以看出小頂堆的頭頂元素存儲著整個數(shù)據(jù)集合中數(shù)字最小的元素,而大頂堆存儲著整個數(shù)據(jù)集合中數(shù)字最大的元素,也就是一個按照升序排列,一個按照降序排列:
//小頂堆的構(gòu)建方法:PriorityQueue<Integer> queue = new PriorityQueue<>(k);//這種寫法等價于:PriorityQueue<Integer> queue = new PriorityQueue<>(k, new Comparator<Integer>() {@Overridepublic int compare(Integer o1, Integer o2) {return o1-o2;}});//同時等價于(lamda表達式的寫法)PriorityQueue<Integer> queue = new PriorityQueue<>(k, (o1, o2) -> o1-o2);//大頂堆的構(gòu)建方法:PriorityQueue<Integer> queue = new PriorityQueue<>(k, new Comparator<Integer>() {@Overridepublic int compare(Integer o1, Integer o2) {return o2-o1;}});
拿測試用例這個例子來說:
構(gòu)建的是指定容量的小頂堆,因此每次queue.peek()返回的是最小的數(shù)字,在遍歷數(shù)組的過程中,如果遇到比該數(shù)字大的元素就將最小的數(shù)字poll(移除掉),然后將較大的元素添加到堆中,在添加進去堆中的時候,堆同時會按照優(yōu)先級比較,將最小的元素再次放到堆頂,這樣的做法就是會一直保持堆中的元素是相對較大的,同時堆頂元素是堆中最小的。
按照測試用例給出的例子,{1, 6, 2, 3, 5, 4, 8, 7, 9} 優(yōu)先級隊列將會是這樣轉(zhuǎn)變的:(注意:本質(zhì)上優(yōu)先級隊列的實現(xiàn)方式是數(shù)組,這里只是用二叉樹的方式表現(xiàn)出來)

假如該題換個角度,求出現(xiàn)頻率最低的元素怎么做呢?
相信你根據(jù)上面的講述應(yīng)該也明白了:直接構(gòu)建一個大頂堆,這樣元素最大的值在堆頂,每次去和數(shù)組的元素的值去做比較,只要堆頂元素比數(shù)組的值小,就將堆頂元素poll出來,然后將數(shù)組的值添加進去,這樣就可以一直保持集合數(shù)組中一直是最小的k個數(shù)字。
2.2:前k個高頻元素

當(dāng)k = 1 時問題很簡單,線性時間內(nèi)就可以解決,只需要用哈希表維護元素出現(xiàn)頻率,每一步更新最高頻元素即可。當(dāng) k > 1 就需要一個能夠根據(jù)出現(xiàn)頻率快速獲取元素的數(shù)據(jù)結(jié)構(gòu),這里就需要用到優(yōu)先隊列
首先建立一個元素值對應(yīng)出現(xiàn)頻率的哈希表,使用 HashMap來統(tǒng)計,然后構(gòu)建優(yōu)先級隊列,這里依舊是構(gòu)建小頂堆,不過因為該題是計算元素出現(xiàn)的頻率,因此我們需要將每個元素的頻率值做對比,
需要重寫優(yōu)先級隊列的comparator,需要手工填值:這個步驟需要 O(N)O(N) 時間其中 NN 是列表中元素個數(shù)。
第二步建立堆,堆中添加一個元素的復(fù)雜度是 O(\log(k))O(log(k)),要進行 NN 次復(fù)雜度是 O(N)O(N)。
最后一步是輸出結(jié)果,復(fù)雜度為 O(k\log(k))O(klog(k)):
public int[] topK(int[] nums, int k) {//統(tǒng)計字符出現(xiàn)的頻率的mapMap<Integer, Integer> count = new HashMap();for (int num : nums) {count.put(num, count.getOrDefault(num, 0) + 1);}//根據(jù)出現(xiàn)頻率的map來構(gòu)建k個元素的優(yōu)先級隊列PriorityQueue<Integer> heap =new PriorityQueue<>(k, (o1, o2) -> count.get(o1) - count.get(o2));for (int n : count.keySet()) {heap.add(n);if (heap.size() > k)heap.poll();}int[] result = new int[heap.size()];for (int i = 0; i < result.length; i++) {result[i] = heap.poll();}return result;}
測試:
public static void main(String[] args) {int[] nums = {1, 1, 1, 3, 5, 6, 5, 6, 5, 4, 7, 8};int[] res = new TOPK().topK(nums, 3);System.out.println(Arrays.toString(res));}
//輸出

對于這樣的問題需要先對原數(shù)組進行處理,比如在計算前3頻率這個問題上,我們需要先計算數(shù)組中數(shù)字出現(xiàn)的頻率,然后維護一個哈希表用來存儲元素的頻率。對于類似問題:微博熱搜的前10名,那么肯定需要統(tǒng)計搜索頻次,抖音小時榜前10名,那么肯定要統(tǒng)計要計算時段的觀看人數(shù),優(yōu)先隊列只不過是一個存儲K元素的一個容器,它不負責(zé)統(tǒng)計,只負責(zé)維護一個K元素的最大或者最小堆頂,對于數(shù)據(jù)采用什么樣的優(yōu)先級順序需要自定義。
如果用一句話來總結(jié)top-k問題:小頂堆用來求最大值,堆頂保存著最小值,判斷如果堆頂?shù)脑匦∮诖闅v數(shù)組的元素,把當(dāng)前元素poll出去,然后把待遍歷數(shù)組元素添加進去;大頂堆用來求最小值,堆頂保存著最大元素,如果堆頂元素大于待遍歷數(shù)組的值,就把當(dāng)前元素poll出去,把待遍歷數(shù)組的元素添加進去,這便是優(yōu)先級隊列的精髓。
三:總結(jié)
在實際中遇見的TOP-K問題有哪些,以及優(yōu)先級隊列PriorityQueue的基本原理介紹,接著由易到難的講解了如何通過優(yōu)先級隊列PriorityQueue來解決TOP-k問題,這兩個問題都比較經(jīng)典。對于理解優(yōu)先級隊列的含義、以及為什么它能解決該問題,想明白這點很重要。希望大家能夠做到舉一反三,下次面對同等問題的時候,能順序解決。起碼棘手的topk問題對于我們來說,有個PriorityQueue這個神兵利器,就顯得很簡單。