
Flink 特性 | Flink 1.14 新特性預(yù)覽
簡(jiǎn)介 流批一體 Checkpoint 機(jī)制 性能與效率 Table / SQL / Python API 總結(jié)
 GitHub 地址
GitHub 地址 此文章為 8 月 7 日的分享整理,1.14 版本最新進(jìn)展請(qǐng)注意文中的注釋說(shuō)明。
一、簡(jiǎn)介
1.14 新版本原本規(guī)劃有 35 個(gè)比較重要的新特性以及優(yōu)化工作,目前已經(jīng)有 26 個(gè)工作完成;5 個(gè)任務(wù)不確定是否能準(zhǔn)時(shí)完成;另外 4 個(gè)特性由于時(shí)間或者本身設(shè)計(jì)上的原因,會(huì)放到后續(xù)版本完成。[1]

Wiki:https://cwiki.apache.org/confluence/display/FLINK/1.14+Release
Jira:https://issues.apache.org/jira/projects/FLINK/versions/12349614
[1] 截至到 8 月 31 日,確定進(jìn)入新版本的是 33 個(gè),已全部完成。
二、流批一體
需要維護(hù)兩套系統(tǒng),相應(yīng)的就需要兩組開(kāi)發(fā)人員,人力的投入成本很高;
另外,兩套數(shù)據(jù)鏈路處理相似內(nèi)容帶來(lái)維護(hù)的風(fēng)險(xiǎn)性和冗余;
最重要的一點(diǎn)是,如果流批使用的不是同一套數(shù)據(jù)處理系統(tǒng),引擎本身差異可能會(huì)存在數(shù)據(jù)口徑不一致的問(wèn)題,從而導(dǎo)致業(yè)務(wù)數(shù)據(jù)存在一定的誤差。這種誤差對(duì)于大數(shù)據(jù)分析會(huì)有比較大的影響。
對(duì)于無(wú)限的數(shù)據(jù)流,統(tǒng)一采用了流的執(zhí)行模式。流的執(zhí)行模式指的是所有計(jì)算節(jié)點(diǎn)是通過(guò) Pipeline 模式去連接的,Pipeline 是指上游和下游計(jì)算任務(wù)是同時(shí)運(yùn)行的,隨著上游不斷產(chǎn)出數(shù)據(jù),下游同時(shí)在不斷消費(fèi)數(shù)據(jù)。這種全 Pipeline 的執(zhí)行方式可以:
通過(guò) eventTime 表示數(shù)據(jù)是什么時(shí)候產(chǎn)生的;
通過(guò) watermark 得知在哪個(gè)時(shí)間點(diǎn),數(shù)據(jù)已經(jīng)到達(dá)了;
通過(guò) state 來(lái)維護(hù)計(jì)算中間狀態(tài);
通過(guò) Checkpoint 做容錯(cuò)的處理。
下圖是不同的執(zhí)行模式:
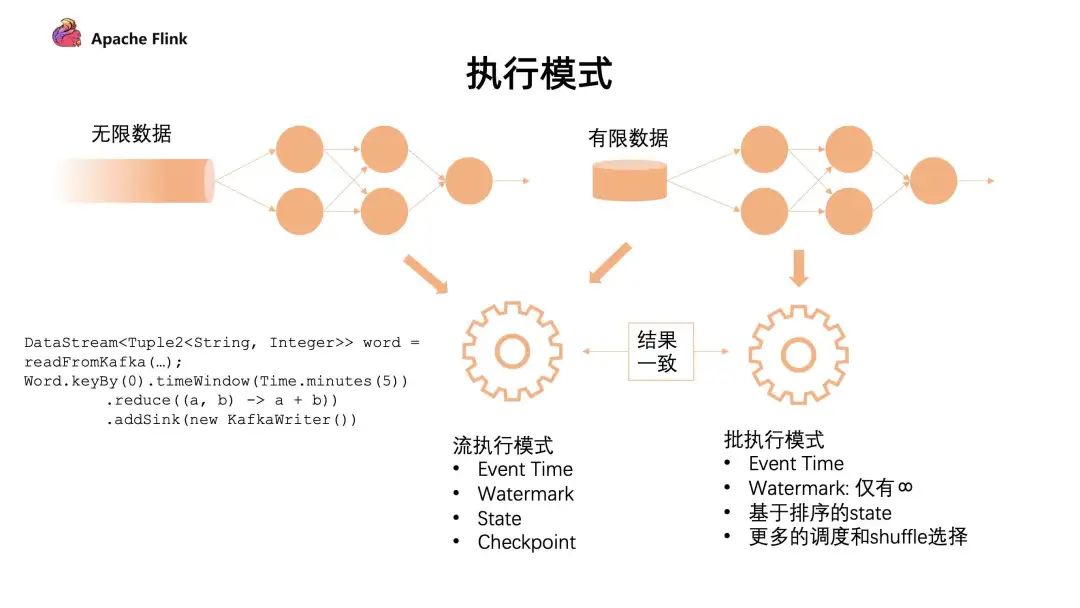
對(duì)于有限的數(shù)據(jù)集有 2 種執(zhí)行模式,我們可以把它看成一個(gè)有限的數(shù)據(jù)流去做處理,也可以把它看成批的執(zhí)行模式。批的執(zhí)行模式雖然也有 eventTime,但是對(duì)于 watermark 來(lái)說(shuō)只支持正無(wú)窮。對(duì)數(shù)據(jù)和 state 排序后,它在任務(wù)的調(diào)度和 shuffle 上會(huì)有更多的選擇。
流批的執(zhí)行模式是有區(qū)別的,最主要的就是批的執(zhí)行模式會(huì)有落盤(pán)的中間過(guò)程,只有當(dāng)前面任務(wù)執(zhí)行完成,下游的任務(wù)才會(huì)觸發(fā),這個(gè)容錯(cuò)機(jī)制是通過(guò) shuffle 進(jìn)行容錯(cuò)的。
這 2 者也各有各的執(zhí)行優(yōu)勢(shì):
對(duì)于流的執(zhí)行模式來(lái)說(shuō),它沒(méi)有落盤(pán)的壓力,同時(shí)容錯(cuò)是基于數(shù)據(jù)的分段,通過(guò)不斷對(duì)數(shù)據(jù)進(jìn)行打點(diǎn) Checkpoint 去保證斷點(diǎn)恢復(fù);
然而在批處理上,因?yàn)橐?jīng)過(guò) shuffle 落盤(pán),所以對(duì)磁盤(pán)會(huì)有壓力。但是因?yàn)閿?shù)據(jù)是經(jīng)過(guò)排序的,所以對(duì)于批來(lái)說(shuō),后續(xù)的計(jì)算效率可能會(huì)有一定的提升。同時(shí),在執(zhí)行時(shí)候是經(jīng)過(guò)分段去執(zhí)行任務(wù)的,無(wú)需同時(shí)執(zhí)行;在容錯(cuò)計(jì)算方面是根據(jù) stage 進(jìn)行容錯(cuò)。
這兩種各有優(yōu)劣,可以根據(jù)作業(yè)的具體場(chǎng)景來(lái)進(jìn)行選擇。
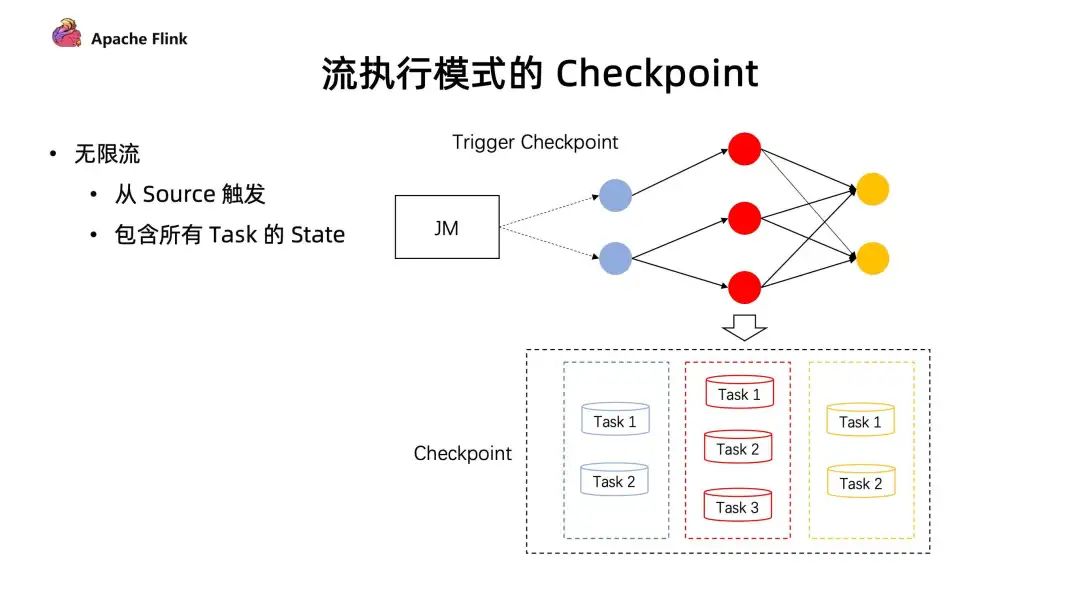
■ 在流的執(zhí)行模式下的 Checkpoint 機(jī)制
對(duì)于無(wú)限流,它的 Checkpoint 是由所有的 source 節(jié)點(diǎn)進(jìn)行觸發(fā)的,由 source 節(jié)點(diǎn)發(fā)送 Checkpoint Barrier ,當(dāng) Checkpoint Barrier 流過(guò)整個(gè)作業(yè)時(shí)候,同時(shí)會(huì)存儲(chǔ)當(dāng)前作業(yè)所有的 state 狀態(tài)。
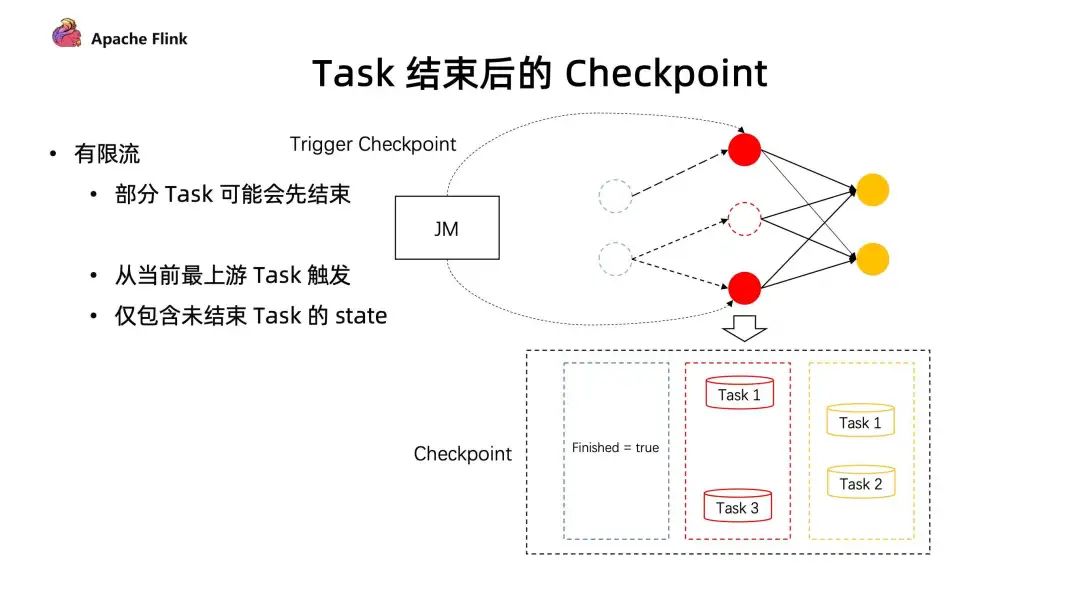
而在有限流的 Checkpoint 機(jī)制中,Task 是有可能提早結(jié)束的。上游的 Task 有可能先處理完任務(wù)提早退出了,但下游的 Task 卻還在執(zhí)行中。在同一個(gè) stage 不同并發(fā)下,有可能因?yàn)閿?shù)據(jù)量不一致導(dǎo)致部分任務(wù)提早完成了。這種情況下,在后續(xù)的執(zhí)行作業(yè)中,如何進(jìn)行 Checkpoint?
在 1.14 中,JobManager 動(dòng)態(tài)根據(jù)當(dāng)前任務(wù)的執(zhí)行情況,去明確 Checkpoint Barrier 是從哪里開(kāi)始觸發(fā)。同時(shí)在部分任務(wù)結(jié)束后,后續(xù)的 Checkpoint 只會(huì)保存仍在運(yùn)行 Task 所對(duì)應(yīng)的 stage,通過(guò)這種方式能夠讓任務(wù)執(zhí)行完成后,還可以繼續(xù)做 Checkpoint ,在有限流執(zhí)行中提供更好的容錯(cuò)保障。
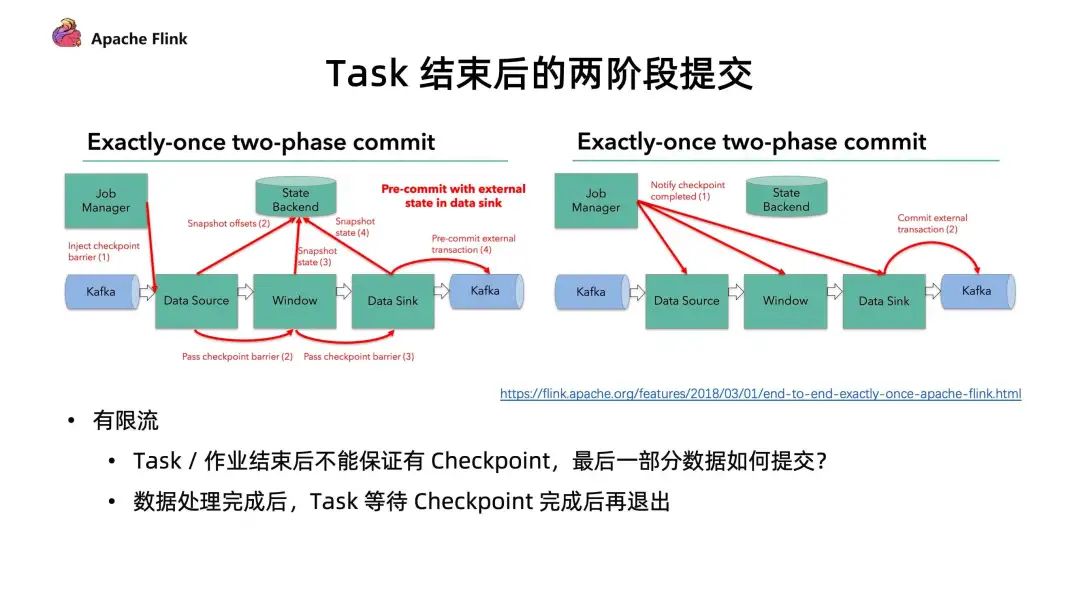
■ Task 結(jié)束后的兩階段提交
三、checkpoint 機(jī)制
1. 現(xiàn)有 Checkpoint 機(jī)制痛點(diǎn)
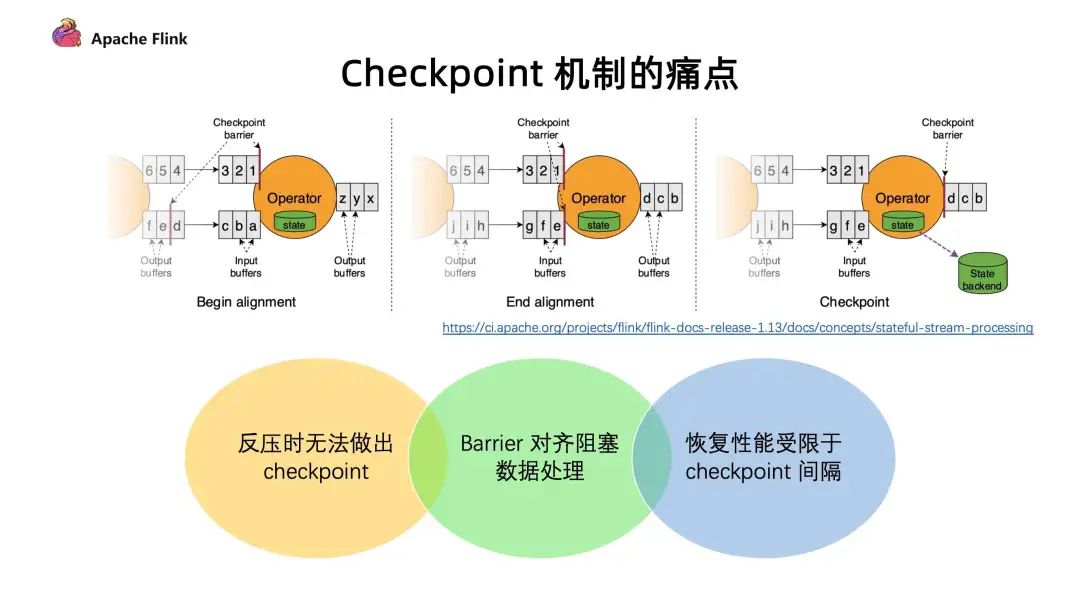
反壓時(shí)無(wú)法做出 Checkpoint :在反壓時(shí)候 barrier 無(wú)法隨著數(shù)據(jù)往下游流動(dòng),造成反壓的時(shí)候無(wú)法做出 Checkpoint。但是其實(shí)在發(fā)生反壓情況的時(shí)候,我們更加需要去做出對(duì)數(shù)據(jù)的 Checkpoint,因?yàn)檫@個(gè)時(shí)候性能遇到了瓶頸,是更加容易出問(wèn)題的階段;
Barrier 對(duì)齊阻塞數(shù)據(jù)處理 :阻塞對(duì)齊對(duì)于性能上存在一定的影響;
恢復(fù)性能受限于 Checkpoint 間隔 :在做恢復(fù)的時(shí)候,延遲受到多大的影響很多時(shí)候是取決于 Checkpoint 的間隔,間隔越大,需要 replay 的數(shù)據(jù)就會(huì)越多,從而造成中斷的影響也就會(huì)越大。但是目前 Checkpoint 間隔受制于持久化操作的時(shí)間,所以沒(méi)辦法做的很快。
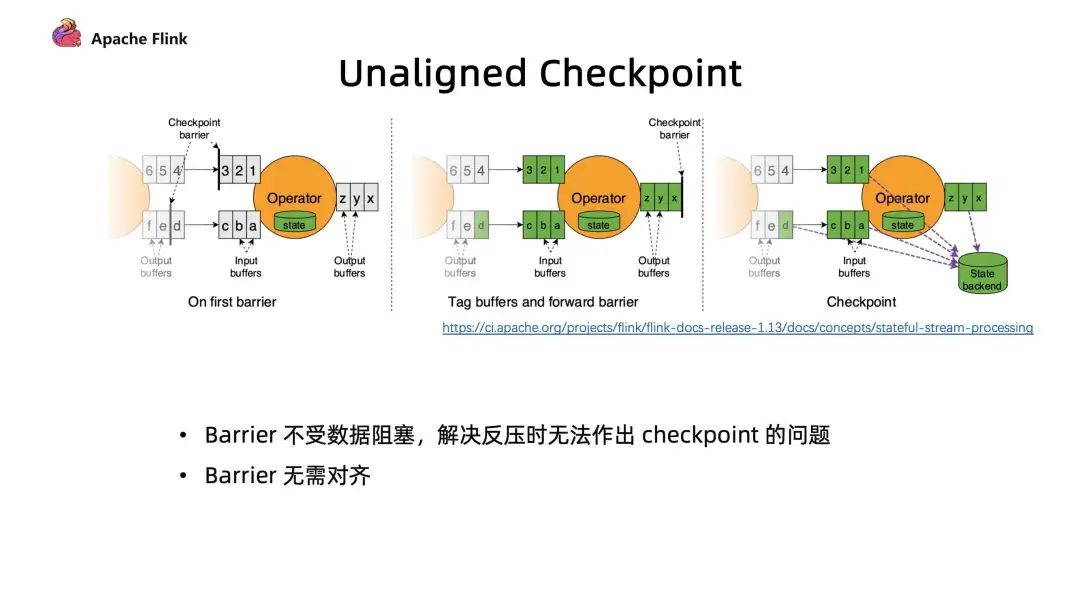
2. Unaligned Checkpoint
 3. Generalized Incremental Checkpoint [2]
3. Generalized Incremental Checkpoint [2]
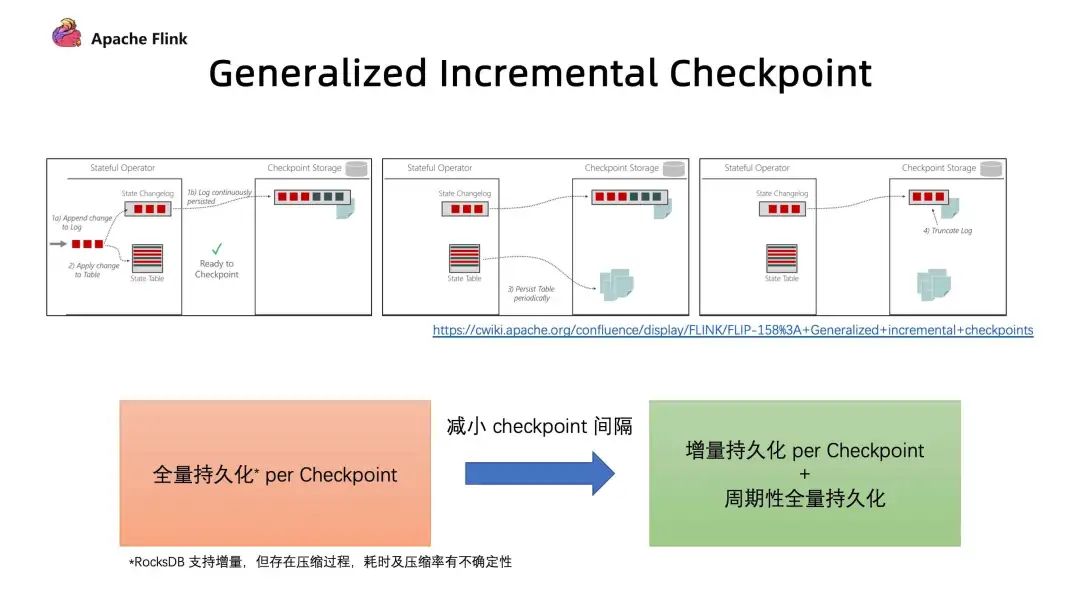
第一個(gè)問(wèn)題是 RocksDB 的 Incremental Checkpoint 是依賴(lài)它自己本身的一些實(shí)現(xiàn),當(dāng)中會(huì)存在一些數(shù)據(jù)壓縮,壓縮所消耗的時(shí)間以及壓縮效果具有不確定性,這個(gè)是和數(shù)據(jù)是相關(guān)的;
第二個(gè)問(wèn)題是只能針對(duì)特定的 StateBackend 來(lái)使用,目前在做的 Generalized Incremental Checkpoint 實(shí)際上能夠保證的是,它與 StateBackend 是無(wú)關(guān)的,從運(yùn)行時(shí)的機(jī)制來(lái)保證了一個(gè)比較穩(wěn)定、更小的 Checkpoint 間隔。
[2] Generalized Incremental Checkpoint 最終在 1.14 中沒(méi)有完成。
四、性能與效率
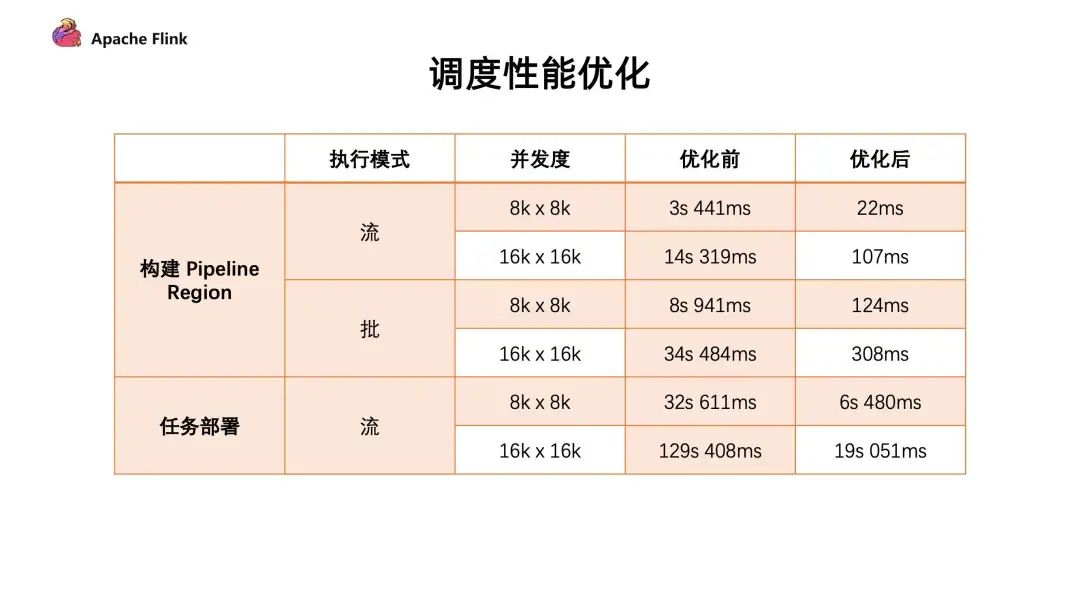
1. 大規(guī)模作業(yè)調(diào)度的優(yōu)化
構(gòu)建 Pipeline Region 的性能提升:所有由 pipline 邊所連接構(gòu)成的子圖 。在 Flink 任務(wù)調(diào)度中需要通過(guò)識(shí)別 Pipeline Region 來(lái)保證由同一個(gè) Pipline 邊所連接的任務(wù)能夠同時(shí)進(jìn)行調(diào)度。否則有可能上游的任務(wù)開(kāi)始調(diào)度,但是下游的任務(wù)并沒(méi)有運(yùn)行。從而導(dǎo)致上游運(yùn)行完的數(shù)據(jù)無(wú)法給下游的節(jié)點(diǎn)進(jìn)行消費(fèi),可能會(huì)造成死鎖的情況
任務(wù)部署階段:每個(gè)任務(wù)都要從哪些上游讀取數(shù)據(jù),這些信息會(huì)生成 Result Partition Deployment Descriptor。
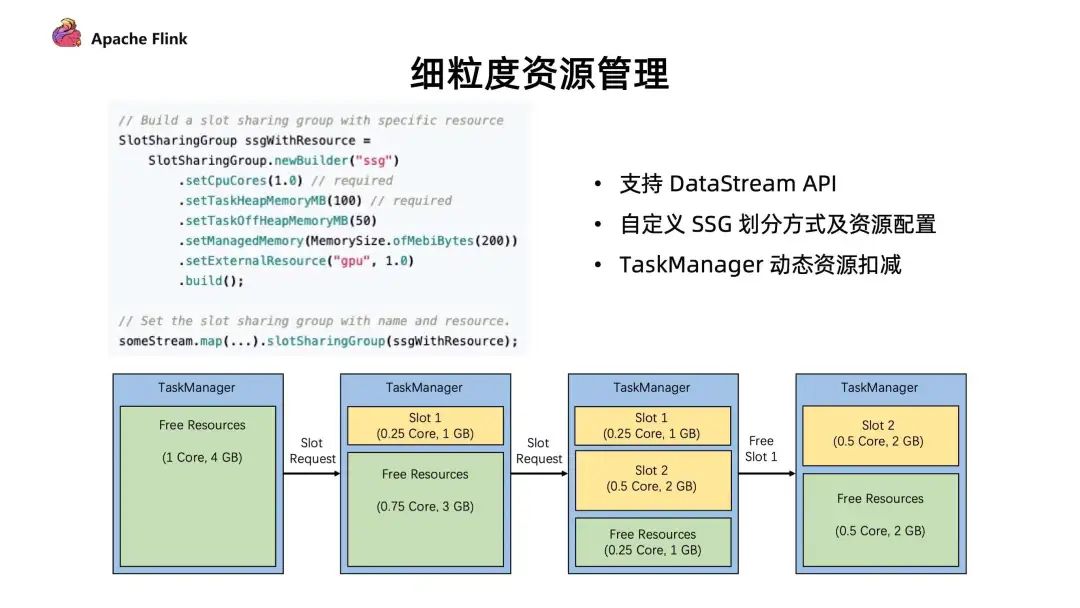
2. 細(xì)粒度資源管理
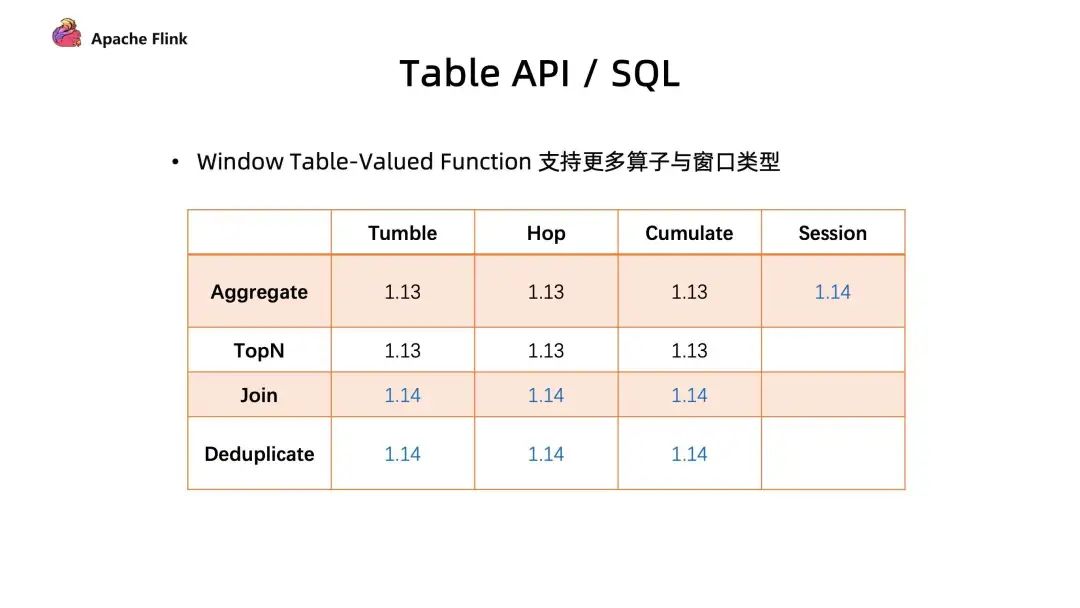
五、Table / SQL / Python API
■ 1.1 支持聲明式注冊(cè) Source/Sink
Table API 支持使用聲明式的方式注冊(cè) Source / Sink 功能對(duì)齊 SQL DDL;
同時(shí)支持 FLIP-27 新的 Source 接口;
new Source 替代舊的 connect() 接口。

■ 1.2 全新代碼生成器
■ 1.3 移除 Flink Planner
2. Python API
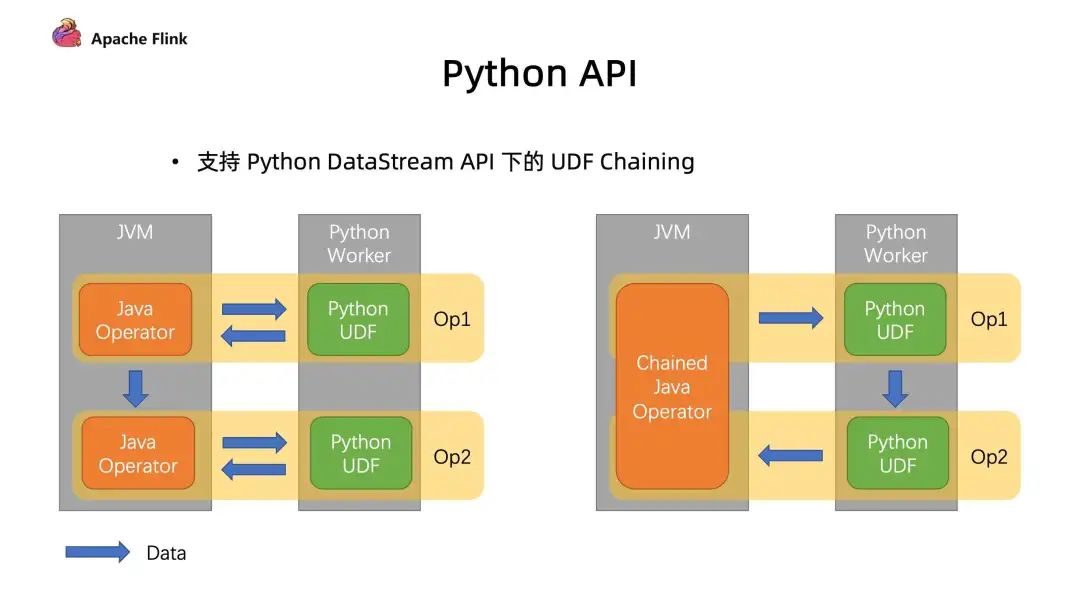
3. 支持 LoopBack 模式
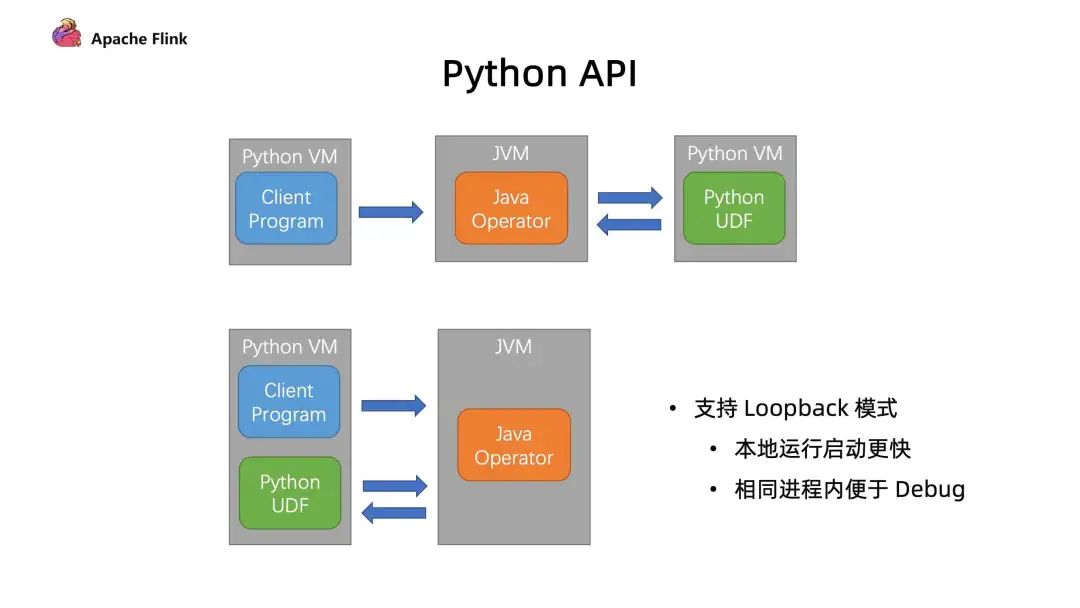
首先是避免了啟動(dòng)額外進(jìn)程所帶來(lái)的開(kāi)銷(xiāo);
最重要的是在本地調(diào)試中,我們可以在同一個(gè)進(jìn)程內(nèi)能夠更好利用一些工具進(jìn)行 debug,這個(gè)是對(duì)開(kāi)發(fā)者體驗(yàn)上的一個(gè)提升。
六、總結(jié)
首先介紹了目前社區(qū)在批流一體上的工作,通過(guò)介紹批流不同的執(zhí)行模式和 JM 節(jié)點(diǎn)任務(wù)觸發(fā)的優(yōu)化改進(jìn)更好的去兼容批作業(yè);
然后通過(guò)分析現(xiàn)有的 Checkpoint 機(jī)制痛點(diǎn),在新版本中如何改進(jìn),以及在大規(guī)模作業(yè)調(diào)度優(yōu)化和細(xì)粒度的資源管理上面如何做到對(duì)性能優(yōu)化;
最后介紹了 TableSQL API 和 Pyhton上相關(guān)的性能優(yōu)化。
第三屆 Apache Flink 極客挑戰(zhàn)賽 伴隨著海量數(shù)據(jù)的沖擊,數(shù)據(jù)處理分析能力在業(yè)務(wù)中的價(jià)值與日俱增,各行各業(yè)對(duì)于數(shù)據(jù)處理時(shí)效性的探索也在不斷深入,作為主打?qū)崟r(shí)計(jì)算的計(jì)算引擎 - Apache Flink 應(yīng)運(yùn)而生。
為給行業(yè)帶來(lái)更多實(shí)時(shí)計(jì)算賦能實(shí)踐的思路,鼓勵(lì)廣大熱愛(ài)技術(shù)的開(kāi)發(fā)者加深對(duì) Flink 的掌握,Apache Flink 社區(qū)聯(lián)手阿里云、英特爾、阿里巴巴人工智能治理與可持續(xù)發(fā)展實(shí)驗(yàn)室 (AAIG)、Occlum 聯(lián)合舉辦 "第三屆 Apache Flink 極客挑戰(zhàn)賽暨 AAIG CUP" 活動(dòng),即日起正式啟動(dòng)。
▼ 掃描圖中二維碼,了解更多賽事信息 ▼

 戳我,回顧作者分享視頻!
戳我,回顧作者分享視頻!