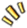分布式事務(wù)之底層原理揭秘
點(diǎn)擊上方“服務(wù)端思維”,選擇“設(shè)為星標(biāo)”
回復(fù)”669“獲取獨(dú)家整理的精選資料集
回復(fù)”加群“加入全國(guó)服務(wù)端高端社群「后端圈」

剛性事務(wù)
柔性事務(wù)
本地事務(wù)
分布式事務(wù)
單階段原子提交協(xié)議
兩階段提交協(xié)議
定義
原理
性能
恢復(fù)
缺陷
XA 標(biāo)準(zhǔn)接口
三階段提交協(xié)議
Paxos
Basic Paxos
Multi-Paxos
Raft
算法類(lèi)型
鎖并發(fā)控制
時(shí)間戳并發(fā)控制
樂(lè)觀并發(fā)控制
導(dǎo)言
分布式事務(wù)是分布式系統(tǒng)必不可少的組成部分,基本上只要實(shí)現(xiàn)一個(gè)分布式系統(tǒng)就逃不開(kāi)對(duì)分布式事務(wù)的支持。本文從分布式事務(wù)這個(gè)概念切入,嘗試對(duì)分布式事務(wù)以及分布式系統(tǒng)最核心的底層原理逐一進(jìn)行剖析,內(nèi)容包括但不限于 BASE 原則、兩階段原子提交協(xié)議、三階段原子提交協(xié)議、Paxos/Multi-Paxos 分布式共識(shí)算法的原理與證明、Raft 分布式共識(shí)算法和分布式事務(wù)的并發(fā)控制等內(nèi)容。
事務(wù)
事務(wù)是訪問(wèn)并可能更新各種數(shù)據(jù)項(xiàng)的一個(gè)程序執(zhí)行單元(unit)。事務(wù)由一個(gè)或多個(gè)步驟組成,一般使用形如 begin transaction 和 end transaction 語(yǔ)句或者函數(shù)調(diào)用作為事務(wù)界限,事務(wù)內(nèi)的所有步驟必須作為一個(gè)單一的、不可分割的單元去執(zhí)行,因此事務(wù)的結(jié)果只有兩種:1. 全部步驟都執(zhí)行完成,2. 任一步驟執(zhí)行失敗則整個(gè)事務(wù)回滾。
事務(wù)最早由數(shù)據(jù)庫(kù)管理系統(tǒng)(database management system,DBMS)引入并實(shí)現(xiàn),數(shù)據(jù)庫(kù)事務(wù)是數(shù)據(jù)庫(kù)管理系統(tǒng)執(zhí)行過(guò)程中的一個(gè)邏輯單位,由一個(gè)有限的數(shù)據(jù)庫(kù)操作序列構(gòu)成。數(shù)據(jù)庫(kù)事務(wù)嚴(yán)格遵循 ACID 原則,屬于剛性事務(wù),一開(kāi)始數(shù)據(jù)庫(kù)事務(wù)僅限于對(duì)單一數(shù)據(jù)庫(kù)資源對(duì)象的訪問(wèn)控制,這一類(lèi)事務(wù)稱(chēng)之為本地事務(wù) (Local Transaction),后來(lái)隨著分布式系統(tǒng)的出現(xiàn),數(shù)據(jù)的存儲(chǔ)也不可避免地走向了分布式,分布式事務(wù)(Distributed Transaction)便應(yīng)運(yùn)而生。
剛性事務(wù)
剛性事務(wù)(如單一數(shù)據(jù)庫(kù)事務(wù))完全遵循 ACID 規(guī)范,即數(shù)據(jù)庫(kù)事務(wù)的四大基本特性:
Atomicity(原子性):一個(gè)事務(wù)(transaction)中的所有操作,或者全部完成,或者全部不完成,不會(huì)結(jié)束在中間某個(gè)環(huán)節(jié)。事務(wù)在執(zhí)行過(guò)程中發(fā)生錯(cuò)誤,會(huì)被回滾(Rollback)到事務(wù)開(kāi)始前的狀態(tài),就像這個(gè)事務(wù)從來(lái)沒(méi)有執(zhí)行過(guò)一樣。即,事務(wù)不可分割、不可約簡(jiǎn)。 Consistency(一致性):在事務(wù)開(kāi)始之前和事務(wù)結(jié)束以后,數(shù)據(jù)庫(kù)的完整性沒(méi)有被破壞。這表示寫(xiě)入的資料必須完全符合所有的預(yù)設(shè)約束、觸發(fā)器、級(jí)聯(lián)回滾等。 Isolation(隔離性):數(shù)據(jù)庫(kù)允許多個(gè)并發(fā)事務(wù)同時(shí)對(duì)其數(shù)據(jù)進(jìn)行讀寫(xiě)和修改的能力,隔離性可以防止多個(gè)事務(wù)并發(fā)執(zhí)行時(shí)由于交叉執(zhí)行而導(dǎo)致數(shù)據(jù)的不一致。事務(wù)隔離分為不同級(jí)別,包括未提交讀(Read uncommitted)、提交讀(read committed)、可重復(fù)讀(repeatable read)和串行化(Serializable)。 Durability(持久性):事務(wù)處理結(jié)束后,對(duì)數(shù)據(jù)的修改就是永久的,即便系統(tǒng)故障也不會(huì)丟失。
剛性事務(wù)也能夠以分布式 CAP 理論中的 CP 事務(wù)來(lái)作為定義。
柔性事務(wù)
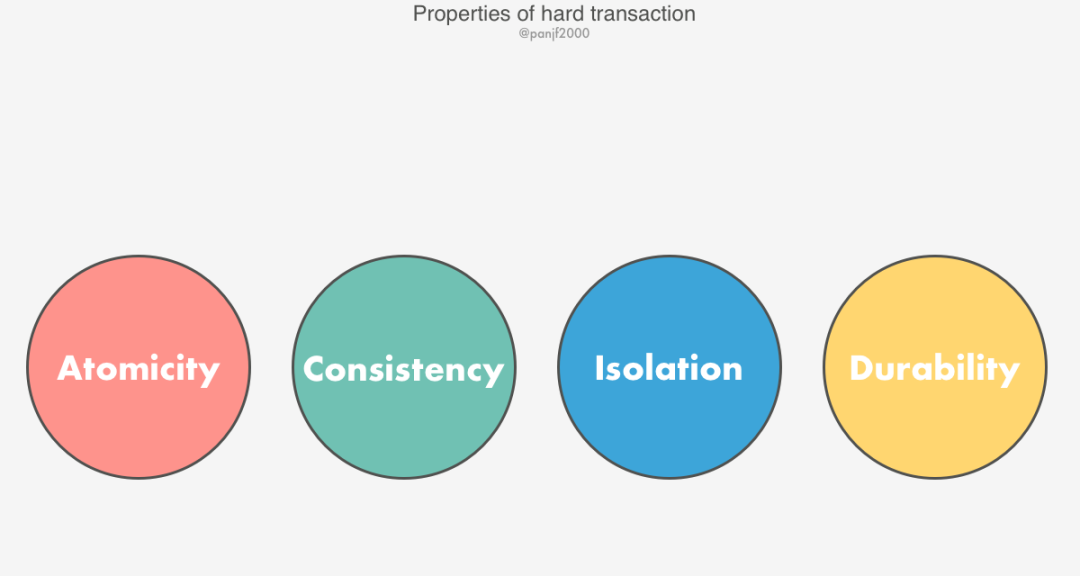
在電商領(lǐng)域等互聯(lián)網(wǎng)場(chǎng)景下,傳統(tǒng)的事務(wù)在數(shù)據(jù)庫(kù)性能和處理能力上都遇到了瓶頸。因此,柔性事務(wù)被提了出來(lái),柔性事務(wù)基于分布式 CAP 理論以及延伸出來(lái)的 BASE 理論,相較于數(shù)據(jù)庫(kù)事務(wù)這一類(lèi)完全遵循 ACID 的剛性事務(wù)來(lái)說(shuō),柔性事務(wù)保證的是 “基本可用,最終一致”,CAP 原理相信大家都很熟悉了,這里我們講一下 BASE 原則:
基本可用(Basically Available):系統(tǒng)能夠基本運(yùn)行、一直提供服務(wù)。 軟狀態(tài)(Soft-state):系統(tǒng)不要求一直保持強(qiáng)一致?tīng)顟B(tài)。 最終一致性(Eventual consistency):系統(tǒng)需要在某一時(shí)刻后達(dá)到一致性要求。
柔性事務(wù)(如分布式事務(wù))為了滿足可用性、性能與降級(jí)服務(wù)的需要,降低一致性(Consistency)與隔離性(Isolation)的要求,遵循 BASE 理論,傳統(tǒng)的 ACID 事務(wù)對(duì)隔離性的要求非常高,在事務(wù)執(zhí)行過(guò)程中,必須將所有的資源對(duì)象鎖定,因此對(duì)并發(fā)事務(wù)的執(zhí)行極度不友好,柔性事務(wù)(比如分布式事務(wù))的理念則是將鎖資源對(duì)象操作從本地資源對(duì)象層面上移至業(yè)務(wù)邏輯層面,再通過(guò)放寬對(duì)強(qiáng)一致性要求,以換取系統(tǒng)吞吐量的提升。
此外,雖然柔性事務(wù)遵循的是 BASE 理論,但是還需要遵循部分 ACID 規(guī)范:
原子性:嚴(yán)格遵循。 一致性:事務(wù)完成后的一致性嚴(yán)格遵循;事務(wù)中的一致性可適當(dāng)放寬。 隔離性:并行事務(wù)間不可影響;事務(wù)中間結(jié)果可見(jiàn)性允許安全放寬。 持久性:嚴(yán)格遵循。
本地事務(wù)
本地事務(wù)(Local Transaction)指的是僅僅對(duì)單一節(jié)點(diǎn)/數(shù)據(jù)庫(kù)資源對(duì)象進(jìn)行訪問(wèn)/更新的事務(wù),在這種事務(wù)模式下,BASE 理論派不上用場(chǎng),事務(wù)完全遵循 ACID 規(guī)范,確保事務(wù)為剛性事務(wù)。
分布式事務(wù)
在分布式架構(gòu)成為主流的當(dāng)下,系統(tǒng)對(duì)資源對(duì)象的訪問(wèn)不能還局限于單節(jié)點(diǎn),多服務(wù)器、多節(jié)點(diǎn)的資源對(duì)象訪問(wèn)成為剛需,因此,本地事務(wù)無(wú)法滿足分布式架構(gòu)的系統(tǒng)的要求,分布式事務(wù)應(yīng)運(yùn)而生。
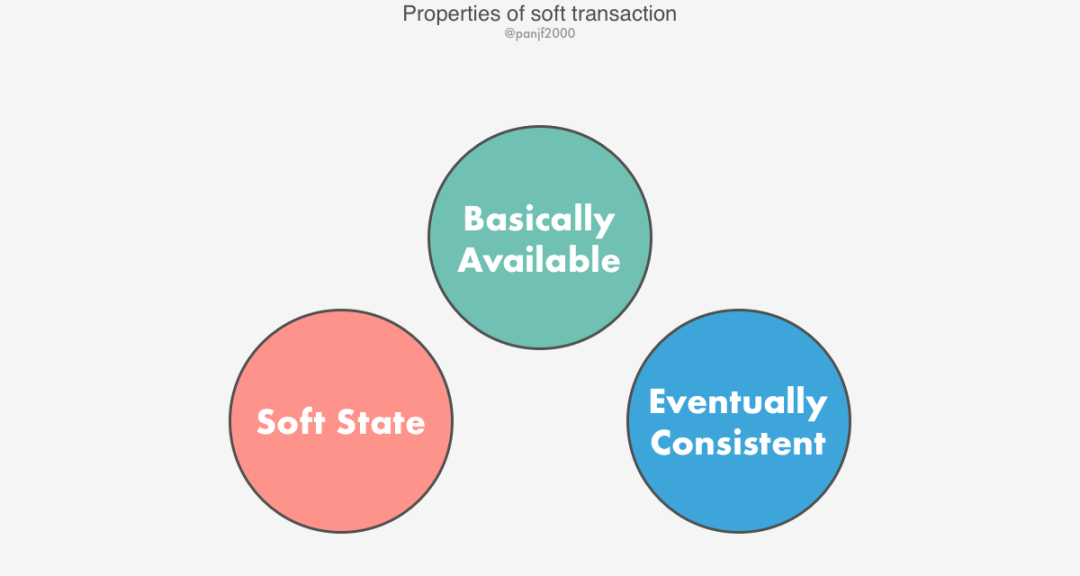
訪問(wèn)/更新由多個(gè)服務(wù)器管理的資源對(duì)象的平面事務(wù)或者嵌套事務(wù)稱(chēng)之為分布式事務(wù)(Distributed Transaction),分布式事務(wù)是相對(duì)于本地事務(wù)來(lái)說(shuō)的。
平面事務(wù):?jiǎn)我皇聞?wù),訪問(wèn)多個(gè)服務(wù)器節(jié)點(diǎn)的資源對(duì)象,一個(gè)平面事務(wù)完成一次請(qǐng)求之后才能發(fā)起下一個(gè)請(qǐng)求。
嵌套事務(wù):多事務(wù)組成,頂層事務(wù)可以不斷創(chuàng)建子事務(wù),子事務(wù)又可以進(jìn)一步地以任意深度嵌套子事務(wù)。
對(duì)于分布式事務(wù)來(lái)說(shuō),有兩個(gè)最核心的問(wèn)題:
如何管理分布式事務(wù)的提交/放棄決定?如果事務(wù)中的一個(gè)節(jié)點(diǎn)在執(zhí)行自己的本地事務(wù)過(guò)程中遇到錯(cuò)誤,希望放棄整個(gè)分布式事務(wù),與此同時(shí)其他節(jié)點(diǎn)則在事務(wù)執(zhí)行過(guò)程中一切順利,希望提交這個(gè)分布式事務(wù),此時(shí)我們應(yīng)該如何做決策? 如何保證并發(fā)事務(wù)在涉及多個(gè)節(jié)點(diǎn)上資源對(duì)象訪問(wèn)的可串行性(規(guī)避分布式死鎖)?如果事務(wù) T 對(duì)某一個(gè)服務(wù)器節(jié)點(diǎn)上的資源對(duì)象 S 的并發(fā)訪問(wèn)在事務(wù) U 之前,那么我們需要保證在所有服務(wù)器節(jié)點(diǎn)上對(duì) S 和其他資源對(duì)象的沖突訪問(wèn),T 始終在 U 之前。
問(wèn)題 1 的解決需要引入一類(lèi)分布式原子提交協(xié)議的算法如兩階段提交協(xié)議等,來(lái)對(duì)分布式事務(wù)過(guò)程中的提交或放棄決策進(jìn)行管理,并確保分布式提交的原子性。而問(wèn)題 2 則由分布式事務(wù)的并發(fā)控制機(jī)制來(lái)處理。
原子提交協(xié)議
原子性是分布式事務(wù)的前置性約束,沒(méi)有原子性則分布式事務(wù)毫無(wú)意義。
原子性約束要求在分布式事務(wù)結(jié)束之時(shí),它的所有操作要么全部執(zhí)行,要么全部不執(zhí)行。以分布式事務(wù)的原子性來(lái)分析,客戶端請(qǐng)求訪問(wèn)/更新多個(gè)服務(wù)器節(jié)點(diǎn)上的資源對(duì)象,在客戶端提交或放棄該事務(wù)從而結(jié)束事務(wù)之后,多個(gè)服務(wù)器節(jié)點(diǎn)的最終狀態(tài)要么是該事務(wù)里的所有步驟都執(zhí)行成功之后的狀態(tài),要么恢復(fù)到事務(wù)開(kāi)始前的狀態(tài),不存在中間狀態(tài)。滿足這種約束的分布式事務(wù)協(xié)議則稱(chēng)之為原子提交協(xié)議。
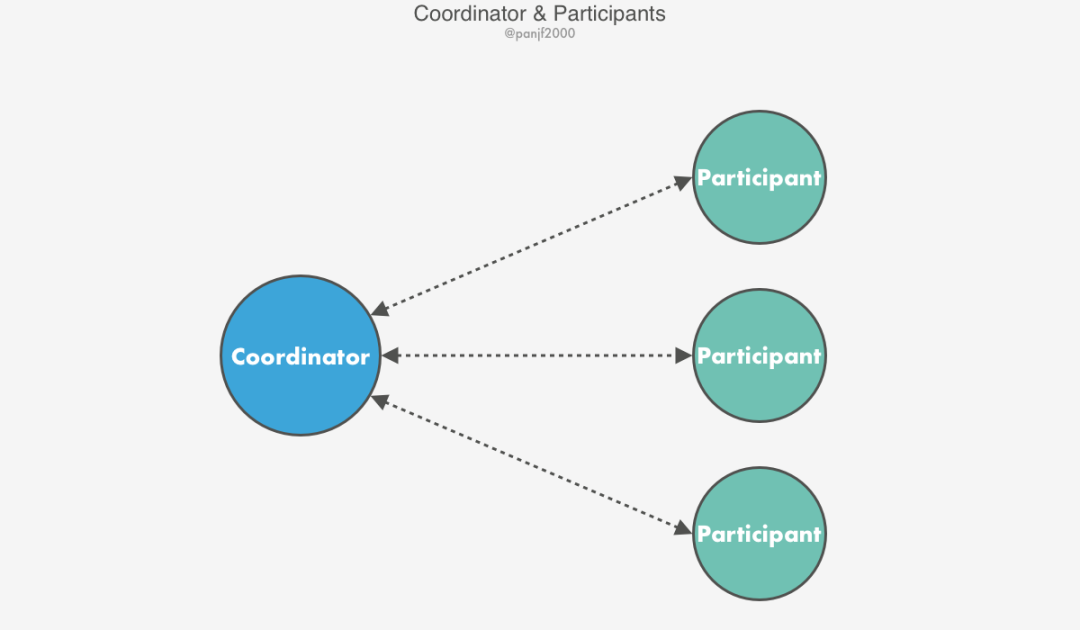
當(dāng)一個(gè)分布式事務(wù)結(jié)束時(shí),事務(wù)的原子特性要求所有參與該事務(wù)的服務(wù)器節(jié)點(diǎn)必須全部提交或者全部放棄該事務(wù),為了實(shí)現(xiàn)這一點(diǎn),必須引入一個(gè)協(xié)調(diào)者(Coordinator)的角色,從參與事務(wù)的所有服務(wù)器節(jié)點(diǎn)中挑選一個(gè)作為協(xié)調(diào)者,由它來(lái)保證在所有服務(wù)器節(jié)點(diǎn)上最終獲得同樣的結(jié)果。協(xié)調(diào)者的工作原理取決于分布式事務(wù)選用的協(xié)議。
一般來(lái)說(shuō),分布式事務(wù)中包含的兩個(gè)最基礎(chǔ)的角色就是:
Coordinator -- 協(xié)調(diào)者 Participants -- 參與者
單階段原子提交協(xié)議
單階段原子提交協(xié)議(one-phase atomic commit protocol, 1APC)是最簡(jiǎn)單的一種原子提交協(xié)議,它通過(guò)設(shè)置一個(gè)協(xié)調(diào)者并讓它不斷地向所有參與者發(fā)送提交(commit)或放棄(abort)事務(wù)的請(qǐng)求,直到所有參與者確認(rèn)已執(zhí)行完相應(yīng)的操作。
1APC 協(xié)議的優(yōu)點(diǎn)是簡(jiǎn)單易用,對(duì)一些事務(wù)不復(fù)雜的場(chǎng)景比較合適,但在復(fù)雜事務(wù)場(chǎng)景則顯得捉襟見(jiàn)肘,因?yàn)樵搮f(xié)議不允許任何服務(wù)器節(jié)點(diǎn)單方面放棄事務(wù),事務(wù)的放棄必須由協(xié)調(diào)者來(lái)發(fā)起,這個(gè)設(shè)計(jì)會(huì)導(dǎo)致很多問(wèn)題:首先因?yàn)橹挥幸淮瓮ㄐ牛瑓f(xié)調(diào)者并不會(huì)收集所有參與者的本地事務(wù)執(zhí)行的情況,所以協(xié)調(diào)者決定提交還是放棄事務(wù)只基于自己的判斷,在參與者執(zhí)行事務(wù)期間可能會(huì)遇到錯(cuò)誤從而導(dǎo)致最終事務(wù)未能真正提交,錯(cuò)誤一般與事務(wù)的并發(fā)控制有關(guān),比如事務(wù)執(zhí)行期間對(duì)資源對(duì)象加鎖,遇到死鎖,需要放棄事務(wù)從而解開(kāi)死鎖,而協(xié)調(diào)者并不知道,因此在發(fā)起下一個(gè)請(qǐng)求之前,客戶端完全不知道事務(wù)已被放棄。另一種情況就是利用樂(lè)觀并發(fā)控制機(jī)制訪問(wèn)資源對(duì)象,某一個(gè)服務(wù)器節(jié)點(diǎn)的驗(yàn)證失敗將導(dǎo)致事務(wù)被放棄,而協(xié)調(diào)者完全不知情。
兩階段提交協(xié)議
定義
兩階段提交協(xié)議(two-phase commit protocol, 2PC)的設(shè)計(jì)初衷是為了解決 1APC 不允許任意一個(gè)服務(wù)器節(jié)點(diǎn)自行放棄它自己的那部分本地事務(wù)的痛點(diǎn),2PC 允許任何一個(gè)參與者自行決定要不要放棄它的本地事務(wù),而由于原子提交協(xié)議的約束,任意一個(gè)本地事務(wù)被放棄將導(dǎo)致整個(gè)分布式事務(wù)也必須放棄掉。
兩階段提交協(xié)議基于以下幾個(gè)假設(shè):
存在一個(gè)節(jié)點(diǎn)作為協(xié)調(diào)者(Coordinator),分布式事務(wù)通常由協(xié)調(diào)者發(fā)起(當(dāng)然也可以由參與者發(fā)起),其余節(jié)點(diǎn)作為參與者(Participants),且節(jié)點(diǎn)之間可以自由地進(jìn)行網(wǎng)絡(luò)通信,協(xié)調(diào)者負(fù)責(zé)啟動(dòng)兩階段提交流程以及決定事務(wù)最終是被提交還是放棄。 每個(gè)節(jié)點(diǎn)會(huì)記錄該節(jié)點(diǎn)上的本地操作日志(op logs),日志必須持久化在可靠的存儲(chǔ)設(shè)備上(比如磁盤(pán)),以便在節(jié)點(diǎn)重啟之后需要恢復(fù)操作日志。另外,不記錄全局操作日志。 所有節(jié)點(diǎn)不能發(fā)生永久性損壞,也就是說(shuō)節(jié)點(diǎn)就算是損壞了也必須能通過(guò)可靠性存儲(chǔ)恢復(fù)如初,不允許出現(xiàn)數(shù)據(jù)永久丟失的情況。 參與者對(duì)協(xié)調(diào)者的回復(fù)必須要去除掉那些受損和重復(fù)的消息。 整個(gè)集群不會(huì)出現(xiàn)拜占庭故障(Byzantine Fault)-- 服務(wù)器要么崩潰,要么服從其發(fā)送的消息。
原理
兩階段提交協(xié)議,顧名思義整個(gè)過(guò)程需要分為兩個(gè)階段:
準(zhǔn)備階段(Prepare Phase) 提交階段(Commit Phase)
在進(jìn)行兩階段提交的過(guò)程中,協(xié)調(diào)者會(huì)在以下四種狀態(tài)間流轉(zhuǎn):
initpreparingcommittedaborted
而參與者則會(huì)在以下三種狀態(tài)間流轉(zhuǎn):
workingpreparedcommitted
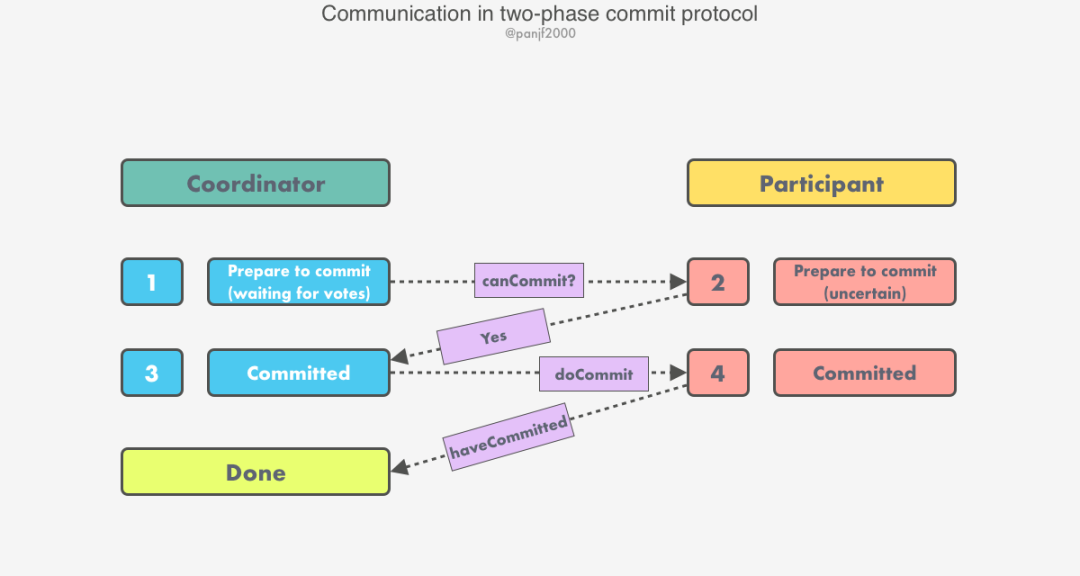
階段 I(投票表決階段)
任意一個(gè)參與者發(fā)起分布式事務(wù) T 并執(zhí)行本地事務(wù)成功,接著將一條 <ready T>記錄追加到本地日志 buffer 中并 flush 到可靠性存儲(chǔ)設(shè)備如磁盤(pán)上,從working狀態(tài)進(jìn)入prepared狀態(tài),然后向協(xié)調(diào)者發(fā)送prepare T消息;收到參與者發(fā)來(lái)的 prepare T消息后,協(xié)調(diào)者將一條<prepare T>記錄追加到日志中,然后從init狀態(tài)進(jìn)入preparing狀態(tài),緊接著向分布式事務(wù)的其他參與者發(fā)出canCommit?消息,發(fā)起事務(wù)表決過(guò)程;當(dāng)參與者收到 canCommit?請(qǐng)求后,除了發(fā)起事務(wù)的那一個(gè)之外,其他還在working狀態(tài)的參與者會(huì)先嘗試執(zhí)行本地事務(wù),如果本地事務(wù)執(zhí)行成功,則會(huì)往本地日志 buffer 寫(xiě)入一條<ready T>記錄并 flush 到可靠性存儲(chǔ)中,但不提交事務(wù),進(jìn)入prepared狀態(tài),然后回復(fù)一條ready T消息對(duì)此事務(wù)投 YES 票;如果本地事務(wù)執(zhí)行失敗,則參與者會(huì)往本地日志 buffer 寫(xiě)入一條<don't commit T>記錄并 flush 到可靠性存儲(chǔ)中,然后回復(fù)一條don't commit T消息投 NO 票。
階段 II(收集投票結(jié)果完成事務(wù))
協(xié)調(diào)者收集所有的投票(包括它自己的投票);
(a) 如果所有的投票都是
ready T,則表示沒(méi)有故障發(fā)生,那么協(xié)調(diào)者決定提交該事務(wù),首先它會(huì)在其本地日志中追加一條<commit T>記錄,從preparing狀態(tài)進(jìn)入committed狀態(tài),然后向所有的參與者發(fā)送doCommit請(qǐng)求消息,要求參與者提交它們的本地事務(wù);(b) 如果有任一個(gè)投票是 No,則協(xié)調(diào)者決定放棄掉該事務(wù),首先它會(huì)往本地日志中追加一條
記錄,從 preparing狀態(tài)進(jìn)入aborted狀態(tài),然后發(fā)送doAbort請(qǐng)求消息給所有的參與者,通知它們回滾各自的本地事務(wù)。投了 YES 票的參與者阻塞等待協(xié)調(diào)者給它發(fā)來(lái)
doCommit或doAbort消息,如果接收到的是doCommit消息則提交本地事務(wù)并在此過(guò)程中記錄日志<commit T>,然后進(jìn)入committed狀態(tài),最后回復(fù)一個(gè)haveCommitted的消息通知協(xié)調(diào)者本地事務(wù)已經(jīng)成功提交;反之,如果收到的是doAbort消息則回滾本地事務(wù)并寫(xiě)入日志<abort T>,然后進(jìn)入aborted狀態(tài)。
上面的過(guò)程是一種更通用的流程,即由任意的參與者發(fā)起一個(gè)分布式事務(wù),而在實(shí)踐中一般把分布式事務(wù)的發(fā)起交給協(xié)調(diào)者來(lái)做,減少事務(wù)發(fā)起者確認(rèn)該事務(wù)已被提交所需等待的網(wǎng)絡(luò)消息延遲:
性能
網(wǎng)絡(luò) I/O 開(kāi)銷(xiāo)
假設(shè)兩階段提交過(guò)程一切運(yùn)行正常,即協(xié)調(diào)者和參與者都不出現(xiàn)崩潰和重啟,網(wǎng)絡(luò)通信也都正常。那么假設(shè)有一個(gè)協(xié)調(diào)者和 N 個(gè)參與者,兩階段提交過(guò)程中將會(huì)發(fā)送如下的消息:
任意一個(gè)參與者從 working狀態(tài)進(jìn)入prepared狀態(tài)并發(fā)送Prepared消息給協(xié)調(diào)者,1 條消息。協(xié)調(diào)者收到消息后,向其他參與者發(fā)送 canCommit?請(qǐng)求消息,N - 1 條消息。收到 canCommit?消息的參與者各自回復(fù)協(xié)調(diào)者投票消息,N - 1 條消息。協(xié)調(diào)者統(tǒng)計(jì)投票情況之后,發(fā)送 doCommit消息給其他參與者,N 條消息。
所以,事務(wù)發(fā)起者在經(jīng)過(guò) 4 條網(wǎng)絡(luò)消息延遲之后確認(rèn)該分布式事務(wù)已被提交,而整個(gè)過(guò)程共計(jì)發(fā)送 3N - 1 條網(wǎng)絡(luò)消息(因?yàn)?haveCommitted 在 2PC 僅僅是用于最后通知協(xié)調(diào)者而已,屬于可有可無(wú)的一次網(wǎng)絡(luò)消息,2PC 在該消息缺省的情況下也能正常運(yùn)行,因此 haveCommitted 一般不計(jì)入網(wǎng)絡(luò)延遲成本中)。
前面我們提到,在實(shí)踐中一般是由協(xié)調(diào)者來(lái)發(fā)起事務(wù),如果考慮這種情況的話,事務(wù)發(fā)起者 -- 協(xié)調(diào)者在經(jīng)過(guò) 3 條網(wǎng)絡(luò)消息延遲之后確認(rèn)該分布式事務(wù)已經(jīng)被提交,而整個(gè)過(guò)程實(shí)際發(fā)送的網(wǎng)絡(luò)消息則變成 3N 條。
總而言之,兩階段提交協(xié)議的網(wǎng)絡(luò)通信開(kāi)銷(xiāo)和集群節(jié)點(diǎn)的數(shù)量成 3 倍正比。
本地存儲(chǔ)設(shè)備 I/O 開(kāi)銷(xiāo)
基于前文中敘述的兩階段提交協(xié)議的基本假設(shè)之一:每個(gè)節(jié)點(diǎn)會(huì)通過(guò)日志來(lái)記錄在本地執(zhí)行的操作,以便在節(jié)點(diǎn)發(fā)生故障并重啟節(jié)點(diǎn)之后能利用日志恢復(fù)到故障前的狀態(tài),因此兩階段提交過(guò)程中除了網(wǎng)絡(luò) I/O 的開(kāi)銷(xiāo)之外,還有本地存儲(chǔ)設(shè)備 I/O 的開(kāi)銷(xiāo):
發(fā)起事務(wù)的參與者執(zhí)行本地事務(wù),1 次寫(xiě)操作。 其余參與者執(zhí)行各自的本地事務(wù),N - 1 次寫(xiě)操作。 協(xié)調(diào)者統(tǒng)計(jì)投票結(jié)果并決定提交事務(wù),1 次寫(xiě)操作。
所以事務(wù)發(fā)起者在經(jīng)過(guò) 3 次本地存儲(chǔ)設(shè)備 I/O 延遲之后確認(rèn)該事務(wù)已被提交,整個(gè)過(guò)程總計(jì)有 N + 1 次本地存儲(chǔ)設(shè)備 I/O,而如果由協(xié)調(diào)者來(lái)發(fā)起事務(wù)的話,則還是需要 N + 1 次本地存儲(chǔ)設(shè)備 I/O,但是只需要經(jīng)過(guò) 2 次本地存儲(chǔ)設(shè)備 I/O 延遲即可確認(rèn)事務(wù)已被提交。
恢復(fù)
在分布式事務(wù)中,所有的參與者節(jié)點(diǎn)都可能發(fā)生故障,所以我們需要保證在該故障節(jié)點(diǎn)恢復(fù)時(shí)發(fā)生的一切都和分布式事務(wù) T 的全局決策保持一致。節(jié)點(diǎn)在恢復(fù)的時(shí)候會(huì)讀取 T 的最后一個(gè)本地日志記錄并作出相應(yīng)的操作:
如果 T 的最后一條日志記錄是 <commit T>,那么說(shuō)明協(xié)調(diào)者在節(jié)點(diǎn)發(fā)生故障時(shí)的全局決策是提交 T,根據(jù)本地事務(wù)所使用的日志方式,在該節(jié)點(diǎn)上可能需要執(zhí)行redo T。如果 T 的最后一條日志記錄是 <abort T>,那么說(shuō)明協(xié)調(diào)者在節(jié)點(diǎn)發(fā)生故障時(shí)的全局決策是中止 T,根據(jù)本地事務(wù)所使用的日志方式,在該節(jié)點(diǎn)上可能需要執(zhí)行undo T。如果 T 的最后一條日志記錄是 <don't commit T>,則和第 2 中情況類(lèi)似,執(zhí)行undo T。如果 T 的最后一條日志記錄是 <ready T>,這種情況比較麻煩,因?yàn)榛謴?fù)節(jié)點(diǎn)無(wú)法確認(rèn)在它故障之后協(xié)調(diào)者發(fā)出的最終全局決策是什么,因此它必須要和集群中其余至少一個(gè)節(jié)點(diǎn)取得聯(lián)系,詢問(wèn) T 的最終結(jié)果是什么:恢復(fù)節(jié)點(diǎn)先嘗試詢問(wèn)協(xié)調(diào)者,如果此時(shí)協(xié)調(diào)者正在工作,則告知恢復(fù)節(jié)點(diǎn) T 的最終結(jié)果,如果是提交就執(zhí)行redo T,中止就執(zhí)行undo T;如果協(xié)調(diào)者因故不在工作,則恢復(fù)節(jié)點(diǎn)可以要求其他某一個(gè)參與者節(jié)點(diǎn)去查看本地日志以找出 T 的最終結(jié)果并告知恢復(fù)節(jié)點(diǎn)。在最壞的情況下,恢復(fù)節(jié)點(diǎn)無(wú)法和集群中其他所有節(jié)點(diǎn)取得聯(lián)系,這時(shí)恢復(fù)節(jié)點(diǎn)只能阻塞等待,直至得知 T 的最終結(jié)果是提交還是中止。如果本地日志中沒(méi)有記錄任何關(guān)于 T 在兩階段提交過(guò)程中的操作,那么根據(jù)前面的兩階段提交流程可知恢復(fù)節(jié)點(diǎn)還沒(méi)來(lái)得及回復(fù)協(xié)調(diào)者的 canCommit?請(qǐng)求消息就發(fā)生了故障,因此根據(jù)兩階段算法,恢復(fù)節(jié)點(diǎn)只能執(zhí)行undo T。
缺陷
同步阻塞:兩階段提交協(xié)議是一個(gè)阻塞的協(xié)議,在第二階段期間,參與者在事務(wù)未提交之前會(huì)一直鎖定其占有的本地資源對(duì)象,直到接收到來(lái)自協(xié)調(diào)者的 doCommit或doAbort消息。單點(diǎn)故障:兩階段提交協(xié)議中只有一個(gè)協(xié)調(diào)者,而由于在第二階段中參與者在收到協(xié)調(diào)者的進(jìn)一步指示之前會(huì)一直鎖住本地資源對(duì)象,如果唯一的協(xié)調(diào)者此時(shí)出現(xiàn)故障而崩潰掉之后,那么所有參與者都將無(wú)限期地阻塞下去,也就是一直鎖住本地資源對(duì)象而導(dǎo)致其他進(jìn)程無(wú)法使用。 數(shù)據(jù)不一致:如果在兩階段提交協(xié)議的第二階段中,協(xié)調(diào)者向所有參與者發(fā)送 doCommit消息之后,發(fā)生了局部網(wǎng)絡(luò)抖動(dòng)或者異常,抑或是協(xié)調(diào)者在只發(fā)送了部分消息之后就崩潰了,那么就只會(huì)有部分參與者接收到了doCommit消息并提交了本地事務(wù);其他未收到doCommit消息的參與者則不會(huì)提交本地事務(wù),因而導(dǎo)致了數(shù)據(jù)不一致問(wèn)題。
XA 標(biāo)準(zhǔn)接口
2PC 兩階段提交協(xié)議本身只是一個(gè)通用協(xié)議,不提供具體的工程實(shí)現(xiàn)的規(guī)范和標(biāo)準(zhǔn),在工程實(shí)踐中為了統(tǒng)一標(biāo)準(zhǔn),減少行業(yè)內(nèi)不必要的對(duì)接成本,需要制定標(biāo)準(zhǔn)化的處理模型及接口標(biāo)準(zhǔn),國(guó)際開(kāi)放標(biāo)準(zhǔn)組織 Open Group 定義了分布式事務(wù)處理模型 DTP(Distributed Transaction Processing)Model,現(xiàn)在 XA 已經(jīng)成為 2PC 分布式事務(wù)提交的事實(shí)標(biāo)準(zhǔn),很多主流數(shù)據(jù)庫(kù)如 Oracle、MySQL 等都已經(jīng)實(shí)現(xiàn) XA。
兩階段事務(wù)提交采用的是 X/OPEN 組織所定義的 DTP Model 所抽象的 AP(應(yīng)用程序), TM(事務(wù)管理器)和 RM(資源管理器) 概念來(lái)保證分布式事務(wù)的強(qiáng)一致性。其中 TM 與 RM 間采用 XA 的協(xié)議進(jìn)行雙向通信。與傳統(tǒng)的本地事務(wù)相比,XA 事務(wù)增加了準(zhǔn)備階段,數(shù)據(jù)庫(kù)除了被動(dòng)接受提交指令外,還可以反向通知調(diào)用方事務(wù)是否可以被提交。TM 可以收集所有分支事務(wù)的準(zhǔn)備結(jié)果,并于最后進(jìn)行原子提交,以保證事務(wù)的強(qiáng)一致性。
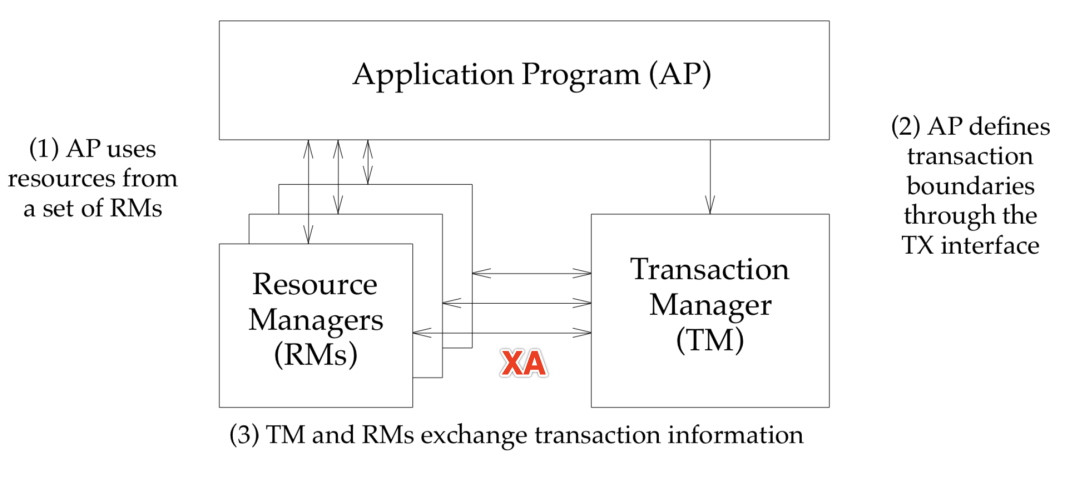
Java 通過(guò)定義 JTA 接口實(shí)現(xiàn)了 XA 模型,JTA 接口中的 ResourceManager 需要數(shù)據(jù)庫(kù)廠商提供 XA 驅(qū)動(dòng)實(shí)現(xiàn), TransactionManager 則需要事務(wù)管理器的廠商實(shí)現(xiàn),傳統(tǒng)的事務(wù)管理器需要同應(yīng)用服務(wù)器綁定,因此使用的成本很高。而嵌入式的事務(wù)管器可以以 jar 包的形式提供服務(wù),同 Apache ShardingSphere 集成后,可保證分片后跨庫(kù)事務(wù)強(qiáng)一致性。
通常,只有使用了事務(wù)管理器廠商所提供的 XA 事務(wù)連接池,才能支持 XA 的事務(wù)。Apache ShardingSphere 在整合 XA 事務(wù)時(shí),采用分離 XA 事務(wù)管理和連接池管理的方式,做到對(duì)應(yīng)用程序的零侵入。
三階段提交協(xié)議
由于前文提到的兩階段提交協(xié)議的種種弊端,研究者們后來(lái)又提出了一種新的分布式原子提交協(xié)議:三階段提交協(xié)議(three-phase commit protocol, 3PC)。
三階段提交協(xié)議是對(duì)兩階段提交協(xié)議的擴(kuò)展,它在特定假設(shè)下避免了同步阻塞的問(wèn)題。該協(xié)議基于以下兩個(gè)假設(shè):
集群不發(fā)生網(wǎng)絡(luò)分區(qū); 故障節(jié)點(diǎn)數(shù)不超過(guò) K 個(gè)(K 是預(yù)先設(shè)定的一個(gè)數(shù)值)。
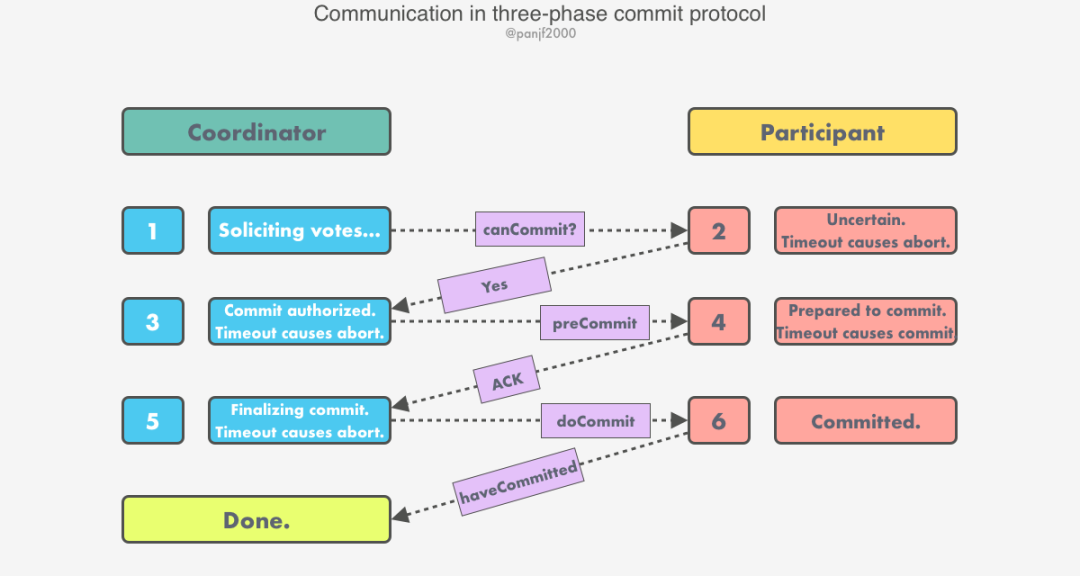
基于這兩個(gè)假設(shè),三階段提交協(xié)議通過(guò)引入超時(shí)機(jī)制和一個(gè)額外的階段來(lái)解決阻塞問(wèn)題,三階段提交協(xié)議把兩階段提交協(xié)議的第一個(gè)階段拆分成了兩步:1) 評(píng)估,2) 資源對(duì)象加鎖,最后才真正提交:
CanCommit 階段:協(xié)調(diào)者發(fā)送 CanCommit請(qǐng)求消息,詢問(wèn)各個(gè)參與者節(jié)點(diǎn),參與者節(jié)點(diǎn)各自評(píng)估本地事務(wù)是否可以執(zhí)行并回復(fù)消息(可以執(zhí)行則回復(fù) YES,否則回復(fù) NO),此階段不執(zhí)行事務(wù),只做判斷;PreCommit 階段:協(xié)調(diào)者根據(jù)上一階段收集的反饋決定通知各個(gè)參與者節(jié)點(diǎn)執(zhí)行(但不提交)或中止本地事務(wù);有兩種可能:1) 所有回復(fù)都是 YES,則發(fā)送 PreCommit請(qǐng)求消息,要求所有參與者執(zhí)行事務(wù)并追加記錄到 undo 和 redo 日志,如果事務(wù)執(zhí)行成功則參與者回復(fù) ACK 響應(yīng)消息,并等待下一階段的指令;2) 反饋消息中只要有一個(gè) NO,或者等待超時(shí)之后協(xié)調(diào)者都沒(méi)有收到參與者的回復(fù),那么協(xié)調(diào)者會(huì)中止事務(wù),發(fā)送Abort請(qǐng)求消息給所有參與者,參與者收到該請(qǐng)求后中止本地事務(wù),或者參與者超時(shí)等待仍未收到協(xié)調(diào)者的消息,同樣也中止當(dāng)前本地事務(wù)。DoCommit 階段:協(xié)調(diào)者根據(jù)上一階段收集到的反饋決定通知各個(gè)參與者節(jié)點(diǎn)提交或回滾本地事務(wù),分三種情況:1) 協(xié)調(diào)者收到全部參與者回復(fù)的 ACK,則向所有參與者節(jié)點(diǎn)廣播 DoCommit請(qǐng)求消息,各個(gè)參與者節(jié)點(diǎn)收到協(xié)調(diào)者的消息之后決定提交事務(wù),然后釋放資源對(duì)象上的鎖,成功之后向協(xié)調(diào)者回復(fù) ACK,協(xié)調(diào)者接收到所有參與者的 ACK 之后,將該分布式事務(wù)標(biāo)記為committed;2) 協(xié)調(diào)者沒(méi)有收到全部參與者回復(fù)的 ACK(可能參與者回復(fù)的不是 ACK,也可能是消息丟失導(dǎo)致超時(shí)),那么協(xié)調(diào)者就會(huì)中止事務(wù),首先向所有參與者節(jié)點(diǎn)廣播Abort請(qǐng)求消息,各個(gè)參與者收到該消息后利用上一階段的 undo 日志進(jìn)行事務(wù)的回滾,釋放占用的資源對(duì)象,然后回復(fù)協(xié)調(diào)者 ACK 消息,協(xié)調(diào)者收到參與者的 ACK 消息后將該分布式事務(wù)標(biāo)記為aborted;3) 參與者一直沒(méi)有收到協(xié)調(diào)者的消息,等待超時(shí)之后會(huì)直接提交事務(wù)。
事實(shí)上,在最后階段,協(xié)調(diào)者不是通過(guò)追加本地日志的方式記錄提交決定的,而是首先保證讓至少 K 個(gè)參與者節(jié)點(diǎn)知道它決定提交該分布式事務(wù)。如果協(xié)調(diào)者發(fā)生故障了,那么剩下的參與者節(jié)點(diǎn)會(huì)重新選舉一個(gè)新的協(xié)調(diào)者,這個(gè)新的協(xié)調(diào)者就可以在集群中不超過(guò) K 個(gè)參與者節(jié)點(diǎn)故障的情況下學(xué)習(xí)到舊協(xié)調(diào)者之前是否已經(jīng)決定要提交分布式事務(wù),若是,則重新開(kāi)始協(xié)議的第三階段,否則就中止該事務(wù),重新發(fā)起分布式事務(wù)。
在最后的 DoCommit 階段,如果參與者一直沒(méi)有收到協(xié)調(diào)者的 DoCommit 或者 Abort 請(qǐng)求消息時(shí),會(huì)在等待超時(shí)之后,直接提交事務(wù)。這個(gè)決策機(jī)制是基于概率學(xué)的:當(dāng)已經(jīng)進(jìn)入第三階段之后,說(shuō)明參與者在第二階段已經(jīng)收到了 PreCommit 請(qǐng)求消息,而協(xié)調(diào)者發(fā)出 PreCommit 請(qǐng)求的前提條件是它在第二階段開(kāi)頭收集到的第一階段向所有參與者發(fā)出的 CanCommit 請(qǐng)求消息的反饋消息都是 YES。所以參與者可以根據(jù)自己收到了 PreCommit 請(qǐng)求消息這一既定事實(shí)得出這樣的一個(gè)結(jié)論:其他所有參與者都同意了進(jìn)行這次的事務(wù)執(zhí)行,因此當(dāng)前的參與者節(jié)點(diǎn)有理由相信,進(jìn)入第三階段后,其他參與者節(jié)點(diǎn)的本地事務(wù)最后成功提交的概率很大,而自己遲遲沒(méi)有收到 DoCommit 或 Abort 消息可能僅僅是因?yàn)榫W(wǎng)絡(luò)抖動(dòng)或異常,因此直接提交自己的本地事務(wù)是一個(gè)比較合理的選擇。
三階段提交協(xié)議主要著重于解決兩階段提交協(xié)議中因?yàn)閰f(xié)調(diào)者單點(diǎn)故障而引發(fā)的同步阻塞問(wèn)題,雖然相較于兩階段提交協(xié)議有所優(yōu)化,但還是沒(méi)解決可能發(fā)生的數(shù)據(jù)不一致問(wèn)題,比如由于網(wǎng)絡(luò)異常導(dǎo)致部分參與者節(jié)點(diǎn)沒(méi)有收到協(xié)調(diào)者的 Abort 請(qǐng)求消息,超時(shí)之后這部分參與者會(huì)直接提交事務(wù),從而導(dǎo)致集群中的數(shù)據(jù)不一致,另外三階段提交協(xié)議也無(wú)法解決腦裂問(wèn)題,同時(shí)也因?yàn)檫@個(gè)協(xié)議的網(wǎng)絡(luò)開(kāi)銷(xiāo)問(wèn)題,導(dǎo)致它并沒(méi)有被廣泛地使用,有關(guān)該協(xié)議的具體細(xì)節(jié)可以參閱本文最后的延伸閱讀一節(jié)中的文獻(xiàn)進(jìn)一步了解,這里不再深入。
共識(shí)算法
共識(shí)(Consensus),很多時(shí)候會(huì)見(jiàn)到與一致性(Consistency)術(shù)語(yǔ)放在一起討論。嚴(yán)謹(jǐn)?shù)刂v,兩者的含義并不完全相同。
一致性的含義比共識(shí)寬泛,在不同場(chǎng)景(基于事務(wù)的數(shù)據(jù)庫(kù)、分布式系統(tǒng)等)下意義不同。具體到分布式系統(tǒng)場(chǎng)景下,一致性指的是多個(gè)副本對(duì)外呈現(xiàn)的狀態(tài)。如前面提到的順序一致性、線性一致性,描述了多節(jié)點(diǎn)對(duì)數(shù)據(jù)狀態(tài)的共同維護(hù)能力。而共識(shí),則特指在分布式系統(tǒng)中多個(gè)節(jié)點(diǎn)之間對(duì)某個(gè)事情(例如多個(gè)事務(wù)請(qǐng)求,先執(zhí)行誰(shuí)?)達(dá)成一致意見(jiàn)的過(guò)程。因此,達(dá)成某種共識(shí)并不意味著就保障了一致性。
實(shí)踐中,要保證系統(tǒng)滿足不同程度的一致性,往往需要通過(guò)共識(shí)算法來(lái)達(dá)成。
共識(shí)算法解決的是分布式系統(tǒng)對(duì)某個(gè)提案(Proposal),大部分節(jié)點(diǎn)達(dá)成一致意見(jiàn)的過(guò)程。提案的含義在分布式系統(tǒng)中十分寬泛,如多個(gè)事件發(fā)生的順序、某個(gè)鍵對(duì)應(yīng)的值、誰(shuí)是主節(jié)點(diǎn)……等等。可以認(rèn)為任何可以達(dá)成一致的信息都是一個(gè)提案。
對(duì)于分布式系統(tǒng)來(lái)講,各個(gè)節(jié)點(diǎn)通常都是相同的確定性狀態(tài)機(jī)模型(又稱(chēng)為狀態(tài)機(jī)復(fù)制問(wèn)題,State-Machine Replication),從相同初始狀態(tài)開(kāi)始接收相同順序的指令,則可以保證相同的結(jié)果狀態(tài)。因此,系統(tǒng)中多個(gè)節(jié)點(diǎn)最關(guān)鍵的是對(duì)多個(gè)事件的順序進(jìn)行共識(shí),即排序。
算法共識(shí)/一致性算法有兩個(gè)最核心的約束:1) 安全性(Safety),2) 存活性(Liveness):
Safety:保證決議(Value)結(jié)果是對(duì)的,無(wú)歧義的,不會(huì)出現(xiàn)錯(cuò)誤情況。
只有是被提案者提出的提案才可能被最終批準(zhǔn); 在一次執(zhí)行中,只批準(zhǔn)(chosen)一個(gè)最終決議。被多數(shù)接受(accept)的結(jié)果成為決議; Liveness:保證決議過(guò)程能在有限時(shí)間內(nèi)完成。
決議總會(huì)產(chǎn)生,并且學(xué)習(xí)者最終能獲得被批準(zhǔn)的決議。
Paxos
Google Chubby 的作者 Mike Burrows 說(shuō)過(guò), there is only one consensus protocol, and that’s Paxos” – all other approaches are just broken versions of Paxos.
意即世上只有一種共識(shí)算法,那就是 Paxos,其他所有的共識(shí)算法都只是 Paxos 算法的殘缺版本。雖然有點(diǎn)武斷,但是自從 Paxos 問(wèn)世以來(lái),它便幾乎成為了分布式共識(shí)算法的代名詞,后來(lái)的許多應(yīng)用廣泛的分布式共識(shí)算法如 Raft、Zab 等的原理和思想都可以溯源至 Paxos 算法。
Paxos 是由 Leslie Lamport (LaTeX 發(fā)明者,圖靈獎(jiǎng)得主,分布式領(lǐng)域的世界級(jí)大師) 在 1990 年的論文《The PartTime Parliament》里提出的,Lamport 在論文中以一個(gè)古希臘的 Paxos 小島上的議會(huì)制訂法律的故事切入,引出了 Paxos 分布式共識(shí)算法。
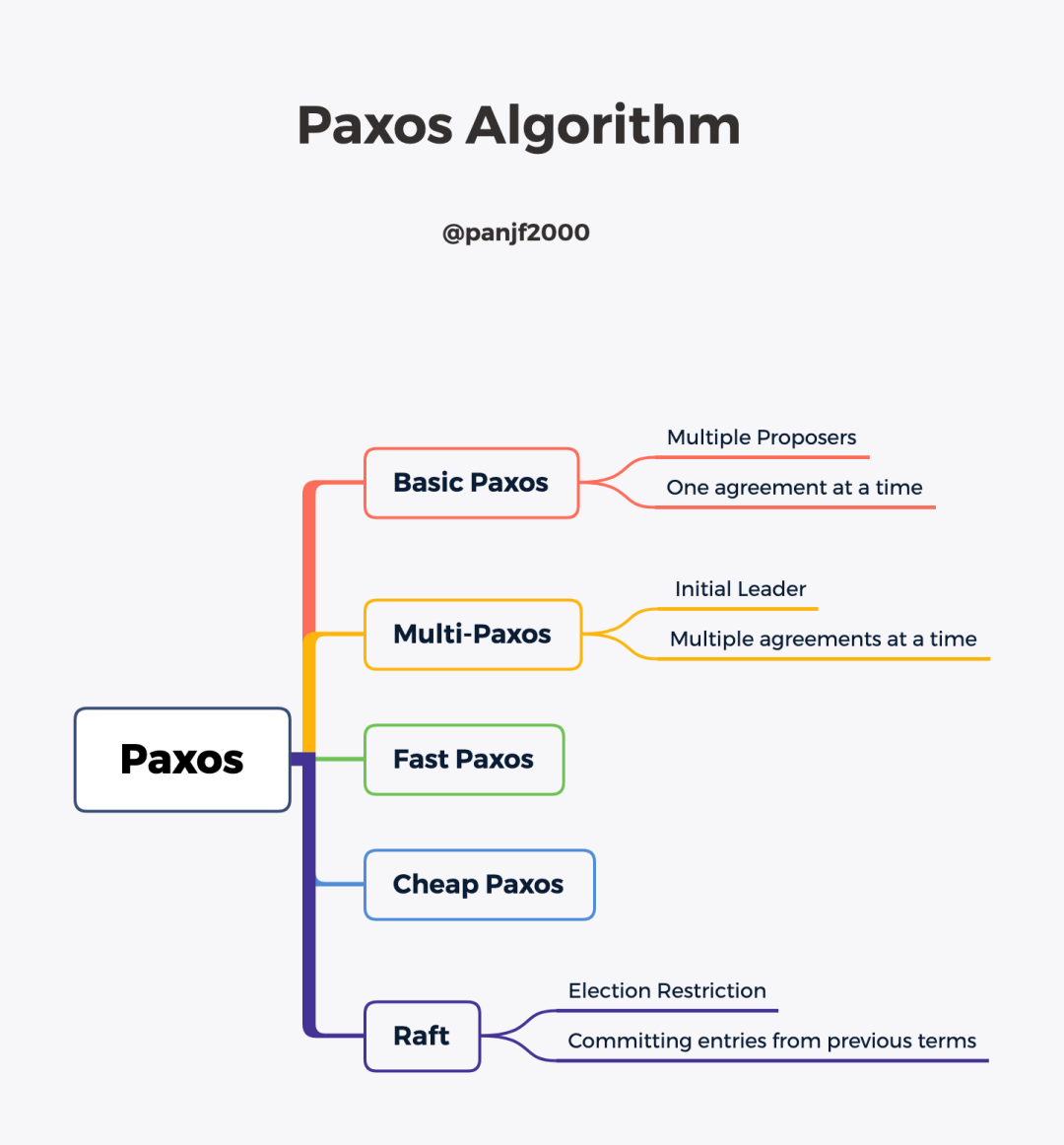
Basic Paxos
業(yè)界一般將 Lamport 論文里最初提出分布式算法稱(chēng)之為 Basic Paxos,這是 Paxos 最基礎(chǔ)的算法思想。
Basic Paxos 算法的最終目標(biāo)是通過(guò)嚴(yán)謹(jǐn)和可靠的流程來(lái)使得集群基于某個(gè)提案(Proposal)達(dá)到最終的共識(shí)。
基礎(chǔ)概念
Value:提案值,是一個(gè)抽象的概念,在工程實(shí)踐中可以是任何操作,如『更新數(shù)據(jù)庫(kù)某一行的某一列』、『選擇 xxx 服務(wù)器節(jié)點(diǎn)作為集群中的主節(jié)點(diǎn)』。 Number:提案編號(hào),全局唯一,單調(diào)遞增。 Proposal:集群需要達(dá)成共識(shí)的提案,提案 = 編號(hào) + 值。
Proposal 中的 Value 就是在 Paxos 算法完成之后需要達(dá)成共識(shí)的值。
Paxos 算法中有三個(gè)核心角色:
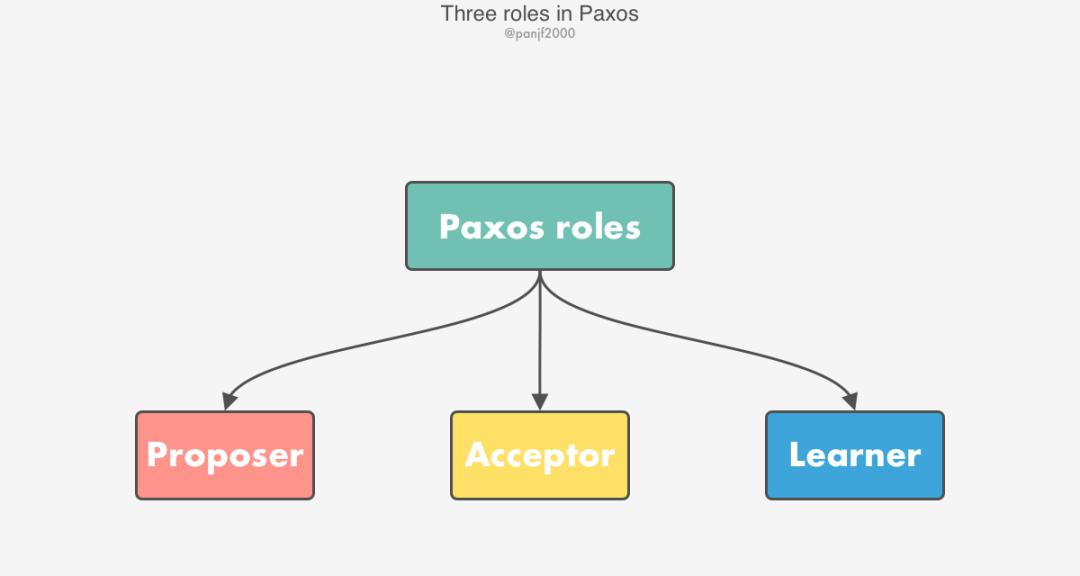
Proposer:生成提案編號(hào) n和值v,然后向 Acceptors 廣播該提案,接收 Acceptors 的回復(fù),如果有超過(guò)半數(shù)的 Acceptors 同意該提案,則選定該提案,否則放棄此次提案并生成更新的提案重新發(fā)起流程,提案被選定之后則通知所有 Learners 學(xué)習(xí)該最終選定的提案值(也可以由 Acceptor 來(lái)通知,看具體實(shí)現(xiàn))。Basic Paxos 中允許有多個(gè) Proposers。Acceptor:接收 Proposer 的提案并參與提案決策過(guò)程,把各自的決定回復(fù)給 Proposer 進(jìn)行統(tǒng)計(jì)。Acceptor 可以接受來(lái)自多個(gè) proposers 的多個(gè)提案。 Learner:不參與決策過(guò)程,只學(xué)習(xí)最終選定的提案值。
在具體的工程實(shí)踐中,一個(gè)節(jié)點(diǎn)往往會(huì)充當(dāng)多種角色,比如一個(gè)節(jié)點(diǎn)可以既是 Proposer 又是 Acceptor,甚至還是 Learner。
算法流程
相較于直接給出 Paxos 算法的流程,我想沿襲 Lamport 大師的經(jīng)典 Paxos 論文《Paxos Made Simple》中的思路:通過(guò)循序漸進(jìn)的方式推導(dǎo)出 Paxos 算法。
首先需要了解 Paxos 算法中的兩個(gè)重要的約束:
C1. 一個(gè) Acceptor 必須接受它收到的第一個(gè)提案。
C2. 只有當(dāng)超過(guò)半數(shù)的 Acceptors 接受某一個(gè)提案,才能最終選定該提案。
C2 其實(shí)有一個(gè)隱含的推論:一個(gè) Acceptor 可以接受多個(gè)提案,這也是為什么我們需要給每一個(gè)提案生成一個(gè)編號(hào)的原因,用來(lái)給提案排序。
我們前面提到過(guò) Paxos 的最終目標(biāo)是通過(guò)嚴(yán)謹(jǐn)和可靠的流程來(lái)使得集群基于某個(gè)提案(Proposal)達(dá)到最終的共識(shí),也就是說(shuō)基于某一個(gè)提案發(fā)起的一次 Paxos 流程,最終目的是希望集群對(duì)該提案達(dá)成一致的意見(jiàn),而為了實(shí)現(xiàn)并維持集群中的這種一致性,前提是 Paxos 算法必須具有冪等性:一旦提案(Proposal)中的值(Value)被選定(Chosen),那么只要還在此次 Paxos 流程中,就算不斷按照 Paxos 的規(guī)則重復(fù)步驟,未來(lái)被 Chosen 的 Value 都會(huì)是同一個(gè)。如果不滿足這種冪等性,將可能導(dǎo)致不一致的問(wèn)題。
因此,我們可以把 Paxos 的基本命題提煉出來(lái):
P1. 在一次 Paxos 流程中,如果一個(gè)值(Value)為
v的提案(Proposal)被選定(Chosen)了,那么后續(xù)任何被最終選定的帶有更大編號(hào)(Number)的提案中的 Value 也必須是v。
提案在被最終選定之前必須先被 Acceptor 接受,于是我們可以再進(jìn)一步總結(jié)一個(gè)具有更強(qiáng)約束的命題:
P2. 在一次 Paxos 流程中,如果一個(gè)值(Value)為
v的提案(Proposal)被選定(Chosen)了,那么后續(xù)任何被 Acceptor 接受的帶有更大編號(hào)(Number)的提案中的 Value 也必須是v。
這還不是具備最強(qiáng)約束的命題,因?yàn)樘岚冈诒?Acceptor 接受之前必須先由 Proposer 提出,因此還可以繼續(xù)強(qiáng)化命題:
P3. 在一次 Paxos 流程中,如果一個(gè)值(Value)為
v的提案(Proposal)被選定(Chosen)了,那么后續(xù)任何 Proposer 提議的帶有更大編號(hào)(Number)的提案中的 Value 也必須是v。
從上述的三個(gè)命題,我們可以很容易地看出來(lái),P3 可以推導(dǎo)出 P2,進(jìn)而推導(dǎo)出 P1,也就是說(shuō)這是一個(gè)歸約的過(guò)程,因此只要 P3 成立則 P1 成立,也就是 Paxos 算法的正確性得到保證。
那么要如何實(shí)現(xiàn)呢 P3 呢?只需滿足如下約束:
C3. 對(duì)于一個(gè)被 Proposer 提議的提案中任意的
v和n,存在一個(gè)數(shù)量超過(guò)半數(shù) Acceptors 的集合 S,滿足以下兩個(gè)條件中的任意一個(gè):
S 中的任何一個(gè) Acceptor 都沒(méi)有接受過(guò)編號(hào)小于 n的提案。S 中所有的 Acceptors 接受過(guò)的最大編號(hào)的提案的 Value 為 v。
為了滿足 C3 從而實(shí)現(xiàn) P3,需要引入一條約束:Proposer 每次生成自己的 n 之后,發(fā)起提案之前,必須要先去『學(xué)習(xí)』那個(gè)已經(jīng)被選定或者將要被選定的小于 n 的提案,如果有這個(gè)提案的話則把那個(gè)提案的 v 作為自己的此次提案的 Value,沒(méi)有的話才可以自己指定一個(gè) Value,這樣的話 Proposer 側(cè)就可以保證更高編號(hào)的提案的值只會(huì)是已選定的 v 了,但是 Acceptor 側(cè)還無(wú)法保證,因?yàn)?Acceptor 有可能還會(huì)接受其他的 Proposers 的提案值,于是我們需要對(duì) Acceptor 也加一條約束,讓它承諾在收到編號(hào)為 n 的 v 之后,不會(huì)再接受新的編號(hào)小于 n 的提案值。
所以我們可以得到一個(gè) Paxos 在 Proposer 側(cè)的算法流程:
Proposer 生成一個(gè)新的提案編號(hào)
n然后發(fā)送一個(gè) prepare 請(qǐng)求給超過(guò)半數(shù)的 Acceptors 集合,要求集合中的每一個(gè) Acceptor 做出如下響應(yīng):(a) 向 Proposer 承諾在收到該消息之后就不再接受編號(hào)小于
n的提案。(b) 如果 Acceptor 在收到該消息之前已經(jīng)接受過(guò)其他提案,則把當(dāng)前接受的編號(hào)最大的提案回復(fù)給 Proposer。
如果 Proposer 收到了超過(guò)半數(shù)的 Acceptors 的回復(fù),那么就可以生成
(n, v)的提案,這里v是所有 Acceptors 回復(fù)中編號(hào)最大的那個(gè)提案里的值,如果所有 Acceptors 回復(fù)中都沒(méi)有附帶上提案的話,則可以由 Proposer 自己選擇一個(gè)v。Proposer 將上面生成的提案通過(guò)一個(gè) accept 請(qǐng)求發(fā)送給一個(gè)超過(guò)半數(shù)的 Acceptors 集合。(需要注意的是這個(gè)集合不一定和第二步中的那個(gè)集合是同一個(gè)。)
Paxos 在 Proposer 側(cè)的算法流程已經(jīng)確定了,接下來(lái)我們需要從 Acceptor 的視角來(lái)完成剩下的算法推導(dǎo)。前面我們提到過(guò),Acceptor 是可以接受多個(gè) Proposers 的多個(gè)提案的,但是在收到一個(gè) Proposer 的 prepare 消息后會(huì)承諾不再接受編號(hào)小于 n 的新提案,也就是說(shuō) Acceptor 也是可以忽略掉其他 Proposers 消息(包括 prepare 和 accept)而不會(huì)破壞算法的安全性,當(dāng)然了,在工程實(shí)踐中也可以直接回復(fù)一個(gè)錯(cuò)誤,讓 Proposer 更早知道提案被拒絕然后生成提案重新開(kāi)始流程。這里我們應(yīng)該重點(diǎn)思考的場(chǎng)景是一個(gè) Acceptor 接受一個(gè)提案請(qǐng)求的時(shí)候,根據(jù)前面 Proposer 要求 Acceptor 的承諾,我們可以給 Acceptor 設(shè)置一個(gè)這樣的約束:
C4. 如果一個(gè) Proposer 發(fā)出了帶
n的 prepare 請(qǐng)求,只要 Acceptor 還沒(méi)有回復(fù)過(guò)任何其他編號(hào)大于n的prepare 請(qǐng)求,則該 Acceptor 可以接受這個(gè)提案。
因?yàn)?Acceptor 需要對(duì) Proposer 做出不接受編號(hào)小于 n 的提案的承諾,因此它需要做持久化記錄,那么它就必須是有狀態(tài)的,也因此每個(gè) Acceptor 都需要利用可靠性存儲(chǔ)(日志)來(lái)保存兩個(gè)對(duì)象:
Acceptor 接受過(guò)的編號(hào)最大的提案; Acceptor 回復(fù)過(guò)的最大的 prepare 請(qǐng)求提案編號(hào)。
以上這就是 Acceptor 側(cè)的約束。接下來(lái)我們就可以得到 Paxos 的整個(gè)算法流程了。
Paxos 算法可以歸納為兩大基本過(guò)程:
選擇過(guò)程; 學(xué)習(xí)過(guò)程。
選擇過(guò)程
選擇過(guò)程分為兩個(gè)階段:
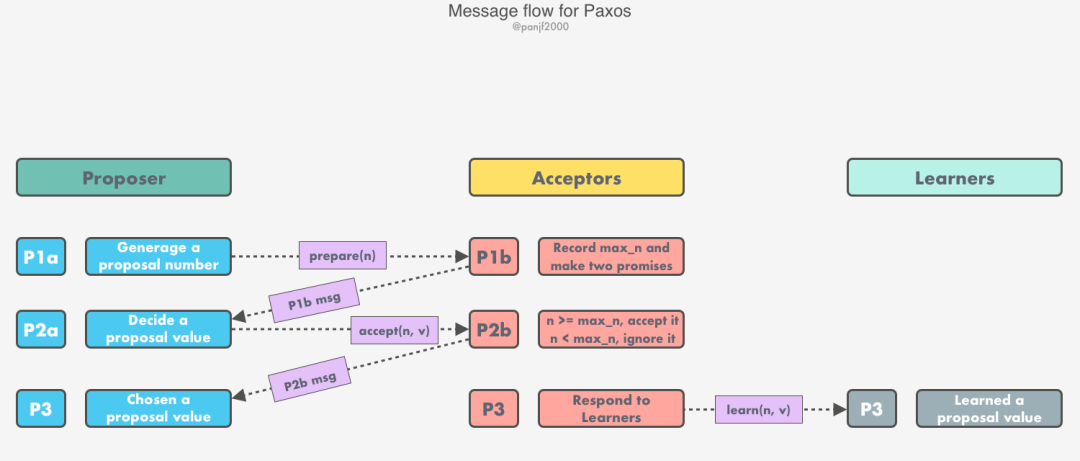
階段一(Phase 1):
(a) Proposer 生成一個(gè)全局唯一且單調(diào)遞增的提案編號(hào)
n,然后發(fā)送編號(hào)為n的 prepare 請(qǐng)求(P1a msg)給超過(guò)半數(shù)的 Acceptors 集合。(b) 當(dāng)一個(gè) Acceptor 收到一個(gè)編號(hào)為
n的 prepare 請(qǐng)求,如果n比它此前接受過(guò)其他的提案編號(hào)(如果有)都要大的話,那么將這個(gè)提案編號(hào)n寫(xiě)入本地日志,這里記為max_n,然后作出『兩個(gè)承諾,一個(gè)回復(fù)』:否則就忽略該 prepare 消息或者回復(fù)一個(gè)錯(cuò)誤。
在不違背以前作出的承諾下,回復(fù)消息(P1b msg),附帶上自己已經(jīng)接受過(guò)的提案中編號(hào)最大的那個(gè)提案的 v和n,沒(méi)有則返回空值。不再接受編號(hào)小于等于 n的 prepare 請(qǐng)求不再接受編號(hào)小于等于 n的 accept 請(qǐng)求兩個(gè)承諾:
一個(gè)回復(fù):
階段二(Phase 2):
(a) 當(dāng) Proposer 收到超過(guò)半數(shù)的 Acceptors 回復(fù)它的編號(hào)為
n的 prepare 請(qǐng)求的響應(yīng),此時(shí)有兩種可能:(b) 當(dāng) Acceptor 收到一個(gè)編號(hào)為
n的提案的 accept 請(qǐng)求消息,需要分兩種情況處理:如果 n>=max_n(通常情況下這兩個(gè)值是相等的),則接受該提案并回復(fù)消息(P2b msg)。如果 n<max_n,則忽略該 accept 消息或者回復(fù)一個(gè)錯(cuò)誤(P2b error)。Free:沒(méi)有任何一個(gè) Acceptor 的回復(fù)消息中附帶已被接受的提案,意味著當(dāng)前流程中還沒(méi)有提案值被最終接受,此時(shí) Proposer 可以自由地選擇提案值 Value,最后發(fā)送一個(gè)包含 (n, v)提案的 accept 請(qǐng)求消息(P2a msg)給 Acceptors 集合。Forced:某些 Acceptors 的回復(fù)消息中附帶已被接受的提案,那么 Proposer 必須強(qiáng)制使用這些回復(fù)消息中編號(hào)最大的提案 Value 作為自己的提案值,最后發(fā)送一個(gè)包含 (n, v)提案的 accept 請(qǐng)求消息(P2a msg)給 Acceptors 集合。
學(xué)習(xí)過(guò)程
選擇過(guò)程結(jié)束之后,我們得到了一個(gè)提案值,接下來(lái)就是要讓集群中的所有 Learner 『學(xué)習(xí)』到這個(gè)值了,以求達(dá)到集群的共識(shí)。
Learner 學(xué)習(xí)提案值的方式可以分成三種:
任意一個(gè) Acceptor 接受了一個(gè)提案后就立刻將該提案發(fā)送給所有 Learner。優(yōu)點(diǎn):Learner 能實(shí)時(shí)學(xué)習(xí)到被 Paxos 流程選定的 Value;缺點(diǎn):網(wǎng)絡(luò)通信次數(shù)太多,如果有 N 個(gè) Acceptors 和 M 個(gè) Learner,則需要的網(wǎng)絡(luò)通信是 N*M 次。 設(shè)置一個(gè)主 Learner,Acceptor 接受了一個(gè)提案后只將該提案發(fā)送給主 Learner,主 Learner 再轉(zhuǎn)發(fā)給剩下的 Learners。優(yōu)點(diǎn):網(wǎng)絡(luò)通信次數(shù)只需 N+M-1 次;缺點(diǎn):主 Learner 有單點(diǎn)故障的風(fēng)險(xiǎn)。 Acceptor 接受了一個(gè)提案后將該提案發(fā)送給一個(gè) Learner 集合,由這個(gè)集合去通知剩下的 Learners。優(yōu)點(diǎn):用集合替代單點(diǎn),可靠性更高;缺點(diǎn):增加系統(tǒng)復(fù)雜度,需要維護(hù)一個(gè) Learner 小集群。
至此,我們就推導(dǎo)出了整個(gè) Paxos 算法的流程:
算法證明
這一節(jié)我們來(lái)證明 Paxos 算法的正確性。
上一節(jié)我們已經(jīng)提煉出來(lái)了 Paxos 的基本命題 P1,并通過(guò)歸約 P1 得到了約束性更強(qiáng)的另外兩個(gè)命題 P2 和 P3,根據(jù)歸約的原理,我們知道 P3 可以最終推導(dǎo)出 P1,也就是說(shuō)如果要證明 Paxos 的基本命題 P1,只需要證明 P3 即可。為什么之前我們要不斷強(qiáng)化 Paxos 的命題呢?因?yàn)閺臄?shù)學(xué)的層面來(lái)講,一個(gè)具有更強(qiáng)約束(更多假設(shè))的命題一般會(huì)更容易證明。
現(xiàn)在我們把 P1, P2 和 P3 用更嚴(yán)格的數(shù)學(xué)語(yǔ)言來(lái)描述:
P1. 在一次 Paxos 流程中,如果一個(gè)包含 (n, v) 的提案被選定(Chosen),那么存在未來(lái)被選定的提案 (k, v1),必然滿足 k > n,v1 = v。
P2. 在一次 Paxos 流程中,如果一個(gè)包含 (n, v) 的提案被選定(Chosen),那么存在未來(lái)被超過(guò)半數(shù)的 Acceptors 接受的提案 (k, v1),必然滿足 k > n,v1 = v。
P3. 在一次 Paxos 流程中,如果一個(gè)包含 (n, v) 的提案被選定(Chosen),那么存在未來(lái)由 Proposer 提議的提案 (k, v1),必然滿足 k > n,v1 = v。
現(xiàn)在我們利用數(shù)學(xué)歸納法來(lái)證明 P3:
假設(shè) k = m 時(shí) P3 成立,由于 (n, v) 已經(jīng)是被選定的提案,因此 Proposer 發(fā)起的從 n 到 k 的提案中的 Value 都會(huì)是 v,其中 m >= n,那么根據(jù)歸約的原理可證 k = m 時(shí) P1 也成立。
現(xiàn)在令 k = m+1,Proposer 發(fā)送帶編號(hào) k 的 prepare 請(qǐng)求消息到 Acceptors 集合。
由于此前已經(jīng)有了選定的提案,那么根據(jù) Paxos 的約束 C2 可知參與這一個(gè)提案投票的 Acceptors 集合必定和上一個(gè)集合有重合。
根據(jù) Acceptors 集合重疊和 Paxos 的 P1b 階段可知,回復(fù)的消息中必定附帶有已被大多數(shù) Acceptors 接受的提案 (i, v0)。
然后根據(jù) P2a 階段,Proposer 提案 (k, v1),其中 v1 = v0。
還是根據(jù) P1b,可知 i 是所有回復(fù)消息里編號(hào)最大的,可得 i >= m,又根據(jù) P1a 可知 i < k,因此可以得出提案 (i, v0) 中有 v0 = v。
可知當(dāng) k = m+1 時(shí),提案 (k, v1) 中的 v1 = v。
根據(jù)數(shù)學(xué)歸納法的原理,我們還需要找到一個(gè)特例來(lái)使得命題成立,然后由特例推廣到普遍,我們這里選擇 k = 1 作為特例,證明 k = 1 時(shí) P3 成立:根據(jù) Paxos 的約束 C1 易知在 n = 0,k = 1 的場(chǎng)景下,P3 成立。
因此可根據(jù)數(shù)學(xué)歸納法基于 k = 1 進(jìn)行推廣至 k = m(m 代表任意自然數(shù)),最后 P3 命題得證。
再由歸約的原理可知,P3 可推導(dǎo)出 P2,最后 P2 推導(dǎo)出 P1。至此, Paxos 算法原理正確性的證明完成。
上述的證明只是一種比較簡(jiǎn)單且粗淺的證明方法,但是對(duì)于工程師理解 Paxos 原理來(lái)說(shuō)已經(jīng)足夠了,如果希望進(jìn)一步學(xué)習(xí) Paxos 原理的嚴(yán)格數(shù)學(xué)證明,可以參閱 Leslie Lamport 的原始論文《The PartTime Parliament》,里面給出了 Paxos 算法的嚴(yán)格數(shù)學(xué)證明。
Multi-Paxos
自 Lamport 于 1990 年在論文《The PartTime Parliament》中提出 Paxos 算法之后,這個(gè)算法一直被評(píng)價(jià)為難以理解和實(shí)現(xiàn),這篇論文中運(yùn)用了大量的數(shù)學(xué)對(duì) Paxos 的原理進(jìn)行證明,而又由于 Lamport 在論文里用講故事的形式解釋 Paxos,進(jìn)一步增大了人們徹底理解 Paxos 的難度,事實(shí)上 Lamport 的這篇論文也因此在發(fā)表過(guò)程中一波三折,這里不展開(kāi),有興趣的讀者可以自行去了解這段這段背景故事。
因?yàn)闃I(yè)界在理解 Paxos 算法上持續(xù)的怨聲載道,Lamport 在 2001 年發(fā)表了論文《Paxos Made Simple》,對(duì)原論文進(jìn)行精簡(jiǎn),以更通俗易懂的語(yǔ)言和形式闡述 Paxos 算法,并在其中提出了更加具備工程實(shí)踐性的 Multi-Paxos 的思想。
關(guān)于 Paxos 難以理解的問(wèn)題上,我個(gè)人的一點(diǎn)愚見(jiàn)是:Paxos 算法的思想其實(shí)并不難理解,真正難的地方是:
Paxos 背后那一套完整的數(shù)學(xué)原理和證明 在復(fù)雜分布式環(huán)境將 Paxos 進(jìn)行工程落地
我個(gè)人建議的 Paxos 學(xué)習(xí)資料是:《Paxos Made Simple》,《Paxos Made Live - An Engineering Perspective》以及 Paxos lecture (Raft user study)。第一篇論文可以說(shuō)是 Lamport 1990 年那篇最初的論文的精簡(jiǎn)版,可讀性提高了很多,論文里也沒(méi)有使用任何數(shù)學(xué)公式,只需一點(diǎn)英文基礎(chǔ)就可以通讀,第二篇論文講的則是 Google 內(nèi)部基于 Multi-Paxos 實(shí)現(xiàn)的分布式鎖機(jī)制和小文件存儲(chǔ)系統(tǒng),這是業(yè)界較早的實(shí)現(xiàn)了 Multi-Paxos 的大規(guī)模線上系統(tǒng),十分具有參考性,最后的 Youtube 視頻則是 Raft 的作者 Diego Ongaro 為了對(duì)比 Raft 和 Multi-Paxos 的學(xué)習(xí)的難易程度而做的,非常適合作為學(xué)習(xí) Paxos 和 Raft 的入門(mén)資料。
從上一節(jié)可知 Basic Paxos 算法有幾個(gè)天然缺陷:
只能就單個(gè)值(Value)達(dá)成共識(shí),不支持多值共識(shí)。在實(shí)際的工程實(shí)踐中往往是需要對(duì)一系列的操作達(dá)成共識(shí),比如分布式事務(wù),由很多執(zhí)行命令組成。 至少需要 2 輪往返 4 次 prepare 和 accept 網(wǎng)絡(luò)通信才能基于一項(xiàng)提案達(dá)成共識(shí)。對(duì)于一個(gè)分布式系統(tǒng)來(lái)說(shuō),網(wǎng)絡(luò)通信是最影響性能的因素之一,過(guò)多的網(wǎng)絡(luò)通信往往會(huì)導(dǎo)致系統(tǒng)的性能瓶頸。 不限制 Proposer 數(shù)量導(dǎo)致非常容易發(fā)生提案沖突。極端情況下,多 Proposer 會(huì)導(dǎo)致系統(tǒng)出現(xiàn)『活鎖』,破壞分布式共識(shí)算法的兩大約束之一的活性(liveness)。
關(guān)于第三點(diǎn),前文提到分布式共識(shí)算法必須滿足兩個(gè)最核心的約束:安全性(safety)和活性(liveness),從上一節(jié)我們可以看出 Basic Paxos 主要著重于 safety,而對(duì) liveness 并沒(méi)有進(jìn)行強(qiáng)約束,讓我們?cè)O(shè)想一種場(chǎng)景:兩個(gè) Proposers (記為 P1 和 P2) 輪替著發(fā)起提案,導(dǎo)致兩個(gè) Paxos 流程重疊了:
首先,P1 發(fā)送編號(hào) N1 的 prepare 請(qǐng)求到 Acceptors 集合,收到了過(guò)半的回復(fù),完成階段一。 緊接著 P2 也進(jìn)入階段一,發(fā)送編號(hào) N2 的 prepare 請(qǐng)求到過(guò)半的 Acceptors 集合,也收到了過(guò)半的回復(fù),Acceptors 集合承諾不再接受編號(hào)小于 N2 的提案。 然后 P1 進(jìn)入階段二,發(fā)送編號(hào) N1 的 accept 請(qǐng)求被 Acceptors 忽略,于是 P1 重新進(jìn)入階段一發(fā)送編號(hào) N3 的 prepare 請(qǐng)求到 Acceptors 集合,Acceptors 又承諾不再接受編號(hào)小于 N3 的提案。 緊接著 P2 進(jìn)入階段二,發(fā)送編號(hào) N2 的 accept 請(qǐng)求,又被 Acceptors 忽略。 不斷重復(fù)上面的過(guò)程......
在極端情況下,這個(gè)過(guò)程會(huì)永遠(yuǎn)持續(xù),導(dǎo)致所謂的『活鎖』,永遠(yuǎn)無(wú)法選定一個(gè)提案,也就是 liveness 約束無(wú)法滿足。
為了解決這些問(wèn)題,Lamport 在《Paxos Made Simple》論文中提出了一種基于 Basic Paxos 的 Multi-Paxos 算法思想,并基于該算法引出了一個(gè)分布式銀行系統(tǒng)狀態(tài)機(jī)的實(shí)現(xiàn)方案,感興趣的讀者不妨看一下。
Multi-Paxos 算法在 Basic Paxos 的基礎(chǔ)上做了兩點(diǎn)改進(jìn):
多 Paxos 實(shí)例:針對(duì)每一個(gè)需要達(dá)成共識(shí)的單值都運(yùn)行一次 Basic Paxos 算法的實(shí)例,并使用 Instance ID 做標(biāo)識(shí),最后匯總完成多值共識(shí)。 選舉單一的 Leader Proposer:選舉出一個(gè) Leader Proposer,所有提案只能由 Leader Proposer 來(lái)發(fā)起并決策,Leader Proposer 作為 Paxos 算法流程中唯一的提案發(fā)起者,『活鎖』將不復(fù)存在。此外,由于單一 Proposer 不存在提案競(jìng)爭(zhēng)的問(wèn)題,Paxos 算法流程中的階段一中的 prepare 步驟也可以省略掉,從而將兩階段流程變成一階段,大大減少網(wǎng)絡(luò)通信次數(shù)。
關(guān)于多值共識(shí)的優(yōu)化,如果每一個(gè) Basic Paxos 算法實(shí)例都設(shè)置一個(gè) Leader Proposer 來(lái)工作,還是會(huì)產(chǎn)生大量的網(wǎng)絡(luò)通信開(kāi)銷(xiāo),因此,多個(gè) Paxos 實(shí)例可以共享同一個(gè) Leader Proposer,這要求該 Leader Proposer 必須是穩(wěn)定的,也即 Leader 不應(yīng)該在 Paxos 流程中崩潰或改變。
由于 Lamport 在論文中提出的 Multi-Paxos 只是一種思想而非一個(gè)具體算法,因此關(guān)于 Multi-Paxos 的很多細(xì)節(jié)他并沒(méi)有給出具體的實(shí)現(xiàn)方案,有些即便給出了方案也描述得不是很清楚,比如他在論文中最后一節(jié)提出的基于銀行系統(tǒng)的狀態(tài)機(jī)中的多 Paxos 實(shí)例處理,雖然給了具體的論述,但是在很多關(guān)鍵地方還是沒(méi)有指明,這也導(dǎo)致了后續(xù)業(yè)界里的 Multi-Paxos 實(shí)現(xiàn)各不相同。
我們這里用 Google Chubby 的 Multi-Paxos 實(shí)現(xiàn)來(lái)分析這個(gè)算法。
首先,Chubby 通過(guò)引入 Master 節(jié)點(diǎn),實(shí)現(xiàn)了 Lamport 在論文中提到的 single distinguished proposer,也就是 Leader Proposer,Leader Proposer 作為 Paxos 算法流程中唯一的提案發(fā)起者,規(guī)避了多 Proposers 同時(shí)發(fā)起提案的場(chǎng)景,也就不存在提案沖突的情況了,從而解決了『活鎖』的問(wèn)題,保證了算法的活性(liveness)。
Lamport 在論文中指出,選擇 Leader Proposer 的過(guò)程必須是可靠的,那么具體如何選擇一個(gè) Leader Proposer 呢?在 Chubby 中,集群利用 Basic Paxos 算法的共識(shí)功能來(lái)完成對(duì) Leader Proposer 的選舉,這個(gè)實(shí)現(xiàn)是具有天然合理性的,因?yàn)?Basic Paxos 本身就是一個(gè)非常可靠而且經(jīng)過(guò)嚴(yán)格數(shù)學(xué)證明的共識(shí)算法,用來(lái)作為選舉算法再合適不過(guò)了,在 Multi-Paxos 流程期間,Master 會(huì)通過(guò)不斷續(xù)租的方式來(lái)延長(zhǎng)租期(Lease)。比如在實(shí)際場(chǎng)景中,一般在長(zhǎng)達(dá)幾天的時(shí)期內(nèi)都是同一個(gè)服務(wù)器節(jié)點(diǎn)作為 Master。萬(wàn)一 Master 故障了,那么剩下的 Slaves 節(jié)點(diǎn)會(huì)重新發(fā)起 Paxos 流程票選出新的 Master,也就是說(shuō)主節(jié)點(diǎn)是一直存在的,而且是唯一的。
此外,Lamport 在論文中提到的過(guò)一種優(yōu)化網(wǎng)絡(luò)通信的方法:“當(dāng) Leader Proposer 處于穩(wěn)定狀態(tài)時(shí),可以跳過(guò)階段一,直接進(jìn)入階段二”,在 Chubby 中也實(shí)現(xiàn)了這個(gè)優(yōu)化機(jī)制,Leader Proposer 在為多個(gè) Paxos 算法實(shí)例服務(wù)的時(shí)候直接跳過(guò)階段一進(jìn)入階段二,只發(fā)送 accept 請(qǐng)求消息給 Acceptors 集合,將算法從兩階段優(yōu)化成了一階段,大大節(jié)省網(wǎng)絡(luò)帶寬和提升系統(tǒng)性能。
最后,Multi-Paxos 是一個(gè)"腦裂"容錯(cuò)的算法思想,就是說(shuō)當(dāng) Multi-Paxos 流程中因?yàn)榫W(wǎng)絡(luò)問(wèn)題而出現(xiàn)多 Leaders 的情況下,該算法的安全性(safety )約束依然能得到保證,因?yàn)樵谶@種情況下,Multi-Paxos 實(shí)際上是退化成了 Basic Paxos,而 Basic Paxos 天然就支持多 Proposers。
在分布式事務(wù)中,Paxos 算法能夠提供比兩階段提交協(xié)議更加可靠的一致性提交:通過(guò)將提交/放棄事務(wù)的決定從原來(lái)兩階段協(xié)議中單一的協(xié)調(diào)者轉(zhuǎn)移到一個(gè)由 Proposer + Acceptors 組成的集群中。Lamport 曾經(jīng)發(fā)表過(guò)一篇《Consensus on Transaction Commit》的論文,通過(guò)將兩階段提交協(xié)議和基于 Paxos 實(shí)現(xiàn)的分布式提交協(xié)議做對(duì)比,對(duì)基于 Paxos 實(shí)現(xiàn)的提交協(xié)議有非常精彩的論述,感興趣的讀者不妨一讀。
Raft
Raft 算法實(shí)際上是 Multi-Paxos 的一個(gè)變種,通過(guò)新增兩個(gè)約束:
追加日志約束:Raft 中追加節(jié)點(diǎn)的日志必須是串行連續(xù)的,而 Multi-Paxos 中則可以并發(fā)追加日志(實(shí)際上 Multi-Paxos 的并發(fā)也只是針對(duì)日志追加,最后應(yīng)用到內(nèi)部 State Machine 的時(shí)候還是必須保證順序)。 選主限制:Raft 中只有那些擁有最新、最全日志的節(jié)點(diǎn)才能當(dāng)選 Leader 節(jié)點(diǎn),而 Multi-Paxos 由于允許并發(fā)寫(xiě)日志,因此無(wú)法確定一個(gè)擁有最新、最全日志的節(jié)點(diǎn),因此可以選擇任意一個(gè)節(jié)點(diǎn)作為 Leader,但是選主之后必須要把 Leader 節(jié)點(diǎn)的日志補(bǔ)全。
基于這兩個(gè)限制,Raft 算法的實(shí)現(xiàn)比 Multi-Paxos 更加簡(jiǎn)單易懂,不過(guò)由于 Multi-Paxos 的并發(fā)度更高,因此從理論上來(lái)說(shuō) Multi-Paxos 的性能會(huì)更好一些,但是到現(xiàn)在為止業(yè)界也沒(méi)有一份權(quán)威的測(cè)試報(bào)告來(lái)支撐這一觀點(diǎn)。
對(duì)比一下 Multi-Paxos 和 Raft 下集群中可能存在的日志順序:
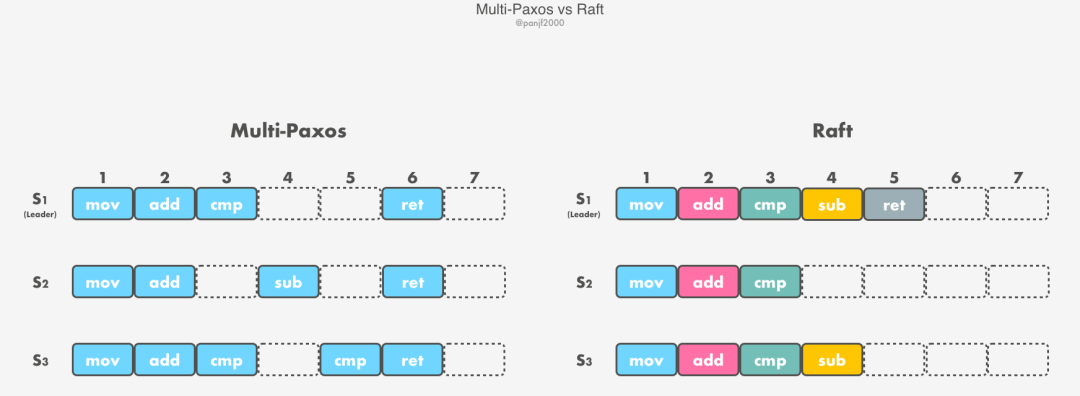
可以看出,Raft 中永遠(yuǎn)滿足這樣一個(gè)約束:follower log 一定會(huì)是 leader log 的子集并且順序一定是連續(xù)的,而 Multi-Paxos 則不一定滿足這個(gè)約束,日志記錄通常是亂序的。
由于 Raft 的核心思想源自 Multi-Paxos,在實(shí)現(xiàn)過(guò)程中做了很多改進(jìn)優(yōu)化,然而萬(wàn)變不離其宗,我相信理解了 Multi-Paxos 之后再去學(xué)習(xí) Raft 會(huì)事半功倍(Raft 在誕生之初也是打著"容易理解"的旗號(hào)來(lái)對(duì)標(biāo) Paxos 的),由于前面已經(jīng)深度剖析過(guò) Paxos 算法的流程和原理了,礙于本文的篇幅所限,這里就不再對(duì) Raft 算法的細(xì)節(jié)進(jìn)行深入探討了,如果有意深入學(xué)習(xí) Raft,可以從 The Raft Consensus Algorithm 處找到相關(guān)的論文、源碼等資料進(jìn)行全面的學(xué)習(xí)。
最后有一些概念要澄清一下,Basic Paxos 是一個(gè)經(jīng)過(guò)了嚴(yán)格數(shù)學(xué)證明的分布式共識(shí)算法,但是由于前文提到的 Basic Paxos 算法應(yīng)用在實(shí)際工程落地中的種種問(wèn)題,現(xiàn)實(shí)中幾乎沒(méi)有直接基于 Basic Paxos 算法實(shí)現(xiàn)的分布式系統(tǒng),絕大多數(shù)都是基于 Multi-Paxos,然而 Multi-Basic 僅僅是一種對(duì) Basic Paxos 的延伸思想而非一個(gè)具體算法,問(wèn)題在于目前業(yè)界并沒(méi)有一個(gè)統(tǒng)一的 Multi-Paxos 實(shí)現(xiàn)標(biāo)準(zhǔn),因此 Multi-Paxos 的工程實(shí)現(xiàn)是建立在一個(gè)未經(jīng)嚴(yán)格證明的前提之上的,工程實(shí)現(xiàn)最終的正確性只能靠實(shí)現(xiàn)方自己去驗(yàn)證,而 Raft 則是一個(gè)具有統(tǒng)一標(biāo)準(zhǔn)實(shí)現(xiàn)的、正確性已經(jīng)過(guò)嚴(yán)格證明的具體算法,因此在分布式系統(tǒng)的工程實(shí)踐中大多數(shù)人往往還是會(huì)選擇 Raft 作為底層的共識(shí)算法。
算法類(lèi)型
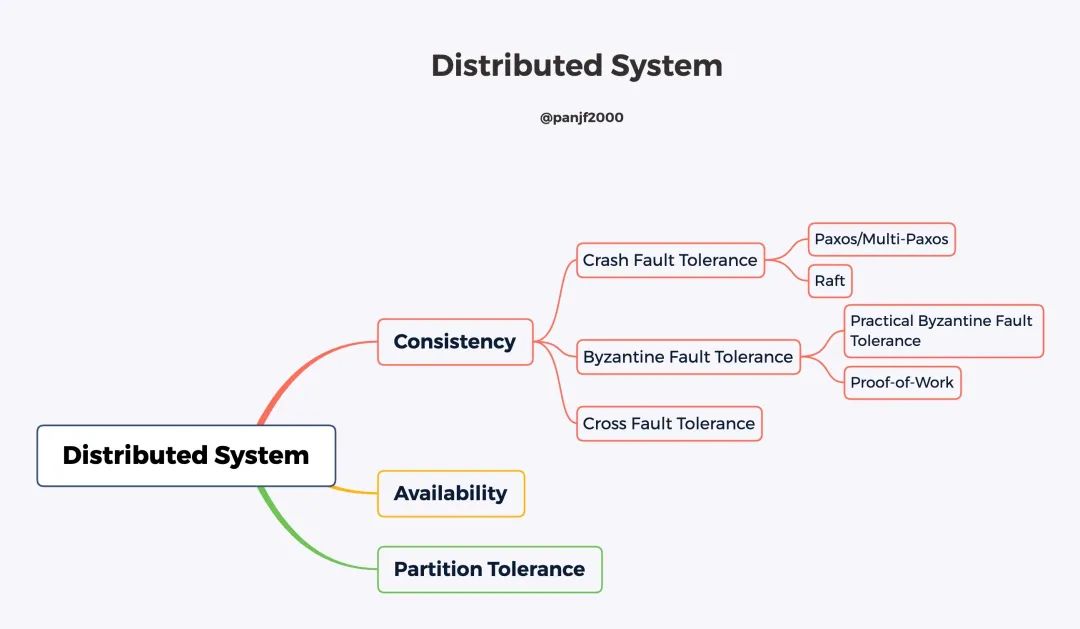
需要特別指出的一點(diǎn)是,根據(jù)解決的場(chǎng)景是否允許拜占庭(Byzantine)錯(cuò)誤,共識(shí)算法可以分為 Crash Fault Tolerance (CFT) 和 Byzantine Fault Tolerance(BFT)兩類(lèi)。
對(duì)于非拜占庭錯(cuò)誤的情況,已經(jīng)存在不少經(jīng)典的算法,包括 Paxos(1990 年)、Raft(2014 年)及其變種等。這類(lèi)容錯(cuò)算法往往性能比較好,處理較快,容忍不超過(guò)一半的故障節(jié)點(diǎn)。
對(duì)于要能容忍拜占庭錯(cuò)誤的情況,包括 PBFT(Practical Byzantine Fault Tolerance,1999 年)為代表的確定性系列算法、PoW(1997 年)為代表的概率算法等。確定性算法一旦達(dá)成共識(shí)就不可逆轉(zhuǎn),即共識(shí)是最終結(jié)果;而概率類(lèi)算法的共識(shí)結(jié)果則是臨時(shí)的,隨著時(shí)間推移或某種強(qiáng)化,共識(shí)結(jié)果被推翻的概率越來(lái)越小,最終成為事實(shí)上結(jié)果。拜占庭類(lèi)容錯(cuò)算法往往性能較差,容忍不超過(guò) 1/3 的故障節(jié)點(diǎn)。
本文主要討論的分布式共識(shí)算法是 CFT 類(lèi)算法,畢竟對(duì)于大多數(shù)分布式系統(tǒng)來(lái)說(shuō),集群節(jié)點(diǎn)和網(wǎng)絡(luò)消息一般都是可控的,系統(tǒng)只會(huì)出現(xiàn)節(jié)點(diǎn)故障而不會(huì)出現(xiàn)像拜占庭錯(cuò)誤那樣偽造的、欺騙性的網(wǎng)絡(luò)消息,在這種場(chǎng)景下,CFT 類(lèi)算法更具有現(xiàn)實(shí)意義;BFT/PBFT 類(lèi)算法更多是用在系統(tǒng)被惡意入侵,故意偽造網(wǎng)絡(luò)消息的場(chǎng)景里。
并發(fā)控制
在分布式事務(wù)中,集群中的每個(gè)服務(wù)器節(jié)點(diǎn)要管理很多資源對(duì)象,每個(gè)節(jié)點(diǎn)必須保證在并發(fā)事務(wù)訪問(wèn)這些資源對(duì)象時(shí),它們能夠始終保持一致性。因此,每個(gè)服務(wù)器節(jié)點(diǎn)需要對(duì)自己的管理的資源對(duì)象應(yīng)用一定的并發(fā)控制機(jī)制。分布式事務(wù)中需要所有服務(wù)器節(jié)點(diǎn)共同保證事務(wù)以串行等價(jià)的的方式執(zhí)行。
也就是說(shuō),如果事務(wù) T 對(duì)某一個(gè)服務(wù)器節(jié)點(diǎn)上的資源對(duì)象 S 的并發(fā)訪問(wèn)在事務(wù) U 之前,那么我們需要保證在所有服務(wù)器節(jié)點(diǎn)上對(duì) S 和其他資源對(duì)象的沖突訪問(wèn),T 始終在 U 之前。
鎖并發(fā)控制
在分布式事務(wù)中,某個(gè)對(duì)象的鎖總是本地持有的(在同一個(gè)服務(wù)器節(jié)點(diǎn)上)。是否加鎖是由本地鎖管理器(Local Lock Manager,LLM)決定的。LLM 決定是滿足客戶端持鎖的請(qǐng)求,還是阻塞客戶端發(fā)起的分布式事務(wù)。但是,事務(wù)在所有服務(wù)器節(jié)點(diǎn)上被提交或者放棄之前,LLM 不能釋放任何鎖。在使用加鎖機(jī)制的并發(fā)控制中,原子提交協(xié)議在進(jìn)行的過(guò)程中資源對(duì)象始終被鎖住,并且是排他鎖,其他事務(wù)無(wú)法染指這些資源對(duì)象。但如果事務(wù)在兩階段提交協(xié)議的階段一就被放棄,則互斥鎖可以提前釋放。
由于不同服務(wù)器節(jié)點(diǎn)上的 LLM 獨(dú)立設(shè)置資源對(duì)象鎖,因此,對(duì)于不同的事務(wù),它們加鎖的順序也可能出現(xiàn)不一致。考慮一個(gè)場(chǎng)景:事務(wù) T 和 U在服務(wù)器 X 和 Y 之間的交錯(cuò)執(zhí)行:
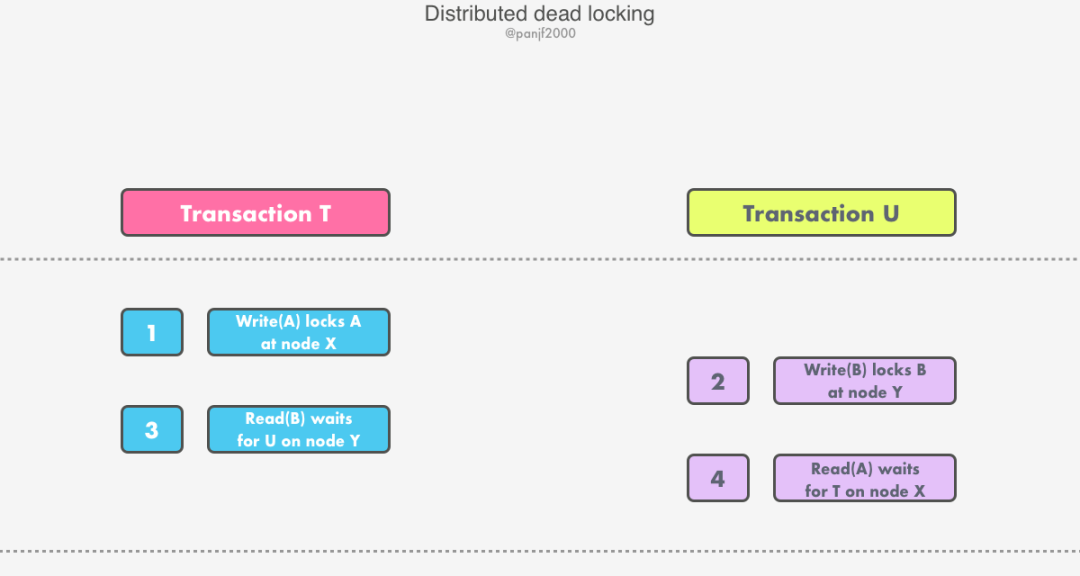
事務(wù) T 鎖住了服務(wù)器節(jié)點(diǎn) X 上的資源對(duì)象 A,做寫(xiě)入操作; 事務(wù) U 鎖住了服務(wù)器節(jié)點(diǎn) Y 上的資源對(duì)象 B,做寫(xiě)入操作; 事務(wù) T 試圖讀取服務(wù)器節(jié)點(diǎn) Y 上的資源對(duì)象 B,此時(shí) B 被事務(wù) U 鎖住,因此 T 等待鎖釋放; 事務(wù) U 試圖讀取服務(wù)器節(jié)點(diǎn) X 上的資源對(duì)象 A,此時(shí) A 被事務(wù) T 鎖住,因此 U 等待鎖釋放。
在服務(wù)器節(jié)點(diǎn) X 上,事務(wù) T 在事務(wù) U 之前;而在服務(wù)器節(jié)點(diǎn) Y 上,事務(wù) U 在事務(wù) T 之前。這種不一致的事務(wù)次序?qū)е铝耸聞?wù)之間的循環(huán)依賴,從而引起分布式死鎖。分布式死鎖需要通過(guò)特定的方法/算法來(lái)檢測(cè)并解除,一旦檢測(cè)到死鎖,則必須放棄其中的某個(gè)事務(wù)來(lái)解除死鎖,然后通知事務(wù)協(xié)調(diào)者,它將會(huì)放棄該事務(wù)所涉及的所有參與者上的事務(wù)。
時(shí)間戳并發(fā)控制
對(duì)于單一服務(wù)器節(jié)點(diǎn)的事務(wù)來(lái)說(shuō),協(xié)調(diào)者在每個(gè)事務(wù)啟動(dòng)時(shí)會(huì)為其分配一個(gè)全局唯一的時(shí)間戳。通過(guò)按照訪問(wèn)資源對(duì)象的事務(wù)時(shí)間戳順序提交資源對(duì)象的版本來(lái)強(qiáng)制保證以事務(wù)執(zhí)行的串行等價(jià)性。在分布式事務(wù)中,協(xié)調(diào)者必須保證每個(gè)事務(wù)都會(huì)附帶全局唯一的時(shí)間戳。全局唯一的時(shí)間戳由事務(wù)訪問(wèn)的第一個(gè)協(xié)調(diào)者發(fā)給客戶端。如果任意一個(gè)服務(wù)器節(jié)點(diǎn)上的資源對(duì)象執(zhí)行了事務(wù)中的一個(gè)操作,那么事務(wù)時(shí)間戳?xí)话l(fā)送給該服務(wù)器節(jié)點(diǎn)上的協(xié)調(diào)者。
分布式事務(wù)中的所有服務(wù)器節(jié)點(diǎn)共同保證事務(wù)以串行等價(jià)的方式執(zhí)行。例如,如果在某服務(wù)器節(jié)點(diǎn)上,由事務(wù) U 訪問(wèn)的資源對(duì)象版本在事務(wù) T 訪問(wèn)之后提交;而在另一個(gè)服務(wù)器節(jié)點(diǎn)上,事務(wù) T 和事務(wù) U 又訪問(wèn)了同一個(gè)資源對(duì)象,那么它們也必須按照相同的次序提交資源對(duì)象。為了保證所有服務(wù)器節(jié)點(diǎn)上的事務(wù)執(zhí)行的相同順序,協(xié)調(diào)者必須就時(shí)間戳排序達(dá)成一致。時(shí)間戳是一個(gè)二元組 < 本地時(shí)間戳,服務(wù)器 ID > 對(duì)。在時(shí)間戳的比較排序過(guò)程中,首先比較本地時(shí)間戳,然后再比較服務(wù)器 ID。
一個(gè)可靠的時(shí)間戳并發(fā)控制應(yīng)該保證即使各個(gè)服務(wù)器節(jié)點(diǎn)之間的本地時(shí)間不同步,也能保證事務(wù)之間的相同順序。但是考慮到效率,各個(gè)協(xié)調(diào)者之間的時(shí)間戳還是最好還是要求大致同步。這樣的話,事務(wù)之間的順序通常與它們實(shí)際開(kāi)始的時(shí)間順序相一致。可以利用一些本地物理時(shí)鐘同步方法來(lái)保證時(shí)間戳的大致同步。
如果決定利用時(shí)間戳機(jī)制進(jìn)行分布式事務(wù)的并發(fā)控制,那么還需要通過(guò)某些方法來(lái)解決事務(wù)沖突問(wèn)題。如果為了解決沖突需要放棄某個(gè)事務(wù)時(shí),相應(yīng)的協(xié)調(diào)者會(huì)收到通知,并且它將在所有的參與者上放棄該事務(wù)。這樣,如果事務(wù)能夠堅(jiān)持到客戶端發(fā)起提交請(qǐng)求命令的那個(gè)時(shí)候,那么這個(gè)事務(wù)就總能被提交。因此在兩階段提交協(xié)議中,正常情況下參與者都會(huì)同意提交,唯一一種不同意提交的情況是參與者在事務(wù)執(zhí)行過(guò)程中曾經(jīng)崩潰過(guò)。
樂(lè)觀并發(fā)控制
加鎖機(jī)制這一類(lèi)悲觀并發(fā)控制有許多明顯的缺陷:
鎖的維護(hù)帶來(lái)了很多新的開(kāi)銷(xiāo)。這些開(kāi)銷(xiāo)在不支持對(duì)共享數(shù)據(jù)并發(fā)訪問(wèn)的系統(tǒng)中是不存在的。即使是只讀事務(wù)(如查詢),就算這一類(lèi)事務(wù)不會(huì)改變數(shù)據(jù)的完整性,卻仍然需要利用鎖來(lái)保證數(shù)據(jù)在讀取過(guò)程中不會(huì)被其他事務(wù)修改,然而鎖卻只在最極端的情況下才會(huì)發(fā)揮作用。 鎖機(jī)制非常容易引發(fā)死鎖。預(yù)防死鎖會(huì)嚴(yán)重降低并發(fā)度,因此必須利用超時(shí)或者死鎖檢測(cè)來(lái)解除死鎖,但這些死鎖解除方案對(duì)于交互式的程序來(lái)說(shuō)并不是很理想。 鎖周期過(guò)長(zhǎng)。為了避免事務(wù)的連鎖(雪崩)放棄,鎖必須保留到事務(wù)結(jié)束之時(shí)才能釋放,這再一次嚴(yán)重降低了系統(tǒng)的并發(fā)度。
由于鎖這一類(lèi)的悲觀并發(fā)控制有上述的種種弊端,因此研究者們提出了另一種樂(lè)觀并發(fā)控制的機(jī)制,以求規(guī)避鎖機(jī)制的天然缺陷,研究者們發(fā)現(xiàn)這樣的一個(gè)現(xiàn)象:在大多數(shù)應(yīng)用中兩個(gè)客戶端事務(wù)訪問(wèn)同一個(gè)資源對(duì)象的可能性其實(shí)很低,事務(wù)總是能夠成功執(zhí)行,就好像事務(wù)之間不存在沖突一樣。
所以事務(wù)的樂(lè)觀并發(fā)控制的基本思路就是:各個(gè)并發(fā)事務(wù)只有在執(zhí)行完成之后并且發(fā)出 closeTransaction 請(qǐng)求時(shí),再去檢測(cè)是否有沖突,如果確實(shí)存在沖突,那么就放棄一些事務(wù),然后讓客戶端重新啟動(dòng)這些事務(wù)進(jìn)行重試。
在樂(lè)觀并發(fā)控制中,每個(gè)事務(wù)在提交之前都必須進(jìn)行驗(yàn)證。事務(wù)在驗(yàn)證開(kāi)始時(shí)首先要附加一個(gè)事務(wù)號(hào),事務(wù)的串行化就是根據(jù)這些事務(wù)號(hào)的順序?qū)崿F(xiàn)的。分布式事務(wù)的驗(yàn)證由一組獨(dú)立的服務(wù)器節(jié)點(diǎn)共同完成,每個(gè)服務(wù)器節(jié)點(diǎn)驗(yàn)證訪問(wèn)自己資源對(duì)象的事務(wù)。這些驗(yàn)證在兩階段提交協(xié)議的第一個(gè)階段進(jìn)行。
關(guān)于分布式事務(wù)的并發(fā)控制就暫時(shí)介紹到這里,如果想要繼續(xù)深入學(xué)習(xí)更多并發(fā)控制的細(xì)節(jié),可以深入閱讀《分布式系統(tǒng):概念與設(shè)計(jì)》、《數(shù)據(jù)庫(kù)系統(tǒng)實(shí)現(xiàn)》和《數(shù)據(jù)庫(kù)系統(tǒng)概念》等書(shū)籍或者其他資料。
總結(jié)
本文通過(guò)講解 BASE 原則、兩階段原子提交協(xié)議、三階段原子提交協(xié)議、Paxos/Multi-Paxos 分布式共識(shí)算法的原理與證明、Raft 分布式共識(shí)算法和分布式事務(wù)的并發(fā)控制等內(nèi)容,為讀者全面而又深入地講解分析了分布式事務(wù)/系統(tǒng)的底層核心原理,特別是通過(guò)對(duì)原子提交協(xié)議中的 2PC/3PC 的闡述和分析,以及對(duì)分布式共識(shí)算法 Paxos 的原理剖析和正確性的證明,最后還有對(duì)分布式事務(wù)中幾種并發(fā)控制的介紹,相信能夠讓讀者對(duì)分布式事務(wù)/系統(tǒng)底層的一致性和并發(fā)控制原理有一個(gè)深刻的認(rèn)知,對(duì)以后學(xué)習(xí)和理解分布式系統(tǒng)大有裨益。
本文不僅僅是簡(jiǎn)單地介紹分布式事務(wù)和分布式系統(tǒng)的底層原理,更是在介紹原理的同時(shí),通過(guò)層層遞進(jìn)的方式引導(dǎo)讀者去真正地理解分布式系統(tǒng)的底層原理和設(shè)計(jì)思路,而非讓讀者死記硬背一些概念,所以希望通過(guò)這篇拋磚引玉的文章,能夠?qū)Ρ疚淖x者在以后學(xué)習(xí)、操作甚至是設(shè)計(jì)分布式系統(tǒng)以及分布式事務(wù)時(shí)的思路有所開(kāi)拓。
參考&延伸
ACID Eventual consistency Atomic commit A Two-Phase Commit Protocol and its Performance The PartTime Parliament Paxos Made Simple Fast Paxos The Performance of Paxos and Fast Paxos Paxos Made Live - An Engineering Perspective Paxos (computer science) The Chubby lock service for loosely-coupled distributed systems Consensus on Transaction Commit Life beyond Distributed Transactions: an Apostate’s Opinion In Search of an Understandable Consensus Algorithm Paxos lecture (Raft user study) Distributed Systems: Concepts and Design How to Build a Highly Available System Using Consensus 數(shù)學(xué)歸納法 共識(shí)算法 Distributed Transaction Processing: The XA Specification
References
[1] DTP Model: http://pubs.opengroup.org/onlinepubs/009680699/toc.pdf[2] 《The PartTime Parliament》: https://lamport.azurewebsites.net/pubs/lamport-paxos.pdf[3] 《Paxos Made Simple》: https://lamport.azurewebsites.net/pubs/paxos-simple.pdf[4] 歸約: https://zh.wikipedia.org/wiki/%E6%AD%B8%E7%B4%84[5] 《The PartTime Parliament》: https://lamport.azurewebsites.net/pubs/lamport-paxos.pdf[6] 《The PartTime Parliament》: https://lamport.azurewebsites.net/pubs/lamport-paxos.pdf[7] 《Paxos Made Simple》: https://lamport.azurewebsites.net/pubs/paxos-simple.pdf[8] 《Paxos Made Simple》: https://lamport.azurewebsites.net/pubs/paxos-simple.pdf[9] 《Paxos Made Live - An Engineering Perspective》: https://read.seas.harvard.edu/~kohler/class/08w-dsi/chandra07paxos.pdf[10] Paxos lecture (Raft user study): https://www.youtube.com/watch?v=JEpsBg0AO6o[11] 《Paxos Made Simple》: https://lamport.azurewebsites.net/pubs/paxos-simple.pdf[12] 《Consensus on Transaction Commit》: https://lamport.azurewebsites.net/video/consensus-on-transaction-commit.pdf[13] The Raft Consensus Algorithm: https://raft.github.io[14] ACID: https://en.wikipedia.org/wiki/ACID[15] Eventual consistency: https://en.wikipedia.org/wiki/Eventual_consistency[16] Atomic commit: https://en.wikipedia.org/wiki/Atomic_commit[17] A Two-Phase Commit Protocol and its Performance : https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=558282[18] The PartTime Parliament: https://lamport.azurewebsites.net/pubs/lamport-paxos.pdf[19] Paxos Made Simple: https://lamport.azurewebsites.net/pubs/paxos-simple.pdf[20] Fast Paxos: https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/tr-2005-112.pdf[21] The Performance of Paxos and Fast Paxos: https://arxiv.org/pdf/1308.1358.pdf[22] Paxos Made Live - An Engineering Perspective: https://read.seas.harvard.edu/~kohler/class/08w-dsi/chandra07paxos.pdf[23] Paxos (computer science): https://en.wikipedia.org/wiki/Paxos_(computer_science)[24] The Chubby lock service for loosely-coupled distributed systems: https://static.googleusercontent.com/media/research.google.com/zh-CN//archive/chubby-osdi06.pdf[25] Consensus on Transaction Commit: https://lamport.azurewebsites.net/video/consensus-on-transaction-commit.pdf[26] Life beyond Distributed Transactions: an Apostate’s Opinion: https://www.ics.uci.edu/~cs223/papers/cidr07p15.pdf[27] In Search of an Understandable Consensus Algorithm: https://raft.github.io/raft.pdf[28] Paxos lecture (Raft user study): https://www.youtube.com/watch?v=JEpsBg0AO6o[29] Distributed Systems: Concepts and Design: https://ce.guilan.ac.ir/images/other/soft/distribdystems.pdf[30] How to Build a Highly Available System Using Consensus: https://www.microsoft.com/en-us/research/uploads/prod/1996/10/Acrobat-58-Copy.pdf[31] 數(shù)學(xué)歸納法: https://zh.wikipedia.org/wiki/%E6%95%B0%E5%AD%A6%E5%BD%92%E7%BA%B3%E6%B3%95[32] 共識(shí)算法: https://yeasy.gitbook.io/blockchain_guide/04_distributed_system/algorithms[33] Distributed Transaction Processing: The XA Specification: https://pubs.opengroup.org/onlinepubs/009680699/toc.pdf
— 本文結(jié)束 —

● 漫談設(shè)計(jì)模式在 Spring 框架中的良好實(shí)踐
關(guān)注我,回復(fù) 「加群」 加入各種主題討論群。
對(duì)「服務(wù)端思維」有期待,請(qǐng)?jiān)谖哪c(diǎn)個(gè)在看
喜歡這篇文章,歡迎轉(zhuǎn)發(fā)、分享朋友圈