
正態(tài)分布對(duì)數(shù)據(jù)分析很重要!
轉(zhuǎn)自:機(jī)器之心
什么是概率分布?
什么是正態(tài)分布?
為什么變量如此青睞正態(tài)分布
如何用 Python 查看查看特征的分布?
其它分布變一變也能近似正態(tài)分布
什么是概率分布?
如果我們想準(zhǔn)確地預(yù)測變量,那么首先我們要了解目標(biāo)變量的基本行為。 我們先要確定目標(biāo)變量可能輸出的結(jié)果,以及這個(gè)可能的輸出結(jié)果是離散值(孤立值)還是連續(xù)值(無限值)。簡單點(diǎn)解釋就是,如果我們要評(píng)估骰子的行為,那么第一步是要知道它可以取 1 到 6 之間的任一整數(shù)值(離散值)。 然后下一步是開始為事件(值)分配概率。因此,如果一個(gè)值不會(huì)出現(xiàn),則概率為 0%。
什么是正態(tài)概率分布?
平均值——樣本中所有點(diǎn)的平均值。
標(biāo)準(zhǔn)差——表示數(shù)據(jù)集與樣本均值的偏離程度。
為什么這么多變量近似正態(tài)分布?
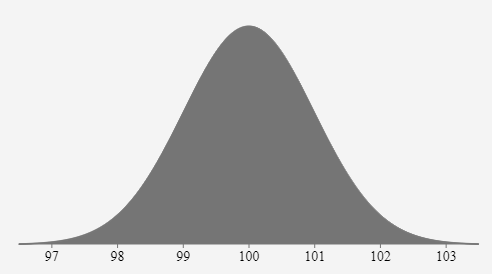
平均值是曲線的中心。這是曲線的最高點(diǎn),因?yàn)榇蠖鄶?shù)點(diǎn)都在平均值附近; 曲線兩側(cè)點(diǎn)的數(shù)量是相等的。曲線中心的點(diǎn)數(shù)量最多; 曲線下的面積是變量能取的所有值的概率和; 因此曲線下面的總面積為 100%。
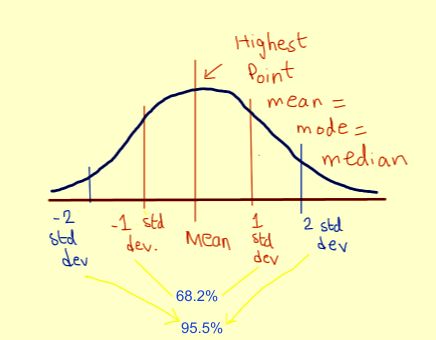
約有 68.2% 的點(diǎn)落在 ±1 個(gè)標(biāo)準(zhǔn)差的范圍內(nèi) 約有 95.5% 的點(diǎn)落在 ±2 個(gè)標(biāo)準(zhǔn)差的范圍內(nèi) 約有 99.7% 的點(diǎn)落在 ±3 個(gè)標(biāo)準(zhǔn)差的范圍內(nèi)。

如果你用計(jì)算好的概率密度函數(shù)繪制概率分布曲線,那么給定范圍的曲線下的面積就描述了目標(biāo)變量在該范圍內(nèi)的概率。 概率分布函數(shù)是根據(jù)多個(gè)參數(shù)(如變量的平均值或標(biāo)準(zhǔn)差)計(jì)算得到的。 我們可以用概率分布函數(shù)求出隨機(jī)變量在一個(gè)范圍內(nèi)取值的相對(duì)概率。舉個(gè)例子,我們可以記錄股票的日收益,把它們分到合適的桶中,然后找出未來收益概率在 20~40% 的股票。 標(biāo)準(zhǔn)差越大,樣本波動(dòng)越大。
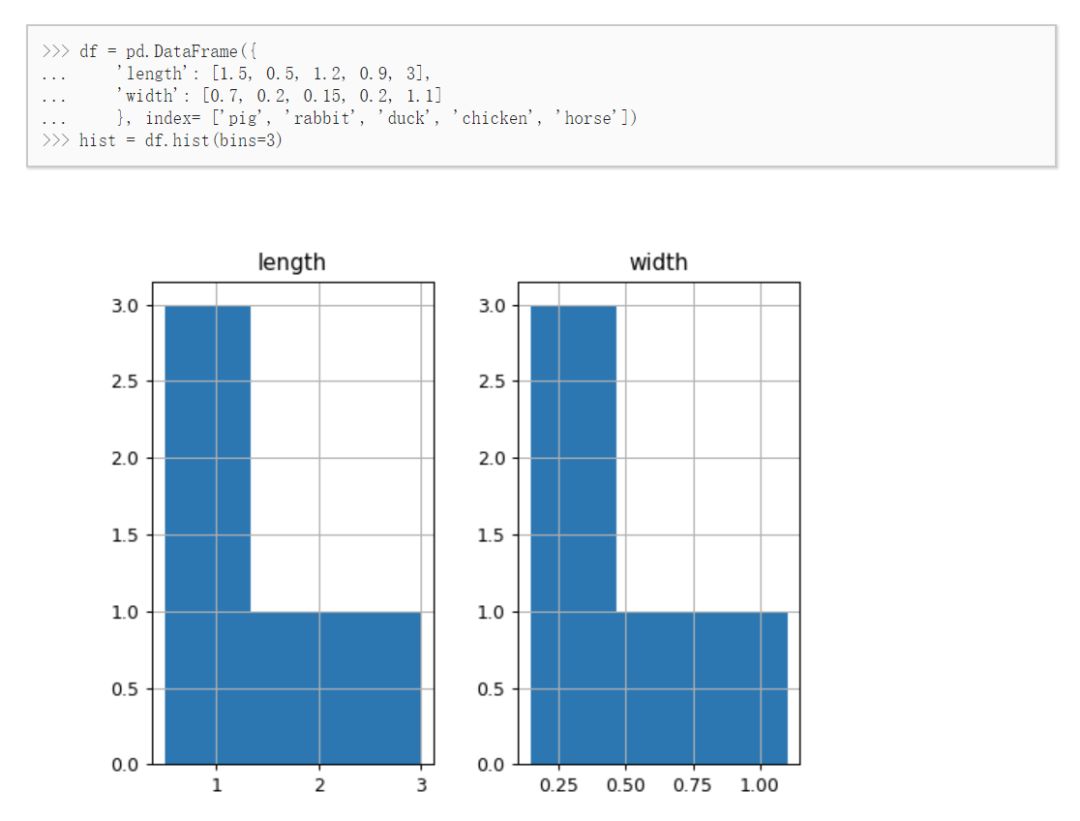
如何用 Python 找出特征分布?
AxB 服從正態(tài)分布; A+B 服從正態(tài)分布。
變量還是乖乖地變成正態(tài)分布吧
Z 分?jǐn)?shù) 計(jì)算平均值 計(jì)算標(biāo)準(zhǔn)差

scipy.stats.boxcox(x,?lmbda=None,?alpha=None)
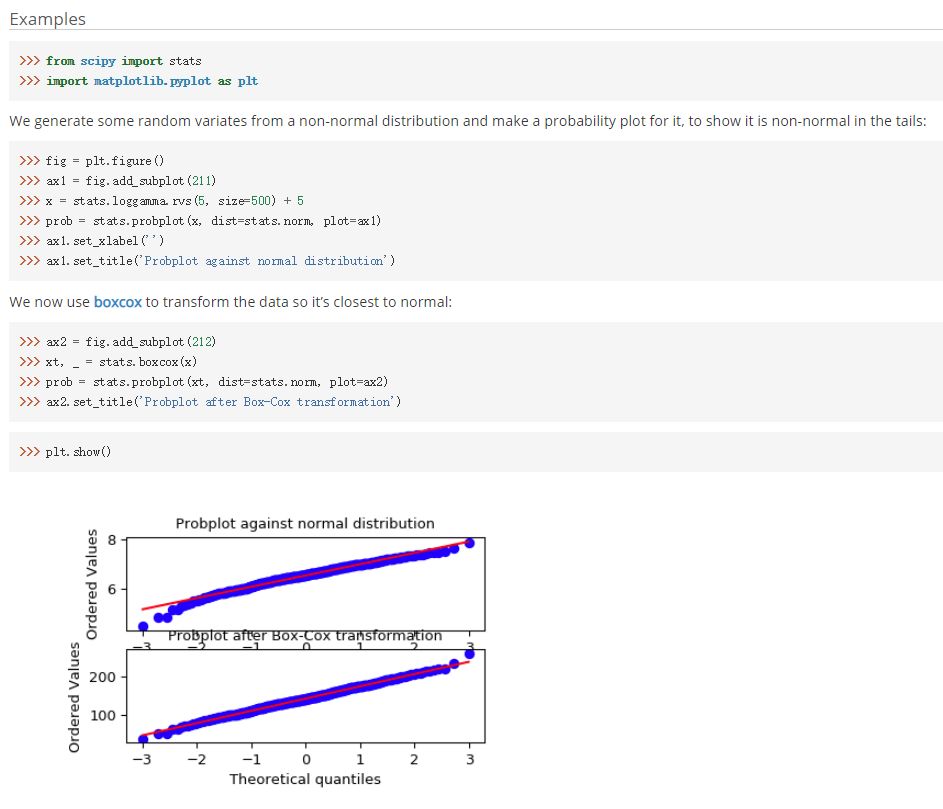
sklearn.preprocessing.PowerTransformer(method=’yeo-johnson’,?standardize=True,?copy=True)

推薦閱讀
歡迎長按掃碼關(guān)注「數(shù)據(jù)管道」
評(píng)論
圖片
表情