
TB 級微服務(wù)海量日志監(jiān)控平臺

-? ? ?前言? ? -
本文主要介紹怎么使用 ELK Stack 幫助我們打造一個(gè)支撐起日產(chǎn) TB 級的日志監(jiān)控系統(tǒng)。在企業(yè)級的微服務(wù)環(huán)境中,跑著成百上千個(gè)服務(wù)都算是比較小的規(guī)模了。在生產(chǎn)環(huán)境上,日志扮演著很重要的角色,排查異常需要日志,性能優(yōu)化需要日志,業(yè)務(wù)排查需要業(yè)務(wù)等等。
-? ? ?我們的解決方案? ? -
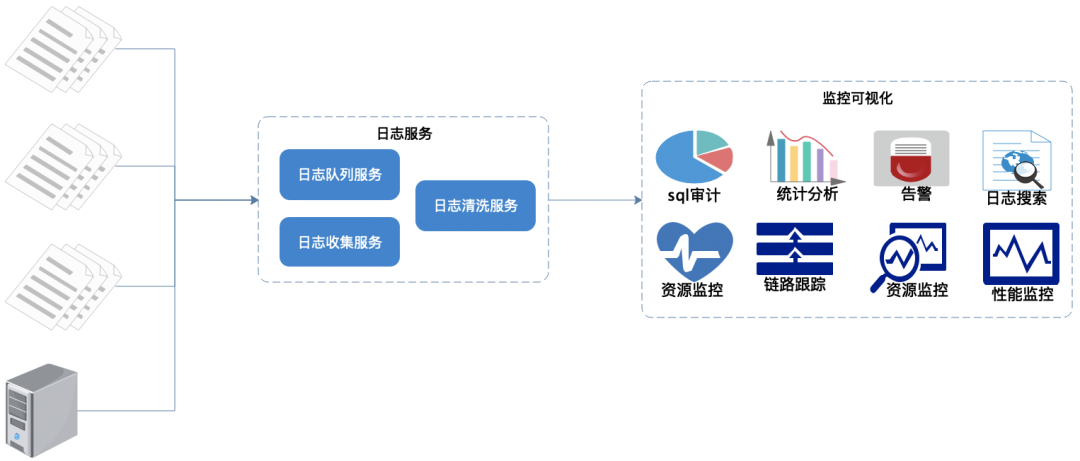
日志統(tǒng)一收集、過濾清洗。 生成可視化界面、監(jiān)控,告警,日志搜索。
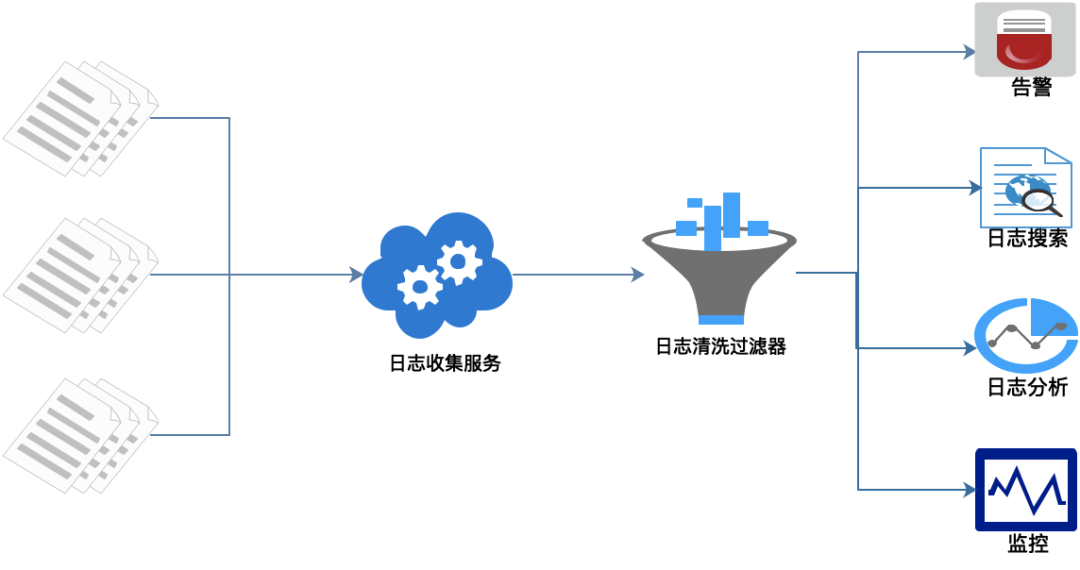
功能流程概覽如上圖:
在每個(gè)服務(wù)節(jié)點(diǎn)上埋點(diǎn),實(shí)時(shí)采集相關(guān)日志。 統(tǒng)一日志收集服務(wù)、過濾、清洗日志后生成可視化界面、告警功能。
-? ? ?我們的架構(gòu)? ? -
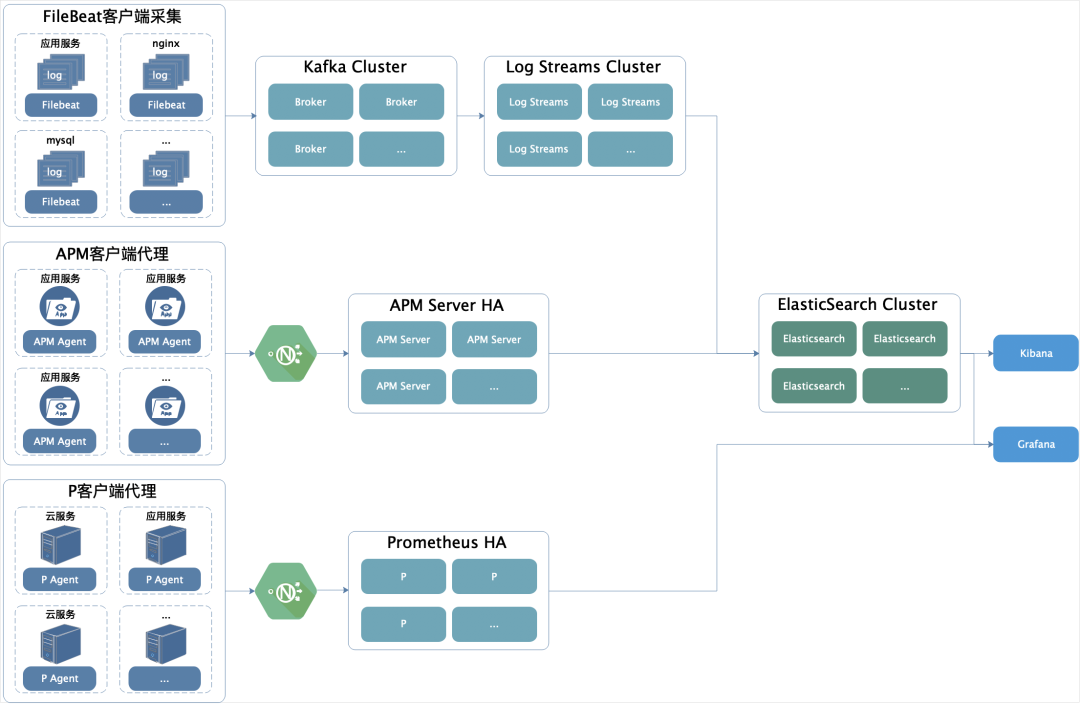
界面化配置日志采集。默認(rèn) Error 級別的日志全量采集。 以錯誤時(shí)間點(diǎn)為中心,在流處理中開窗,輻射上下可配的 N 時(shí)間點(diǎn)采集非 Error 級別日志,默認(rèn)只采 info 級別。 每個(gè)服務(wù)可配 100 個(gè)關(guān)鍵日志,默認(rèn)關(guān)鍵日志全量采集。 在慢 SQL 的基礎(chǔ)上,按業(yè)務(wù)分類配置不同的耗時(shí)再次過濾。 按業(yè)務(wù)需求實(shí)時(shí)統(tǒng)計(jì)業(yè)務(wù) SQL,比如:高峰期階段,統(tǒng)計(jì)一小時(shí)內(nèi)同類業(yè)務(wù) SQL 的查詢頻率。可為 DBA 提供優(yōu)化數(shù)據(jù)庫的依據(jù),如按查詢的 SQL 創(chuàng)建索引。 高峰時(shí)段按業(yè)務(wù)類型的權(quán)重指標(biāo)、日志等級指標(biāo)、每個(gè)服務(wù)在一個(gè)時(shí)段內(nèi)日志最大限制量指標(biāo)、時(shí)間段指標(biāo)等動態(tài)清洗過濾日志。 根據(jù)不同的時(shí)間段動態(tài)收縮時(shí)間窗口。 日志索引生成規(guī)則:按服務(wù)生成的日志文件規(guī)則生成對應(yīng)的 index,比如:某個(gè)服務(wù)日志分為:debug、info、error、xx_keyword,那么生成的索引也是 debug、info、error、xx_keyword 加日期作后綴。這樣做的目的是為研發(fā)以原習(xí)慣性地去使用日志。
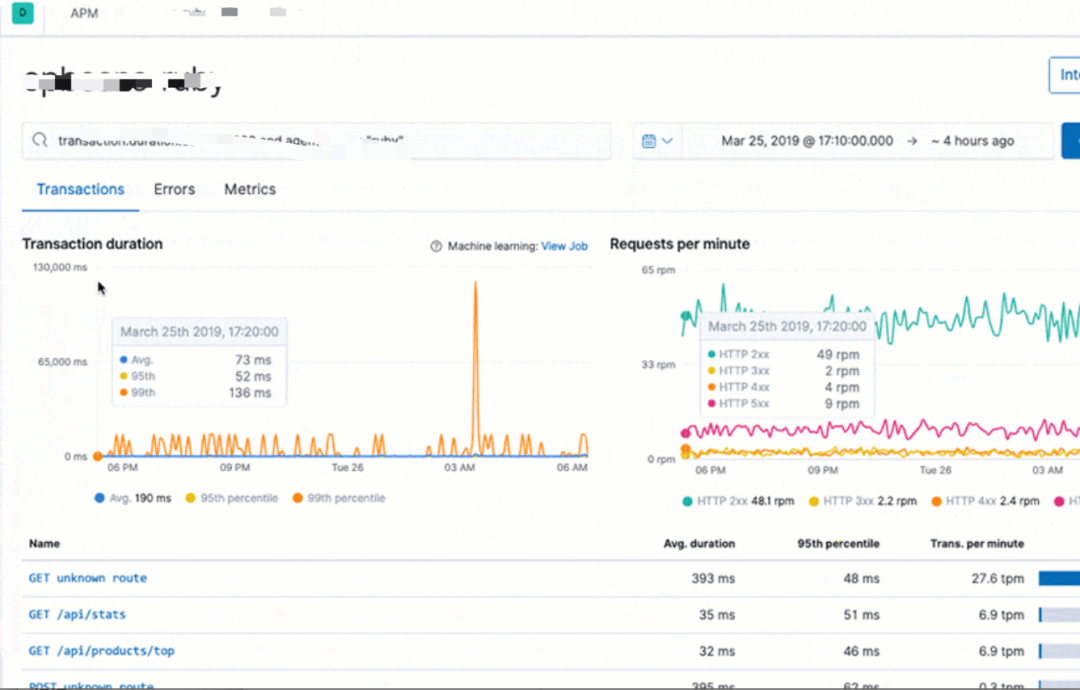
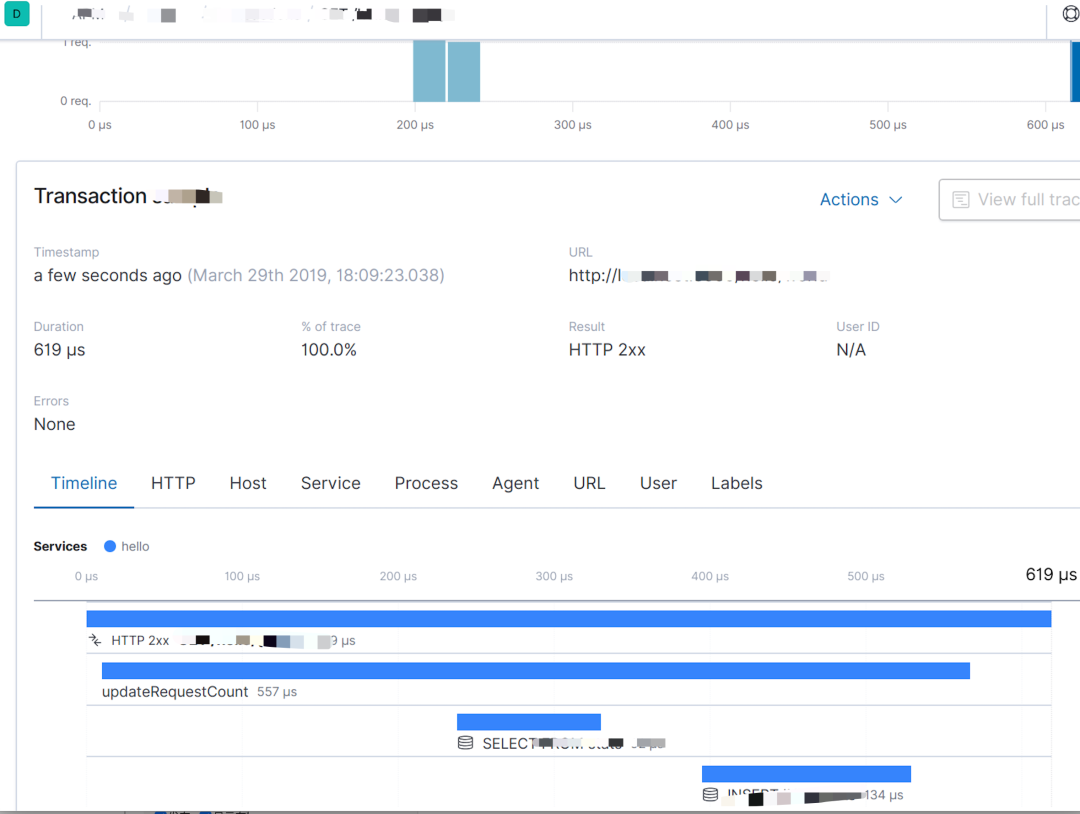
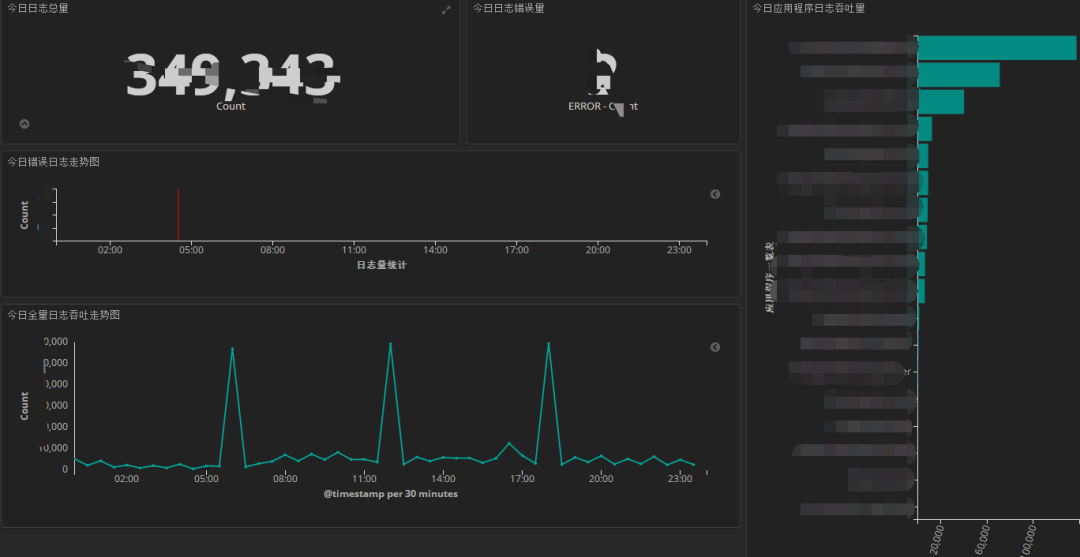
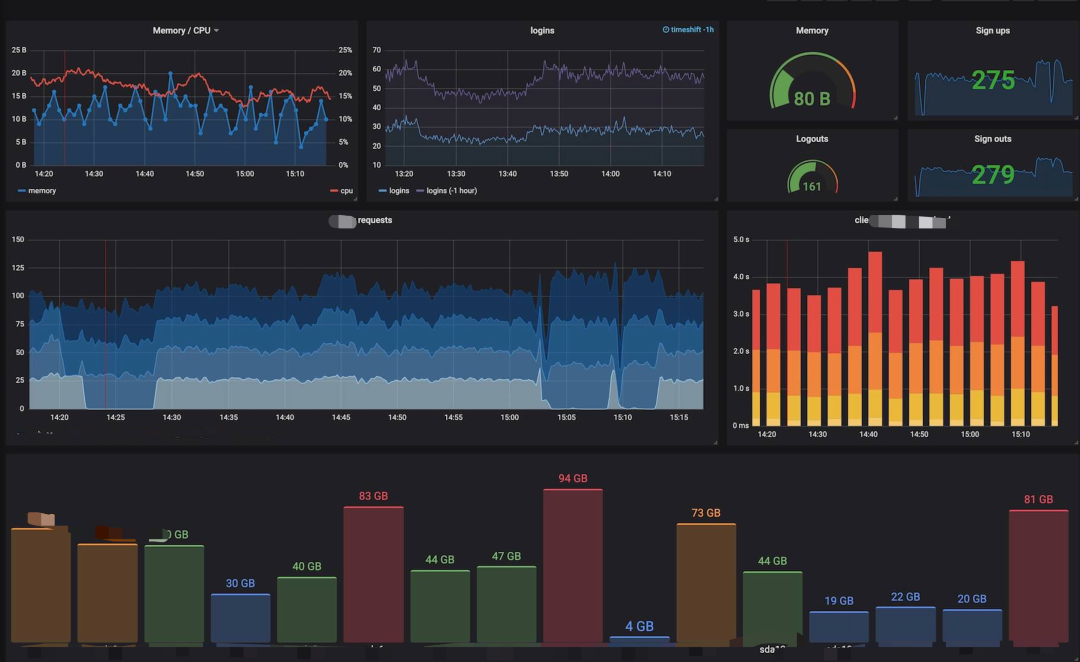
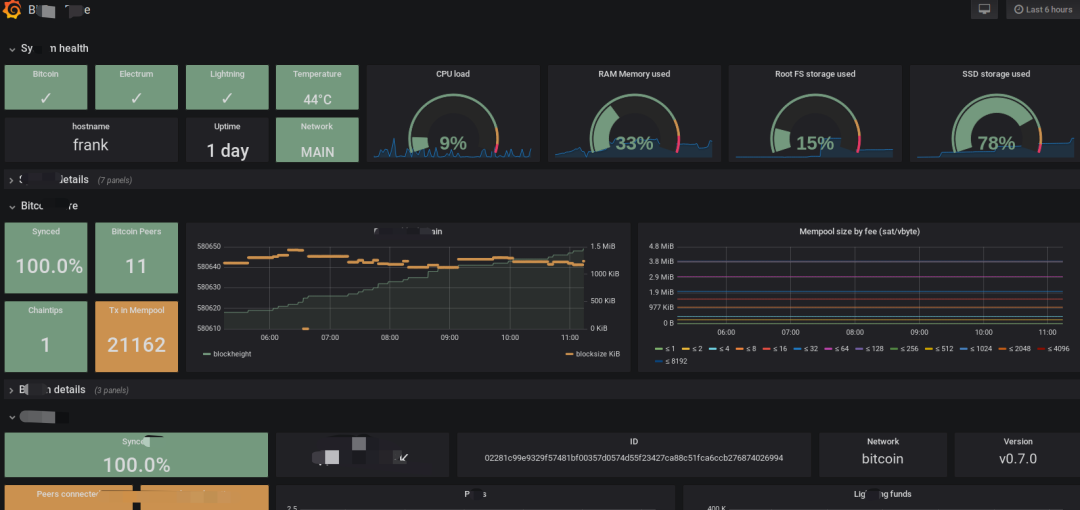
-? ? ?日志可視化? ? -
我們的日志可視化如下圖:

作者:非洲羚羊?
來源:www.cnblogs.com/dengbangpang/p/12961593.html

評論
圖片
表情