
微服務(wù)海量日志監(jiān)控平臺
不點藍字關(guān)注,我們哪來故事?

正文如下
目錄
背景
我們的解決方案
功能流程概覽
我們的架構(gòu)
日志可視化
前面幾章蜻蜓點水的介紹了elasticsearch、apm相關(guān)的內(nèi)容。本片主要介紹怎么使用ELK Stack幫助我們打造一個支撐起日產(chǎn)TB級的日志監(jiān)控系統(tǒng)
背景
在企業(yè)級的微服務(wù)環(huán)境中,跑著成百上千個服務(wù)都算是比較小的規(guī)模了。在生產(chǎn)環(huán)境上,日志扮演著很重要的角色,排查異常需要日志,性能優(yōu)化需要日志,業(yè)務(wù)排查需要業(yè)務(wù)等等。然而在生產(chǎn)上跑著成百上千個服務(wù),每個服務(wù)都只會簡單的本地化存儲,當需要日志協(xié)助排查問題時,很難找到日志所在的節(jié)點。也很難挖掘業(yè)務(wù)日志的數(shù)據(jù)價值。那么將日志統(tǒng)一輸出到一個地方集中管理,然后將日志處理化,把結(jié)果輸出成運維、研發(fā)可用的數(shù)據(jù)是解決日志管理、協(xié)助運維的可行方案,也是企業(yè)迫切解決日志的需求。
我們的解決方案
通過上面的需求我們推出了日志監(jiān)控系統(tǒng)。
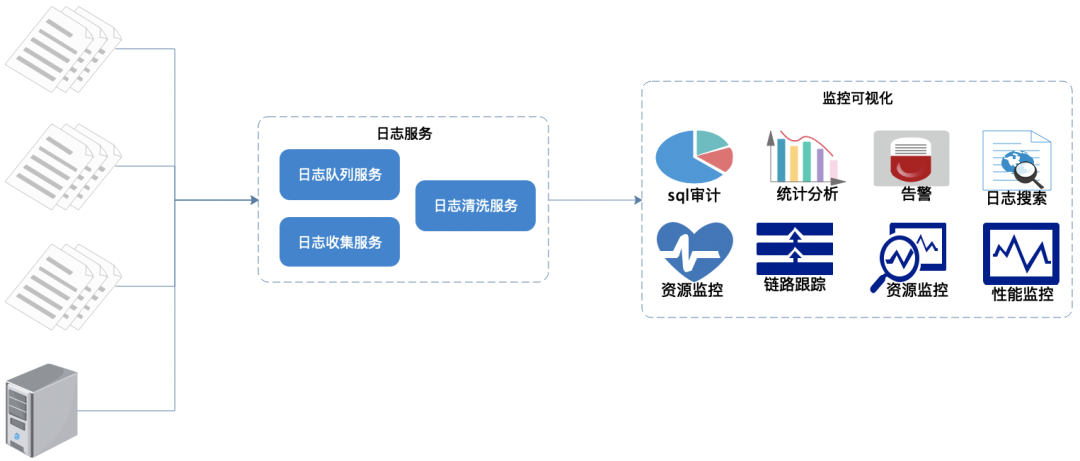
日志統(tǒng)一收集、過濾清洗。
生成可視化界面、監(jiān)控,告警,日志搜索。
功能流程概覽
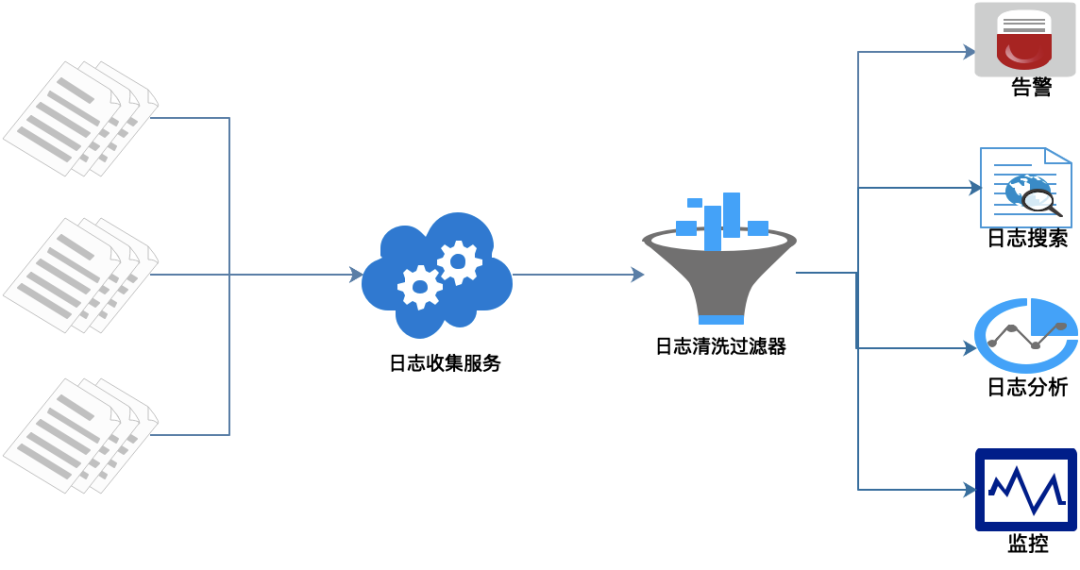
在每個服務(wù)節(jié)點上埋點,實時采集相關(guān)日志。
統(tǒng)一日志收集服務(wù)、過濾、清洗日志后生成可視化界面、告警功能。
我們的架構(gòu)

日志文件采集端我們使用filebeat,運維通過我們的后臺管理界面化配置,每個機器對應(yīng)一個filebeat,每個filebeat日志對應(yīng)的topic可以是一對一、多對一,根據(jù)日常的日志量配置不同的策略。除了采集業(yè)務(wù)服務(wù)日志外,我們還收集了mysql的慢查詢?nèi)罩竞湾e誤日志,還有別的第三方服務(wù)日志,如:nginx等。最后結(jié)合我們的自動化發(fā)布平臺,自動發(fā)布并啟動每一個filebeat進程。
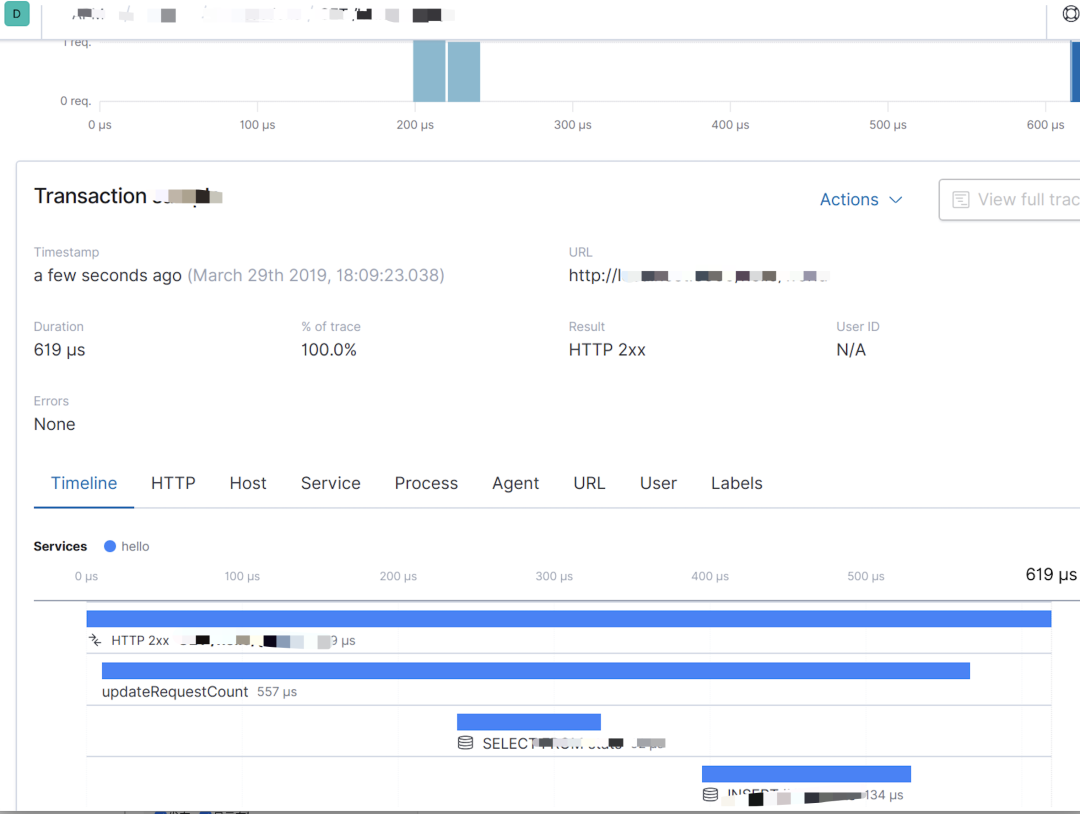
調(diào)用棧、鏈路、進程監(jiān)控指標我們使用的代理方式:Elastic APM,這樣對于業(yè)務(wù)側(cè)的程序無需任何改動。對于已經(jīng)在運營中的業(yè)務(wù)系統(tǒng)來說,為了加入監(jiān)控而需要改動代碼,那是不可取的,也是無法接受的。Elastic APM可以幫我們收集http接口的調(diào)用鏈路、內(nèi)部方法調(diào)用棧、使用的sql、進程的cpu、內(nèi)存使用指標等。可能有人會有疑問,用了Elastic APM,其它日志基本都可以不用采集了。還要用filebeat干嘛?是的,Elastic APM采集的信息確實能幫我們定位80%以上的問題,但是它不是所有的語言都支持的比如:C。其二、它無法幫你采集你想要的非error日志和所謂的關(guān)鍵日志,比如:某個接口調(diào)用時出了錯,你想看出錯時間點的前后日志;還有打印業(yè)務(wù)相關(guān)方便做分析的日志。其三、自定義的業(yè)務(wù)異常,該異常屬于非系統(tǒng)異常,屬于業(yè)務(wù)范疇,APM會把這類異常當成系統(tǒng)異常上報,如果你后面對系統(tǒng)異常做告警,那這些異常將會干擾告警的準確度,你也不能去過濾業(yè)務(wù)異常,因為自定義的業(yè)務(wù)異常種類也不少。
同時我們對agent進行了二開。采集更詳細的gc、堆棧、內(nèi)存、線程信息。
服務(wù)器采集我們采用普羅米修斯。
由于我們是saas服務(wù)化,服務(wù)N多,很多的服務(wù)日志做不到統(tǒng)一規(guī)范化,這也跟歷史遺留問題有關(guān),一個與業(yè)務(wù)系統(tǒng)無關(guān)的系統(tǒng)去間接或直接地去對接已有的業(yè)務(wù)系統(tǒng),為了適配自己而讓其更改代碼,那是推不動的。牛逼的設(shè)計是讓自己去兼容別人,把對方當成攻擊自己的對象。很多日志是沒有意義的,比如:開發(fā)過程中為了方便排查跟蹤問題,在if else里打印只是有標志性的日志,代表是走了if代碼塊還是else代碼塊。甚至有些服務(wù)還打印著debug級別的日志。在成本、資源的有限條件下,所有所有的日志是不現(xiàn)實的,即使資源允許,一年下來將是一比很大的開銷。所以我們采用了過濾、清洗、動態(tài)調(diào)整日志優(yōu)先級采集等方案。首先把日志全量采集到kafka集群中,設(shè)定一個很短的有效期。我們目前設(shè)置的是一個小時,一個小時的數(shù)據(jù)量,我們的資源暫時還能接受。
Log Streams是我們的日志過濾、清洗的流處理服務(wù)。為什么還要ETL過濾器呢?因為我們的日志服務(wù)資源有限,但不對啊,原來的日志分散在各各服務(wù)的本地存儲介質(zhì)上也是需要資源的哈。現(xiàn)在我們也只是匯集而已哈,收集上來后,原來在各服務(wù)上的資源就可以釋放掉日志占用的部分資源了呀。沒錯,這樣算確實是把原來在各服務(wù)上的資源化分到了日志服務(wù)資源上來而已,并沒有增加資源。不過這只是理論上的,在線上的服務(wù),資源擴大容易,收縮就沒那么容易了,實施起來極其困難。所以短時間內(nèi)是不可能在各服務(wù)上使用的日志資源化分到日志服務(wù)上來的。這樣的話,日志服務(wù)的資源就是當前所有服務(wù)日志使用資源的量。隨存儲的時間越長,資源消耗越大。如果解決一個非業(yè)務(wù)或非解決不可的問題,在短時間內(nèi)需要投入的成本大于解決當前問題所帶來收益的話,我想,在資金有限的情況下,沒有哪個領(lǐng)導(dǎo)、公司愿意采納的方案。所以從成本上考慮,我們在Log Streams服務(wù)引入了過濾器,過濾沒有價值的日志數(shù)據(jù),從而減少了日志服務(wù)使用的資源成本。技術(shù)我們采用Kafka Streams作為ETL流處理。通過界面化配置實現(xiàn)動態(tài)過濾清洗的規(guī)則:
界面化配置日志采集。默認error級別的日志全量采集
以錯誤時間點為中心,在流處理中開窗,輻射上下可配的N時間點采集非error級別日志,默認只采info級別
每個服務(wù)可配100個關(guān)鍵日志,默認關(guān)鍵日志全量采集
在慢sql的基礎(chǔ)上,按業(yè)務(wù)分類配置不同的耗時再次過濾
按業(yè)務(wù)需求實時統(tǒng)計業(yè)務(wù)sql,比如:高峰期階段,統(tǒng)計一小時內(nèi)同類業(yè)務(wù)sql的查詢頻率。可為dba提供優(yōu)化數(shù)據(jù)庫的依據(jù),如按查詢的sql創(chuàng)建索引
高峰時段按業(yè)務(wù)類型的權(quán)重指標、日志等級指標、每個服務(wù)在一個時段內(nèi)日志最大限制量指標、時間段指標等動態(tài)清洗過濾日志?
根據(jù)不同的時間段動態(tài)收縮時間窗口
日志索引生成規(guī)則:按服務(wù)生成的日志文件規(guī)則生成對應(yīng)的index,比如:某個服務(wù)日志分為:debug、info、error、xx_keyword,那么生成的索引也是debug、info、error、xx_keyword加日期作后綴。這樣做的目的是為研發(fā)以原習慣性地去使用日志
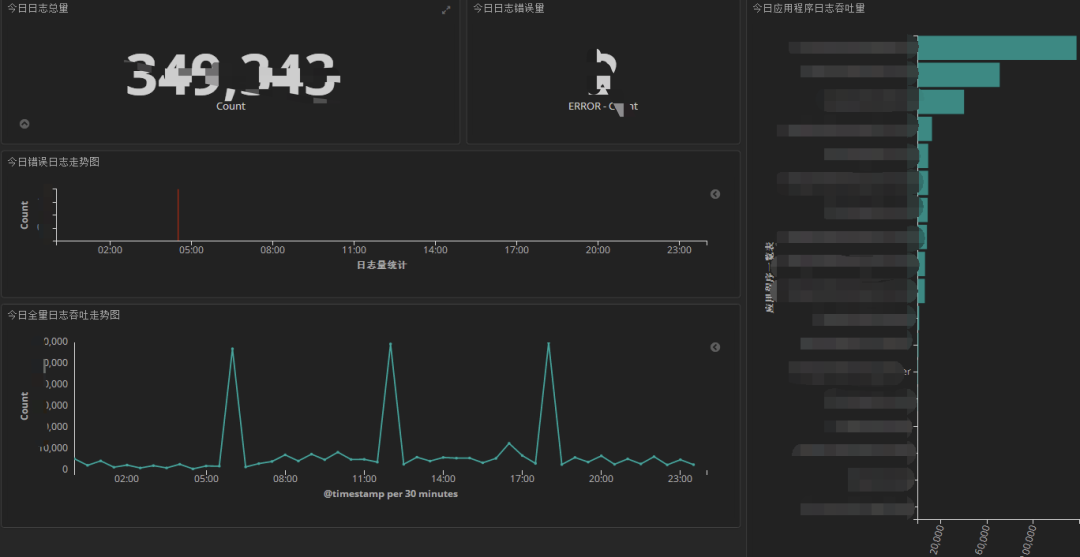
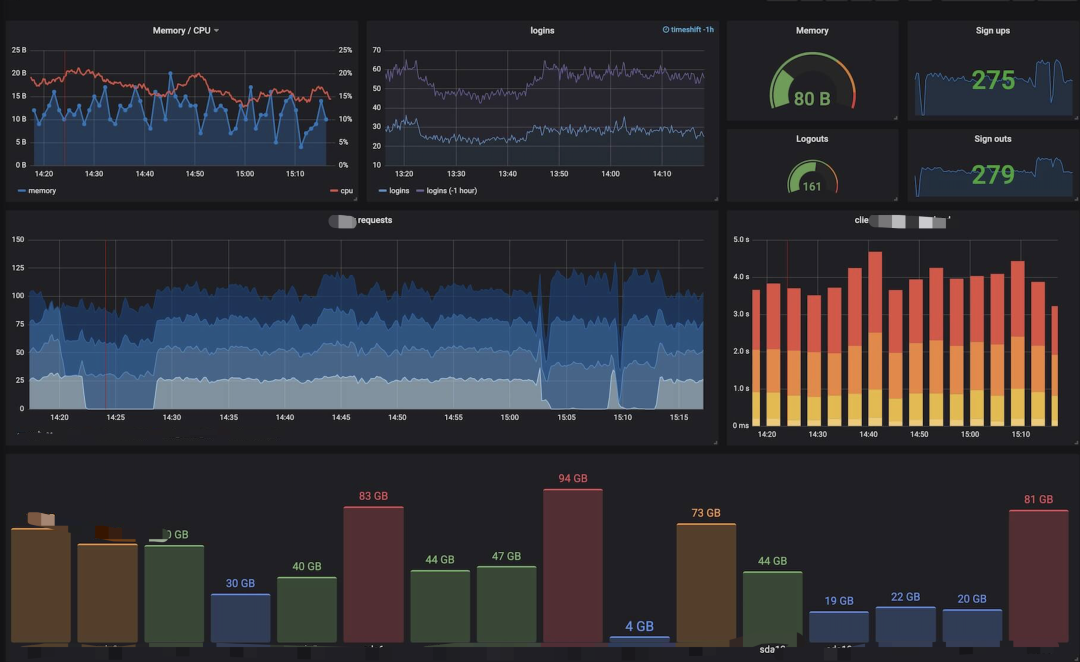
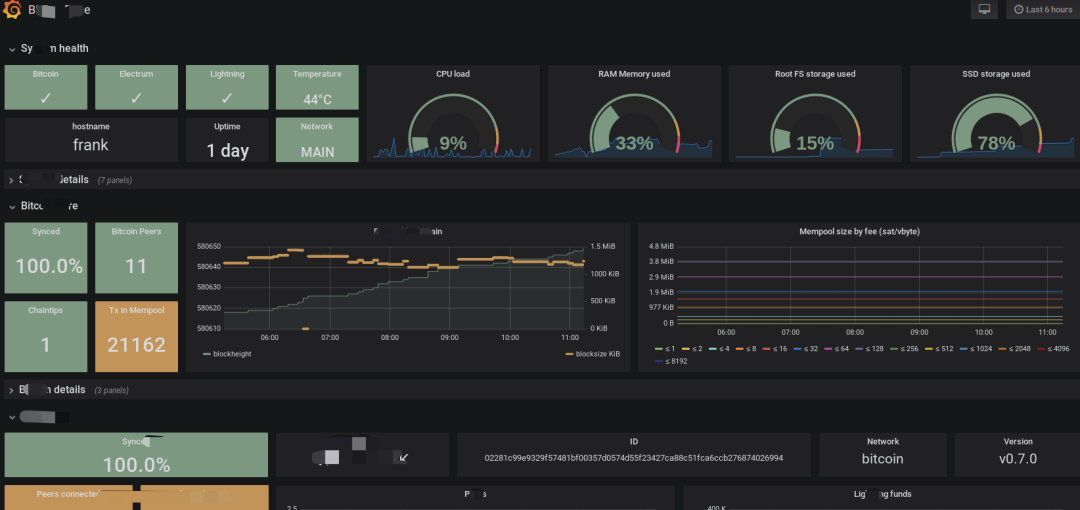
? ? 7. 可視化界面我們主要使用grafana,它支持的眾多數(shù)據(jù)源中,其中就有普羅米修斯和elasticsearch,與普羅米修斯可謂是無縫對接。而kibana我們主要用于apm的可視分析
日志可視化
?
往期推薦
-END-
↑ 點擊上方關(guān)注我公號?↑?
一枚醫(yī)科大本科生,開源小作者,半吊子創(chuàng)業(yè)愛好者...
半吊子的自己在試錯,不知道以后會干什么,但享受現(xiàn)在的試錯,試錯給我驚訝的生活
喜歡公號的互動分享,感謝關(guān)注,路上遇見了你,同一小段時間之路,相伴 ~
長按識別,加我微信
