
【關(guān)于Transformer】 那些的你不知道的事(上)
?作者:楊夕
?項(xiàng)目地址:https://github.com/km1994/nlp_paper_study
論文鏈接:https://arxiv.org/pdf/1706.03762.pdf
【注:手機(jī)閱讀可能圖片打不開!!!】
個(gè)人介紹:大佬們好,我叫楊夕,該項(xiàng)目主要是本人在研讀頂會(huì)論文和復(fù)現(xiàn)經(jīng)典論文過程中,所見、所思、所想、所聞,可能存在一些理解錯(cuò)誤,希望大佬們多多指正。
##?引言
本博客?主要?是本人在學(xué)習(xí)?Transformer?時(shí)的**所遇、所思、所解**,通過以?**十六連彈**?的方式幫助大家更好的理解?該問題。
##?十六連彈
1.?為什么要有?Transformer?
2.?Transformer 作用是什么?
3.?Transformer 整體結(jié)構(gòu)怎么樣?
4.?Transformer-encoder 結(jié)構(gòu)怎么樣?
5.?Transformer-decoder?結(jié)構(gòu)怎么樣?
6.?傳統(tǒng)?attention?是什么?
7.?self-attention?長(zhǎng)怎么樣?
8.?self-attention 如何解決長(zhǎng)距離依賴問題?
9.?self-attention 如何并行化?
10.?multi-head?attention?怎么解?
11.?為什么要?加入 position embedding ?
12.?為什么要?加入?殘差模塊?
13.?Layer normalization。Normalization 是什么?
14.?什么是 Mask?
15.?Transformer 存在問題?
16.?Transformer?怎么?Coding?
##?問題解答
###?一、為什么要有?Transformer?
為什么要有 Transformer? 首先需要知道在 Transformer 之前都有哪些技術(shù),這些技術(shù)所存在的問題:
-?RNN:能夠捕獲長(zhǎng)距離依賴信息,但是無法并行;
-?CNN:?能夠并行,無法捕獲長(zhǎng)距離依賴信息(需要通過層疊 or 擴(kuò)張卷積核?來?增大感受野);
-?傳統(tǒng)?Attention
??-?方法:基于源端和目標(biāo)端的隱向量計(jì)算Attention,
??-?結(jié)果:源端每個(gè)詞與目標(biāo)端每個(gè)詞間的依賴關(guān)系?【源端->目標(biāo)端】
??-?問題:忽略了?遠(yuǎn)端或目標(biāo)端?詞與詞間?的依賴關(guān)系
###?二、Transformer 作用是什么?
基于Transformer的架構(gòu)主要用于建模語言理解任務(wù),它避免了在神經(jīng)網(wǎng)絡(luò)中使用遞歸,而是完全依賴于self-attention機(jī)制來繪制輸入和輸出之間的全局依賴關(guān)系。
###?三、Transformer 整體結(jié)構(gòu)怎么樣?
1.?整體結(jié)構(gòu)
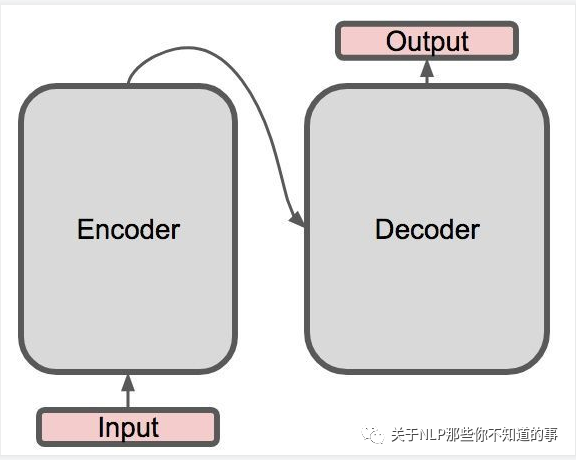
-?Transformer 整體結(jié)構(gòu):
??-??encoder-decoder?結(jié)構(gòu)
-?具體介紹:
??-?左邊是一個(gè)?Encoder;
??-?右邊是一個(gè)?Decoder;
2.?整體結(jié)構(gòu)放大一點(diǎn)
???
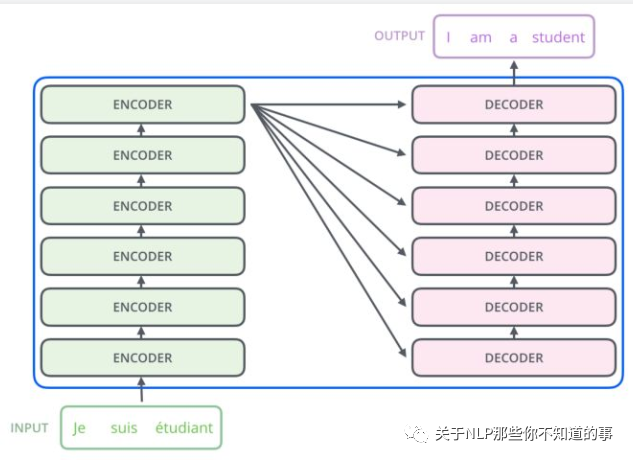
從上一張 Transformer 結(jié)構(gòu)圖,可以知道 Transformer 是一個(gè) encoder-decoder 結(jié)構(gòu),但是 encoder 和 decoder 又包含什么內(nèi)容呢?
-?Encoder 結(jié)構(gòu):
??-?內(nèi)部包含6層小encoder 每一層里面有2個(gè)子層;
-?Decoder 結(jié)構(gòu):
??-?內(nèi)部也是包含6層小decoder?,每一層里面有3個(gè)子層
3.?整體結(jié)構(gòu)再放大一點(diǎn)
???
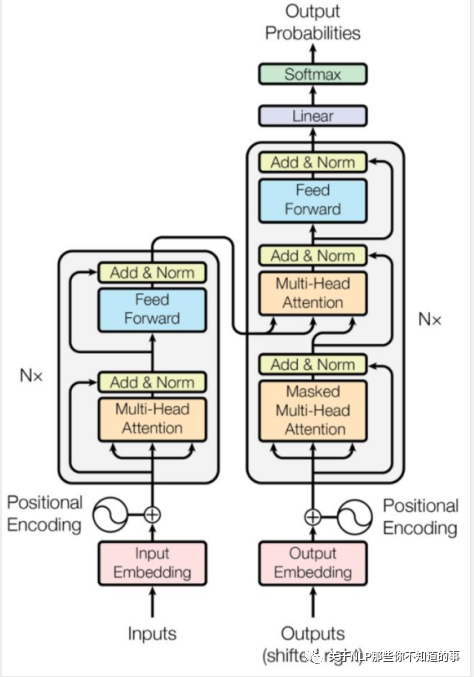
?其中上圖中每一層的內(nèi)部結(jié)構(gòu)如下圖所求。
?-?上圖左邊的每一層encoder都是下圖左邊的結(jié)構(gòu);
?-?上圖右邊的每一層的decoder都是下圖右邊的結(jié)構(gòu);
??
具體內(nèi)容,后面會(huì)逐一介紹。
###?四、Transformer-encoder 結(jié)構(gòu)怎么樣?
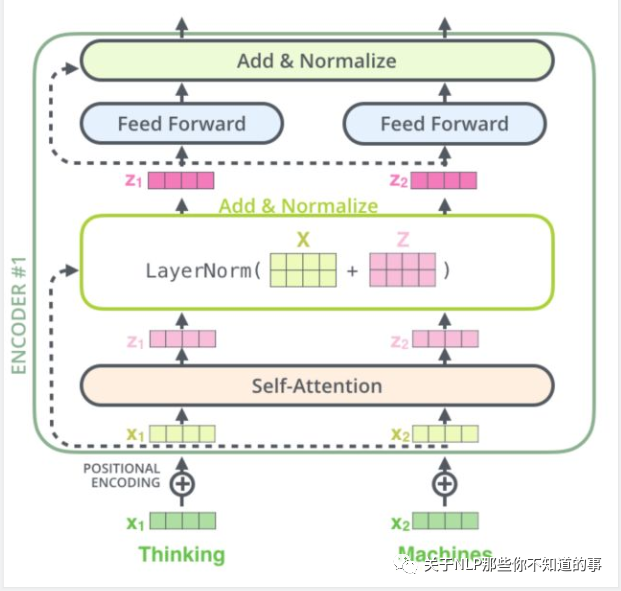
-?特點(diǎn):
??-?與 RNN,CNN 類似,可以當(dāng)成一個(gè)特征提取器;
-?組成結(jié)構(gòu)介紹
??-?embedding 層:將 input 轉(zhuǎn)化為 embedding 向量 X;
??-?Position?encodding:?input的位置與?input?的?embedding??X?相加?得到?向量?$X$;
??-?self-attention?:?將融合input的位置信息?與?input?的?embedding?信息的?$X$?輸入?Self-Attention?層得到?Z;
??-?殘差網(wǎng)絡(luò):Z?與 X 相加后經(jīng)過 layernorm 層;
??-?前饋網(wǎng)絡(luò):經(jīng)過一層前饋網(wǎng)絡(luò)以及 Add&Normalize,(線性轉(zhuǎn)換+relu+線性轉(zhuǎn)換?如下式)
??

-?舉例說明(假設(shè)序列長(zhǎng)度固定,如100,如輸入的序列是“我愛中國(guó)”):
??-?首先需要?**encoding**:
????-?將詞映射成一個(gè)數(shù)字,encoding后,由于序列不足固定長(zhǎng)度,因此需要padding,
????-?然后輸入 embedding層,假設(shè)embedding的維度是128,則輸入的序列維度就是100*128;
??-?接著是**Position?encodding**,論文中是直接將每個(gè)位置通過cos-sin函數(shù)進(jìn)行映射;
????-?分析:這部分不需要在網(wǎng)絡(luò)中進(jìn)行訓(xùn)練,因?yàn)樗枪潭ā5F(xiàn)在很多論文是將這塊也embedding,如bert的模型,至于是encoding還是embedding可取決于語料的大小,語料足夠大就用embedding。將位置信息也映射到128維與上一步的embedding相加,輸出100*128
??-?經(jīng)過**self-attention層**:
????-?操作:假設(shè)v的向量最后一維是64維(假設(shè)沒有多頭),該部分輸出100*64;
??-?經(jīng)過殘差網(wǎng)絡(luò):
????-?操作:即序列的embedding向量與上一步self-attention的向量加總;
??-?經(jīng)過?**layer-norm**:
????-?原因:
??????-?由于在self-attention里面更好操作而已;
??????-?真實(shí)序列的長(zhǎng)度一直在變化;
??-?經(jīng)過?**前饋網(wǎng)絡(luò)**:
????-?目的:增加非線性的表達(dá)能力,畢竟之前的結(jié)構(gòu)基本都是簡(jiǎn)單的矩陣乘法。若前饋網(wǎng)絡(luò)的隱向量是512維,則結(jié)構(gòu)最后輸出100*512;
###?五、Transformer-decoder?結(jié)構(gòu)怎么樣?
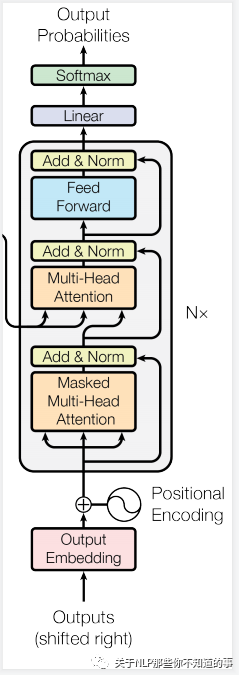
-?特點(diǎn):與 encoder 類似
-?組成結(jié)構(gòu)介紹
??-?masked 層:
????-?目的:確保了位置 i 的預(yù)測(cè)僅依賴于小于 i 的位置處的已知輸出;
??-?Linear layer:
????-?目的:將由解碼器堆棧產(chǎn)生的向量投影到一個(gè)更大的向量中,稱為對(duì)數(shù)向量。這個(gè)向量對(duì)應(yīng)著模型的輸出詞匯表;向量中的每個(gè)值,對(duì)應(yīng)著詞匯表中每個(gè)單詞的得分;
??-?softmax層:
????-?操作:這些分?jǐn)?shù)轉(zhuǎn)換為概率(所有正數(shù),都加起來為1.0)。選擇具有最高概率的單元,并且將與其相關(guān)聯(lián)的單詞作為該時(shí)間步的輸出
##?參考資料
1.?[Transformer理論源碼細(xì)節(jié)詳解](https://zhuanlan.zhihu.com/p/106867810)
2.?[論文筆記:Attention is all you need(Transformer)](https://zhuanlan.zhihu.com/p/51089880)
3.?[深度學(xué)習(xí)-論文閱讀-Transformer-20191117](https://zhuanlan.zhihu.com/p/92234185)
4.?[Transform詳解(超詳細(xì))?Attention?is?all?you?need論文](https://zhuanlan.zhihu.com/p/63191028)
5.?[目前主流的attention方法都有哪些?](https://www.zhihu.com/question/68482809/answer/597944559)
6.?[transformer三部曲](https://zhuanlan.zhihu.com/p/85612521)
7.?[Character-Level?Language?Modeling?with?Deeper?Self-Attention](https://aaai.org/ojs/index.php/AAAI/article/view/4182)
8.?[Transformer-XL:?Unleashing?the?Potential?of?Attention?Models](https://ai.googleblog.com/2019/01/transformer-xl-unleashing-potential-of.html)
9.?[The?Importance?of?Being?Recurrent?for?Modeling?Hierarchical?Structure](https://arxiv.org/abs/1803.03585)
10.?[Linformer](https://arxiv.org/abs/2006.04768)
