
【關(guān)于 KBQA】那些你不知道的事
作者:楊夕
項(xiàng)目地址:https://github.com/km1994/nlp_paper_study
個(gè)人介紹:大佬們好,我叫楊夕,該項(xiàng)目主要是本人在研讀頂會(huì)論文和復(fù)現(xiàn)經(jīng)典論文過程中,所見、所思、所想、所聞,可能存在一些理解錯(cuò)誤,希望大佬們多多指正。
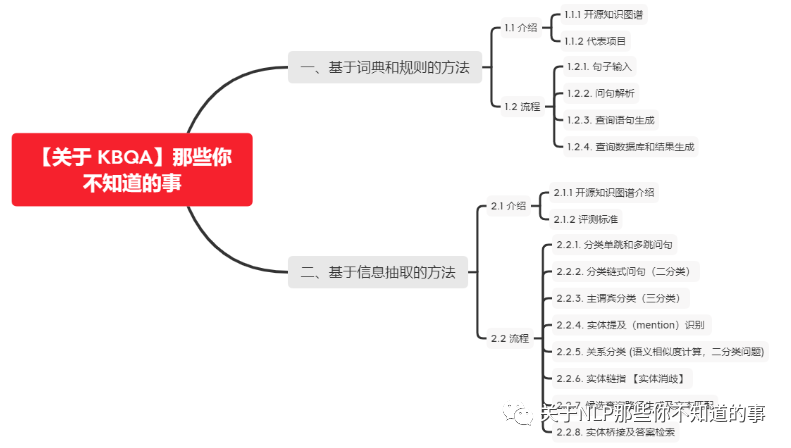
一、基于詞典和規(guī)則的方法
1.1 介紹
1.1.1 開源知識(shí)圖譜
工業(yè)界的知識(shí)圖譜有兩種分類方式,第一種是根據(jù)領(lǐng)域的覆蓋范圍不同分為通用知識(shí)圖譜和領(lǐng)域知識(shí)圖譜。其中通用知識(shí)圖譜注重知識(shí)廣度,領(lǐng)域知識(shí)圖譜注重知識(shí)深度。通用知識(shí)圖譜常常覆蓋生活中的各個(gè)領(lǐng)域,從衣食住行到專業(yè)知識(shí)都會(huì)涉及,但是在每個(gè)領(lǐng)域內(nèi)部的知識(shí)體系構(gòu)建不是很完善;而領(lǐng)域知識(shí)圖譜則是專注于某個(gè)領(lǐng)域(金融、司法等),結(jié)合領(lǐng)域需求與規(guī)范構(gòu)建合適的知識(shí)結(jié)構(gòu)以便進(jìn)行領(lǐng)域內(nèi)精細(xì)化的知識(shí)存儲(chǔ)和問答。代表的知識(shí)圖譜分別有:
通用知識(shí)圖譜
Google Knowledge Graph
Microsoft Satori & Probase
領(lǐng)域知識(shí)圖譜
Facebook 社交知識(shí)圖譜
Amazon 商品知識(shí)圖譜
阿里巴巴商品知識(shí)圖譜
上海交大學(xué)術(shù)知識(shí)圖譜
第二種分類方式是按照回答問題需要的知識(shí)類別來定義的,分為常識(shí)知識(shí)圖譜和百科全書知識(shí)圖譜。針對(duì)常識(shí)性知識(shí)圖譜,我們只會(huì)挖掘問題中的詞之間的語義關(guān)系,一般而言比較關(guān)注的關(guān)系包括 isA Relation、isPropertyOf Relation,問題的答案可能根據(jù)情景不同而有不同,所以回答正確與否往往存在概率問題。而針對(duì)百科全書知識(shí)圖譜,我們往往會(huì)定義很多謂詞,例如DayOfbirth, LocatedIn, SpouseOf 等等。這些問題即使有多個(gè)答案,這些答案往往也都是確定的,所以構(gòu)建這種圖譜在做問答時(shí)最優(yōu)先考慮的就是準(zhǔn)確率。代表的知識(shí)圖譜分別有:
常識(shí)知識(shí)圖譜
WordNet, KnowItAll, NELL, Microsoft Concept Graph
百科全書知識(shí)圖譜
Freebase, Yago, Google Knowledge Graph
1.1.2 代表項(xiàng)目
豆瓣影評(píng)問答
基于醫(yī)療知識(shí)圖譜的問答系統(tǒng)
1.2 流程
1.2.1. 句子輸入
- eg:query:高血壓要怎么治?需要多少天?
1.2.2. 問句解析
實(shí)體抽取:
作用:得到匹配的詞和類型
方法:
模式匹配:
介紹:主要采用規(guī)則 提槽
工具:正則表達(dá)式
詞典:
介紹:利用詞典進(jìn)行匹配
采用的詞典匹配方法:trie和Aho-Corasick自動(dòng)機(jī),簡(jiǎn)稱AC自動(dòng)機(jī)
工具:ahocorasick、FlashText 等 python包
基于詞向量的文本相似度計(jì)算:
介紹:計(jì)算 query 中 實(shí)體 與 實(shí)體庫 中候選實(shí)體的相似度,通過設(shè)定閾值,得到最相似的 實(shí)體
工具:詞向量工具(TF-idf、word2vec、Bert 等)、相似度計(jì)算方法(余弦相似度、L1、L2等)
命名實(shí)體識(shí)別方法:
利用 命名實(shí)體識(shí)別方法 識(shí)別 query 中實(shí)體
方法:BiLSTM-CRF等命名實(shí)體識(shí)別模型
舉例說明:
eg:通過解析 上面的 query ,獲取里面的實(shí)體和實(shí)體類型:{'Disease': ['高血壓'], 'Symptom': ['高血壓'], 'Complication': ['高血壓']}
屬性和關(guān)系抽取:
作用:抽取 query 中 的 屬性和關(guān)系
方法:
模式匹配:
介紹:主要采用規(guī)則匹配
工具:正則表達(dá)式
詞典:
介紹:利用詞典進(jìn)行匹配
采用的詞典匹配方法:trie和Aho-Corasick自動(dòng)機(jī),簡(jiǎn)稱AC自動(dòng)機(jī)
工具:ahocorasick、FlashText 等 python包
意圖識(shí)別方法:
介紹:采用分類模型 對(duì) query 所含關(guān)系 做預(yù)測(cè)
工具:
機(jī)器學(xué)習(xí)方法:LR、SVM、NB
深度學(xué)習(xí)方法:TextCNN、TextRNN、Bert 等
命名實(shí)體識(shí)別方法:【同樣,可以采用命名實(shí)體識(shí)別挖掘出 query 中的某些動(dòng)詞和所屬類型】
利用 命名實(shí)體識(shí)別方法 識(shí)別 query 中實(shí)體
方法:BiLSTM-CRF等命名實(shí)體識(shí)別模型
舉例說明:
- eg:通過解析 上面的 query ,獲取里面的實(shí)體和實(shí)體類型:
- predicted intentions:['query_period'] 高血壓要怎么治?
- word intentions:['query_cureway'] 需要多少天?
1.2.3. 查詢語句生成
作用:根據(jù) 【問句解析】 的結(jié)果,將 實(shí)體、屬性和關(guān)系轉(zhuǎn)化為對(duì)于的 圖數(shù)據(jù)庫(eg:Neo4j圖數(shù)據(jù)庫等)查詢語句
舉例說明:
- eg:
對(duì)于 query:高血壓要怎么治?需要多少天?
- sql 解析結(jié)果:
[{'intention': 'query_period', 'sql': ["MATCH (d:Disease) WHERE d.name='高血壓' return d.name,d.period"]}, {'intention': 'query_cureway', 'sql': ["MATCH (d:Disease)-[:HAS_DRUG]->(n) WHERE d.name='高血壓' return d.name,d.treatment,n.name"]}]
1.2.4. 查詢數(shù)據(jù)庫和結(jié)果生成
作用:利用 【查詢語句生成】 的結(jié)果,去 圖數(shù)據(jù)庫 中 查詢 答案,并利用預(yù)設(shè)模板 生成答案
- eg:
- 高血壓可以嘗試如下治療:藥物治療;手術(shù)治療;支持性治療
二、基于信息抽取的方法
2.1 介紹
2.1.1 開源知識(shí)圖譜介紹


2.2 流程
2.2.1. 分類單跳和多跳問句
思路:利用 文本分類方法 對(duì) query 進(jìn)行分類,判斷其屬于 一跳問題還是多跳問題
方法:文本分類方法【TextCNN、TextRNN、Bert 等】
解析
單跳:SPARQL 只出現(xiàn)一個(gè)三元組
q26:豌豆公主這個(gè)形象出自于哪?
select ?x where { <豌豆公主_(安徒生童話)> <作品出處> ?x. }
<安徒生童話>
雙跳或多跳:SPARQL 只出現(xiàn)兩個(gè)以上三元組
q524:博爾赫斯的國家首都在哪里?
select ?x where { <豪爾赫·路易斯·博爾赫斯_(阿根廷作家)> <出生地> ?y. ?y <首都> ?x}
<布宜諾斯艾利斯_(阿根廷的首都和最大城市)>
2.2.2. 分類鏈?zhǔn)絾柧洌ǘ诸悾?/h4>思路:利用 文本分類方法 對(duì) query 進(jìn)行分類,判斷其是否 屬于 鏈?zhǔn)絾柧?/p>
介紹:鏈?zhǔn)剑篠PARQL 多個(gè)三元組呈遞進(jìn)關(guān)系,x->y->z,非交集關(guān)系
q894:納蘭性德的父親擔(dān)任過什么官職?
select ?y where { <納蘭性德> <父親> ?x. ?x <主要職位> ?y. }
"武英殿大學(xué)士" "太子太傅"
q554:宗馥莉任董事長的公司的公司口號(hào)是?
select ?y where { ?x <董事長> <宗馥莉>. ?x <公司口號(hào)> ?y. }
"win happy health,娃哈哈就在你身邊"
2.2.3. 主謂賓分類(三分類)
思路:利用 文本分類方法 對(duì) query 進(jìn)行分類,判斷 問句的答案對(duì)應(yīng)三元組里面的 主謂賓
問句的答案對(duì)應(yīng)三元組里面的主語,spo=0
q70:《悼李夫人賦》是誰的作品?
select ?x where { ?x <代表作品> <悼李夫人賦>. }
<漢武帝_(漢朝皇帝)>
問句的答案對(duì)應(yīng)三元組里面的謂語,spo=1
q506:林徽因和梁思成是什么關(guān)系?
select ?x where { <林徽因_(中國建筑師、詩人、作家)> ?x <梁思成>. }
<丈夫>
問句的答案對(duì)應(yīng)三元組里面的賓語,spo=2
q458:天津大學(xué)的現(xiàn)任校長是誰?
select ?x where { <天津大學(xué)> <現(xiàn)任校長> ?x . }
<李家俊_(天津市委委員,天津大學(xué)校長)>
2.2.4. 實(shí)體提及(mention)識(shí)別
思路:對(duì)于 給定 query,我們需要 識(shí)別出 query 中 所含有的 實(shí)體提及(mention)
問題:主辦方提供的數(shù)據(jù)中 包含 :query、sql語句,但是 sql語句中的實(shí)體并不能在 query 中被找到,如下:
q1440:濟(jì)南是哪個(gè)省的省會(huì)城市?
select ?x where { ?x <政府駐地> <濟(jì)南_(山東省省會(huì))>. }
<山東_(中國山東省)>
注:query 中 的 濟(jì)南 是 <濟(jì)南_(山東省省會(huì))>的 簡(jiǎn)稱、省會(huì)城市 在 知識(shí)庫中 對(duì)應(yīng) <政府駐地>
解決方法:根據(jù)訓(xùn)練語料的SPARQL語句,查找實(shí)體的提及,反向構(gòu)建訓(xùn)練數(shù)據(jù)
思路:利用 文本分類方法 對(duì) query 進(jìn)行分類,判斷其是否 屬于 鏈?zhǔn)絾柧?/p>
介紹:鏈?zhǔn)剑篠PARQL 多個(gè)三元組呈遞進(jìn)關(guān)系,x->y->z,非交集關(guān)系
q894:納蘭性德的父親擔(dān)任過什么官職?
select ?y where { <納蘭性德> <父親> ?x. ?x <主要職位> ?y. }
"武英殿大學(xué)士" "太子太傅"
q554:宗馥莉任董事長的公司的公司口號(hào)是?
select ?y where { ?x <董事長> <宗馥莉>. ?x <公司口號(hào)> ?y. }
"win happy health,娃哈哈就在你身邊"
思路:利用 文本分類方法 對(duì) query 進(jìn)行分類,判斷 問句的答案對(duì)應(yīng)三元組里面的 主謂賓
問句的答案對(duì)應(yīng)三元組里面的主語,spo=0
q70:《悼李夫人賦》是誰的作品?
select ?x where { ?x <代表作品> <悼李夫人賦>. }
<漢武帝_(漢朝皇帝)>
問句的答案對(duì)應(yīng)三元組里面的謂語,spo=1
q506:林徽因和梁思成是什么關(guān)系?
select ?x where { <林徽因_(中國建筑師、詩人、作家)> ?x <梁思成>. }
<丈夫>
問句的答案對(duì)應(yīng)三元組里面的賓語,spo=2
q458:天津大學(xué)的現(xiàn)任校長是誰?
select ?x where { <天津大學(xué)> <現(xiàn)任校長> ?x . }
<李家俊_(天津市委委員,天津大學(xué)校長)>
思路:對(duì)于 給定 query,我們需要 識(shí)別出 query 中 所含有的 實(shí)體提及(mention)
問題:主辦方提供的數(shù)據(jù)中 包含 :query、sql語句,但是 sql語句中的實(shí)體并不能在 query 中被找到,如下:
q1440:濟(jì)南是哪個(gè)省的省會(huì)城市?
select ?x where { ?x <政府駐地> <濟(jì)南_(山東省省會(huì))>. }
<山東_(中國山東省)>
注:query 中 的 濟(jì)南 是 <濟(jì)南_(山東省省會(huì))>的 簡(jiǎn)稱、省會(huì)城市 在 知識(shí)庫中 對(duì)應(yīng) <政府駐地>
解決方法:根據(jù)訓(xùn)練語料的SPARQL語句,查找實(shí)體的提及,反向構(gòu)建訓(xùn)練數(shù)據(jù)

q6:叔本華信仰什么宗教?
select ?y where { <亞瑟·叔本華> <信仰> ?y. }
<佛教>
>>>
叔本華信仰什么宗教? ['叔本華']
亞瑟·叔本華信仰什么宗教? ['亞瑟·叔本華']
>>>
叔 本 華 信 仰 什 么 宗 教 ? B-SEG I-SEG E-SEG O O O O O O O
亞 瑟 · 叔 本 華 信 仰 什 么 宗 教 ? B-SEG I-SEG I-SEG I-SEG I-SEG E-SEG O O O O O O O

2.2.5. 關(guān)系分類 (語義相似度計(jì)算,二分類問題)
目標(biāo):查詢實(shí)體關(guān)系中與問句最相似的關(guān)系
思路:
正例:根據(jù)給定 訓(xùn)練集,獲得 實(shí)體和關(guān)系 的樣本
負(fù)例:根據(jù) 該實(shí)體名 從 Neo4j 圖數(shù)據(jù)庫中隨機(jī)抽取出 5個(gè)關(guān)系作為負(fù)例
q1:莫妮卡·貝魯奇的代表作?
select ?x where { <莫妮卡·貝魯奇> <代表作品> ?x. }
<西西里的美麗傳說>
>>> 表達(dá)形式一:
正例:
莫妮卡·貝魯奇的代表作?代表作品 1
負(fù)例:
莫妮卡·貝魯奇的代表作?出生地 0
莫妮卡·貝魯奇的代表作?類型 0
莫妮卡·貝魯奇的代表作?制片地區(qū) 0
莫妮卡·貝魯奇的代表作?主演 0
莫妮卡·貝魯奇的代表作?作者 0

2.2.6. 實(shí)體鏈指 【實(shí)體消歧】
問題:對(duì)于 問句中的實(shí)體提及在 Neo4j 圖數(shù)據(jù)庫 中可能存在多個(gè)相關(guān)實(shí)體,如何選取 將 實(shí)體提及 鏈指到 對(duì)應(yīng)的 知識(shí)庫中的實(shí)體
q15:清明節(jié)起源于哪里?
select ?x where { <清明_(二十四節(jié)氣之一)> <起源> ?x. }
<綿山風(fēng)景名勝區(qū)>
>>>
問句中 實(shí)體提及:清明
對(duì)應(yīng)的知識(shí)庫中的 實(shí)體:<清明_(二十四節(jié)氣之一)>、清明_(漢語詞匯)、清明_(長篇小說)、清明_(唐代杜牧詩作)等
目標(biāo):查找問句中實(shí)體提及對(duì)應(yīng)的唯一實(shí)體
思路:
在訓(xùn)練集上,令標(biāo)注的實(shí)體標(biāo)簽為1,其余候選實(shí)體標(biāo)簽為0,使用邏輯回歸對(duì)上述特征進(jìn)行擬合。
在驗(yàn)證集和測(cè)試集上,使用訓(xùn)練好的機(jī)器模型對(duì)每個(gè)實(shí)體打分,保留分?jǐn)?shù)排名前n的候選實(shí)體。
特征選擇:

# 獲取 mention 的特征 mention_features : [mention, f1, f2, f3]
# f1 : mention的長度
# f2 : mention 在 SogouLabDic.dic 中 的詞頻
# f3 : mention 在 question 中 的位置
def get_mention_feature(self,question,mention):
f1 = float(len(mention)) #mention的長度
try:
f2 = float(self.word_2_frequency[mention]) # mention的tf/10000
except:
f2 = 1.0
if mention[-2:] == '大學(xué)':
f2 = 1.0
try:
f3 = float(question.index(mention))
except:
f3 = 3.0
#print ('這個(gè)mention無法提取位置')
return [mention,f1,f2,f3]
圖譜子圖與問題的匹配度:計(jì)算問題和主語實(shí)體及其兩跳內(nèi)關(guān)系間的相似度
實(shí)體提及及兩跳內(nèi)關(guān)系和實(shí)體與問題重疊詞數(shù)量
實(shí)體提及及兩跳內(nèi)關(guān)系和實(shí)體與問題重疊字?jǐn)?shù)量
# similar_features : [overlap,jaccard] * {(q_tokens,e_tokens), (q_chars,e_chars), (q_tokens,p_tokens), (q_chars,p_chars)} = 8
def extract_subject(self,entity_mentions,subject_props,question):
...
#得到實(shí)體兩跳內(nèi)的所有關(guān)系
entity = '<'+entity+'>'
if entity in self.entity2hop_dic:
relations = self.entity2hop_dic[entity]
else:
relations = kb.GetRelations_2hop(entity)
self.entity2hop_dic[entity] = relations
# 計(jì)算問題和主語實(shí)體及其兩跳內(nèi)關(guān)系間的相似度
similar_features = ComputeEntityFeatures(question,entity,relations)
...
def ComputeEntityFeatures(question,entity,relations):
'''
抽取每個(gè)實(shí)體或?qū)傩灾?hop內(nèi)的所有關(guān)系,來跟問題計(jì)算各種相似度特征
input:
question: python-str
entity: python-str <entityname>
relations: python-dic key:<rname>
output:
[word_overlap,char_overlap,word_embedding_similarity,char_overlap_ratio]
'''
#得到主語-謂詞的tokens及chars
p_tokens = []
for p in relations:
p_tokens.extend(segger.cut(p[1:-1]))
p_tokens = [token[0] for token in p_tokens]
p_chars = [char for char in ''.join(p_tokens)]
q_tokens = segger.cut(question)
q_tokens = [token[0] for token in q_tokens]
q_chars = [char for char in question]
e_tokens = segger.cut(entity[1:-1])
e_tokens = [token[0] for token in e_tokens]
e_chars = [char for char in entity[1:-1]]
qe_feature = features_from_two_sequences(q_tokens,e_tokens) + features_from_two_sequences(q_chars,e_chars)
qr_feature = features_from_two_sequences(q_tokens,p_tokens) + features_from_two_sequences(q_chars,p_chars)
#實(shí)體名和問題的overlap除以實(shí)體名長度的比例
return qe_feature+qr_feature
def features_from_two_sequences(s1,s2):
#overlap
overlap = len(set(s1)&(set(s2)))
#集合距離
jaccard = len(set(s1)&(set(s2))) / len(set(s1)|(set(s2)))
#詞向量相似度
#wordvecsim = model.similarity(''.join(s1),''.join(s2))
return [overlap,jaccard]
實(shí)體提及的流行度特征
實(shí)體提及在圖譜中關(guān)系個(gè)數(shù)/出現(xiàn)頻率
# popular_feature : GetRelationNum = 1 實(shí)體的流行度特征
def extract_subject(self,entity_mentions,subject_props,question):
...
#實(shí)體的流行度特征
popular_feature = kb.GetRelationNum(entity)
...
def GetRelationNum(self,entity):
'''根據(jù)實(shí)體名,得到與之相連的關(guān)系數(shù)量,代表實(shí)體在知識(shí)庫中的流行度'''
cql= "match p=(a:Entity)-[r1:Relation]-() where a.name=$name return count(p)"
res = self.session.run(cql,name=entity)
ans = 0
for record in res:
ans = record.values()[0]
return ans
實(shí)體名稱和問題的字符串匹配度(char/word)
問題和實(shí)體提及語義相似度
問題和實(shí)體關(guān)系的最大相似度 ...
標(biāo)簽:是否為 對(duì)應(yīng)實(shí)體
q15:清明節(jié)起源于哪里?
select ?x where { <清明_(二十四節(jié)氣之一)> <起源> ?x. }
<綿山風(fēng)景名勝區(qū)>
>>>
清明節(jié)起源于哪里?<清明_(二十四節(jié)氣之一)> 1.0 1.0 0.43 0.15978466 0.6 0.99257445 ... 0
清明節(jié)起源于哪里?<清明_(漢語詞匯)> 0.9 1.0 0.43 0.97132427 0.58 0.99660385 ... 1
清明節(jié)起源于哪里?<清明_(長篇小說)> 0.8 1.0 0.43 0.920861 0.38 0.0007164952 ... 0
清明節(jié)起源于哪里?<清明_(唐代杜牧詩作)> 0.8 1.0 0.43 0.920861 0.38 0.0007164952 ... 0
...
分類方法:
LR、SVM、xgboost 等


q15:清明節(jié)起源于哪里?
select ?x where { <清明_(二十四節(jié)氣之一)> <起源> ?x. }
<綿山風(fēng)景名勝區(qū)>
>>> 實(shí)體提及 和 關(guān)系
實(shí)體提及 <清明_(二十四節(jié)氣之一)>
關(guān)系 起源
>>> (entity,relation)
(entity,relation):(<清明_(二十四節(jié)氣之一)>,起源 )
>>> 候選查詢路徑:(entity,relation) => entity 的 relation
(<清明_(二十四節(jié)氣之一)>,起源 ): 清明_(二十四節(jié)氣之一)的起源
>>> 文本匹配:
清明節(jié)起源于哪里?清明_(二十四節(jié)氣之一)的起源 1
清明節(jié)起源于哪里?清明_(二十四節(jié)氣之一)的類型 0
清明節(jié)起源于哪里?清明_(漢語詞匯)的起源地 0
清明節(jié)起源于哪里?清明_(漢語詞匯)的類型 0
2.2.8. 實(shí)體橋接及答案檢索
動(dòng)機(jī):
2.2.7 節(jié) 所提方法只能處理 單實(shí)體問題,但是 樣本中 不僅 包含 單實(shí)體問題,還包含 多實(shí)體問題,那需要怎么解決呢?
eg:北京大學(xué)出了哪些哲學(xué)家
解決方法:實(shí)體橋接
思路:
對(duì)于每個(gè)問題,首先對(duì)2.2.7 節(jié) 打分后的候選查詢路徑進(jìn)行排序,保留前30個(gè)單關(guān)系的查詢路徑(entity1,relation1)。
對(duì)于這些查詢路徑,到知識(shí)庫中進(jìn)行檢索,驗(yàn)證其是否能和其他候選實(shí)體組成多實(shí)體情況的查詢路徑(entity1,relation1,ANSWER,relation2,entity2),將其加入候選查詢路徑中。
最后,本文將2.2.7 節(jié) 單實(shí)體情況排名前三的候選查詢路徑和本節(jié)得到的雙實(shí)體情況查詢路徑同時(shí)和問題計(jì)算重疊的字?jǐn)?shù),選擇重疊字?jǐn)?shù)最多的作為最終的查詢路徑,認(rèn)為其在語義和表達(dá)上最與問題相似。
參考資料
中文知識(shí)圖譜問答 CCKS2019 CKBQA - 參賽總結(jié)
ccks2019-ckbqa-4th-codes
QA-Survey
中文知識(shí)圖譜問答 CCKS2019 CKBQA 參賽總結(jié)
CCKS2019 測(cè)評(píng)報(bào)告
