
快速入門數(shù)據(jù)結(jié)構(gòu)和算法


點擊「閱讀原文」查看良許原創(chuàng)精品視頻。
點擊「閱讀原文」查看良許原創(chuàng)精品視頻。
阿里妹導(dǎo)讀:有哪些常見的數(shù)據(jù)結(jié)構(gòu)?基本操作是什么?常見的排序算法是如何實現(xiàn)的?各有什么優(yōu)缺點?本文簡要分享算法基礎(chǔ)、常見的數(shù)據(jù)結(jié)構(gòu)以及排序算法,給同學(xué)們帶來一堂數(shù)據(jù)結(jié)構(gòu)和算法的基礎(chǔ)課。
一? 前言
1 ?為什么要學(xué)習(xí)算法和數(shù)據(jù)結(jié)構(gòu)?
解決特定問題。
深度優(yōu)化程序性能的基礎(chǔ)。
學(xué)習(xí)一種思想:如何把現(xiàn)實問題轉(zhuǎn)化為計算機(jī)語言表示。
2 ?業(yè)務(wù)開發(fā)要掌握到程度?
了解常見數(shù)據(jù)結(jié)構(gòu)和算法,溝通沒有障礙。
活學(xué)活用:遇到問題時知道要用什么數(shù)據(jù)結(jié)構(gòu)和算法去優(yōu)化。
?
二? 數(shù)據(jù)結(jié)構(gòu)基礎(chǔ)
1 ?什么是數(shù)據(jù)結(jié)構(gòu)?
數(shù)據(jù)結(jié)構(gòu)是數(shù)據(jù)的組織、管理和存儲格式,其使用目的是為了高效的訪問和修改數(shù)據(jù)。
數(shù)據(jù)結(jié)構(gòu)是算法的基石。如果把算法比喻成美麗靈動的舞者,那么數(shù)據(jù)結(jié)構(gòu)就是舞者腳下廣闊而堅實的舞臺。
2 ?物理結(jié)構(gòu)和邏輯結(jié)構(gòu)的區(qū)別?
物理結(jié)構(gòu)就像人的血肉和骨骼,看得見,摸得著,實實在在,如數(shù)組、鏈表。
邏輯結(jié)構(gòu)就像人的思想和精神,它們看不見、摸不著,如隊列、棧、樹、圖。
3 ?線性存儲結(jié)構(gòu)和非線性存儲結(jié)構(gòu)的區(qū)別?
線性:元素之間的關(guān)系是一對一的,如棧、隊列。
非線性:每個元素可能連接0或多個元素,如樹、圖。
?
三? 算法基礎(chǔ)
1 ?什么是算法?
數(shù)學(xué):算法是用于解決某一類問題的公式和思想。
計算機(jī):一系列程序指令,用于解決特定的運(yùn)算和邏輯問題。
2 ?如何衡量算法好壞?
時間復(fù)雜度:運(yùn)行時間長短。
空間復(fù)雜度:占用內(nèi)存大小。
3 ?怎么計算時間復(fù)雜度?
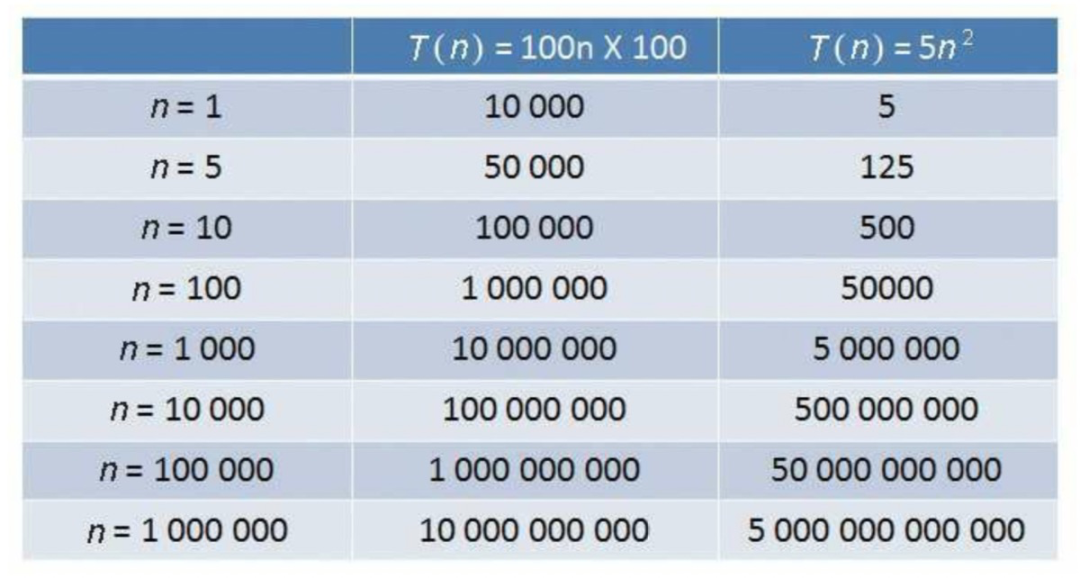
大O表示法(漸進(jìn)時間復(fù)雜度):把程序的相對執(zhí)行時間函數(shù)T(n)簡化為一個數(shù)量級,這個數(shù)量級可以是n、n^2、logN等。
推導(dǎo)時間復(fù)雜度的幾個原則:
如果運(yùn)行時間是常數(shù)量級,則用常數(shù)1表示。
只保留時間函數(shù)中的最高階項。
如果最高階項存在,則省去最高項前面的系數(shù)。
時間復(fù)雜度對比:O(1) > O(logn) > O(n) > O(nlogn) > O(n^2)。
不同時間復(fù)雜度算法運(yùn)行次數(shù)對比:
4 ?怎么計算空間復(fù)雜度?
常量空間 O(1):存儲空間大小固定,和輸入規(guī)模沒有直接的關(guān)系。
線性空間 O(n):分配的空間是一個線性的集合,并且集合大小和輸入規(guī)模n成正比。
二維空間 O(n^2):分配的空間是一個二維數(shù)組集合,并且集合的長度和寬度都與輸入規(guī)模n成正比。
遞歸空間 O(logn):遞歸是一個比較特殊的場景。雖然遞歸代碼中并沒有顯式的聲明變量或集合,但是計算機(jī)在執(zhí)行程序時,會專門分配一塊內(nèi)存空間,用來存儲“方法調(diào)用棧”。執(zhí)行遞歸操作所需要的內(nèi)存空間和遞歸的深度成正比。
5 ?如何定義算法穩(wěn)定性?
穩(wěn)定:如果a原本在b前面,而a=b,排序之后a仍然在b的前面。
不穩(wěn)定:如果a原本在b的前面,而a=b,排序之后 a 可能會出現(xiàn)在 b 的后面。
6 ?有哪些常見算法?
首先要明確:特定算法解決特定問題。
字符串:暴力匹配、BM、KMP、Trie等。
查找:二分查找、遍歷查找等。
排序:冒泡排序、快排、計數(shù)排序、堆排序等。
搜索:TFIDF、PageRank等。
聚類分析:期望最大化、k-meanings、k-數(shù)位等。
深度學(xué)習(xí):深度信念網(wǎng)絡(luò)、深度卷積神經(jīng)網(wǎng)絡(luò)、生成式對抗等。
異常檢測:k最近鄰、局部異常因子等。
......
其中,字符串、查找、排序算法是最基礎(chǔ)的算法。
四? 常見數(shù)據(jù)結(jié)構(gòu)
1? 數(shù)組
1)什么是數(shù)組?
數(shù)據(jù)是有限個相同類型的變量所組成的有序集合。數(shù)組中的每一個變量被稱為元素。

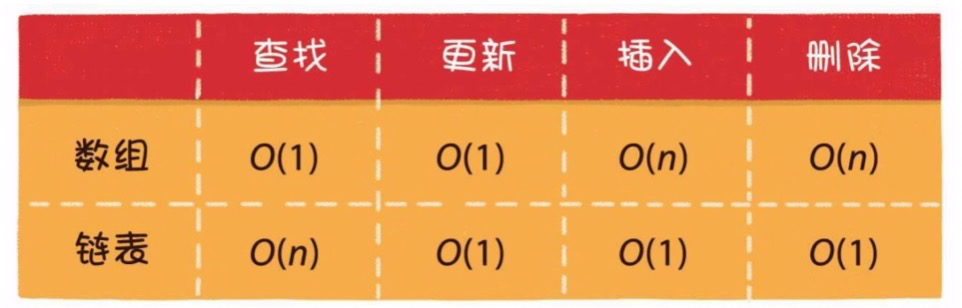
2)數(shù)組的基本操作?
讀取O(1)、更新O(1)、插入O(n)、刪除O(n)、擴(kuò)容O(n)。
2? 鏈表
1)什么是鏈表?
鏈表是一種在物理上非連續(xù)、非順序的數(shù)據(jù)結(jié)構(gòu),由若干個節(jié)點組成。
單向鏈表的每一個節(jié)點又包含兩部分,一部分是存放數(shù)據(jù)的變量data,另一部分是指向下一個節(jié)點的指針next。

2)鏈表的基本操作?
讀取O(n)、更新O(1)、插入O(1)、刪除O(1)。
3)鏈表 VS 數(shù)組
數(shù)組:適合多讀、插入刪除少的場景。
鏈表:適用于插入刪除多、讀少的場景。
3? 棧
1)什么是棧?
棧是一種線性邏輯數(shù)據(jù)結(jié)構(gòu),棧的元素只能后進(jìn)先出。最早進(jìn)入的元素存放的位置叫做棧底,最后進(jìn)入的元素存放的位置叫棧頂。
一個比喻,棧是一個一端封閉一端的開放的中空管子,隊列是兩端開放的中空管子。

2)如何實現(xiàn)棧?
數(shù)組實現(xiàn):

鏈表實現(xiàn):

3)棧的基本操作
入棧O(1)、出棧O(1)。
4)棧的應(yīng)用?
回溯歷史,比如方法調(diào)用棧。
頁面面包屑導(dǎo)航。
4? 隊列
1)什么是隊列?
一種線性邏輯數(shù)據(jù)結(jié)構(gòu),隊列的元素只能后進(jìn)后出。隊列的出口端叫做隊頭,隊列的入口端叫做隊尾。

2)如何實現(xiàn)隊列?
數(shù)組實現(xiàn):

鏈表實現(xiàn):

3)隊列的基本操作?
入隊 O(1)、出隊 O(1)。
4)隊列的應(yīng)用
消息隊列
多線程的等待隊列
網(wǎng)絡(luò)爬蟲的待爬URL隊列
5? 哈希表
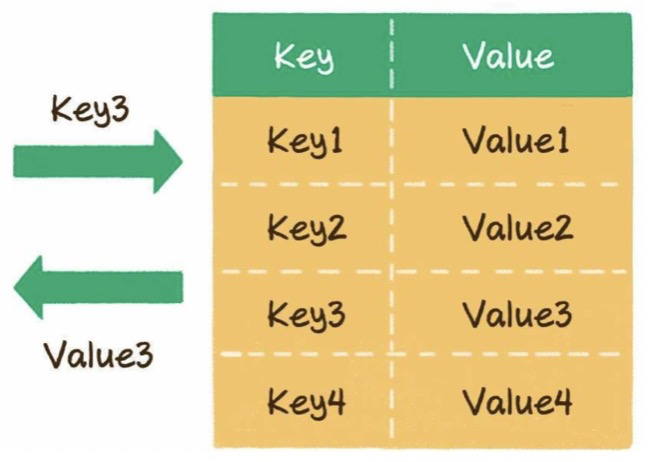
1)什么是哈希表?
一種邏輯數(shù)據(jù)結(jié)構(gòu),提供了鍵(key)和值(value)的映射關(guān)系。
2)哈希表的基本操作?
寫入:O(1)、讀取:O(1)、擴(kuò)容O(n)。
3)什么是哈希函數(shù)?
哈希表本質(zhì)上是一個數(shù)組,只是數(shù)組只能根據(jù)下標(biāo),像a[0] a[1] a[2] a[3] 這樣來訪問,而哈希表的key則是以字符串類型為主的。
通過哈希函數(shù),我們可以把字符串或其他類型的key,轉(zhuǎn)化成數(shù)組的下標(biāo)index。
如給出一個長度為8的數(shù)組,則:
當(dāng)key=001121時,
index = HashCode ("001121") % Array.length = 7當(dāng)key=this時,
index = HashCode ("this") % Array.length = 6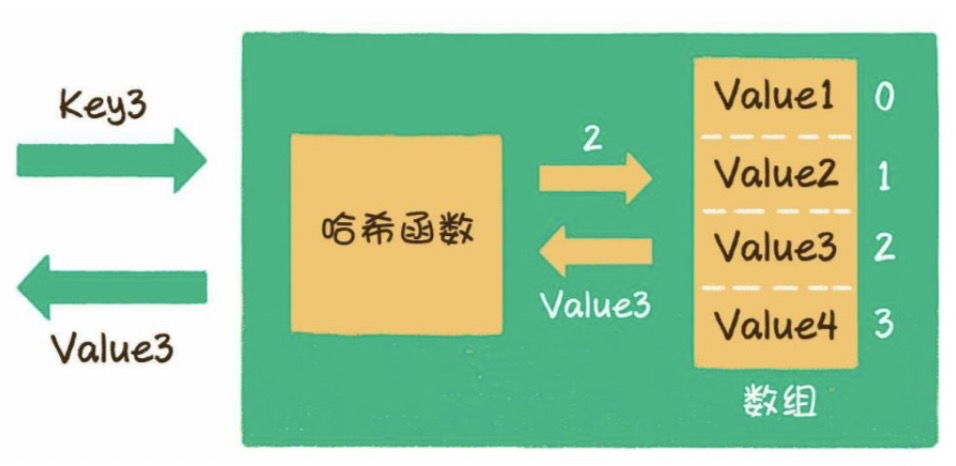
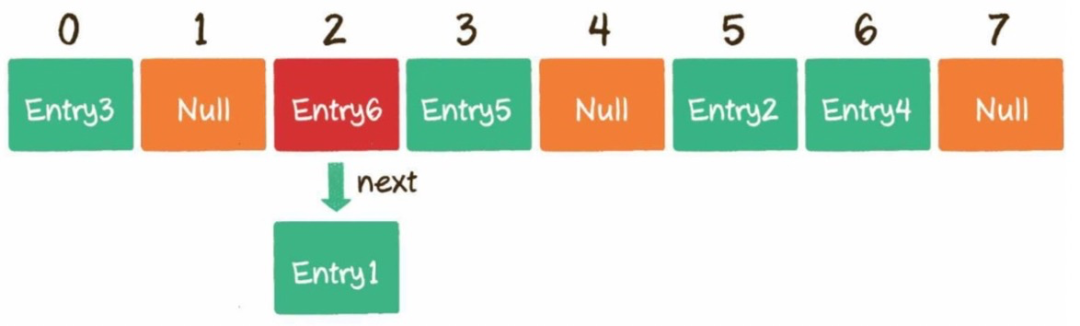
4)什么是哈希沖突?
不同的key通過哈希函數(shù)獲得的下標(biāo)有可能是相同的,例如002936這個key對應(yīng)的數(shù)組下標(biāo)是2,002947對應(yīng)的數(shù)組下標(biāo)也是2,這種情況就是哈希沖突。
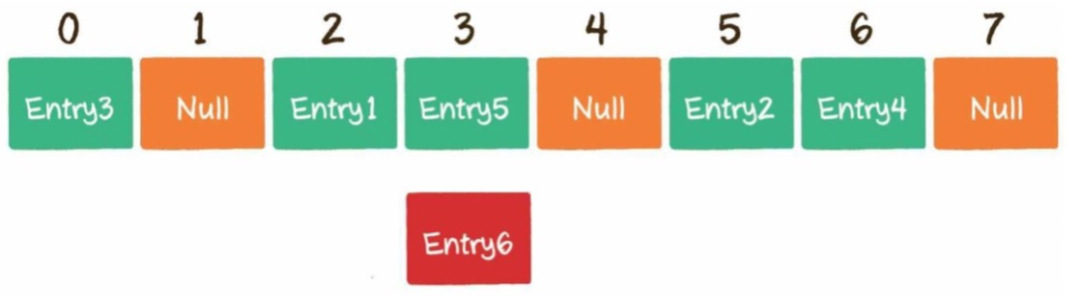
5)如何解決哈希沖突?
開放尋址法:例子Threadlocal。

鏈表法:例子Hashmap。
6? 樹
1)什么是樹?
樹(tree)是n(n≥0)個節(jié)點的有限集。
當(dāng)n=0時,稱為空樹。在任意一個非空樹中,有如下特點:
有且僅有一個特定的稱為根的節(jié)點。
當(dāng)n>1時,其余節(jié)點可分為m(m>0)個互不相交的有限集,每一個集合本身又是一個樹,并稱為根的子樹。
2)樹的遍歷?
(1)深度優(yōu)先
前序:根節(jié)點、左子樹、右子樹。
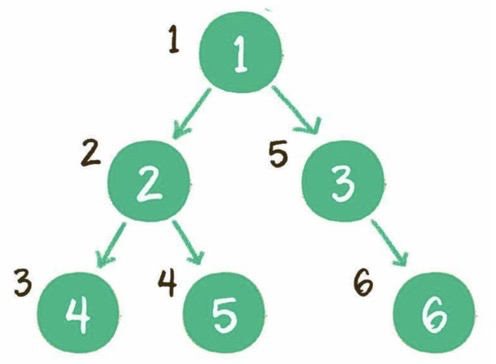
中序:左子樹、根節(jié)點、右子樹。
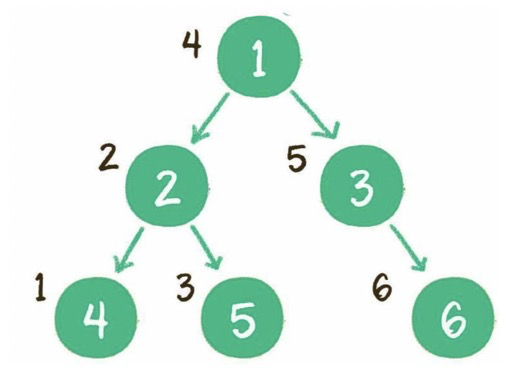
后序:左子樹、右子樹、根節(jié)點。
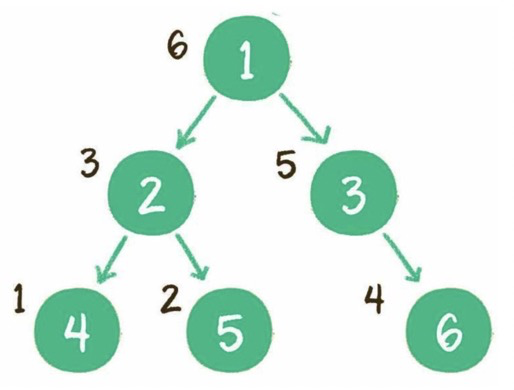
實現(xiàn)方式:遞歸或棧。
(2)廣度優(yōu)先
層序:一層一層遍歷。
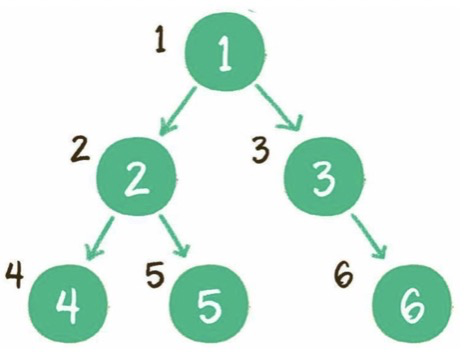
實現(xiàn)方式:隊列。
7? 二叉樹
1)什么是二叉樹?
二叉樹(binary tree)是樹的一種特殊形式。二叉,顧名思義,這種樹的每個節(jié)點最多有2個孩子節(jié)點。注意,這里是最多有2個,也可能只有1個,或者沒有孩子節(jié)點。
2)什么是滿二叉樹?
一個二叉樹的所有非葉子節(jié)點都存在左右孩子,并且所有葉子節(jié)點都在同一層級上,那么這個樹就是滿二叉樹。
3)什么是完全二叉樹?
對一個有n個節(jié)點的二叉樹,按層級順序編號,則所有節(jié)點的編號為從1到n。如果這個樹所有節(jié)點和同樣深度的滿二叉樹的編號為從1到n的節(jié)點位置相同,則這個二叉樹為完全二叉樹。
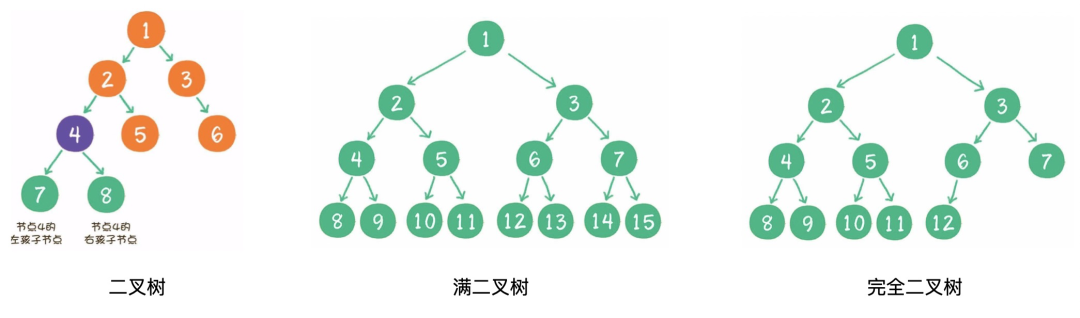
8? 二叉查找樹
1)什么是二叉查找樹?
二叉查找樹在二叉樹的基礎(chǔ)上增加了以下幾個條件:
如果左子樹不為空,則左子樹上所有節(jié)點的值均小于根節(jié)點的值。
如果右子樹不為空,則右子樹上所有節(jié)點的值均大于根節(jié)點的值。
左、右子樹也都是二叉查找樹。
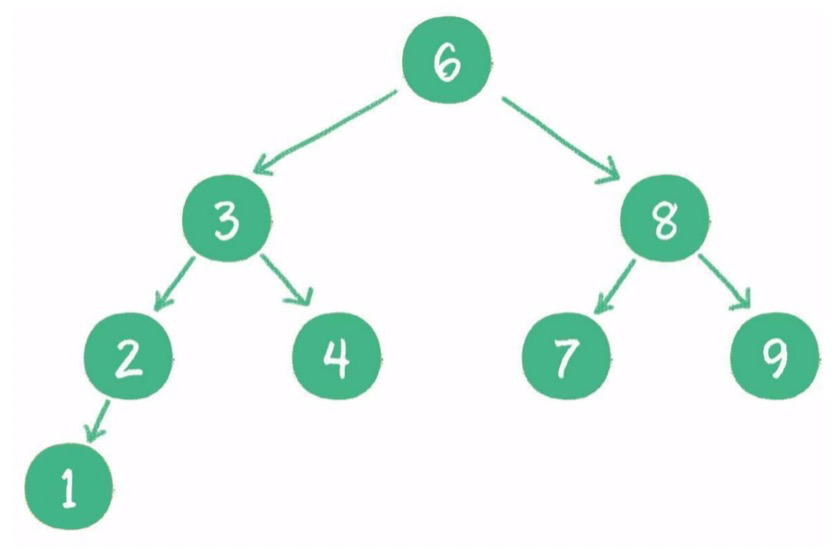
2)二叉查找樹的作用?
查找==》二分查找。
排序==》中序遍歷。
3)二叉樹的實現(xiàn)方式?
鏈表。
數(shù)組:對于稀疏二叉樹來說,數(shù)組表示法是非常浪費空間的。
?
9? 二叉堆
1)什么是二叉堆?
二叉堆是一種特殊的完全二叉樹,它分為兩個類型:最大堆和最小堆。
最大堆的任何一個父節(jié)點的值,都大于或等于它左、右孩子節(jié)點的值。
最小堆的任何一個父節(jié)點的值,都小于或等于它左、右孩子節(jié)點的值。
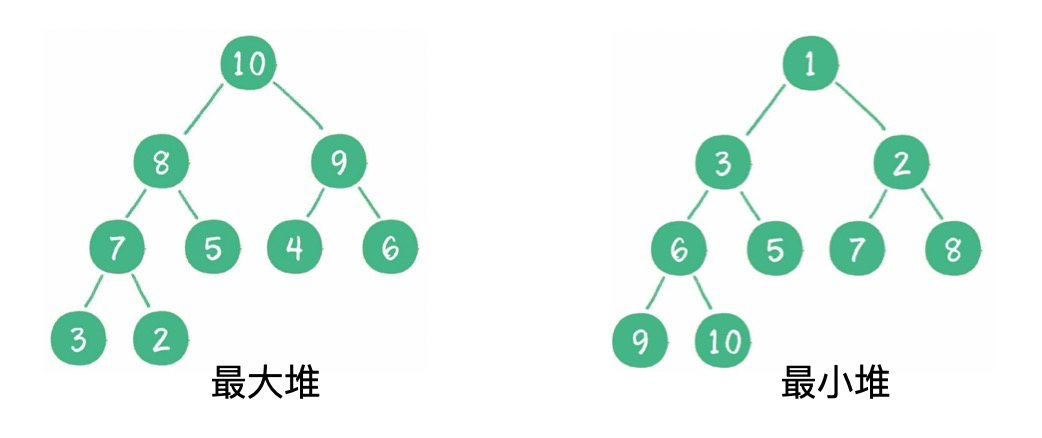
2)二叉堆的基本操作?
(1)插入:插入最末,節(jié)點上浮。
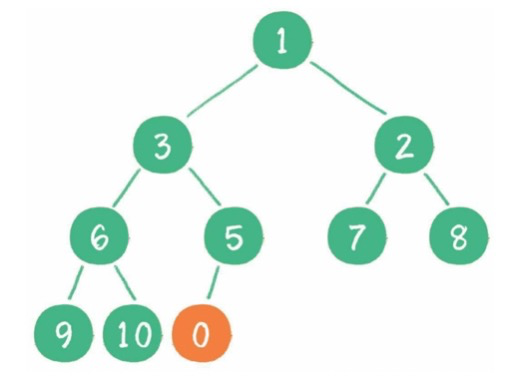
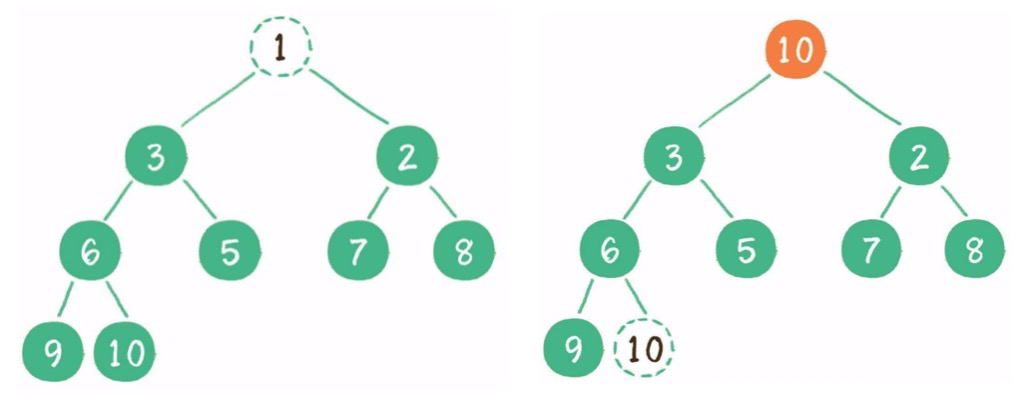
(2)刪除:刪除頭節(jié)點,尾節(jié)點放到頭部,再下沉。
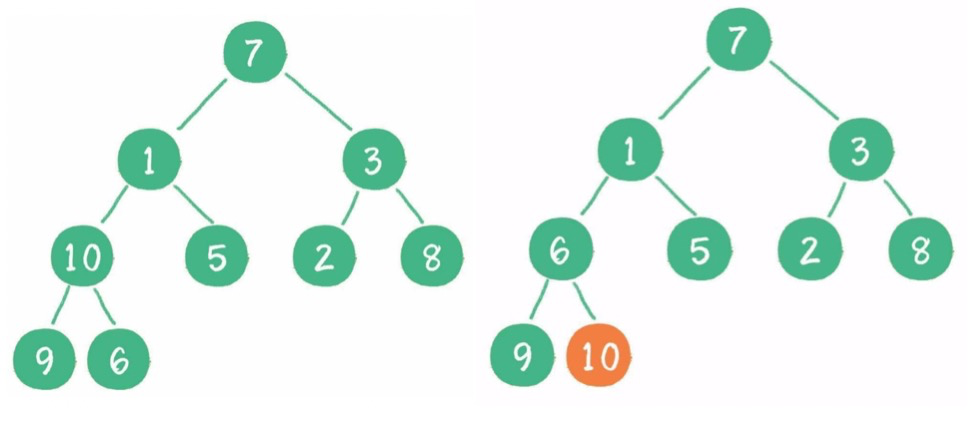
(3)構(gòu)建二叉堆:二叉樹==》二叉堆,所有非葉子節(jié)點依次下沉。
3)二叉堆的實現(xiàn)方式?
數(shù)組:
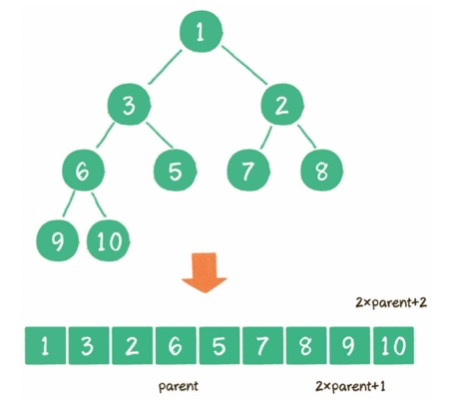
五? 常見排序算法
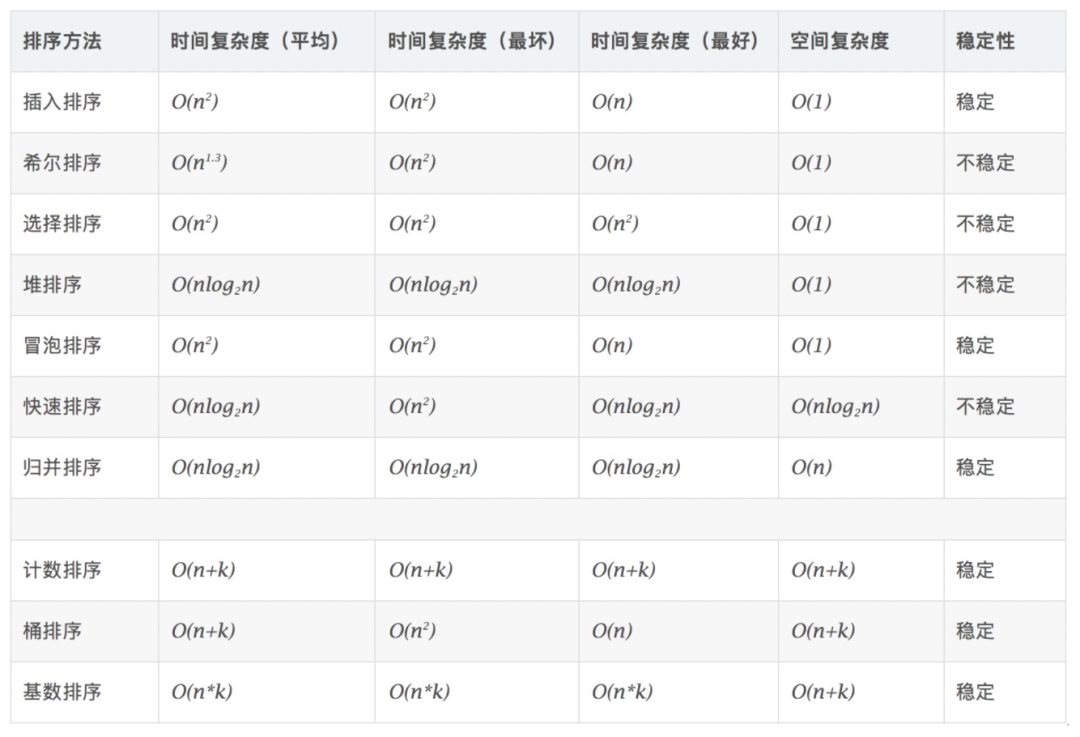
1? 十大經(jīng)典排序算法
2? 冒泡排序
1)算法描述
冒泡排序是一種簡單的排序算法。它重復(fù)地走訪過要排序的數(shù)列,一次比較兩個元素,如果它們的順序錯誤就把它們交換過來。走訪數(shù)列的工作是重復(fù)地進(jìn)行直到?jīng)]有再需要交換,也就是說該數(shù)列已經(jīng)排序完成。這個算法的名字由來是因為越小的元素會經(jīng)由交換慢慢“浮”到數(shù)列的頂端。?
2)實現(xiàn)步驟
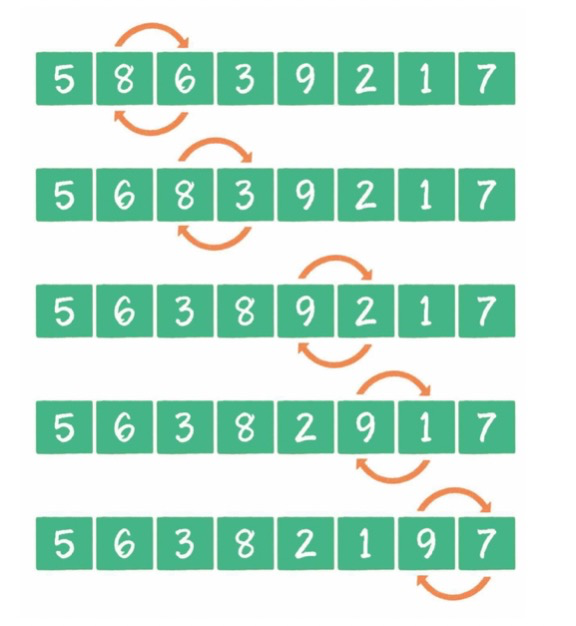
比較相鄰的元素。如果第一個比第二個大,就交換它們兩個。
對每一對相鄰元素作同樣的工作,從開始第一對到結(jié)尾的最后一對,這樣在最后的元素應(yīng)該會是最大的數(shù)。
針對所有的元素重復(fù)以上的步驟,除了最后一個。
重復(fù)步驟1~3,直到排序完成。
3)優(yōu)缺點
優(yōu)點:實現(xiàn)和理解簡單。
缺點:時間復(fù)雜度是O(n^2),排序元素多時效率比較低。
4)適用范圍
數(shù)據(jù)已經(jīng)基本有序,且數(shù)據(jù)量較小的場景。
5)場景優(yōu)化
(1)已經(jīng)有序了還再繼續(xù)冒泡問題
本輪排序中,元素沒有交換,則isSorted為true,直接跳出大循環(huán),避免后續(xù)無意義的重復(fù)。
(2)部分已經(jīng)有序了,下一輪的時候但還是會被遍歷
記錄有序和無序數(shù)據(jù)的邊界,有序的部分在下一輪就不用遍歷了。
(3)只有一個元素不對,但需要走完全部輪排序
雞尾酒排序:元素的比較和交換是雙向的,就像搖晃雞尾酒一樣。
?
3? 歸并排序
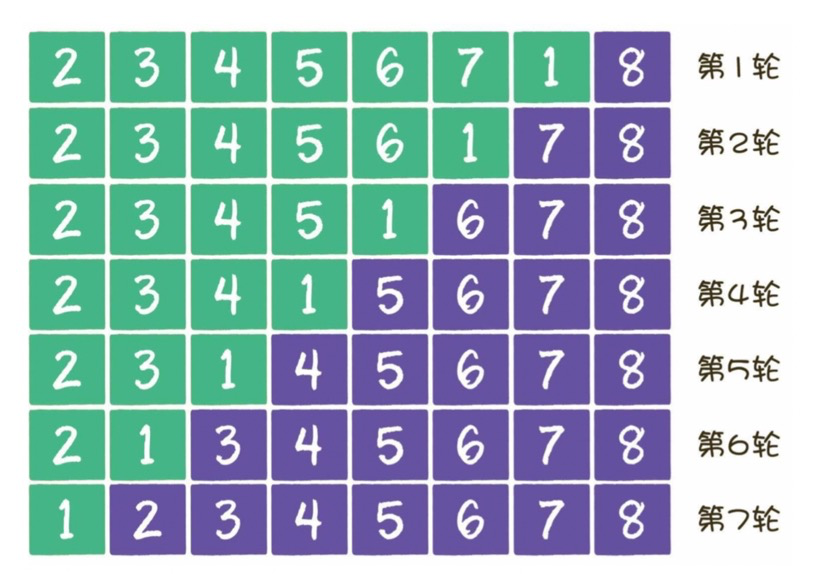
1)算法描述
歸并排序是建立在歸并操作上的一種有效的排序算法。該算法是采用分治法的一個非常典型的應(yīng)用。遞歸的把當(dāng)前序列分割成兩半(分割),在保持元素順序的同時將上一步得到的子序列集成到一起(歸并),最終形成一個有序數(shù)列。
2)實現(xiàn)步驟
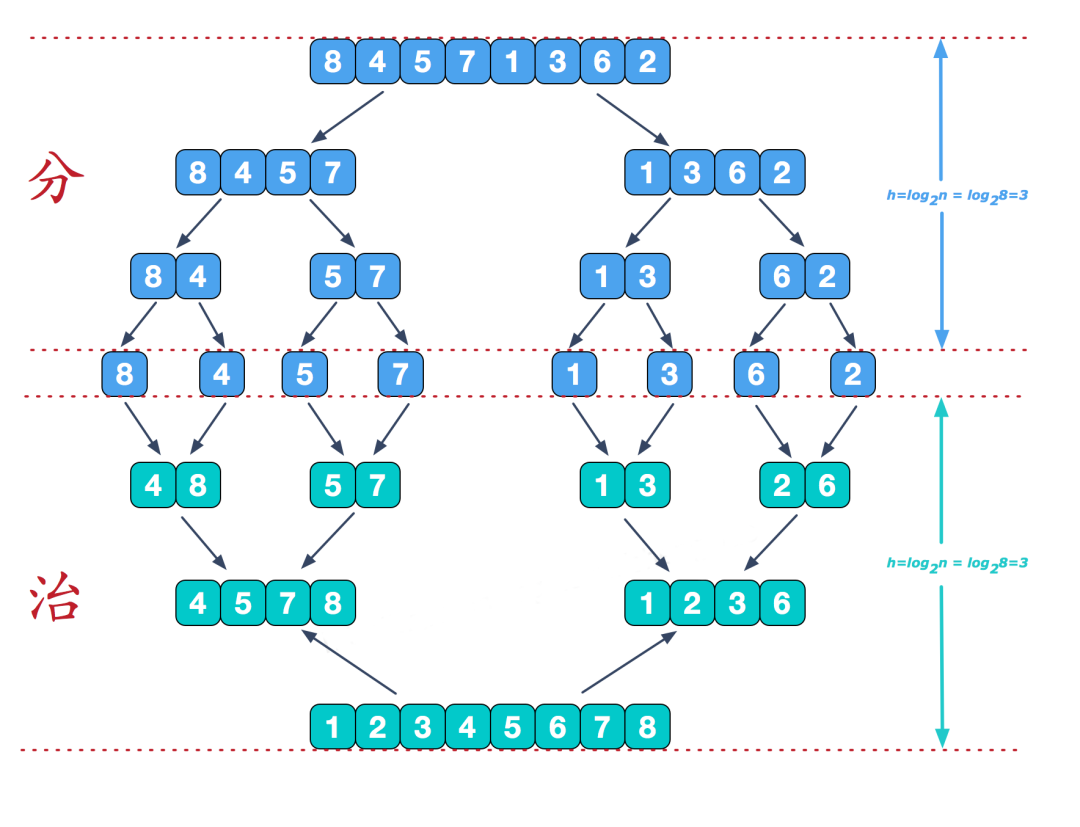
圖源:https://www.cnblogs.com/chengxiao/p/6194356.html
把長度為n的輸入序列分成兩個長度為n/2的子序列。
對這兩個子序列分別采用歸并排序。
將兩個排序好的子序列合并成一個最終的排序序列。
3)優(yōu)缺點
優(yōu)點:
性能好且穩(wěn)定,時間復(fù)雜度為O(nlogn) 。
穩(wěn)定排序,適用場景更多。
缺點:
非原地排序,空間復(fù)雜度高。
4)適用范圍
大數(shù)據(jù)量且期望要求排序穩(wěn)定的場景。
4? 快速排序
1)算法描述
快速排序使用分治法策略來把一個序列分為較小和較大的2個子序列,然后遞歸地排序兩個子序列,以達(dá)到整個數(shù)列最終有序。
2)實現(xiàn)步驟
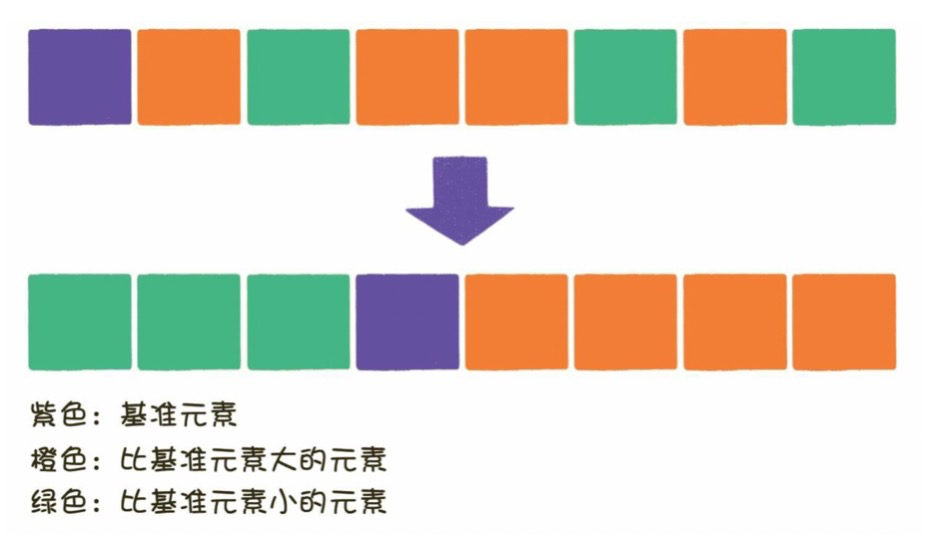
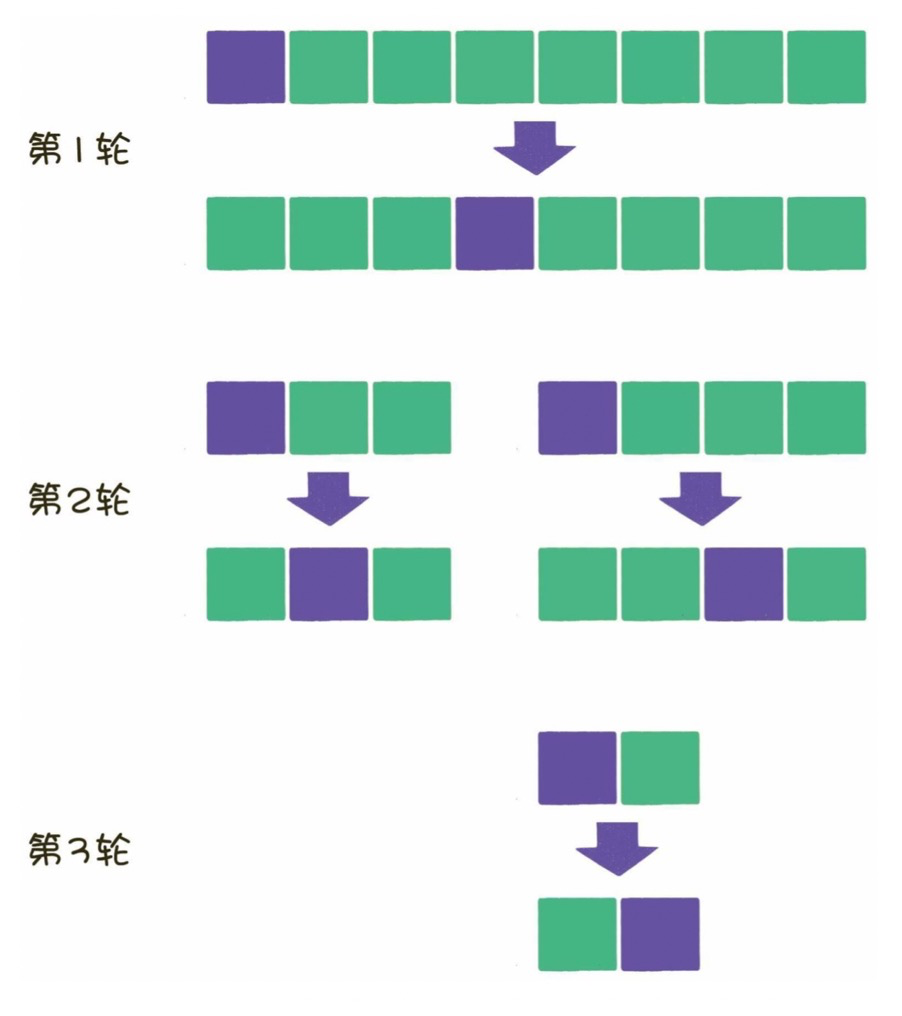
從數(shù)列中挑出一個元素,稱為 “基準(zhǔn)值”(pivot)。
重新排序數(shù)列,所有元素比基準(zhǔn)值小的擺放在基準(zhǔn)前面,所有元素比基準(zhǔn)值大的擺在基準(zhǔn)的后面(相同的數(shù)可以到任一邊)。在這個分區(qū)退出之后,該基準(zhǔn)就處于數(shù)列的中間位置。這個稱為分區(qū)(partition)操作。
遞歸地對【小于基準(zhǔn)值元素的子數(shù)列】和【大于基準(zhǔn)值元素的子數(shù)列】進(jìn)行排序。
3)優(yōu)缺點
優(yōu)點:
性能較好,時間復(fù)雜度最好為O(nlogn),大多數(shù)場景性能都接近最優(yōu)。
原地排序,時間復(fù)雜度優(yōu)于歸并排序。
缺點:
部分場景,排序性能最差為O(n^2)。
不穩(wěn)定排序。
4)適用范圍
大數(shù)據(jù)量且不要求排序穩(wěn)定的場景。
5)場景優(yōu)化
(1)每次的基準(zhǔn)元素都選中最大或最小元素
隨機(jī)選擇基準(zhǔn)元素,而不是選擇第一個元素。
三數(shù)取中法,隨機(jī)選擇三個數(shù),取中間數(shù)為基準(zhǔn)元素。
(2)數(shù)列含有大量重復(fù)數(shù)據(jù)
大于、小于、等于基準(zhǔn)值。
(3)快排的性能優(yōu)化
雙軸快排:2個基準(zhǔn)數(shù),例子:Arrays.sort() 。
5? 堆排序
1)算法描述
堆排序(Heapsort)是指利用堆這種數(shù)據(jù)結(jié)構(gòu)所設(shè)計的一種排序算法。堆積是一個近似完全二叉樹的結(jié)構(gòu),并同時滿足堆積的性質(zhì):即子結(jié)點的鍵值或索引總是小于(或者大于)它的父節(jié)點。
2)實現(xiàn)步驟
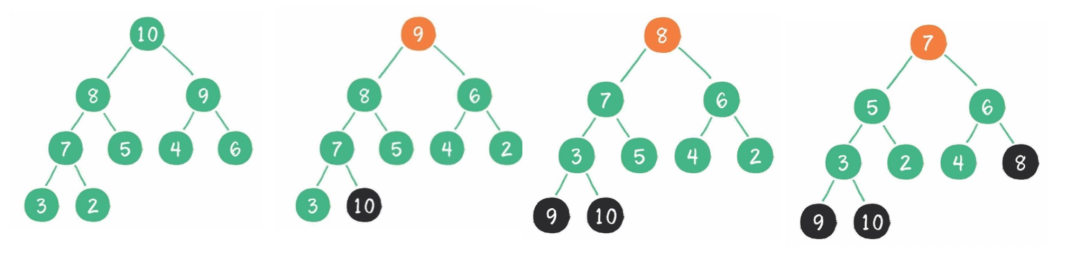
將初始待排序關(guān)鍵字序列(R1,R2….Rn)構(gòu)建成最大堆,此堆為初始的無序區(qū)。
將堆頂元素R[1]與最后一個元素R[n]交換,此時得到新的無序區(qū)(R1,R2,……Rn-1)和新的有序區(qū)(Rn),且滿足R[1,2…n-1]<=R[n]。
由于交換后新的堆頂R[1]可能違反堆的性質(zhì),因此需要對當(dāng)前無序區(qū)(R1,R2,……Rn-1)調(diào)整為新堆,然后再次將R[1]與無序區(qū)最后一個元素交換,得到新的無序區(qū)(R1,R2….Rn-2)和新的有序區(qū)(Rn-1,Rn)。不斷重復(fù)此過程直到有序區(qū)的元素個數(shù)為n-1,則整個排序過程完成。
3)優(yōu)缺點
優(yōu)點:
性能較好,時間復(fù)雜度為O(nlogn)。
時間復(fù)雜度比較穩(wěn)定。
輔助空間復(fù)雜度為O(1)。
缺點:
數(shù)據(jù)變動的情況下,堆的維護(hù)成本較高。
4)適用范圍
數(shù)據(jù)量大且數(shù)據(jù)呈流式輸入的場景。
5)為什么實際情況快排比堆排快?
堆排序的過程可知,建立最大堆后,會將堆頂?shù)脑睾妥詈笠粋€元素對調(diào),然后讓那最后一個元素從頂上往下沉到恰當(dāng)?shù)奈恢茫驗榈撞康脑匾欢ㄊ潜容^小的,下沉的過程中會進(jìn)行大量的近乎無效的比較。所以堆排雖然和快排一樣復(fù)雜度都是O(NlogN),但堆排復(fù)雜度的常系數(shù)更大。
6? 計數(shù)排序
1)算法描述
計數(shù)排序不是基于比較的排序算法,其核心在于將輸入的數(shù)據(jù)值轉(zhuǎn)化為鍵存儲在額外開辟的數(shù)組空間中。作為一種線性時間復(fù)雜度的排序,計數(shù)排序要求輸入的數(shù)據(jù)必須是有確定范圍的整數(shù)。
2)實現(xiàn)步驟
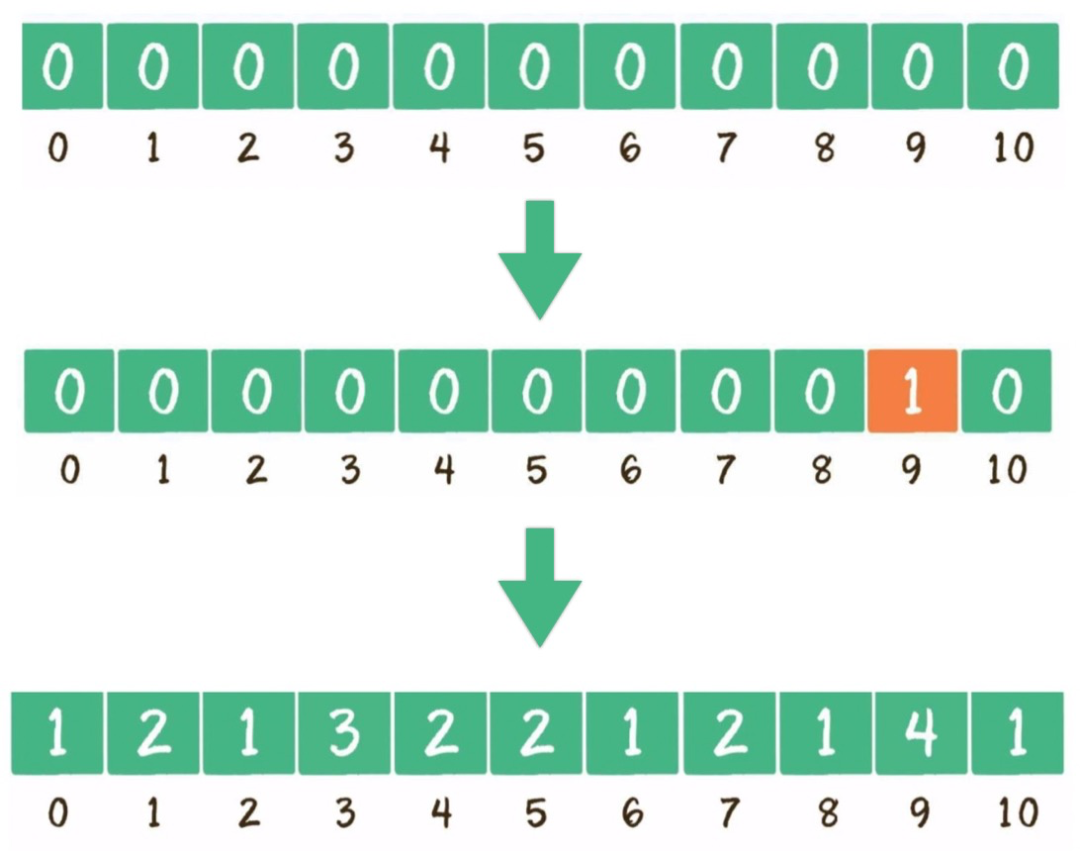
找出待排序的數(shù)組中最大元素。
構(gòu)建一個數(shù)組C,長度為最大元素值+1。
遍歷無序的隨機(jī)數(shù)列,每一個整數(shù)按照其值對號入座,對應(yīng)數(shù)組下標(biāo)的值加1。
遍歷數(shù)組C,輸出數(shù)組元素的下標(biāo)值,元素的值是幾就輸出幾次。
3)優(yōu)缺點
優(yōu)點:
性能完爆比較排序,時間復(fù)雜度為O(n+k),k為數(shù)列最大值。
穩(wěn)定排序。
缺點:
適用范圍比較狹窄。
4)適用范圍
數(shù)列元素是整數(shù),當(dāng)k不是很大且序列比較集中時適用。
5)場景優(yōu)化
(1)數(shù)字不是從0開始,會存在空間浪費的問題
數(shù)列的最小值作為偏移量,以數(shù)列最大值-最小值+1作為統(tǒng)計數(shù)組的長度。
7? 桶排序
1)算法描述
桶排序是計數(shù)排序的升級版。它利用了函數(shù)的映射關(guān)系,高效與否的關(guān)鍵就在于這個映射函數(shù)的確定。實現(xiàn)原理:假設(shè)輸入數(shù)據(jù)服從均勻分布,將數(shù)據(jù)分到有限數(shù)量的桶里,每個桶再分別排序(有可能再使用別的排序算法或是以遞歸方式繼續(xù)使用桶排序進(jìn)行排序)。
2)實現(xiàn)步驟
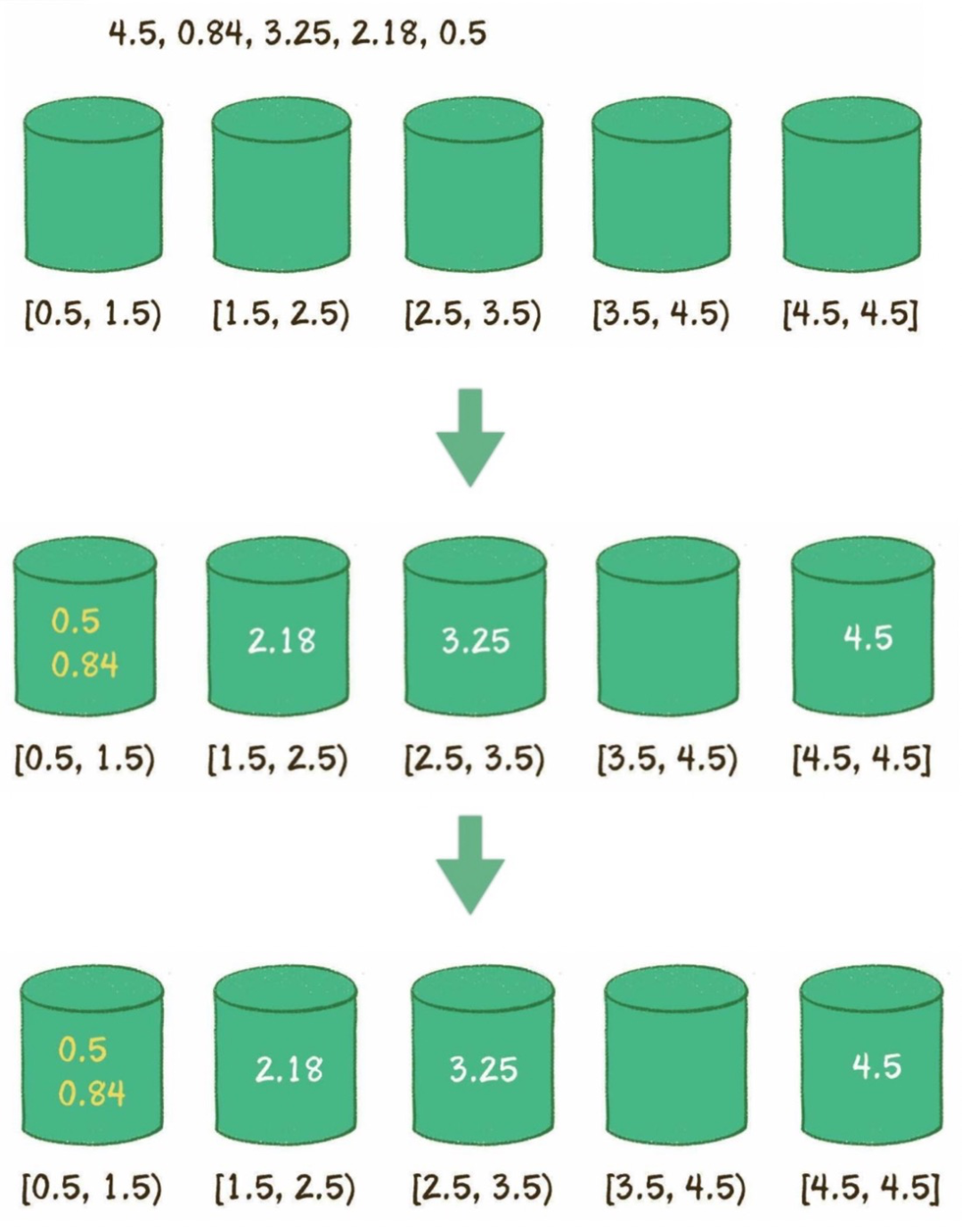
創(chuàng)建桶,區(qū)間跨度=(最大值-最小值)/(桶的數(shù)量-1)。
遍歷數(shù)列,對號入座。
每個桶內(nèi)進(jìn)行排序,可選擇快排等。
遍歷所有的桶,輸出所有元素。
3)優(yōu)缺點
優(yōu)點:
最優(yōu)時間復(fù)雜度為O(n),完爆比較排序算法。
缺點:
適用范圍比較狹窄。
時間復(fù)雜度不穩(wěn)定。
4)適用范圍
數(shù)據(jù)服從均勻分布的場景。
8? 性能對比
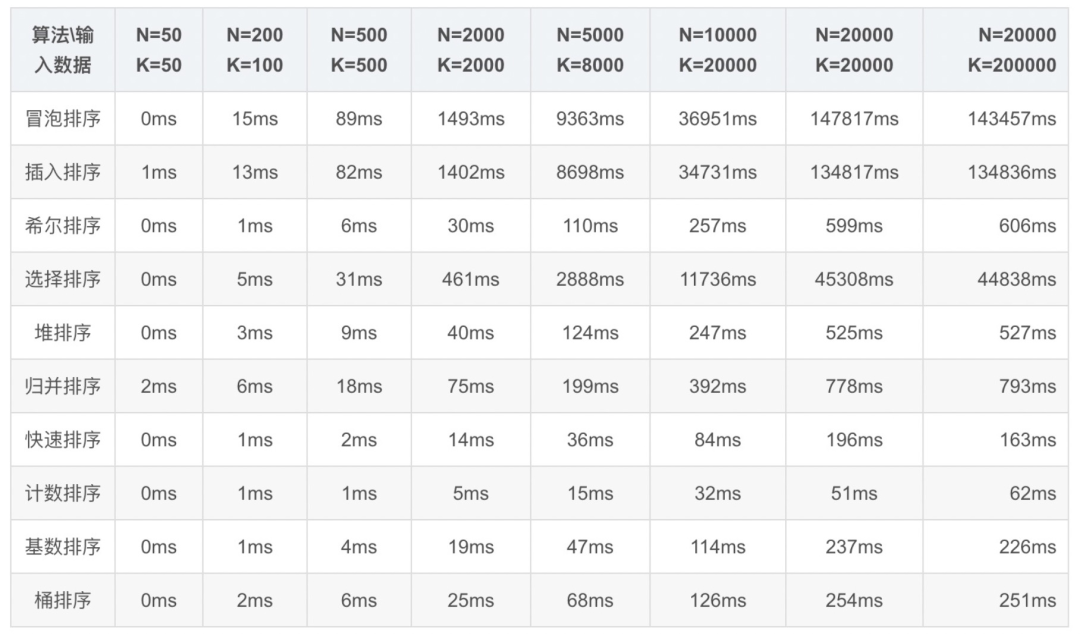
隨機(jī)生成區(qū)間0 ~ K之間的序列,共計N個數(shù)字,利用各種算法進(jìn)行排序,記錄排序所需時間。
參考內(nèi)容及圖源
[1]《漫畫算法:小灰的算法之旅》
[2]《算法(第4版)》
[3]《算法圖解》
[4]《劍指Offer》
[5]十大經(jīng)典排序算法(動圖演示)
https://www.cnblogs.com/onepixel/p/7674659.html[6]維基百科
https://zh.wikipedia.org/wiki/Wikipedia:%E9%A6%96%E9%A1%B5
推薦閱讀:
如何設(shè)置與查看Linux系統(tǒng)中的環(huán)境變量?
5T技術(shù)資源大放送!包括但不限于:C/C++,Linux,Python,Java,PHP,人工智能,單片機(jī),樹莓派,等等。在公眾號內(nèi)回復(fù)「1024」,即可免費獲取!!