
pyspider爬取王者榮耀數(shù)據(jù)(下)
咪哥雜談

本篇閱讀時間約為 4 分鐘。
1
前言
本篇來繼續(xù)完成數(shù)據(jù)的爬取。離上周文章已經(jīng)過了一星期了,忘記的可以回顧下:《pyspider爬取王者榮耀數(shù)據(jù)(上)》
上篇文章中寫到的,無非就是頭像圖片的懶加載是個小困難點,其余部分,操作起來使用網(wǎng)頁自帶的 css 選擇器很好選擇。
2
pyspider爬取數(shù)據(jù)
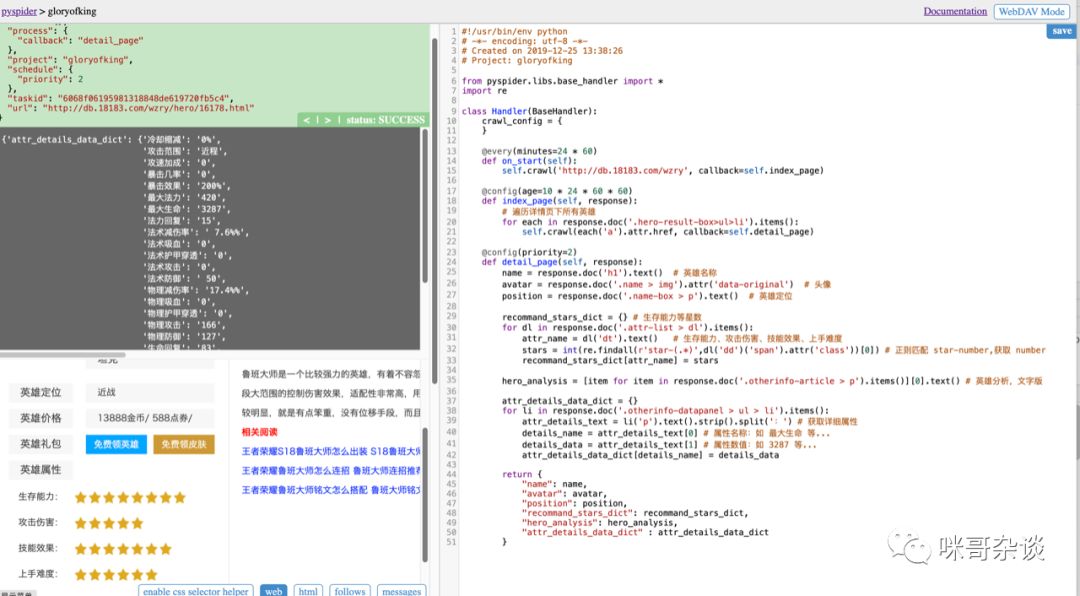
1. 完善上周的代碼
右側(cè)是完善的代碼,將具體的目標(biāo)爬取了下來,并且可以看到左側(cè)上方已經(jīng)輸出了響應(yīng)的內(nèi)容。
寫完代碼后,別忘了點擊右上方的 save 按鈕。(具體代碼文末有獲取方式)
2. pyspider啟動爬取
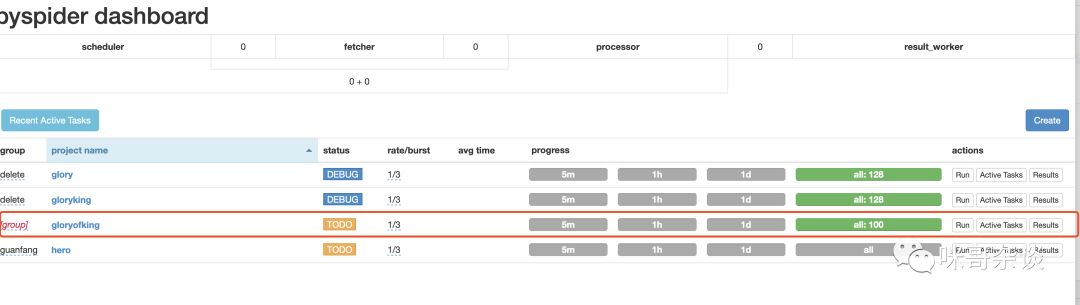
寫好了代碼后,如何去啟動此爬蟲呢?
首先回到配置任務(wù)的界面,畫紅線是我現(xiàn)在編寫的任務(wù):
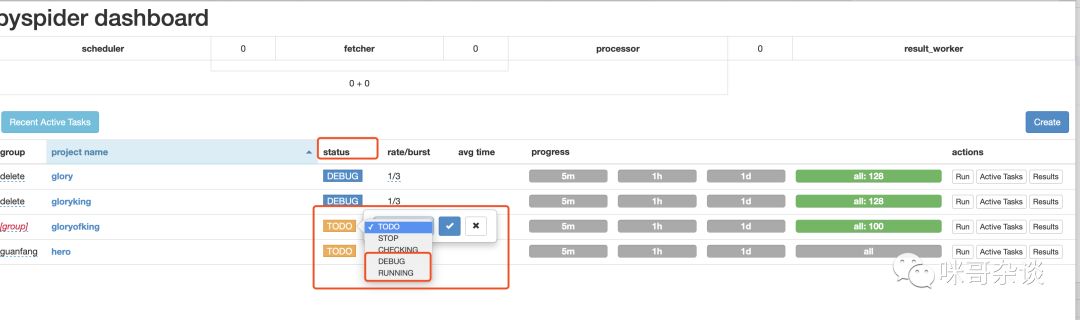
可以看到有個 status 欄,你需要將此狀態(tài)換成 debug 或者 run 才行。
點擊 run ,即可運行,同時progress的進度條也會變顏色:
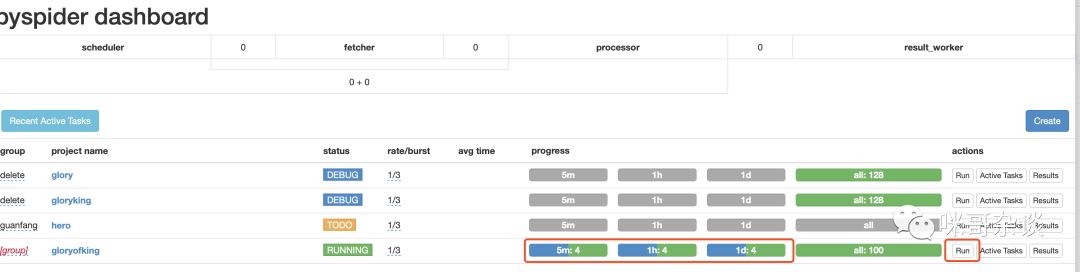
3. 獲取數(shù)據(jù)
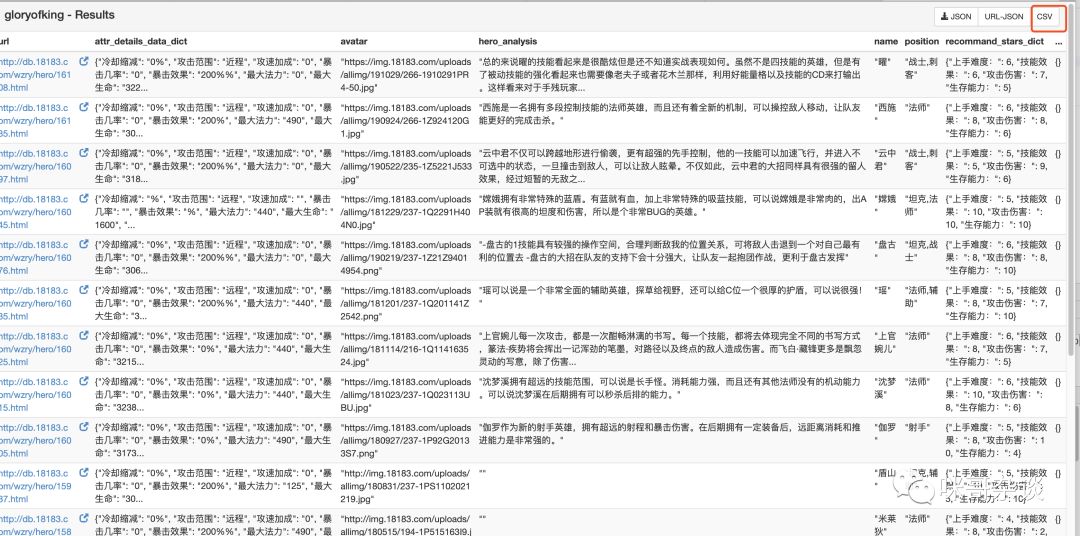
4. 關(guān)于數(shù)據(jù)落地于數(shù)據(jù)庫中
此時的做法,引入相應(yīng)的數(shù)據(jù)庫即可,以 mysql 為例。下面提供一個編程的思路,無代碼。
在 pyspider?提供的?Handler 類中,可以自行實現(xiàn)一個?__init__ 方法(學(xué)過面向?qū)ο蟮耐瑢W(xué)應(yīng)該不陌生),在此方法中,對連接 mysql 數(shù)據(jù)庫的操作進行初始化,生成一個實例對象變量 db。
這樣一來,在 detail_page 函數(shù)中,我們便可以用 self.db 的方式來對 mysql 實例進行入庫操作。
3
總結(jié)
在此次爬取中,圖片的懶加載可以注意下,找到對應(yīng)js即可。
對比一下用框架來爬取數(shù)據(jù),和我們自己寫代碼的區(qū)別:
有想要看 pyspider 源碼的同學(xué),后臺回復(fù)?pyspider 即可獲得。
硬核!用Python為你的父母送上每日天氣提醒!
 你點的每個在看,我都認真當(dāng)成了喜歡
你點的每個在看,我都認真當(dāng)成了喜歡評論
圖片
表情