
帶你了解虛擬現(xiàn)實(VR)的原理
大家好,我是陳銳。
感謝大家關(guān)注CRBrain腦世界公眾號。
今天分享內(nèi)容來源網(wǎng)絡(luò)整理,僅供參考分享。
最近一年,我們身邊出現(xiàn)了很多基于虛擬現(xiàn)實(VR)技術(shù)的新玩具:比如VR眼鏡,明明只是播放了一些逼真立體的虛擬畫面,卻讓你感覺這些虛擬的畫面才是現(xiàn)實。
這是因為,虛擬現(xiàn)實內(nèi)容模擬了人眼的視覺體驗:
可以用一個小實驗來感受一下
?1.當你分別遮住一只眼睛,用另一只眼睛看你的手時,兩只眼睛各自看到的圖像,會有一些差別。這個就叫做人眼的雙目視差。

2.當你把手機放在面前,把頭歪到左邊,再歪到右邊時,你的眼睛看到的就分別是手機的左邊框和右邊框。這個叫做人眼的移動視差。
?


3.而當你攤開兩只手,眼睛聚焦到不同的手上時,會依次看到左手清晰右手模糊,以及左手模糊右手清晰的圖像。這是人眼的變焦功能。


因為人眼天然擁有以上這些視覺差異和變焦功能,你眼前的這個場景,才能在大腦的加工后變得立體和縱深;
人眼這么復雜的視覺體驗,虛擬現(xiàn)實是怎么模仿出來的呢?
?
我們來做一個實驗:
如果把相機放在一個點上,拍攝廣場上一遠一近的兩個人。那么當鏡頭對焦在不同的人身上時,就能拍到2張只有一個人清晰,而其他部分虛化的照片。
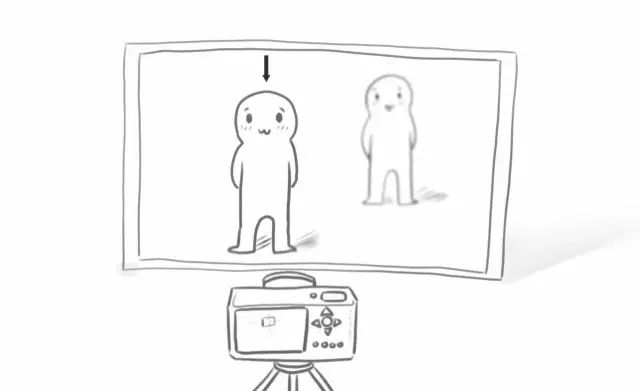
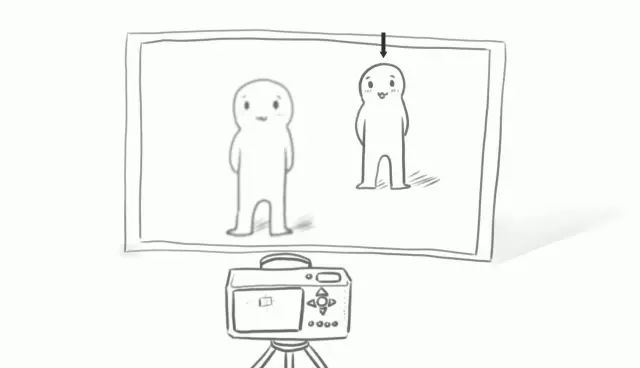
?
如果在這兩個人的斜后方再加一個人,整個場景里就出現(xiàn)了3個遠近不同的人。那么鏡頭對焦在不同的人身上時,我們就能拍到3張只有一個人清晰,而其他部分虛化的照片。
?
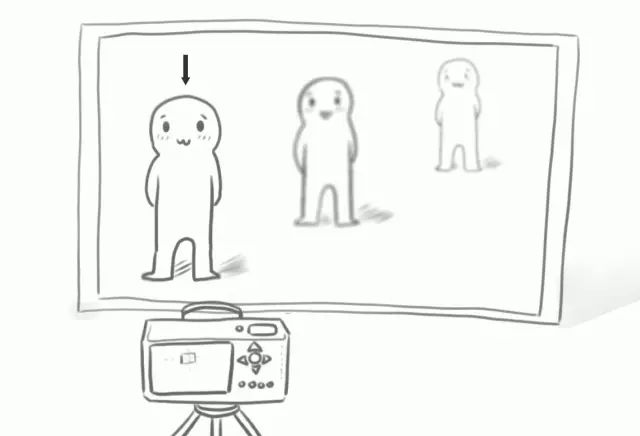
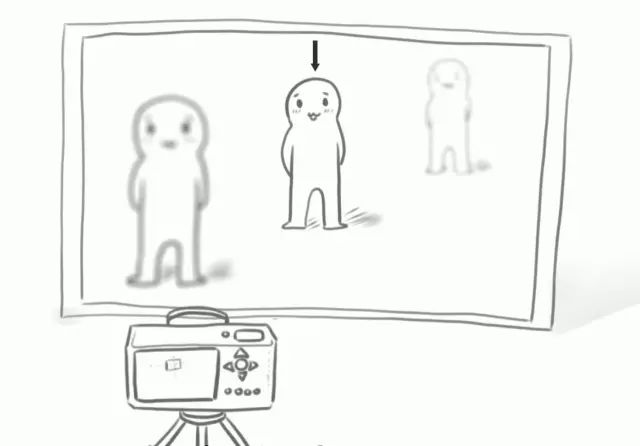
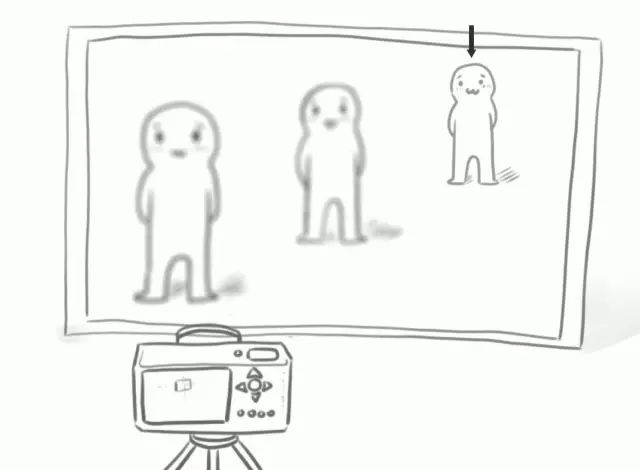
?
而如果再不斷地向斜后方增加人數(shù),那么這個相機就能拍攝出無數(shù)張只有一個人清晰,而其他部分虛化的照片。
?

現(xiàn)在,見證奇跡的時刻來了。
?
如果把這些照片疊在一起,它們實際上就粗略地組成了在這個角度上,“很多人站在廣場上”,這樣的一個立體場景;
?
換句話說,相機在這個點上能夠“看”到的整個立體的場景,可以被豎著切成無數(shù)張切片,也就是這無數(shù)張照片。
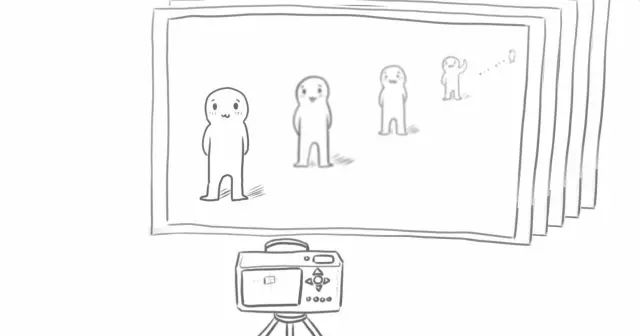
再模仿人的雙眼,以及在不同位置上的視角,再把眼前的場景從各個角度都切片,那么整個場景里所有角度的切片疊加在一起,就最終組成了一個完整的立體場景。
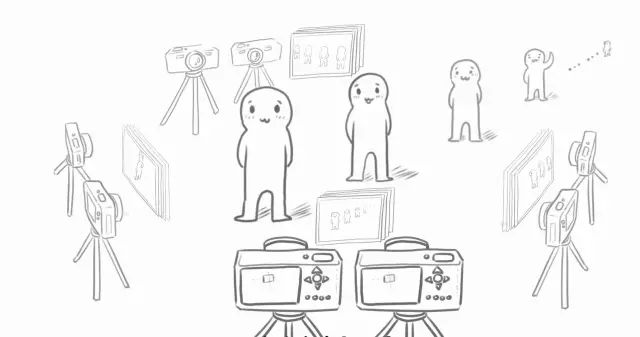

現(xiàn)在的虛擬現(xiàn)實,卻可以通過采集整個場景中的很多切片,甚至是所有切片,來生成一個模擬人眼視覺的切片數(shù)據(jù)庫;
?
這個數(shù)據(jù)庫中的圖像經(jīng)過處理,就能在顯示屏上再復現(xiàn)出立體的場景了。

?
現(xiàn)在最先進的顯示技術(shù),已經(jīng)可以根據(jù)體驗者眼睛和身體的動作,實時切換數(shù)據(jù)庫中的切片。
?
不管你在某個瞬間是移動了位置,還是眼睛切換了焦點,計算機都可以通過算法,篩選出你做出這個動作的瞬間應(yīng)該看到的那一個切片,并且經(jīng)過快速加工,把那個切片呈現(xiàn)在你眼前的顯示屏上。

?
隨著動作變化,眼睛在這一瞬間該看到哪張切片,虛擬現(xiàn)實就給你看哪張切片。
?
這樣,看著眼前這些人工加工的圖像,就如同在現(xiàn)實世界中了。
?

本文僅供學習參考,不作其它用途,有任何疑問及侵權(quán),掃描以下公眾號二維碼添加交流:
更多詳細內(nèi)容,僅在知識星球發(fā)布: