
2021年11月23日,某車企NLP算法崗面試題分享!
文 | 七月在線
編 | 小七

問(wèn)題1、CNN原理及優(yōu)缺點(diǎn)
CNN是一種前饋神經(jīng)網(wǎng)絡(luò),通常包含5層,輸入層,卷積層,激活層,池化層,全連接FC層,其中核心部分是卷積層和池化層。
優(yōu)點(diǎn):共享卷積核,對(duì)高維數(shù)據(jù)處理無(wú)壓力;無(wú)需手動(dòng)選取特征。
缺點(diǎn):需要調(diào)參;需要大量樣本。

問(wèn)題2、word2vec的兩種優(yōu)化方式
第一種改進(jìn)為基于層序 softmax 的模型。
首先構(gòu)建哈夫曼樹(shù),即以詞頻作為 n 個(gè)詞的節(jié)點(diǎn)權(quán)重,不斷將最小權(quán)重的節(jié)點(diǎn)進(jìn)行合并,最終形成一棵樹(shù),權(quán)重越大的葉子結(jié)點(diǎn)越靠近根節(jié)點(diǎn),權(quán)重越小的葉子結(jié)點(diǎn)離根節(jié)點(diǎn)越遠(yuǎn)。
然后進(jìn)行哈夫曼編碼,即對(duì)于除根節(jié)點(diǎn)外的節(jié)點(diǎn),左子樹(shù)編碼為1,右子樹(shù)編碼為0。
最后采用二元邏輯回歸方法,沿著左子樹(shù)走就是負(fù)類,沿著右子樹(shù)走就是正類,從訓(xùn)練樣本中學(xué)習(xí)邏輯回歸的模型參數(shù)。
優(yōu)點(diǎn):計(jì)算量由V(單詞總數(shù))減小為 log2V;高頻詞靠近根節(jié)點(diǎn),所需步數(shù)小,低頻詞遠(yuǎn)離根節(jié)點(diǎn)。
第二種改進(jìn)為基于負(fù)采樣的模型。
通過(guò)采樣得到少部分的負(fù)樣本,對(duì)正樣本和少部分的負(fù)樣本,利用二元邏輯回歸模型,通過(guò)梯度上升法,來(lái)得到每個(gè)詞對(duì)應(yīng)的模型參數(shù)。具體負(fù)采樣的方法為:根據(jù)詞頻進(jìn)行采樣,也就是詞頻越大的詞被采到的概率也越大。
問(wèn)題3、描述下CRF模型及應(yīng)用
給定一組輸入隨機(jī)變量的條件下另一組輸出隨機(jī)變量的條件概率分布密度。條件隨機(jī)場(chǎng)假設(shè)輸出變量構(gòu)成馬爾科夫隨機(jī)場(chǎng),而我們平時(shí)看到的大多是線性鏈條隨機(jī)場(chǎng),也就是由輸入對(duì)輸出進(jìn)行預(yù)測(cè)的判別模型。求解方法為極大似然估計(jì)或正則化的極大似然估計(jì)。
CRF模型通常應(yīng)用于優(yōu)化命名實(shí)體識(shí)別任務(wù)。
問(wèn)題4、CNN的卷積公式
卷積層計(jì)算公式如下:
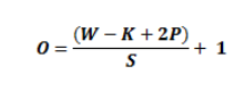
其中,W為輸入大小,K為卷積核大小,P為 padding大小,S為步幅。
如果,想保持卷積前后的特征圖大小相同,通常會(huì)設(shè)定padding為:
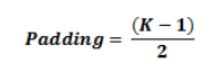
問(wèn)題5、邏輯回歸用的什么損失函數(shù)
邏輯回歸是在數(shù)據(jù)服從伯努利分布的假設(shè)下,通過(guò)極大似然的方法,運(yùn)用梯度下降法來(lái)求解參數(shù),從而達(dá)到將數(shù)據(jù)二分類的目的。
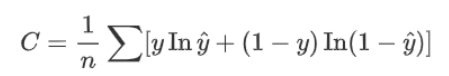
問(wèn)題6、transformer結(jié)構(gòu)
Transformer本身是一個(gè)典型的encoder-decoder模型,Encoder端和Decoder端均有6個(gè)Block,Encoder端的Block包括兩個(gè)模塊,多頭self-attention模塊以及一個(gè)前饋神經(jīng)網(wǎng)絡(luò)模塊;Decoder端的Block包括三個(gè)模塊,多頭self-attention模塊,多頭Encoder-Decoder attention交互模塊,以及一個(gè)前饋神經(jīng)網(wǎng)絡(luò)模塊;需要注意:Encoder端和Decoder端中的每個(gè)模塊都有殘差層和Layer Normalization層。
問(wèn)題7、elmo 和 Bert的區(qū)別
BERT采用的是Transformer架構(gòu)中的Encoder模塊;
GPT采用的是Transformer架構(gòu)中的Decoder模塊;
ELMo采用的雙層雙向LSTM模塊。
問(wèn)題8、elmo 和 word2vec 的區(qū)別
elmo 詞向量是包含上下文信息的,不是一成不變的,而是根據(jù)上下文而隨時(shí)變化。
問(wèn)題9、lstm 與 GRU區(qū)別
(1)LSTM和GRU的性能在很多任務(wù)上不分伯仲;
(2)GRU參數(shù)更少,因此更容易收斂,但是在大數(shù)據(jù)集的情況下,LSTM性能表現(xiàn)更好;
(3)GRU 只有兩個(gè)門(mén)(update和reset),LSTM 有三個(gè)門(mén)(forget,input,output),GRU 直接將hidden state 傳給下一個(gè)單元,而 LSTM 用memory cell 把hidden state 包裝起來(lái)。
xgboost目標(biāo)函數(shù):
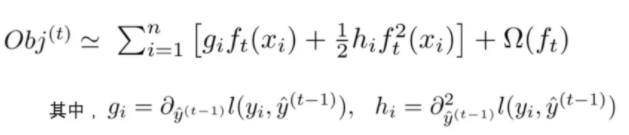
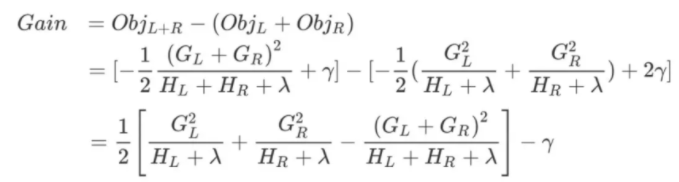

— 推薦閱讀 — 最新大廠面試題
AI開(kāi)源項(xiàng)目論文
NLP ( 自然語(yǔ)言處理 )
CV(計(jì)算機(jī)視覺(jué))
推薦
戳↓↓“閱讀原文”領(lǐng)取PDF!